Data Query: Word Frequency Count Query
Word Frequency Count Query
A word frequency count provides researchers with an overall sense of the most common (usually) semantic-based words in a data set, document, text corpus, microblogging stream, or research set (or some mix of the data). The intuition here is that words (and phrases) that are repeated often are a topic of focus for the author, discussion forum, literary document set, or other originating texts. This approach is used for coarse text summarization and topic modeling, among other endeavors. The words may include common formulas or symbols. The level of the count is at a unigram or one-gram, so unless phrases are run-together, they will not be treated as a single unit ("goodtoseeyou" is treated as a one-gram, but "good to see you" will disaggregate into "good" "to" "see" "you" and then will only be counted individually if the component parts are not in the stop words list and are not under three letters). Of course, it is possible to change the parameters of this process and most other processes in NVivo. (Just keep a record of the parameters when running processes, if you will be reporting out in a presentation or a publication or other sharing.)
Data Pre-Processing
Texts as Stand-alone, Grouped, or Wholly Melded Files?
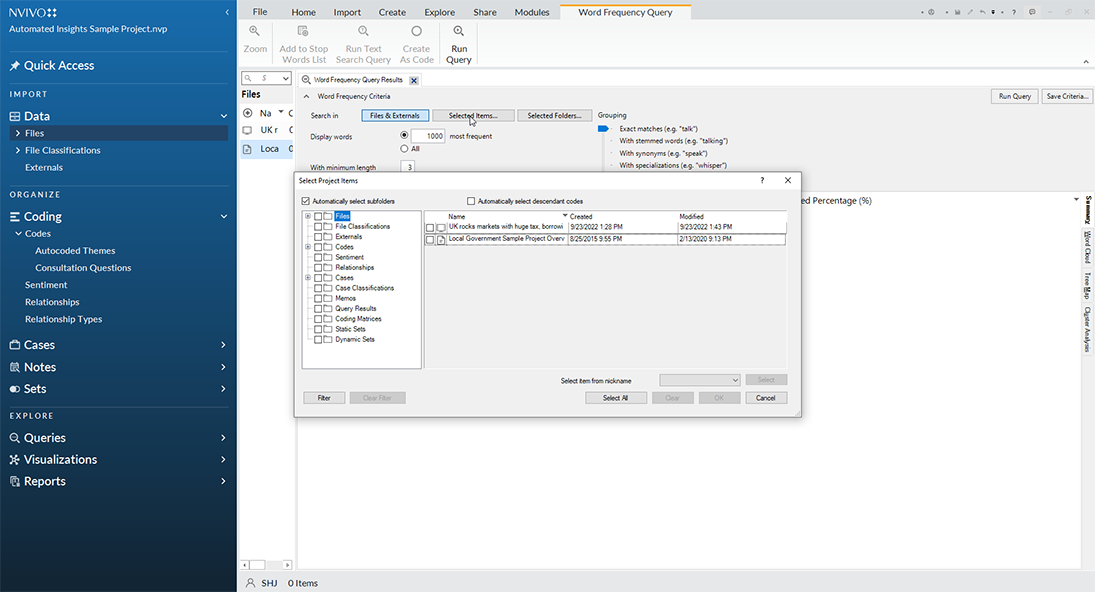
Setting Parameters for the Word Frequency Count
{kind=link}
