Starting a New NVivo Project
There is no absolute set time in a research sequence to begin an NVivo project. As noted, an NVivo project may be started from the nascent brainstorming phase before any research has started to take shape. It may be started at any time in the research sequence—depending on the objectives of the researcher.
There may be one large cumulative .nvp (NVivo project) file, or there may be a lot of (or a few) small ones for any research sequence. The tool is very stable and has backup mechanisms if set up properly (when a project is started). That said, a project does not have to be cumulative. It has to only include the data about which research questions may be asked. Anything beyond that would be excessive. In other words, it helps to know what you want to ask of the data when setting up projects. Another upside is that as research question needs change, new projects may be easily set up and used for exploration.
The point is to use the tool in the most optimal way possible for you and your team.
Starting a New NVivo Project
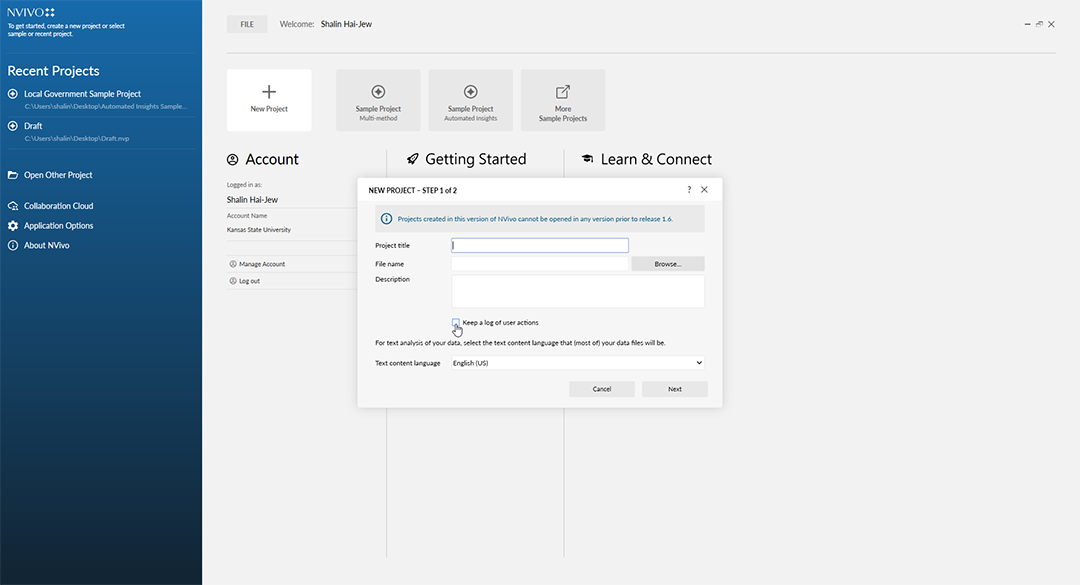
To start a new project, after you have already downloaded and installed NVivo, start up NVivo. Click the New Project button in the start-screen left menu bar. A window will open with two text fields: “Title” and “Description”. Fill those text boxes. The title and description may be re-edited and updated later as well. You may choose where you want to save the project to.
{kind=link}
To start an eventlog or not
Finally, there is a check-box to indicate whether you want NVivo to maintain event logs. The message reads: “Write user actions to project event log.” An "event" is any sort of human-instigated occurrence which happens in the NVivo project. Event logs are text-based recordings of when each individual on a project accessed the project and what was achieved at that time. This text-record may be used to understand the data cleaning, the human coding, the human-instigated machine coding, the various types of coding queries, the data visualizations, and other types of work conducted inside NVivo. (Text records are very light on memory, so there is low memory expense to actually logging actions.)
This macro feature may be useful on team- or group-research projects where it is important to keep track of who has done what and when. This may be helpful for single-person projects in order to keep track of the numbers of hours invested and the trajectory of the work. Such collected information may be used in the "Methods" section of a publication or even in the Appendices.
