Data Query: Coding Comparison (Advanced) and Cohen's Kappa Coefficient
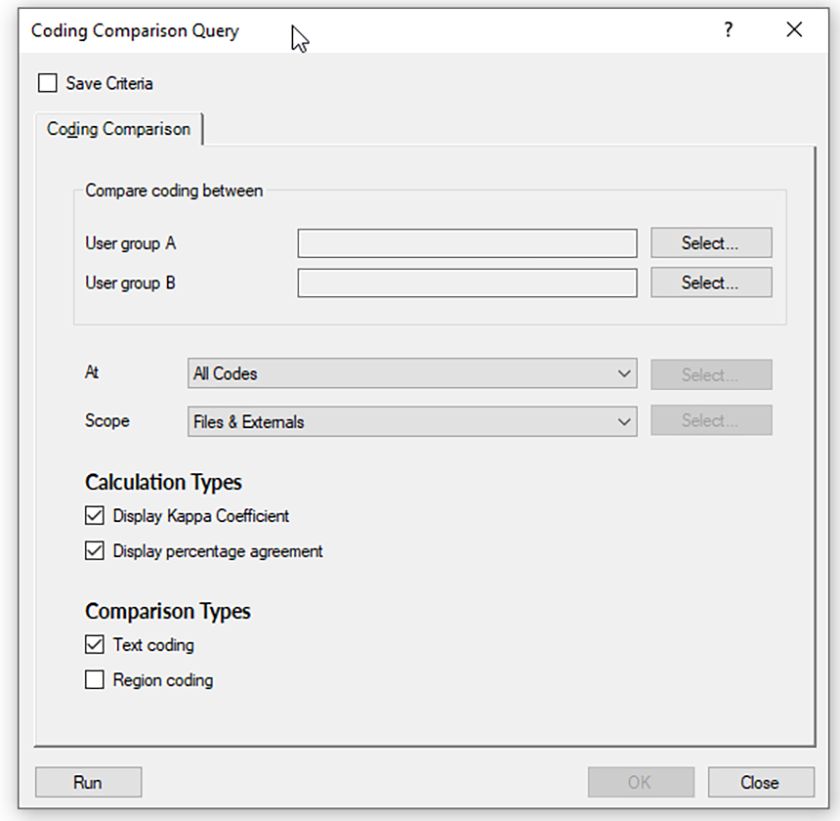
Coding Comparison (Advanced)
{kind=link}
A more advanced form of coding query involves the “Coding Comparison” feature. This query enables a researcher to compare the similarities and differences between how individuals or teams code in a shared project.
In general, if a research team wants to see if a particular social construct is supported as something extant (instead of reified), a team would train together on how to code around a shared codebook. They would strive towards controlling against rating variability. They would engage a shared project and would would have a common codebook and shared data for coding...or at least something in common, like a codebook OR shared data...or some other combination. Then, if they independently code the data with a statistical level of similarity, they can perhaps make the argument that the construct appears to exist...
For some projects, especially if a team’s members are all coding different parts of a shared dataset and need to be trained and normed to code similarly, then a high Kappa Coefficient (a sort of inter-rater reliability based on the similarity analysis of their respective coding) is desirable. If a team is collaboratively coding the same data (with all members with the same data set), then it may be more valuable to focus on dissensus and creative interpretations—so that new ideas may be surfaced. Research questions and objectives, theories, methodologies, and domain-based approaches will often vary widely. The unofficial e-book focuses on the tool but not really how the findings may be interpreted.
Dyadic Comparisons:
This tool enables dyadic comparisons only, but multiple coders may be placed on Team A or Team B for melded comparisons. Or one coder may be used as a baseline, and the other coders may be compared against that baseline coder.
Understanding "Percentage Agreement"
When a user runs a coding comparison query, NVivo calculates the percentage of agreement individually for coded source information and the node it is coded to. “Percentage agreement” is the percentage of the source’s content where the two users concur on whether the information may be coded at a particular node…or whether the information should be coded at all. From each source document, NVivo analyzes the following:
- the number of characters coded by both users (or both teams of users);
- the number of characters coded by only one of the users (but not the other);
- the number of characters not coded by either user.
