Conducting Data Queries in NVivo (Part 1 of 2)
Once there has been a sufficient amount of information ingested into the NVivo project (or created directly in the project), researchers may want to explore the data using some of the features of NVivo.
Data Queries
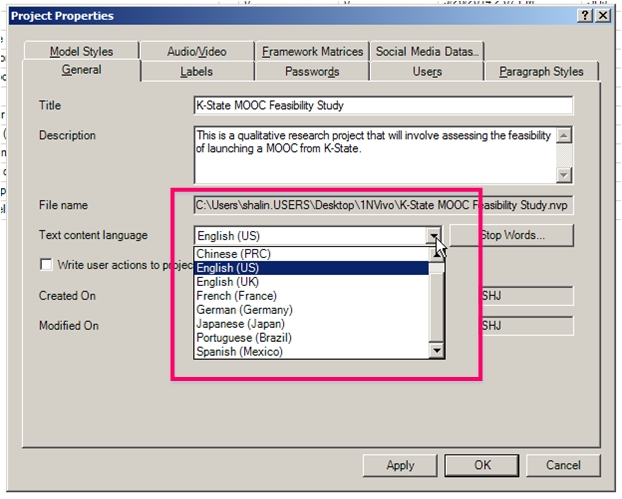
Because so much data querying in NVivo is based on a core language, it is important to ensure that the main text content language is set properly (if it is not the default language or if there are multiple languages used in a project).
To change the default language, take the following path:
NVivo ribbon -> File tab -> Info -> Project Properties -> General (sub) tab -> Text content language (in the dropdown menu) -> Apply -> OK
It helps to set some baseline understandings. The quality of the data analysis depends on multiple factors. Among others, they include the following:
NVivo enables human-machine analysis of data. This sort of research is not a technologically deterministic one in which the computer software drives the work. The technology enables some features that would not be possible otherwise.
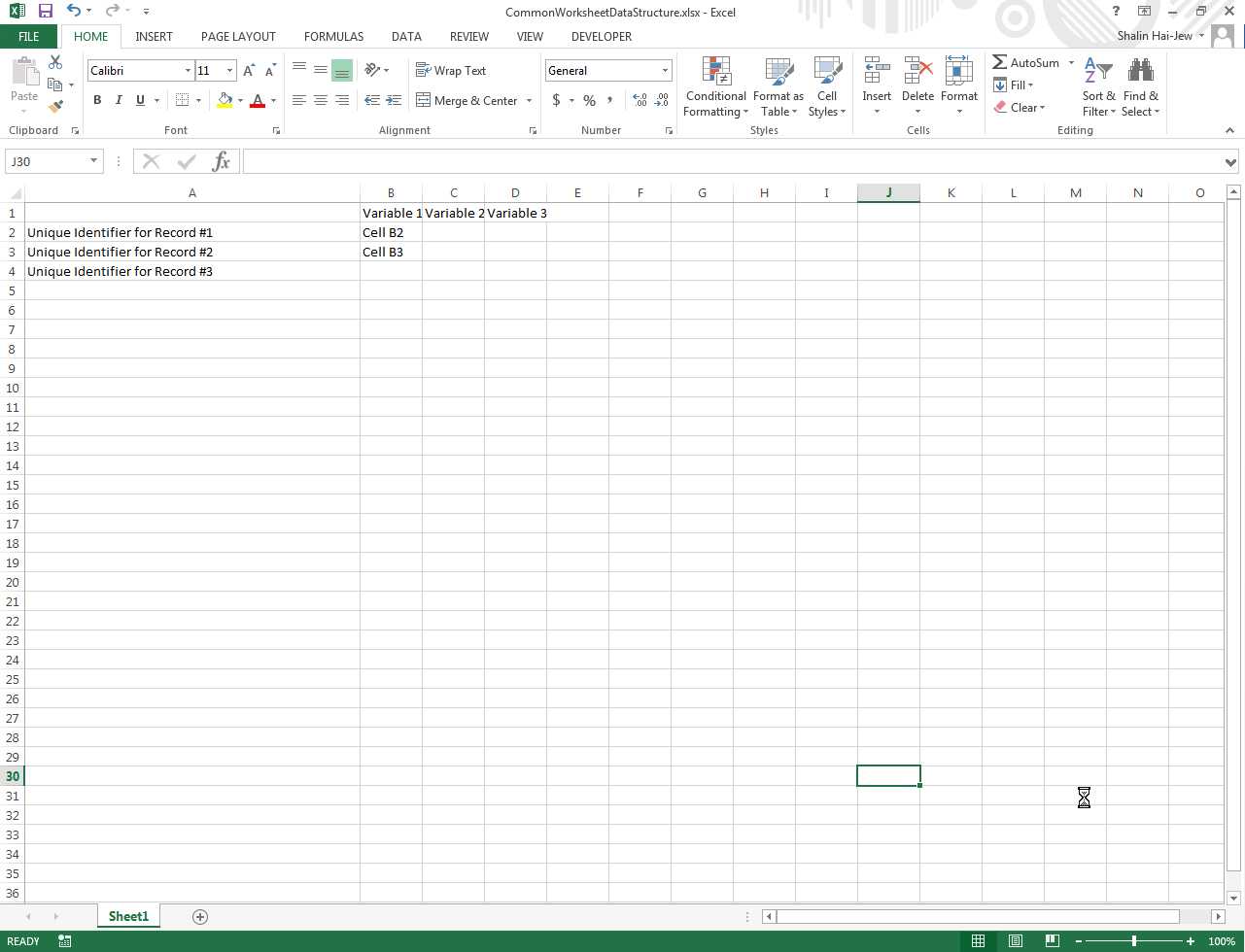
“Structured” data that is ingested would involve datasets from databases and spreadsheet programs. The “structuring” refers to the fact that the data is identified and labeled based on its location in a table or a dataset. Each informational cell then is identified information. The following is a screenshot of a simplified worksheet for data. Notice the uses of the rows with the unique identifiers and the columns with the shared variables.