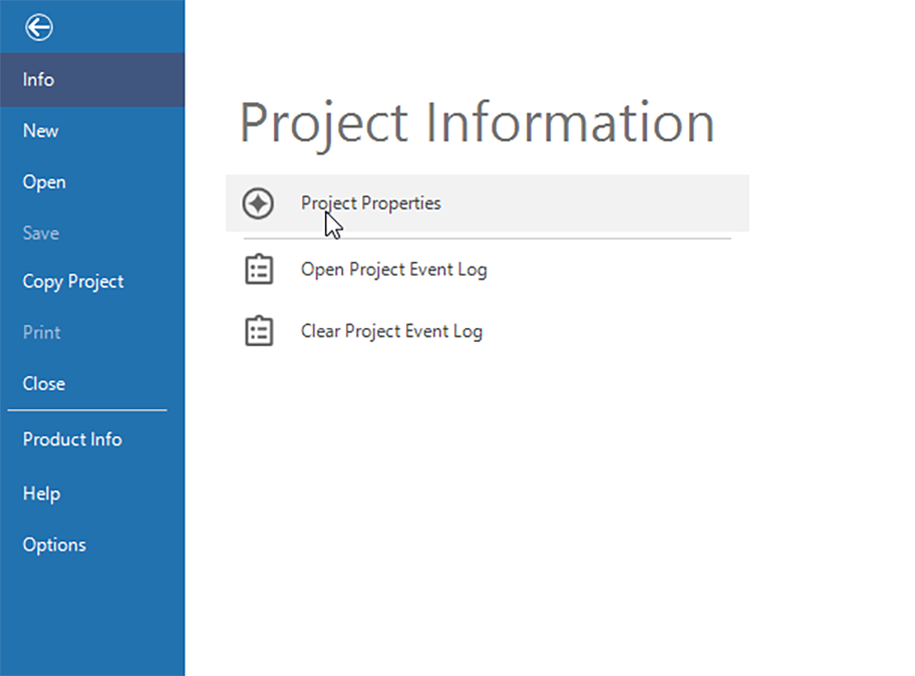
It helps to note that an event log cannot be captured retroactively. If there is any chance that this feature (and related information) is going to be needed, it’s a good idea to check the box as early in the process as possible. The captured information is in text format. The screenshot here is from NVivo (in Windows).
To access the event logs, go to File -> Info -> Project Properties -> Project Event Logs
{kind=link}
In terms of event logs, researchers may maintain their own in their Memos folder or any file that they maintain and update in NVivo (or elsewhere, for that matter).
What to have ready
Researchers who prefer to wait until they have a fair amount of resources ready before starting an NVivo project file may think about some of the following contents.
- It may help to think about Sources—both Internals and Externals. Are there various .PDF, HTML, .doc, .docx, .rtf, .txt, or other such files that may be collected for uploading into the Sources as secondary research (such as for a literature review or white paper)? Are there files that describe external and non-digitized sources for the Externals folders?
- Is there an a priori-designed codebook that will be used? Or are there ideas on how to create an emergent codebook? Or will a codebook be created in both a mixed a priori and emergent way?
- Is there a research journal that has been started that would help inform the research and that may be continued as the project progresses?
- Is there a folder of “authorizing documents” for the funded research (from grant funders)?
- Is there a project stylebook for how the work will proceed for when the project is in the publishing and presentation phase?
Keeping it simple
New users to NVivo may over-weight the technological determinism of the tool and feel pressured to use all tool functionalities. There is certainly no pressure to bring everything into play. As a matter of fact, it is probable that researchers only use parts of the tools for various functions. There is no need to add unnecessary complexity.
NVivo project sizes. According to the QSR International site, there is a 10 GB limit for NVivo projects that are run off of local machines. Video sizes are limited to 20 MB sizes each; many project videos are hosted on free social media platforms like YouTube, for which NVivo has a smooth integration to the YouTube embed link. There is a way to reset the upper limits of per-ingested-video-size to 40 MB. (That would be 500 20 MB videos, minus whatever it would take to include some of the additional in-project information.) Presenters with QSR International have said that there will likely be fairly high computer processing latency before one achieves the higher ends of that project size anyway.
