Manual Coding in NVivo
Before looking at coding in NVivo, it helps to address a few assumptions. In all qualitative research, the work involves some airing out of assumptions early on. That seems like a useful practice even for a simple primer. The assumption for coding is that the researcher has a clear and close attention to words and word meanings (including nuances and inflections) during the research and data analysis. To this end, it may help to bring this issue of language-based semantic (meaning-bearing) concepts to the fore first.
{kind=link}
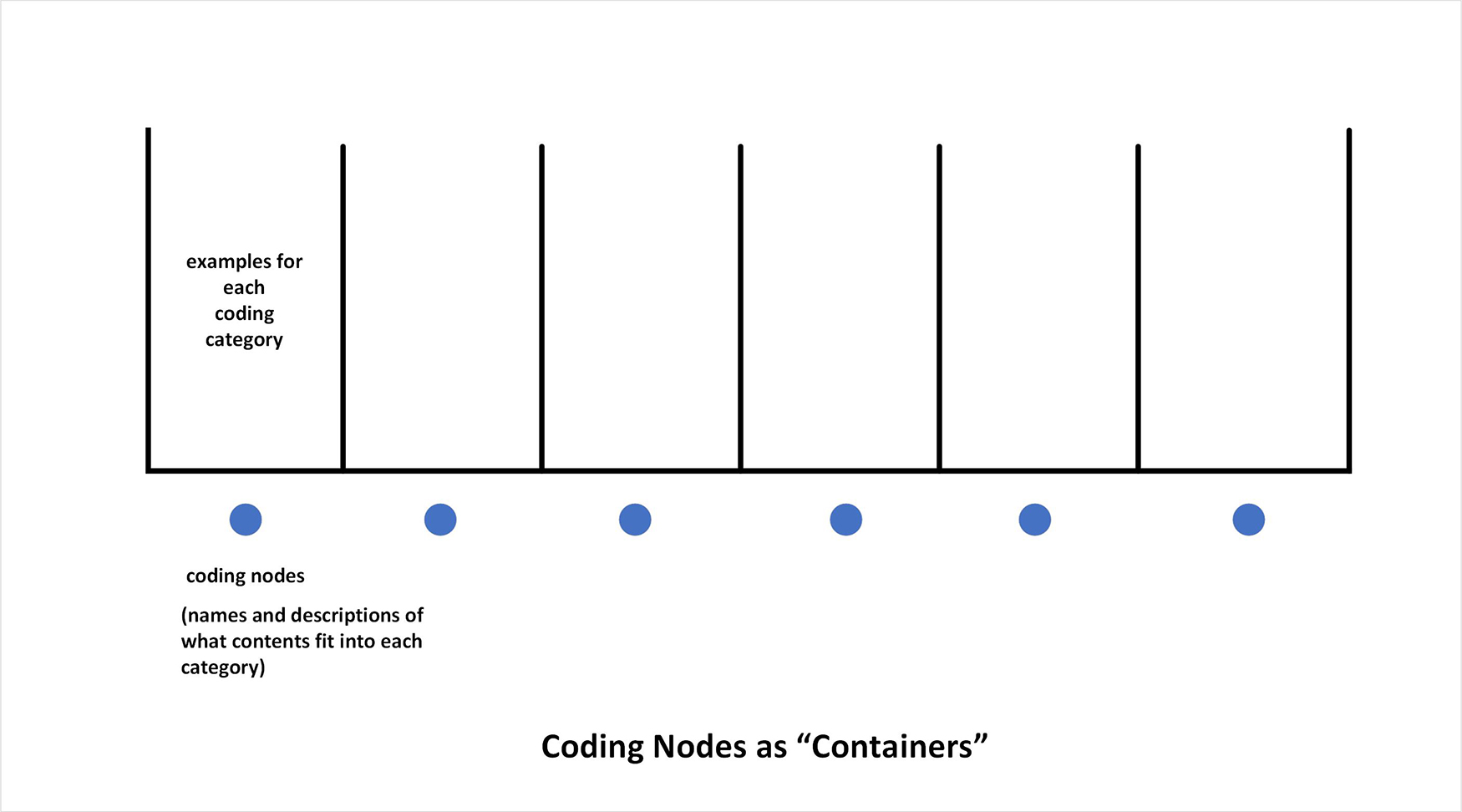
It also helps to consider what coding is in a very generic and general sense. Coding may be the creation of categories of information and emplacing examples into each category (as words, phrases, sentences, and paragraphs).