It may help to consider some examples. Quantitative data are often structured data. Geospatial data are structured data. This data may be captured from multiple-choice surveys, for example. Text-based responses from interviews, surveys, focus groups, and Delphi studies are examples of unstructured data. Extracted text datasets from social media platforms (through their respective application programming interfaces or APIs) contain both structured and unstructured data. Some extractions from online survey tools contain both structured and unstructured data.
Data processing can turn unstructured data into semi-structured or fully-structured quantitative data…and this section will show how that process can work.
Data Processing as a Start-Stop Process
"Sufficiency" really depends on the researcher and the particular stage of the project. For example, the researcher may have achieved "full saturation" in terms of secondary sources for a literature review or a white paper. ("Saturation" is achieved when all possible work that could have direct or peripheral relevance has been collected...and read.) Or the researcher may have collected some initial groups of survey or focus group or interview responses—as either text data or a mix of quantitative and qualitative data. The researcher may have a set of field notes from some immersive research in a number of related locations. Any and all of this data are query-able.
Coding without Querying?
Those who are using NVivo may choose to ingest data and code it and use that coding in a mostly manual way to extract meaning from the research and call that good. There is not a particular impetus to use further functions in NVivo for some researchers. However, for those who want to use more of the feature set in this tool and to extract insights that are not as readily achievable manually, there are some elegant data queries that may be used.
Data Queries
What are data queries? Within NVivo, these include ways to identify patterns and interrelationships in textual data. They include ways to select out particular words or phrases or symbols or characters to understand their gist in a dataset. Data queries enable researchers to find "latent" or "hidden" information that may not be seeable by manual means.
Setting the Text Content Language (Base Language)
Because so much data querying in NVivo is based on a core language, it is important to ensure that the main text content language is set properly (if it is not the default language or if there are multiple languages used in a project).
To change the default language, take the following path:
NVivo ribbon -> File tab -> Info -> Project Properties -> General (sub) tab -> Text content language (in the dropdown menu) -> Apply -> OK
{kind=link}
Some Initial Understandings
It helps to set some baseline understandings. The quality of the data analysis depends on multiple factors. Among others, they include the following:
- the quality, provenance, and handling of the ingested data;
- the training of the researcher and research team; and
- the ability to use NVivo in a strategic way.
NVivo enables human-machine analysis of data. This sort of research is not a technologically deterministic one in which the computer software drives the work. The technology enables some features that would not be possible otherwise.
Structured, Unstructured (Multi-Structured), and Mixed Data
“Structured” data that is ingested would involve datasets from databases and spreadsheet programs. The “structuring” refers to the fact that the data is identified and labeled based on its location in a table or a dataset. Each informational cell then is identified information. The following is a screenshot of a simplified worksheet for data. Notice the uses of the rows with the unique identifiers and the columns with the shared variables.
{kind=link}
“Unstructured” data refers to information that contains miscellaneous mixes of heterogeneous information, without any pre-structuring of the data type. A text corpus, for example, is unstructured data because it is only “a bag of words.” It does not have the placement of elements in different rows and columns. Human-readable structure (in text) is not machine-readable structure. Any structure extracted from texts and text corpora / corpuses is extracted based on the counting of semantic terms and phrases, word proximities, word frequency counts, and word networks. (NVivo enables some queries of such texts but not all.) Mixed or heterogeneous information types refer to the idea that the information may be of various digital formats--images, audio files, videos, texts, multimedia, and others.