Those who have NVivo hosted on a local server may have 100 GB or an even unlimited setting for project sizes. (QSR International does not offer a hosted solution for NVivo currently. Institutions using the software on a server will have to host it on their own servers. They will have to protect and defend their own data against hacking and compromise and potential destruction.)
[As an aside, the sample project used here for the screenshots is 248,000 kilobytes (KB) or 248 megabytes (MB) or 0.3 gigabytes (GB). The sample project contains numerous articles, screenshots, and other small-footprint types of files.]
Using multiple NVivo projects for a single research endeavor
NVivo project sizes. According to the QSR International site, there is a 10 GB limit for NVivo projects that are run off of local machines. Video sizes are limited to 20 MB sizes each; many project videos are hosted on free social media platforms like YouTube, for which NVivo has a smooth integration to the YouTube embed link. There is a way to reset the upper limits of per-ingested-video-size to 40 MB. (That would be 500 20 MB videos, minus whatever it would take to include some of the additional in-project information.) Presenters with QSR International have said that there will likely be fairly high computer processing latency before one achieves the higher ends of that project size anyway.
Those who have NVivo hosted on a local server may have 100 GB or an even unlimited setting for project sizes. (QSR International does not offer a hosted solution for NVivo currently. Institutions using the software on a server will have to host it on their own servers. They will have to protect and defend their own data against hacking and compromise and potential destruction.)
[As an aside, the sample project used here for the screenshots is 248,000 kilobytes (KB) or 248 megabytes (MB) or 0.3 gigabytes (GB). The sample project contains numerous articles, screenshots, and other small-footprint types of files.]
Using multiple NVivo projects for a single research endeavor
It is helpful to strategize how to approach research particularly if it is possible that there may be a high number of large datasets. It is wholly possible to have contents in separate NVivo projects…and to integrate them for particular data queries and processes only…and to leave the contents mostly disaggregated otherwise. If there are private video captures of interviews, clearly, those cannot be hosted on a public video site, and the videos may have to be ingested…but there are ways to compress videos into smaller sizes to enable easier handling. (The solutions to such issues are both within NVivo and outside of NVivo. When troubleshooting, it helps to consider a wide range of possible approaches.)
Backing up a project
Every 15 minutes, if there have been changes to the project, NVivo will prompt the researcher to save the project file; it is a good idea to save the project. (Backups, if these are set to back up, seem to save automatically. It is unclear why the 15-minute prompts occur for the main project.)
Part of responsible research involves proper handling of data. To that end, one aspect of that proper handling involves ensuring that the invested hours and expertise in setting up, coding, analyzing, and writing up research in NVivo is not possibly lost due to file corruption or fire / water damage or other potential issue. It is advisable to save a copy of a project to a secure server space beyond the work space (whether that’s a desktop or laptop). (The suggested formula is to have two copies stored spatially in a local space and at least one non-locally. The idea is to save a backup to a remote location or one that is at least not co-located with the main work file. It is also a good idea to test backups to make sure that that are saving correctly.) It is not advisable to have a main working copy only on a mobile external memory device in part because of the potential for external hard disk corruption (and nontrivial irrecoverability of the data) and of user misplacement and / or loss of the memory device.