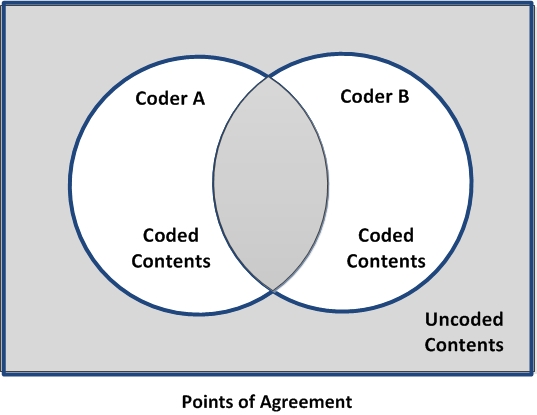
Agreement then occurs with both the overlapping characters coded *and* the characters not coded by either. The amount of disagreement then is on something that one coded but that the other did not. The points of agreement are the shaded areas in the figure below.
{kind=link}
The example given at the Lumivero (formerly QSR International) site reads:
“For example, if the source is a document with 1000 characters, where:
- 50 of these characters have been coded by both users
- 150 of these characters have been coded by only one of these users, and
- the remaining 800 characters have not been coded by either user
then the percentage agreement is calculated as (800 + 50) ÷ 1000 = 85%.” (Running a coding comparison query, Lumivero, QSR International)
For coding comparison of non-textual sources, NVivo uses image area in pixels for visualizations. For audio files and videos, the unit of measurement is seconds in duration. (This would suggest that the machine is looking at whether a segment of multimedia was pulled out for relevance to a particular node and not what message was noted in the coding.)
Cohen's Kappa / Kappa Coefficient
Cohen’s Kappa coefficient is a statistical measure of the similarity between inter-rater or inter-annotator coding selections based on a given number of rated items and mutually exclusive coding categories. Given those conditions, it measures the percentage of agreement between coders in terms of what they identify to code and where they code it to as well as what they choose to not code. In other words, this analysis focuses on what coders see as relevant (worthy of coding) and as less or not relevant (not worthy of coding). The Kappa coefficient is then a measure of inter-rater reliability (understood as percentage agreement).
The range of the coefficient spans from ≤ 0 if there is no agreement between the raters (the “less than zero” occurs because Cohen’s Kappa considers what could be coded by chance and so assumes a small potential for coding agreement based on the original size of the dataset) all the way to 1 if there is total agreement. (A machine-emulation of the human coder gets very close to 1 or an actual 1.) The in-between measures, expressed as decimals, show the percentage agreement.
Cohen’s Kappa is generally considered a fairly conservative measure of agreement because it subtracts the probability of random (by chance) agreement. This is calculated basically as follows: the probability of two coders or two teams agreeing on the coding minus the probability of randomly agreeing on the coding divided by one minus the probability of random agreement.
So kappa = the relative observed agreement among interraters (p0) minus the hypothetical probability of chance agreement (pe) divided by 1 minus the pe. Total agreement would result = 1. No agreement would result = 0.
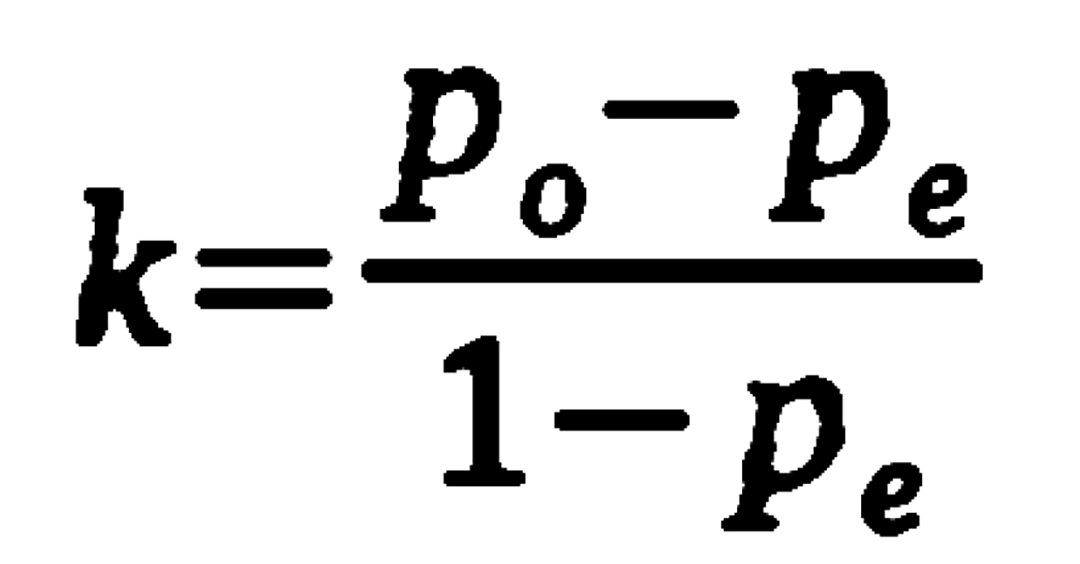{kind=link}
Κ = 1 if there is complete agreement. K = 0 or slightly less than 0 if there is no agreement. (The "slightly less than 0" is because of the accounting for accidental or by-chance agreement and subtracting that probability.) Most kappa coefficients are somewhere between these two extremes. (Depending on the context, there can theoretically and maybe rarely practically be a -1 where the coding is totally dissimilar.)