{kind=link}
In terms of categories, they may be impermeable, or they may be porous, in terms of separations between categories.
Also, there may be sub-categories, sub-sub-categories, and so on (which are not depicted here).
Aligning with Research Methods
and Domain-Specific Professional Values and Practices
"A code in qualitative inquiry is most often a word or short phrase that symbolically assigns a summative, salient, essence-capturing, and / or evocative attribute for a portion of language-based or visual data...In qualitative data analysis, a code is a researcher-generated construct that symbolizes and thus attributes interpreted meaning to each individual datum for later purposes of pattern detection, categorization, theory building, and other analytic processes," writes Johnny Saldaña in The Coding Manual for Qualitative Researchers (2nd Ed., 2013, pp. 3 and 4). M.B. Miles, A. M. Huberan, and J. Saldaña, in Qualitative Data Analysis (3rd Ed., 2014), describe a variety of coding types: descriptive, in vivo, process, emotion, values, evaluation, dramaturgical, holistic, provisional, hypothesis, protocol, causation, attribute, magnitude, subcoding, and simultaneous (pp. 74 - 81); multiple types may be applied simultaneously. The listing--which is not particularly comprehensive--may offer ideas for approaches to coding.
Beyond these general observations, there are a number of additional considerations depending on the research domain. How coding is done changes also with the length of the project--whether it is cross-sectional or longitudinal. The type of information handled also affects the coding; for example, multimedia data are analyzed differently than, say, interview data. Researchers differentiate between a priori or pre-defined coding schemes (based on a conceptual framework, for example) and those that are emergent and evolving (based on "grounded theory," for example) and inductive data analysis. A more colloquial reference is that a priori coding is "top-down," and emergent coding is "bottom-up."
Grounded theory is often used for the creation of new theoretical insights and for the creation of novel codebooks. Top-down coding is often to use an existing theoretical framework or model to address particular hypotheses.
In a sense, coding continues throughout the research. Precoding involves the collection of continuing observations and jotting of ideas even before the primary research has been conducted. The idea here is that the researcher is jotting down potential words of interest and themes early on even before the formal data analysis stage. He or she or they are marking up texts with ideas even as they are thinking about possible research. Precoding work will inform the more formal coding work when that phase is reached. Coding, for many, is a continuous and cumulative process.
Researchers who are engaging in mixed methods work--often including survey data--have to consider a range of other coding considerations, including a raft of basic statistical methods related to research. [Arlene Fink's How to Conduct Surveys: A Step-by-Step Guide (2013) offers a helpful and simple overview of both parametric and non-parametric approaches related to the analysis of survey results. She also provides a helpful approach to firming up survey research design and creation, along with testing the survey instrument. Richard A. Krueger and Mary Anne Casey's Focus Groups: A Practical Guide for Applied Research (4th Ed.) highlights practical fundamental considerations for using focus groups for a number of social, professional, and research contexts.]
Defining Terminology
The defining of terms (words, phrases, concepts) is a critical part of qualitative and mixed methods research. Before a term is used, a researcher often has to conduct thorough research and either use a definition from the research literature or else something he or she has created [in (dis)alignment with the prior research]. In this sense, it is a good idea to have a clear initial sense of a word's definition. As the coding and analysis proceed, word definitions may evolve; it is critical to capture those new understandings and to record those.
In the same way, there is a fair amount of defining of what various codes mean. The definitions of codes (as categories) will change based on the examples that are included in that particular code grouping. The named code at a particular node may evolve and change to more accurately reflect the contents of that coding category.
In the same way, there is a fair amount of defining of what various codes mean. The definitions of codes (as categories) will change based on the examples that are included in that particular code grouping. The named code at a particular node may evolve and change to more accurately reflect the contents of that coding category.
It may be helpful to have a folder which contains initial terms and their respective definitions (with examples). Over the course of the research and analyses, a researcher or researcher team may return to the folder and revisit terminology--to see if understandings have evolved, and if so, how, and what the implications may be of those changes for the particular research.