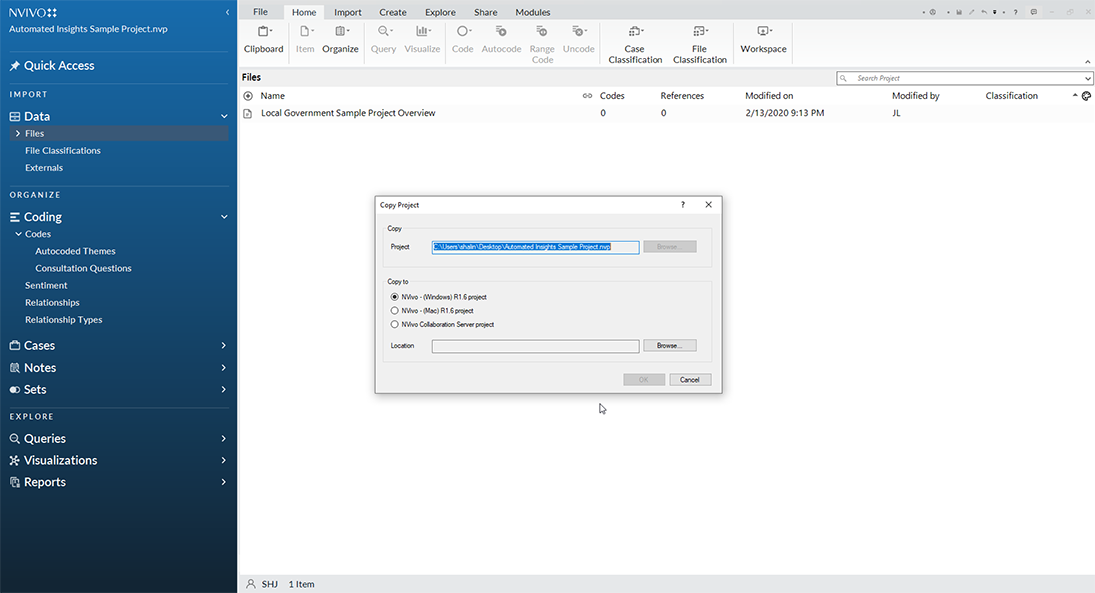
The steps to copying a project are: File -> Copy Project.
The steps to copying a project are: File -> Copy Project.
Saving a project locks in any changes from the last save. If a mistake was made, sometimes not saving the project enables a return of the project to a prior state.
{kind=link}
Automated project backup
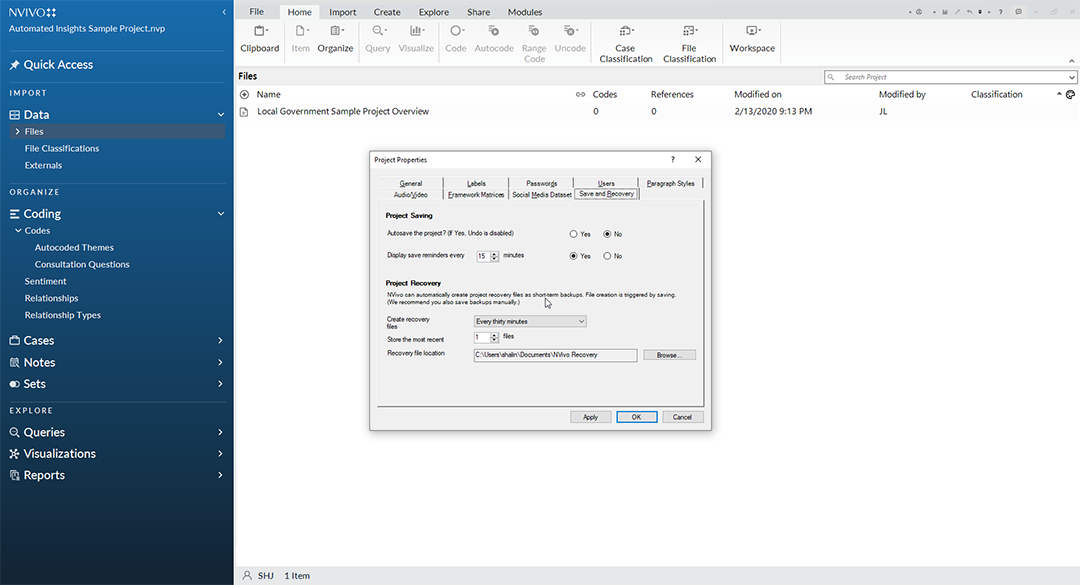
Another option involves setting up automated project backup file (.nvb). This feature enables the automatic creation of a backup project recovery file "on save" every half-hour, hour, every four hours, or once a day. This enables the creation of file redundancy on the system (with the file set up to be saved in the user's documents folder). This on-system redundancy is a local one, so if there is system failure, file redundancy itself (on that system) fails.