There is not a set magnitude or threshold of kappa that has been broadly agreed on as indicating inter-rater or inter-annotator “agreement.” Different sources point to Κ = .75 - .8 to 1 as agreement, and .4 - .6 as moderate agreement.
Another source offers a table that summarizes how to interpret the Kappa coefficient. (Do note that different topical areas set the relevance threshold for "similarity" at different levels.
Regardless, the Coding Comparison tool in NVivo can offer some insights.
Conducting a Coding Comparison Query
In the NVivo ribbon, click the Query tab. In the Create section, select “Coding Comparison.” A Coding Comparison Query window will open. Click “Add to project” in order to save this macro for later similar queries. Select which users to include. Indicate where this comparison should focus—whether on a particular article or file or node or parts of the research set or the entire research project. (NVivo can go as granular as an individual file or as global as the entire research set.) Check whether the Kappa Coefficient should be displayed, and also indicate percentage agreement. (Agreement means whether the two concur on whether something should be coded or not and in what way; disagreement means whether the one codes to something that the other does not.)
When these parameters have been input, click “Run” at the bottom left.
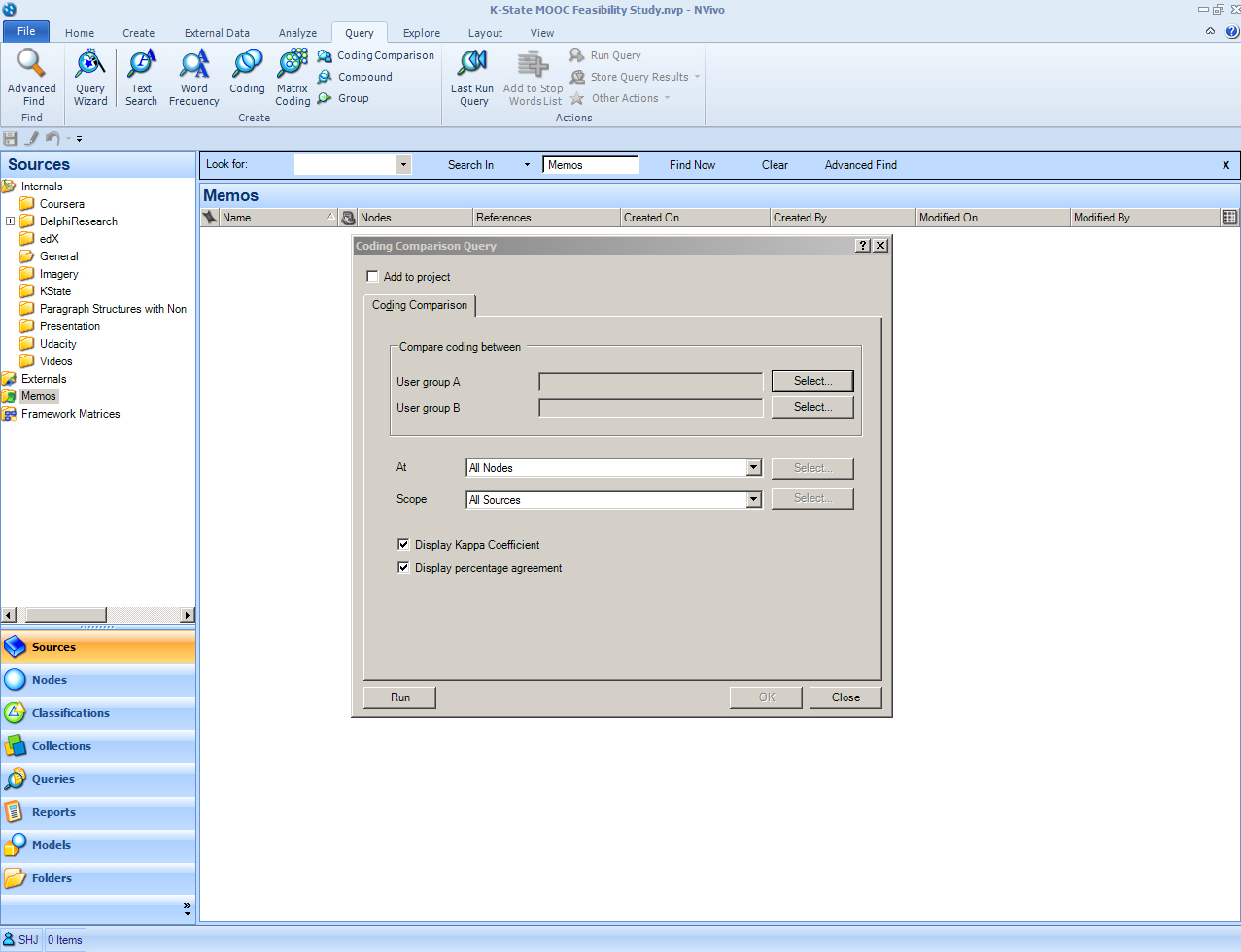{kind=link}
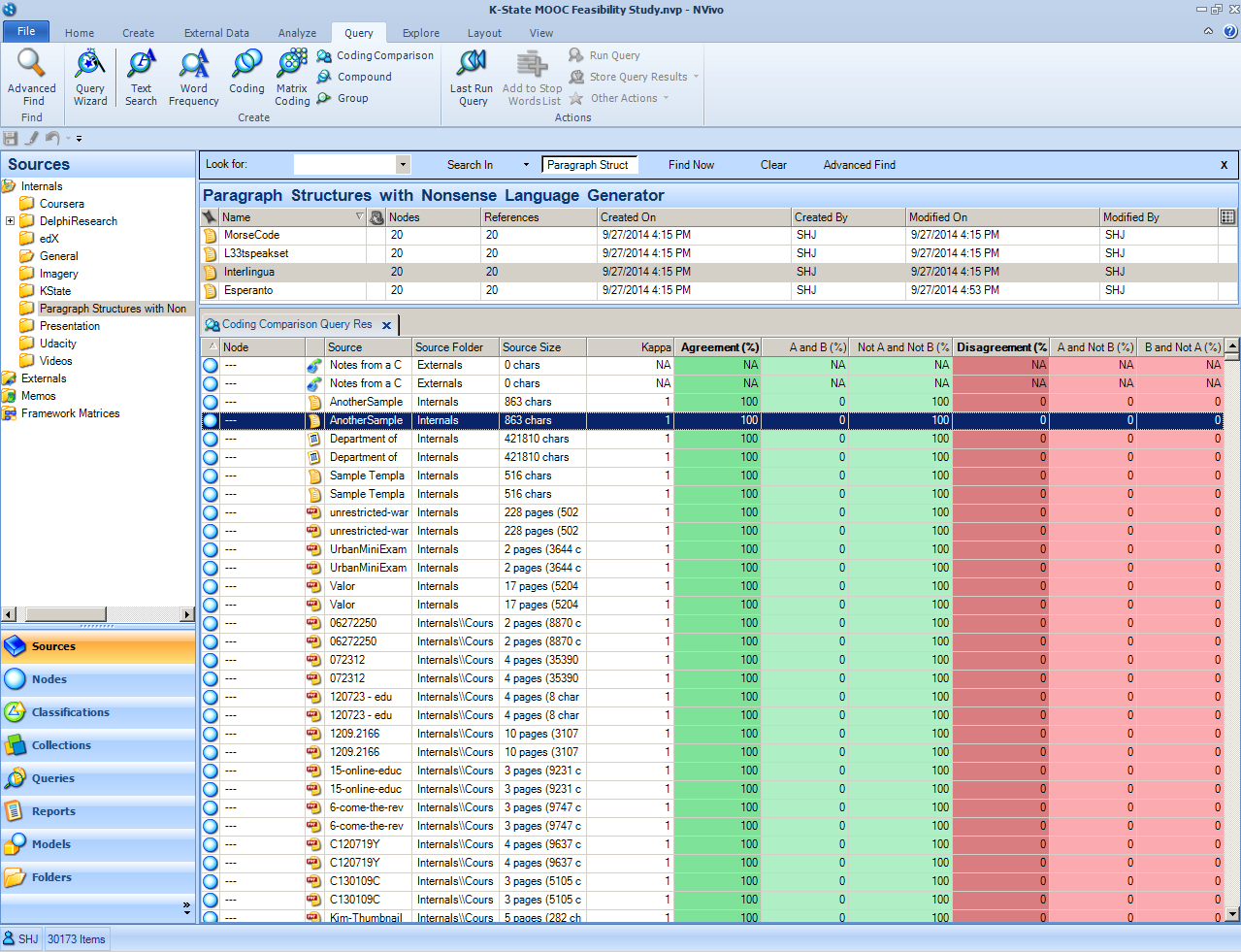
The example below is not a fair one to run because the “NVivo” (NV) coder is the software program which was trained to emulate the human coding. (Machines may emulate human coders to a full kappa coefficient of 1 even if that coding may not fully make human sense.) The “A” in this case is the human; the “B” in this case is the machine. The computer was asked to code the rest of the project beyond what the researcher had done, but in truth, all the contents had been pre-coded by the human. The column headers of this Coding Comparison Query are informative. Notice that this comparison looks at:
- points of agreement, AND
- points of disagreement
Theoretically, this could be conceptualized as a Venn Diagram with everything A coded, everything B coded, and then the overlap in these two sets.