Coining new terms
Coining new terms
Since academic researchers sometimes like to "coin" new terms and phrases, it is important to do a full scour of the literature to ensure that no one else has already captured the meaning of the new term in another way or with similar phrasing. The basic rules of the academic "game" for coining new terms is to be first (no points for second), original, insightful, precise, and accurate (to the world). Another rule of the game is that if others can find precursor terms, they will call out the researcher for hubris, arrogance, and a lack of thoroughness.
Coding @ Nodes (in NVivo)
{kind=link}
In general, no two researchers would necessarily code the same data the same way because of the differences in perspectives, experiences, personalities, and training (the different subjectivities of the researchers). Even research teams that are closely trained the same way will have variances in how they code and what they see as relevant. (Inter-rater reliability has to be fairly high for a team to do its work, but oftentimes, fresh insights come from points of disagreement and differences in perspectives. In some cases, teams are designed to be heterogeneous and to surface divergent insights; in such contexts, the inter-rater reliability coefficient--a similarity measure--is not desired.)
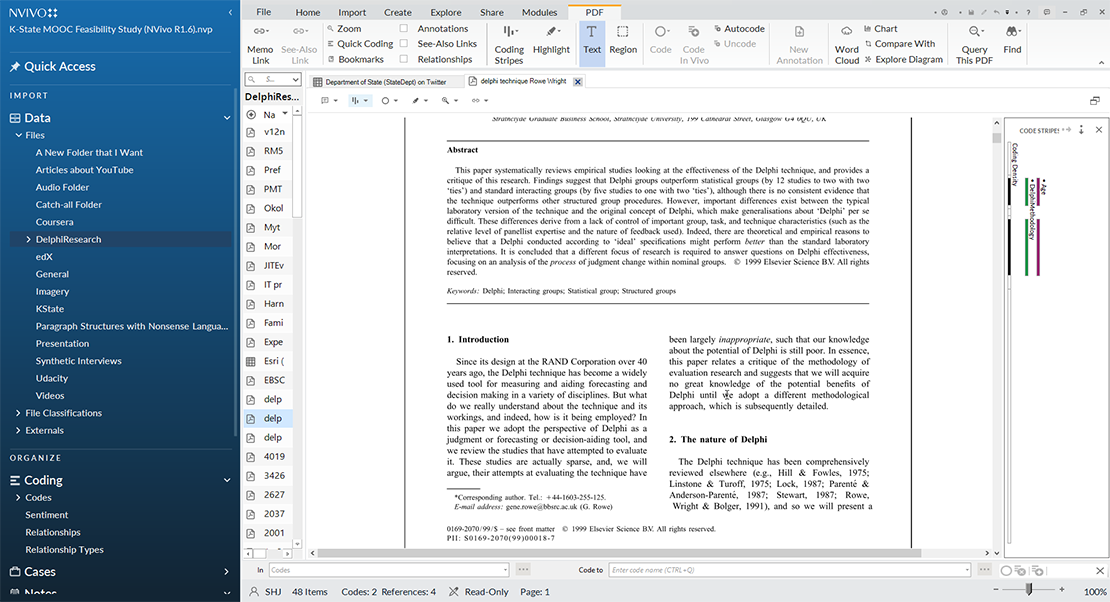
In NVivo, researchers code the concepts to “nodes.” These are indicated by round blue-filled circles. In the sources folders, researchers access the various files (documents, images, audio, video, data sets, and other file types), and they highlight texts that they find relevant by linking them to particular categorical or other types of nodes. Sub-nodes may be used for "subcoding" of second-order codes. NVivo enables the visualizing of nodes in a variety of ways, including a tree structure with nested nodes.
The coding function is the main (non-automated) affordance of NVivo for researchers. Some researchers use this tool only for manual coding, and these may never use the machine-analysis aspects of NVivo. There are many appropriate ways to use NVivo based on context and researcher preferences.