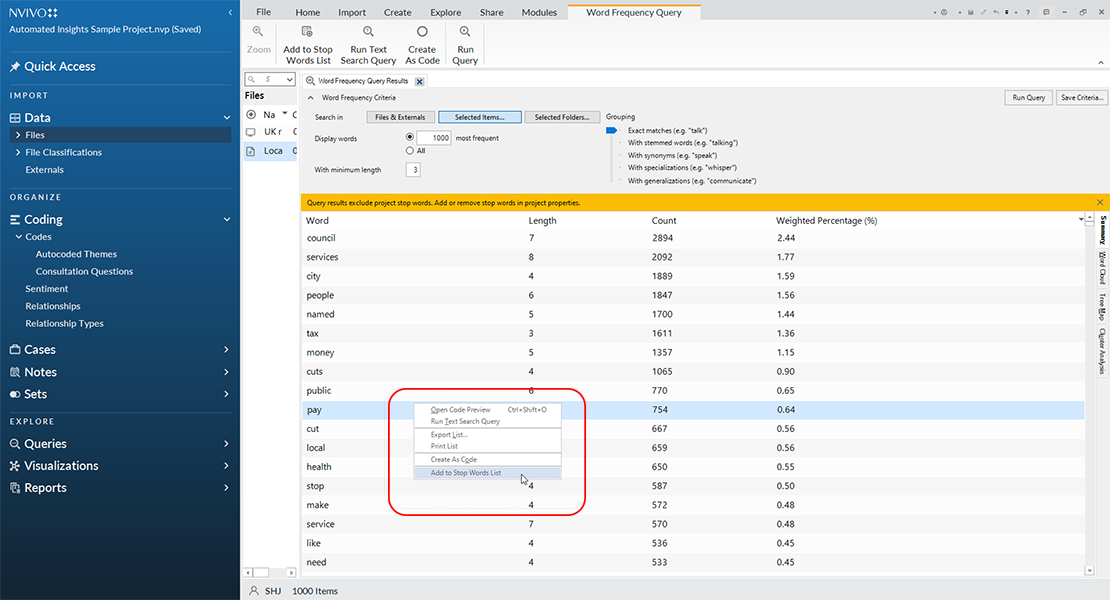
When the run is completed, the summary data is shown as a table. The researcher may go through the list and add more words to the stop words list by right clicking on a particular word and clicking on “Add to Stop Words List”. Click OK. Or, a researcher may select a list of words to “stop” and click OK.
Once this is done, the text frequency query has to be re-run in order to apply the new stop words list to the data set. To achieve this, the researcher has to start again at the ribbon.
Usually, once the frequency count has been done, it is helpful to peruse the list to look for anything anomalous or of special interest. Anything that stands out may provide a lead for further research.
{kind=link}
At this point, click “Run” again. The resulting table will be listed in descending order with the most popular words at the top and the least-used ones on the bottom. At the far right column is the weighted percentage in terms of numbers of occurrences of that word in the set.
Adding Stopwords Globally to an NVivo Project
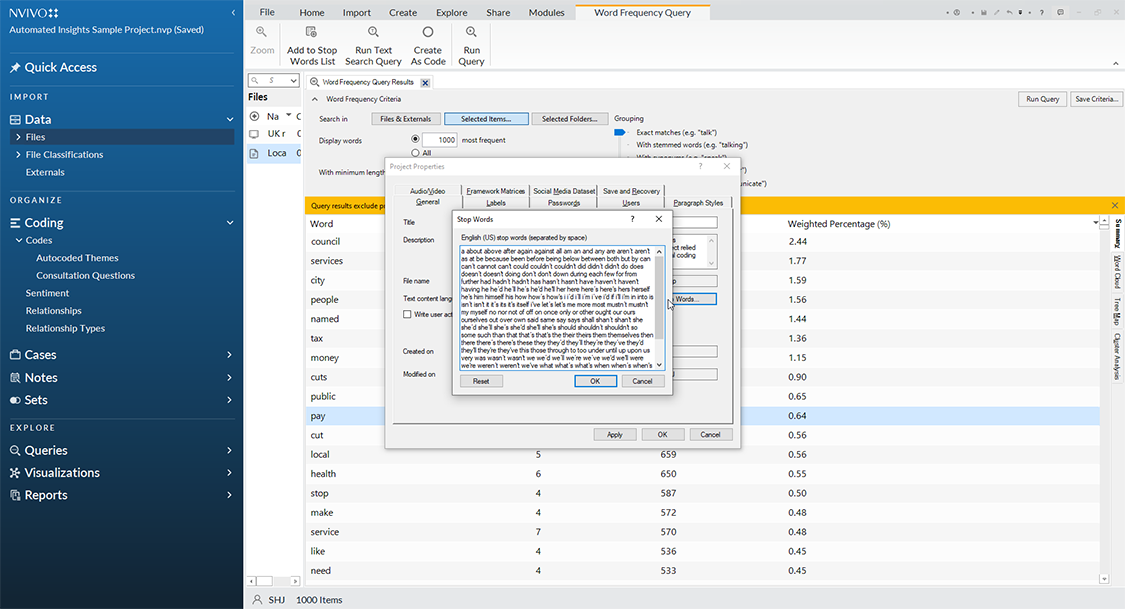
To add stopwords globally to a project, go to File -> Project Properties -> General (tab), and click "Stop Words." A window will open with a list of built-in stop words in the "text content language" (base language) selected for the project. Input all other desired stop words to the built-in list. Click OK.