{kind=link}
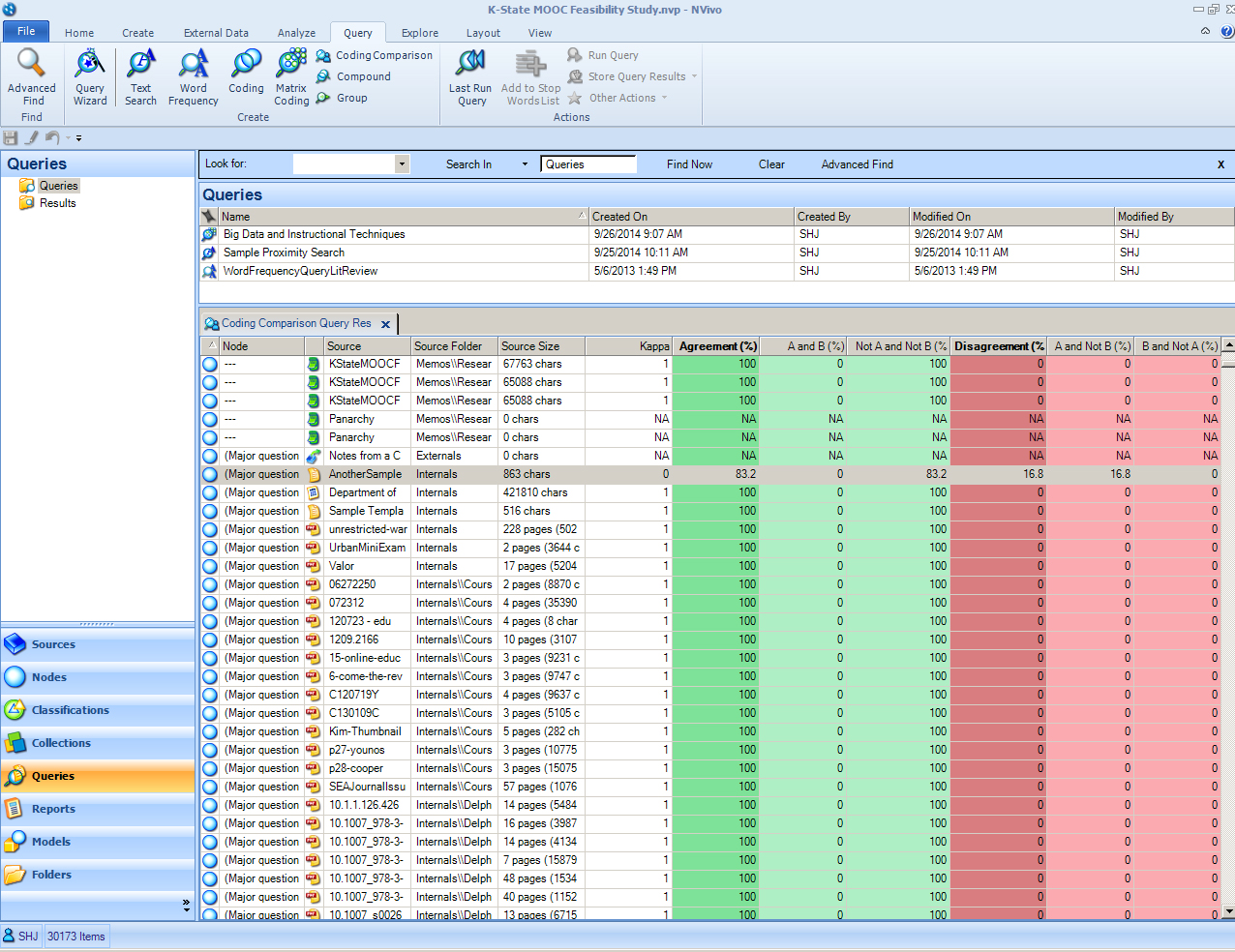
The comparison is specific and granular to particular documents. Clicking into a particular row will show the coding stripes and where there was difference. Anomalies may be explored.