Unit of coding
The highlighted sections may be particular words, phrases, sentences, or paragraphs—based on the lengths of the concepts that the researcher finds relevant. If the size is too atomistic or granular, the concept may be too focused; if the size of the cited text is too broad, the coding may be too broadscale and too inclusive of multiple concepts to be useful. It may take several attempts in order to find a comfort zone for coding. When researchers name “nodes” to which various highlighted texts are coded, the node naming may enhance the quality of the coding (because there is an interdependency between the naming of the node and the contents that are coded to that node). The “unit of analysis” may be considered the node level.
How to think about nodes
One of the more elusive aspects to nodes involves how to conceptualize them. One common approach is to think of nodes as categories within which certain concepts may be placed. These categories may or may not be mutually exclusive. Some researchers may build up a coding structure in which information may only fit into one node category, in which case the categories are mutually exclusive. Other researchers may prefer to use a coding structure in which information may be coded to multiple nodes simultaneously, in which case the nodes are not mutually exclusive. A category is a grouping of similar or related objects, and as such, it is a generalized or broad set (with cases or exemplars within each category).
Essentially, coding involves the extraction of information and researcher sense-making. This enables “data reduction” and “data summary” in order to understand the relevance of the collected information.
In this software program, when a user clicks on a node, he or she will see all content coded to that node. All highlighted citations are coded under particular nodes, which enable the collation of related information. Also, he or she will be able to navigate directly to the source by double-clicking the link to that highlighted section in a source. Also, a researcher may view the coding stripes to the right side of a source to see all the coding linked to a particular source. Coding stripes may also be double-clicked in order to highlight its referent text in the Detail View.
In this software program, when a user clicks on a node, he or she will see all content coded to that node. All highlighted citations are coded under particular nodes, which enable the collation of related information. Also, he or she will be able to navigate directly to the source by double-clicking the link to that highlighted section in a source. Also, a researcher may view the coding stripes to the right side of a source to see all the coding linked to a particular source. Coding stripes may also be double-clicked in order to highlight its referent text in the Detail View.
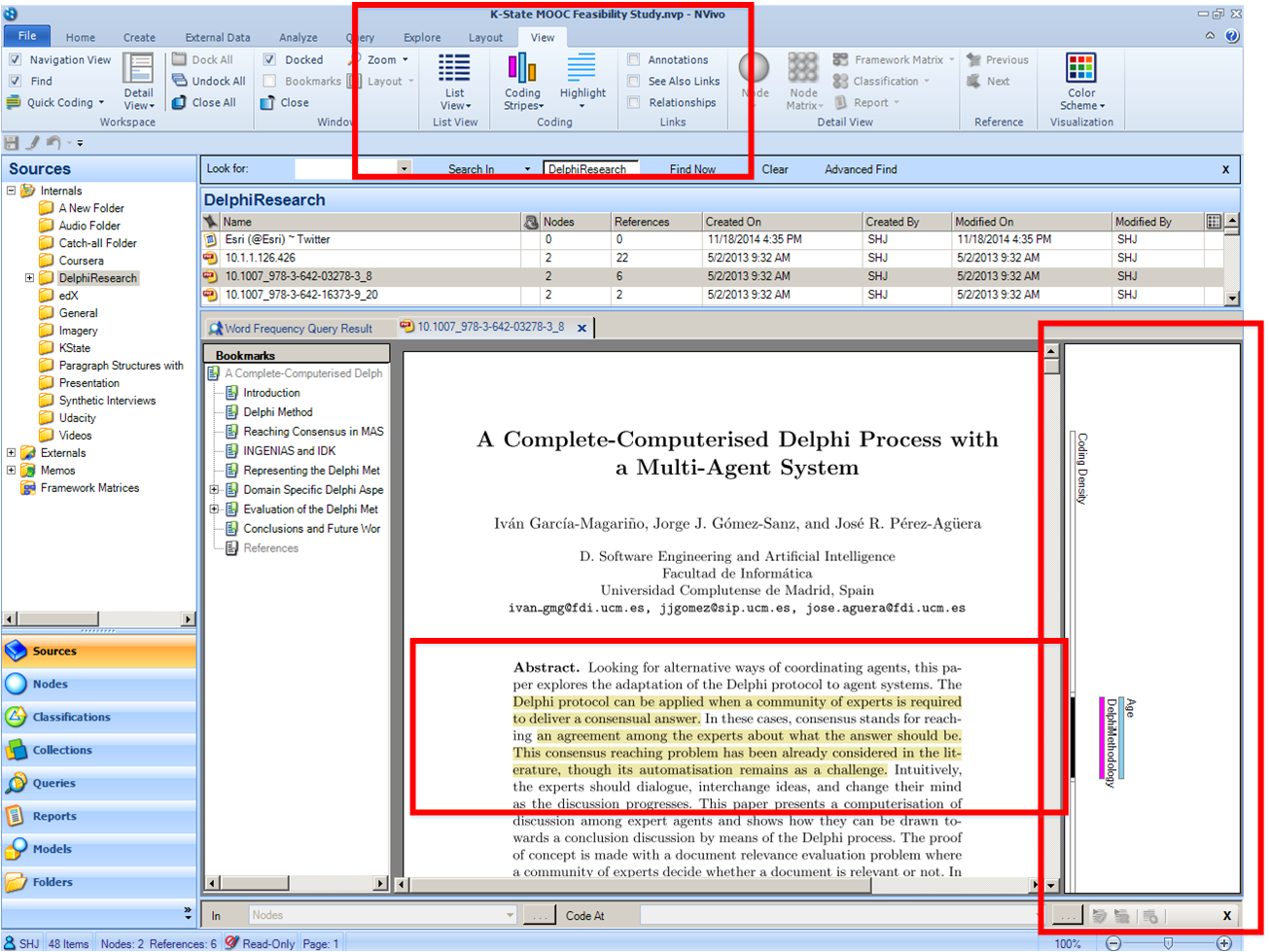{kind=link}
In the context of coding visuals, a researcher may indicate a portion of a photo or figure for coding and type the relevant information in reference to that section of the visual. In the context of audio or video files, a researcher may place a playhead at a certain location on the waveform (visualization of the sound) or the video timeline and input text relevant to that time…or he or she may highlight sections of a transcript for coding.