All future text frequency counts in the project will ignore the Stop Words designated for the particular project. (Once a new project is started, though, the default stop words dictionary built into NVivo will be used. If a researcher wants to use the customized Stop Words list, then he or she or they should either use a template project with the change instantiated...or they should revise the Stop Words list every time.)
{kind=link}
If the researcher wants to return to the default built-in "stop words" list, he or she can take the same path and click the "Reset" button at the bottom left.
A "local" stopwords list is local to the process, such as the word cloud word frequency count.
Saving a Particular Word Count as a Node
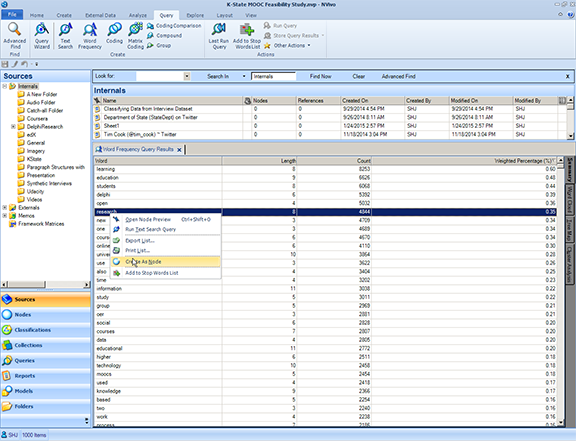
In the Detail View, a user may right-click a row of the word frequency count table and "Create as a Node." This will enable the viewing of every iteration of that word in the dataset along with its context (usually the five words before and the five words after the target term). Also, the node itself contains a direct link to the original source in which the counted word appears.
{kind=link}
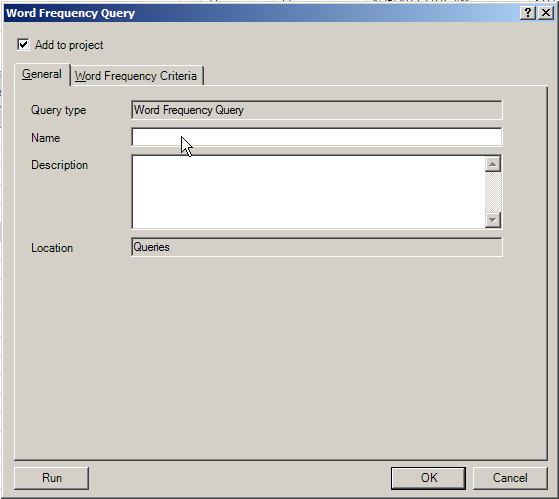
Saving the Word Frequency Count
Check the "Add to Project" box at the top left of the Word Frequency Query window in order to save the parameters of the word frequency query. Use a descriptive name and in-depth descriptor in order to explain what the query entails (for accuracy when accessing this query "macro" at a later date).
Macros are usually saved for more complex data queries, so they can be run again and again as new data is ingested into the project (or the database, as it were).
