Starting a Multilingual Project
{kind=link}
Accommodation of Languages in Unicode Character Sets
NVivo can accommodate a wide range of languages in its projects given its UTF-8 and UTF-16 (Unicode) character sets' capabilities. These capabilities extend across documents, photos (as textual descriptors), audio files (as textual transcripts), videos (as verbatim transcripts), spreadsheets and datasets, and nodes. Various languages may also be applied in the file management process, including search, find, node names, and others. This means that any language that is expressible on social media platforms, the World Wide Web (WWW), and the Internet may be captured with fidelity in an NVivo project.
It is one thing to say that a software can ingest symbols that represent over 180+ languages, including symbol and character-based languages (Japanese, Korean, Chinese, and others). It is another to say that the software can actually represent directions in that language.
It is one thing to say that a software can ingest symbols that represent over 180+ languages, including symbol and character-based languages (Japanese, Korean, Chinese, and others). It is another to say that the software can actually represent directions in that language.
Computational Analytics and Select Languages (one at a time)
The software has the the basic integrated languages: Chinese, English (US), English (UK), French, German, Japanese, Portuguese, and Spanish.
- This means that the sentiment dictionary is in that base language.
- This means that the "stopwords" lists for that project are in that base language. (Stopwords lists are editable at either the project level or at the particular query level, for the word counts, for the data displays.)
- This means that the topic modeling is conducted in that base language.
- This means that the autocoding by existing pattern is conducted in that base language (assuming the human coding is in that base language).
The software also has limited ability to build character trees from character searches are limited because of the challenges of identifying sentence beginnings and ends with some character languages.
The software does not enable multiple language analytics simultaneously (not like natural language processing by cloud services by IBM, Google, Amazon, Microsoft, and others).
Defining a Main (Base, Content) Language for the Project
Those who are using multiple languages in a project are advised to set the project’s “Text content language.” This is the main language used for spell checks (as the "proofing language"), word stemming, synonyms, stop words lists (used in word frequency counts, text search queries, and cluster analyses), and data visualizations.
For the sake of some of the queries, it may help to translate original documents into the text content language for specific data queries and analyses. Those using machine translations are advised to have a native speaker go through the contents because the quality of translations vary, and machine translations still fall far short of accuracy and nuance.
Steps to Setting the Text Content Language
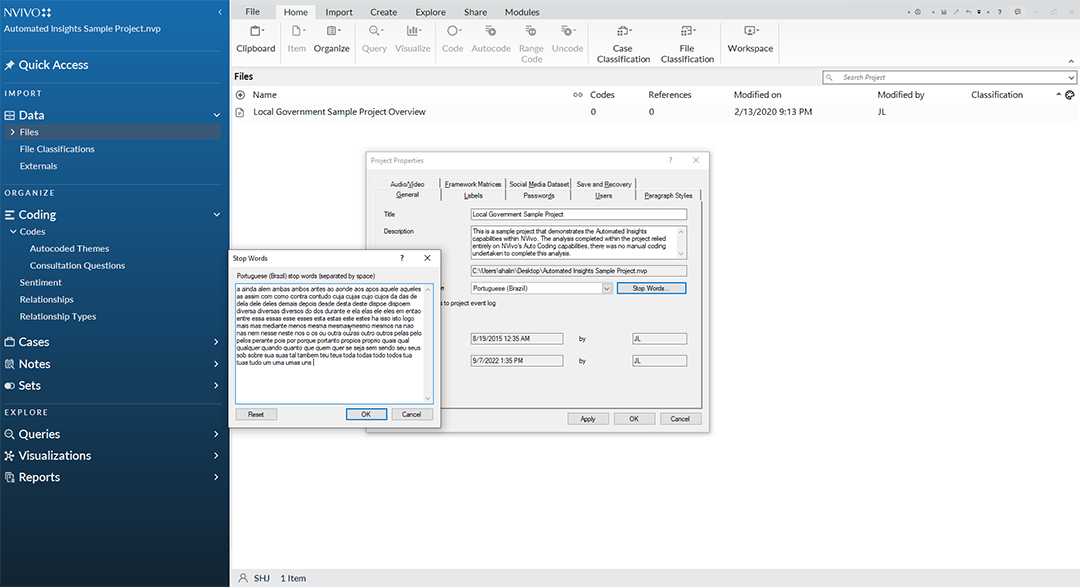
When starting a bilingual or multilingual project, go to File -> Info -> Project Properties. Click on Project Properties.