[A note about terminology: Some argue that there is no such thing as truly "unstructured" data...but rather that data is multi-structured. The intuition here is that all language has some inherent structure. All 2D or 3D imagery has some inherent structure. All information has some patterning or some inherent structure. Those who subscribe to this school of thought suggest that instead of "unstructured," people should use "multi-structured". The only true unstructured data, it is said, is fully randomized 0s and 1s. Others will assert further and say that there is "innate structure in everything," even if some of it is hidden or latent to people at this time.]
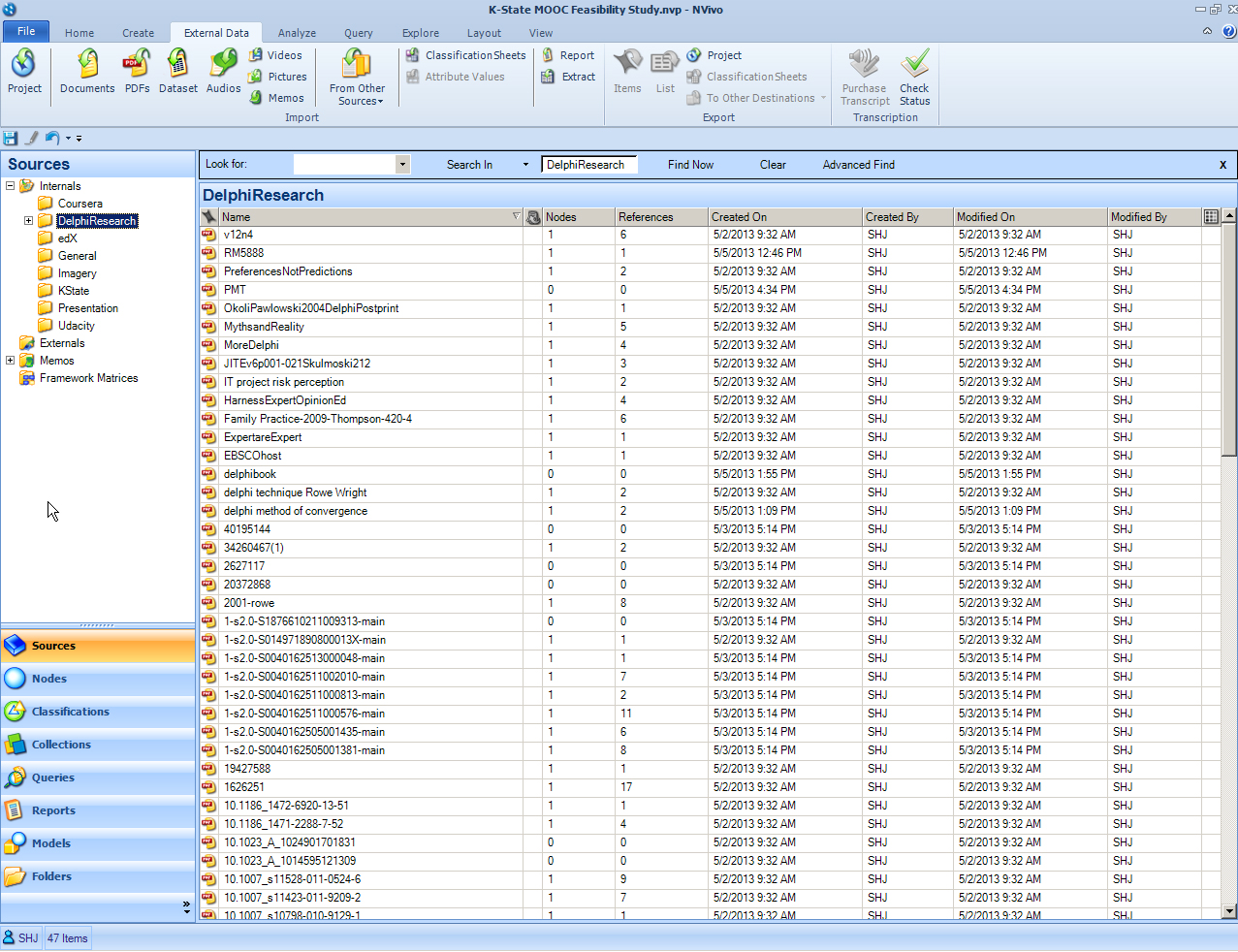
A screenshot of unstructured data follows. This is a screenshot of a text corpus of related articles collected in a folder in NVivo. This actually may look like structured data because of the table, but these are standalone text articles.
{kind=link}
It may help to consider some examples. Quantitative data are often structured data. Geospatial data are structured data. This data may be captured from multiple-choice surveys, for example. Text-based responses from interviews, surveys, focus groups, and Delphi studies are examples of unstructured data. Extracted text datasets from social media platforms (through their respective application programming interfaces or APIs) contain both structured and unstructured data. Some extractions from online survey tools contain both structured and unstructured data.