{kind=link}
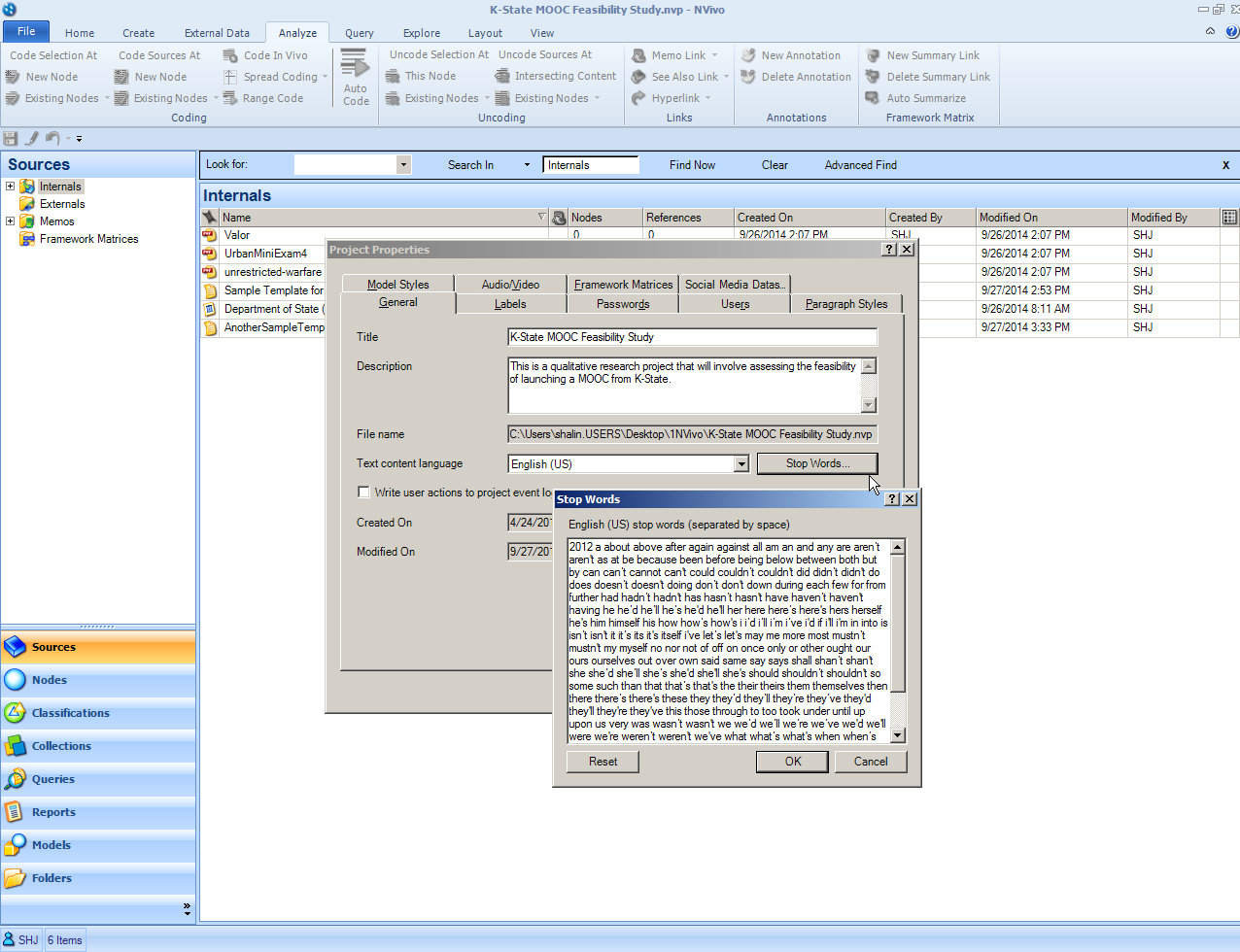
A Default Stopwords List
NVivo has brief stopwords lists for its main interface languages: English (US), English (UK), simplified Chinese, Japanese, French, German, Portuguese, and Spanish. Any of the terms may be removed by the researcher; further, any new terms may be added to the stopwords lists during the query process.
To view the stopwords list, take the following path:
File -> Info -> Project Properties -> General tab -> Stop Words button.
{kind=link}
There is not a way to edit the built-in default stopwords list to apply to all future projects, but they may be edited project-by-project. [To use an updated default stopwords list, one work-around can be to create a template project file...and to use that for the team's work.]
Word Frequency Count Visualizations
Various data visualizations are available at the far right. The data may be turned into word clouds, tree maps, or cluster analyses. (Data visualizations are often used with the underlying datasets from which the visualizations were developed.)
{kind=link}
Jumping into a Text Search Query
After conducting a word frequency count, if there is a particular term of interest, it is easy enough to right click on the term in the table view, and move on to a text search query (with that select word as the seed term). A "seed term" may be a phrase (a multi-term n-gram or a "multi-gram"), a name, a formula, a symbol, a named location, a number, or anything representable by Unicode and seeable by the software and computer.
A Walk-through with the "Query Wizard" Feature
Finally, it may be helpful to note that the Query Wizard (in the Query Tab in the Create area) may be used for a Word Frequency query.