The steps to setting up global-level NVivo project recovery setup are: File -> Project Properties -> Save and Recovery.
{kind=link}
Set up how often a backup copy should be saved. Note the breadcrumb trail to find the recovered file if needed.
(NVivo is a very robust tool in general, and it is not common to have any project irrecoverably lost. However, technology is technology.)
For many researchers, they may also maintain analog (physical, material) data in addition to the digital data. It is important to protect these resources as well, such as having paper notes and manuscripts copied and stored in fireproof safes...or digitized in an appropriate format and saved in multiple copies.
Some Fundamentals for Digital Data Management
Specialists in data management suggest that it may be good to keep a separate set of all files used in NVivo albeit outside of the proprietary .nvp file--as a matter of good practice to protect against potential future inaccessibility. (However, such files will not have the annotations or linked memos and such within NVivo.) [A counter view could be that QSR International has been around for many years and has a very solid track record in terms of supporting its flagship product. This stance would be that making an extra set of files is unnecessary and bordering on excessive caution.]
As general good practice, they suggest the creation of a README file (usually a .txt or .rtf file) that summarizes the related data contents; also, a listing of all data is often created in a spreadsheet. (It is important to document related metadata linked to data at the moment of information capture, so that nothing is lost to time and bad memory. Recreating notes retroactively risks being inaccurate and incomplete.) They suggest the application of consistent and informative file naming protocols for easy findability, sorting, and searching. (There are tools that enable batch renaming of files.) They also suggest the recording of "data provenance" especially if there are multiple individuals or entities that will "touch" digital data and evolve that data. If there are standards for the representation of information--such as the ISO standard for the representation of dates--those should be used. (There are as-yet no global standards for data management.) There should always be a set of data kept pristine (untouched, un-annotated, unchanged), separate from what the researchers used, in case it is important to return to a pristine version to check on data.
Folder structures should be clearly and logically named for easy findability. There should not be any white spaces in the folder names (likewise, there should be no whitespaces in file names; many use hyphens or underscores in place of the whitespaces). This is good practice because whitespaces are problematic for uses on certain systems (such as on unix machines). Also, special characters should not be used in file names because these are reserved for certain machine processes and may cause problems in search, sorting, and other processes. Also, it is a good idea to use "leading zeroes" (01, 02, 03, 04...10...) in order to name files, so that the 1 is not co-clustered with 10, and the actual numbering is represented in file ordering.
Current practice involves transcoding of certain file types to more accessible ones: from proprietary to open-source, from raw files to accessible processed ones, from single-platform formats to multiple-platform formats, from single OS formats to multiple-OS-accessible ones, from complex file types to "lowest common denominator" file types, and so on. A .zip of contents is considered inaccessible because of the software used to create .zip files and the fact that many such software tools go defunct or are not reverse-compatible). Another tenet is to ensure that there is as little data "loss" in the transcoding as possible. DataOne is an important resource on this topic.
Many grant funding agents require a data management component, and defining how the data will be handled at every phase from collection to archival is critical for the success of most research projects. Sensitive information will require even more careful data handling, such as requiring that the data be hosted on machines not connected / not connectable to the Internet, or that information at rest and / or in transit be encrypted. Most data have guidelines for their ethical use, and those should be followed to the letter.
Finally, there is an important caveat. In all training materials, it is important not to be caught up in the short-comings of the presenter. What is shown here are some approaches only and by no means *the* right ones. Research work should be an open space, with all sorts of methods for ingress and egress while maintaining standards.
Discussion of "Starting a New NVivo Project"
Add your voice to this discussion.
Checking your signed in status ...