{kind=link}
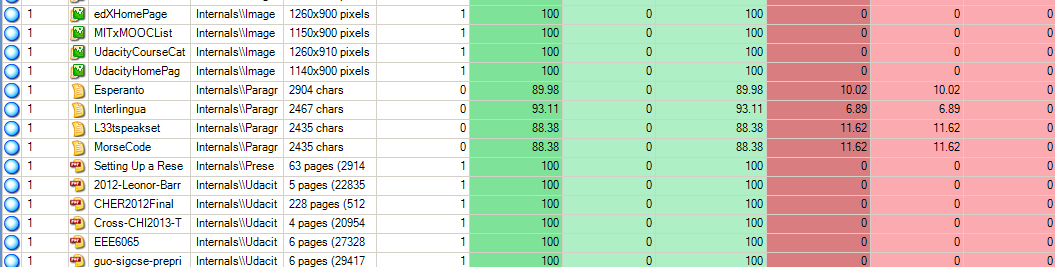
Multilingual data will not be handled as easily in terms of comparisons, or they may create their own anomalies. [This is especially if there is use of base language coding by NVivo for autocoding for topic modeling (themes and subthemes) or sentiment (positive - negative sentiment). In such cases, one "text content language" is used for the extraction, so if a project has multiple languages, the Kappa will be lower...since the computer is only using one main language for its autocoding.]
{kind=link}
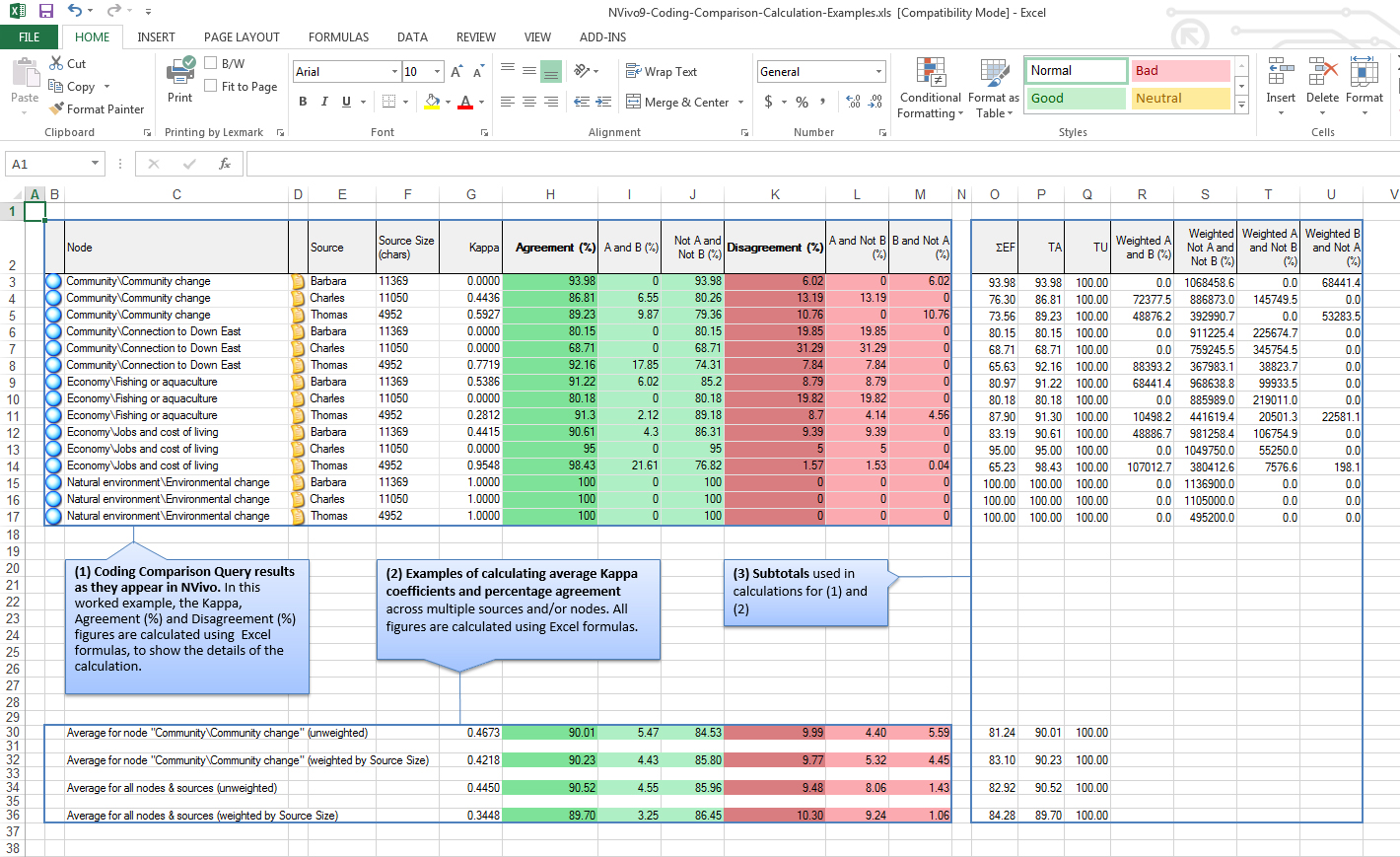
To offer a more accurate sense of a coding comparison query, the following is a screenshot of the example that QSR International has made available on its site.
{kind=link}
This Coding Comparison results in a table with both nodes and sources (depending on how the researcher set up the parameters of this Coding Comparison). In other words, it is possible to look at Kappa coefficients at each node and each source item level. Nodes, if there are no overlapping codes (e.g. A coded some text to the node, but B did not), will be at 0 (because there is no similarity between the coding behaviors of the two sides for that particular node).
Also, please note that this procedure may result in exportable data as a table. The exported table data may be analyzed in other tools, such as those that may enable more in-depth statistical analysis. .
A Summary Kappa's Coefficient: Also, the Kappa Coefficient is compared across coding nodes and individual sources. For a summary Kappa Coefficient, export the list (right-click the table and click "Export List"), and run the summary Kappa in Excel (by running an average on Column G...).