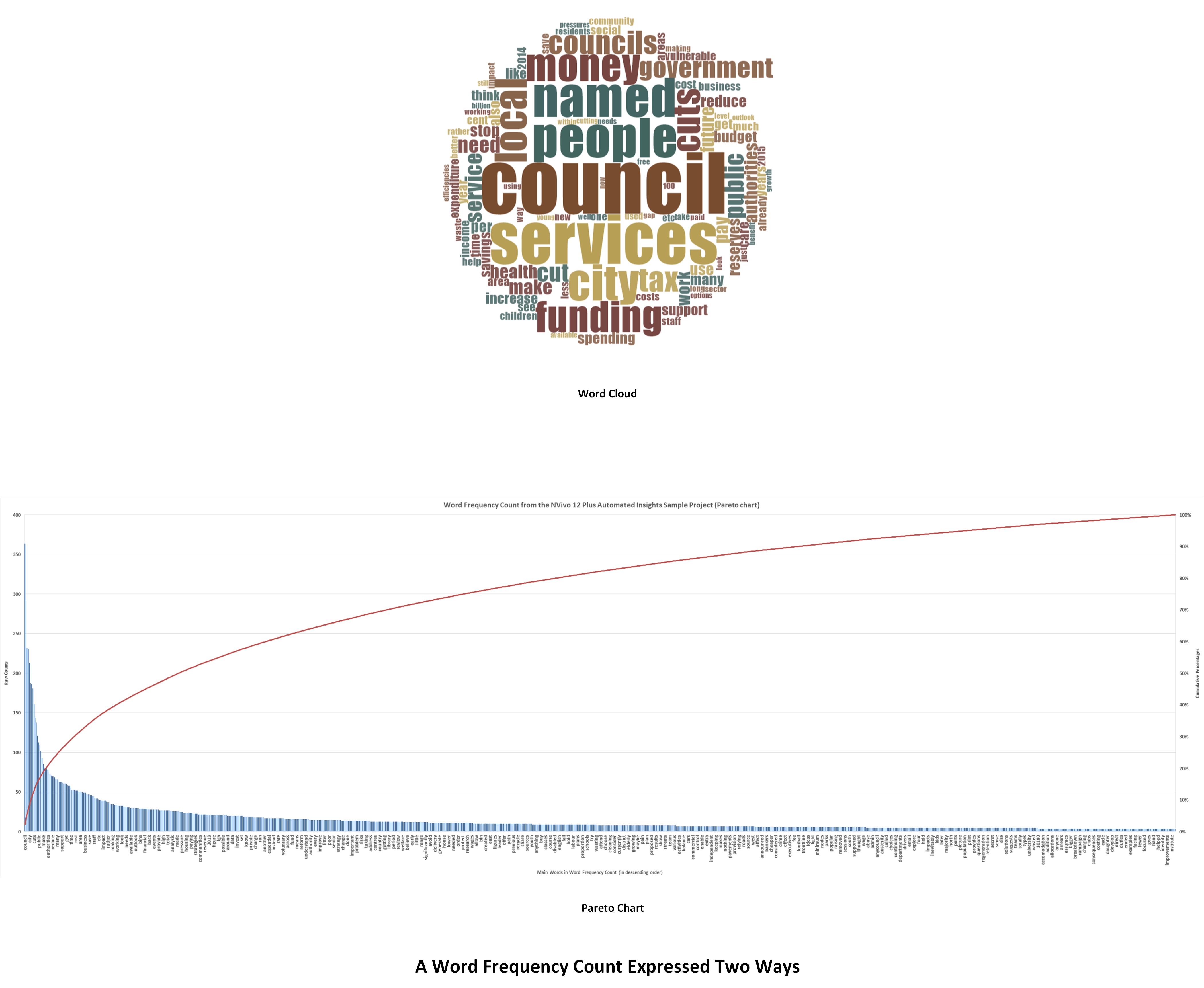
A Pareto Chart Version
The data table for a word frequency count may be exported into Excel to create a Pareto chart. See below.
{kind=link}
Discussion of "Data Query: Word Frequency Count Query"
Add your voice to this discussion.
Checking your signed in status ...