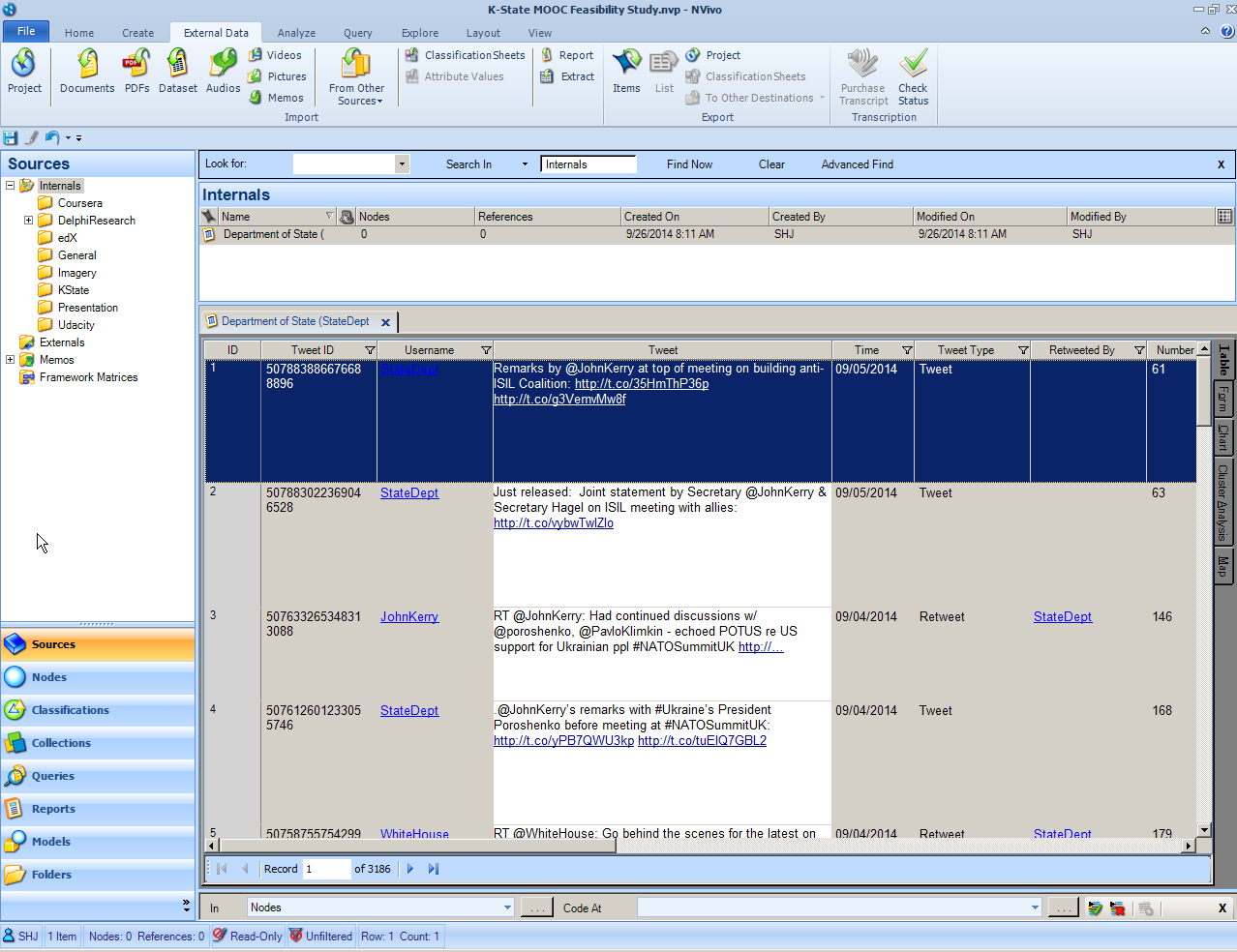
A screenshot of an example of a mix of structured and unstructured data follows in the Tweetstream dataset.
{kind=link}
Data processing can turn unstructured data into semi-structured or fully-structured quantitative data…and this section will show how that process can work.
Data Processing as a Start-Stop Process
Data processing in NVivo is a start-stop process. It is not possible to insert pre-set breakpoints in the data processing. Once a process starts, it runs until the data is fully processed, or the process is interrupted or stopped. There are no mid-point stoppages that may be conducted in order to view intermediate semi-processed data.
If a process runs for more than an hour without stopping, the system is probably hanging and not likely to recover on its own. Remember that NVivo (unless it's the server version) is running on your local machine with the limits of the computer's / laptop's processing. If there is too much data to analyze, the software will sometimes hang...and it may take some creative work to make text sets smaller or to change the file types or to make other adjustments in order to achieve the computational analyses.
Discussion of "Conducting Data Queries in NVivo (Part 1 of 2)"
Add your voice to this discussion.
Checking your signed in status ...