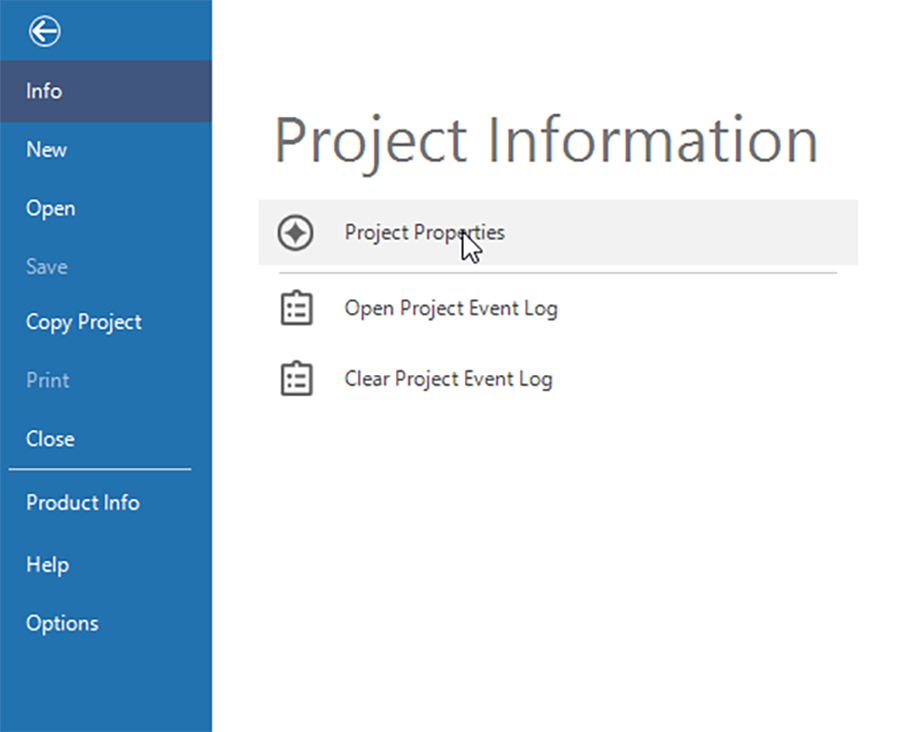{kind=link}
The Project Properties window opens.
In the General Tab, go down to “Text content language.” (This is the same as the "base language.") The dropdown menu enables the choice of which language to use for the predominant language for analyses and data visualizations.
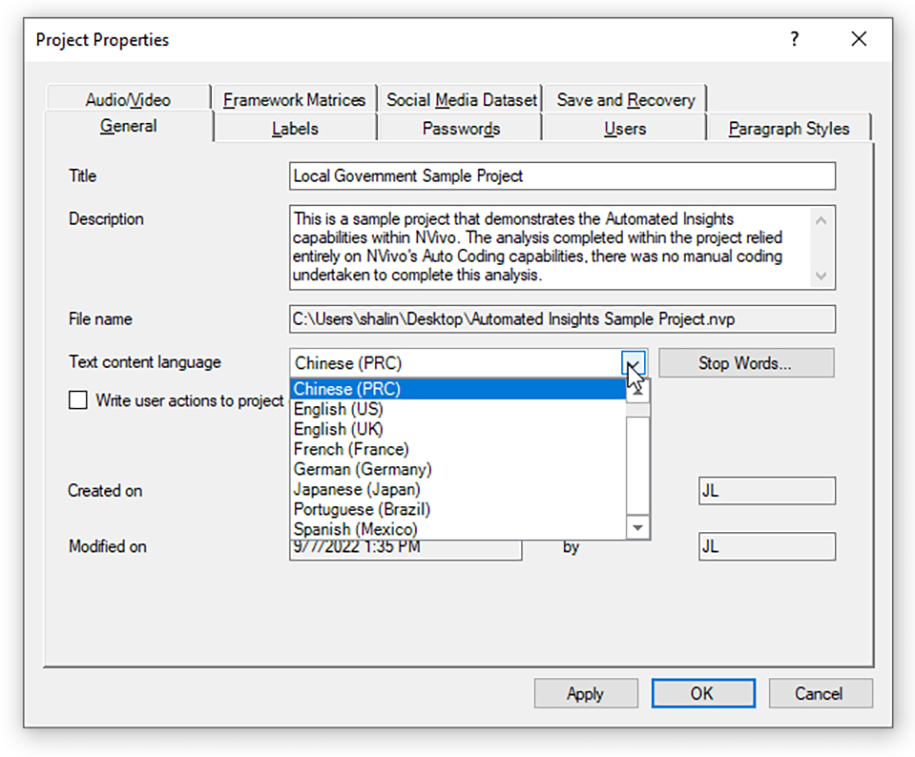{kind=link}
Click "Apply". Click "OK".