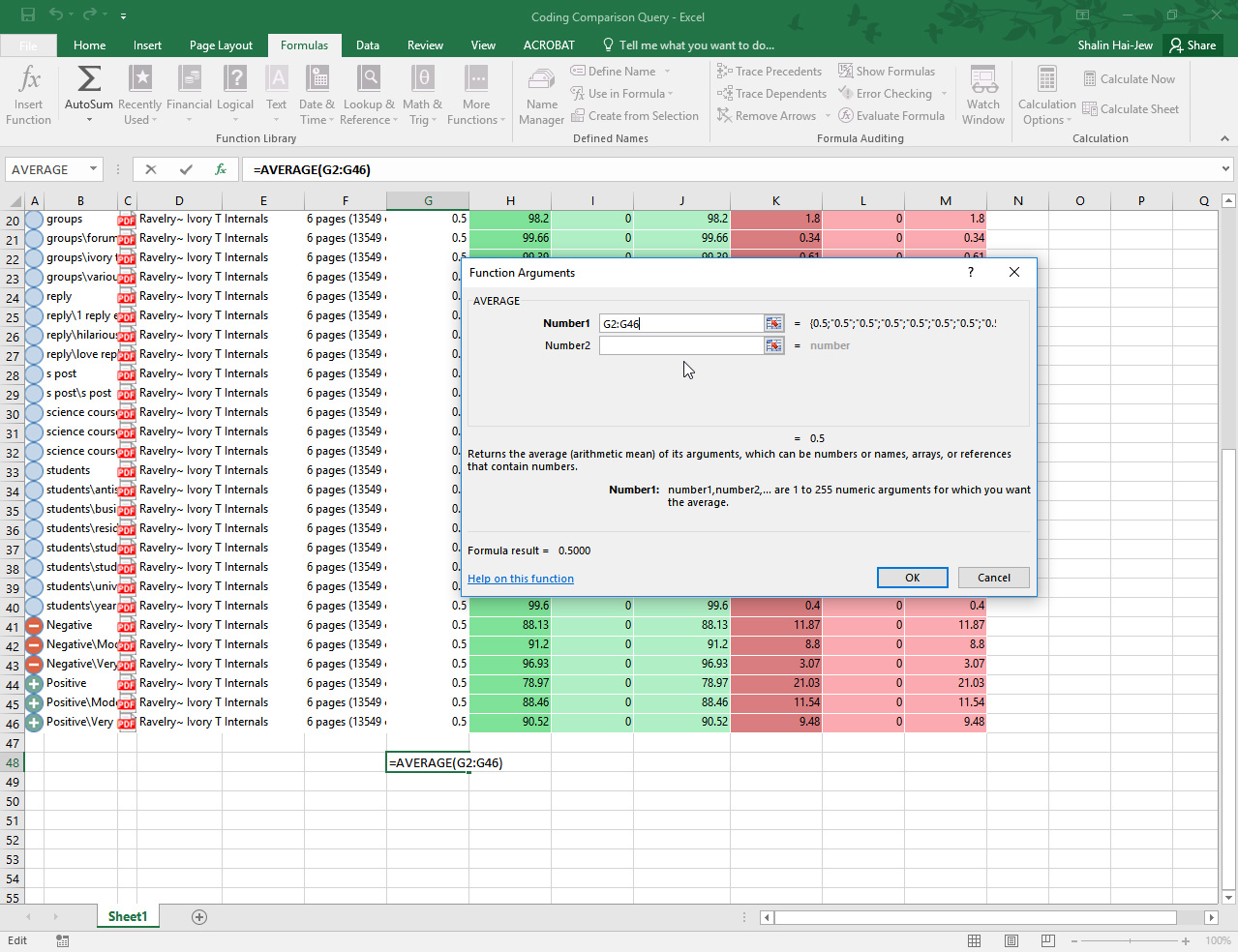{kind=link}
When Melding .nvp and .nvpx Projects
Researchers can sometimes have problems when trying to run a coding comparison across projects from different coders. Problems may be introduced when project ingestion is done incorrectly.
For example, if a master project was not created with the desired codes and labeled sources, then it is possible that each of the coders used different node naming protocols and different source naming protocols. To salvage the work, the person or team integrating the stand-alone projects will need to merge the nodes to one correct set...and delete the incorrectly named nodes. Likewise, if there were problems in the naming of sources, then that may be even more difficult because then the actual sources have to be corrected. (If this is the case, I would return back to the original coded project and re-name the sources for full alignment with the master project...before importing the project...into a master file.)
Once this norming has been correctly done, it is then possible to run a correct Coding Comparison Query...with an accurate Cohen's Kappa.
Similarity Matrix Structure
A basic similarity matrix structure follows:
Coder 1/ Coder 2 | Attribute 1 | Attribute 2 | Attribute 3 | Attribute 4 | Attribute 5 | Attribute 6 |
Attribute 1 |
|
|
|
|
|
|
Attribute 2 |
|
|
|
|
|
|
Attribute 3 |
|
|
|
|
|
|
Attribute 4 |
|
|
|
|
|
|
Attribute 5 |
|
|
|
|
|
|
Attribute 6 |
|
|
|
|
|
|
Total |
|
|
|
|
|
|
Percentage Agreement |
|
|
|
|
|
|
Some Caveats: Convergence, Divergence/Dissensus