The main preferred language may be changed later on in the project, but that selection will change how the prior stored data queries (macros) will function for certain types of queries (such as word frequency counts, word searches, and so on).
If this preferred language is not selected, then the default language will be used. That default is part of the initial software purchase.
The main preferred language may be changed later on in the project, but that selection will change how the prior stored data queries (macros) will function for certain types of queries (such as word frequency counts, word searches, and so on).
If this preferred language is not selected, then the default language will be used. That default is part of the initial software purchase.
Viewing the Default Stopwords List in the Selected Language
Those who may want to view the Stopwords list in the selected language simply have to click the “Stop Words” button to the right of the “Text content language” dropdown menu.
The path is File -> Info -> Project Properties -> General tab -> Stop Words button.
The visualization below shows the default stopwords list in Japanese. (Users of the software may add their own stopwords at any time. They may also delete any of the default stopwords words or characters. Another common term for the "stopwords list" is a "delete words list.")
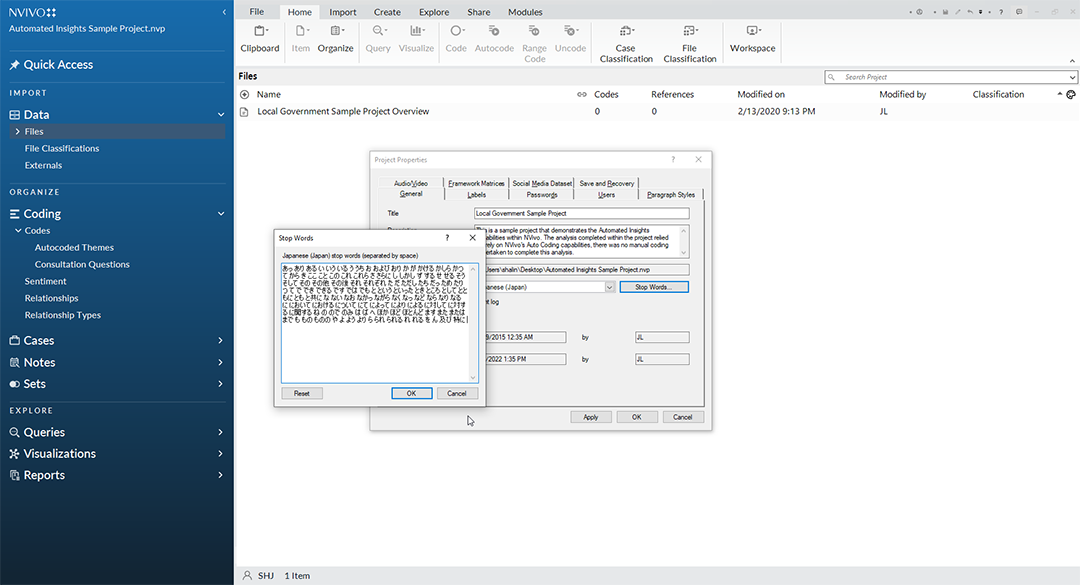{kind=link}
If changes are made to the stopwords list, that may be an important fact to note for the Methods section of a research paper.
What May Be Added to Project Stopwords Lists?
Whatever is put into the stopwords list may be from any language. They may be names. They may be emoticons. They may be numbers. They may be formulas or mathematical equations or algorithms. Anything that is representable in Unicode may be placed into the stopwords list for that project (not for every use ever after of the software).
Handling Multiple Languages
Remember that the same data (dataset, document collection, imageset, videoset, etc.) may be run through multiple language queries...by setting up the project to focus on different languages...or saving the content into different projects with different base language settings and running those.
[Online AI tools by IBM, Google, Microsoft, and others enable multiple language analytics simultaneously. At scale, the analytics would entail costs (although surprisingly low costs). Such analyses may require knowledge of methods for light programming.]
Software Interface Languages in NVivo
There are seven interface languages that may be used: English (US, UK), simplified Chinese, French, German, Japanese, Portuguese, and Spanish. Interface languages are the languages used to describe NVivo tool functions and capabilities in-tool. This means the directions for the project are in the selected language. These are determined at the time of purchase and applies even if the text content languages for analytics are changed.
The interface languages (the languages used for tool labeling and explanations within the tool) are set at the time of purchase...
| Previous page on path | Starting a New NVivo Project, page 1 of 1 |
Discussion of "Starting a Multilingual Project"
Add your voice to this discussion.
Checking your signed in status ...