There are some important caveats here. The Kappa number (generally conceptualized on a scale of -1 to +1) is affected by the underlying dataset. If there are a large number of coding nodes, and the data is highly noisy and complex, the Kappa could be much lower than in a project in which the coding nodes are fewer and a dataset which is simpler. This is the reason why many researchers argue that you cannot compare Cohen's Kappa across datasets unless they are somehow "similar". With qualitative, mixed methods, and multi-methodology types of datasets, comparability of datasets is an even more difficult problem.
Also, if team coding is applied in an exploratory way by research team members with individually very different objectives and skillsets and backgrounds, low Kappa would likely be desirable to capture coding divergence, dissensus, and non-agreement. There are times when it is beneficial to have a broad range of understandings when approaching a project. For example, if a team is building a consensus codebook in a bottom-up coding way using a wide range of contents, divergent coding (and initial dissensus) may enable the collection of a wide range of concepts for the codebook. (The assumption here is that the node structure set up in the NVivo project used is broad and general to be inclusive of the wide range of interpretations.) Having a myopic and limited codebook would be a limitation to the project.
{kind=link}
Finally, the coding comparison here evokes something of multi-coder co-orientation towards a particular topic. There is a co-orientation research model from the 1970s.
Also, note how visuals make data relationships feel intuitive. (Lots of practice in using and viewing these data visualizations may improve analytical depth.)
Discussion of "Data Query: Coding Comparison (Advanced) and Cohen's Kappa Coefficient"
Add your voice to this discussion.
Checking your signed in status ...