Another way to use nodes is by highlighting particular interview / survey / e-Delphi study respondent attributes or characteristics to certain nodes, so that their responses may be collated by these attributes [gender, socioeconomic status (SES), location, age group, or other factor] in order to identify themes across respondent characteristics through matrix coding queries. This is achieved by naming column headers based on respondent characteristics and ingesting those datasets or .xl worksheets with the attribute data as particular nodes.
Ultimately, the completed coding will be extractable as a structure of interrelated nodes. This structure may be viewed textually and spatially (in a 2D or 3D way). If the original collected information may be considered raw data, the nodes are processed data that have been analyzed and vetted by the human researchers (sometimes aided also by computerized support). The nodes are the extracted network of abstracted concepts extracted from the data.
Within the Nodes space, researchers may create various folder structures to organize the nodes. The nodes themselves may also be structured in (great- great-...) grandparent-parent-child and other structured hierarchies. By default, NVivo alphabetizes nodes at each folder level. NVivo itself does not force any lock-in to the coding or the node structures; nodes are eminently editable.
While it is assumed that a researcher or research team will use a number of coding approaches over time—and based on new information and new insights—it is advisable to preserve nodes and sources even if researchers think that they went down a wrong path or that certain sources are not relevant. It is advisable to have a catch-all folder for “discarded” concepts, nodes, and sources—so that work is not just deleted. Everything that is deleted in NVivo should be considered a “hard delete,” which means that it is irretrievable. (Ctrl + Z does work a few steps in to “undo” some actions. However, once a project is saved with the changes, there is no going back.)
Coding is often non-linear and recursive, rarely if ever linear. Researchers may review their work and realize that what seemed like a dead-end or “stub” should actually be developed further and revisited. This is why it it smarter to take a preservationist approach to the work.
For long-term projects, it may be important to "fix" snapshots of the various codebooks over time. For example, some projects may involve various cohorts of individuals assessed year-over-year for decades. Certainly, additions may be made to the original codebook, and the new coding may be applied retroactively to the prior data. Or spinoff work may require new codebooks to be applied to the collected data.
To summarize, coding then involves the act of researcher sense-making for data reduction and simplification. Coding nodes (categories) enable the collation of related data as concepts or types of phenomena. Within NVivo, these nodes may be placed in matrices for matrix coding queries. Nodes may also be used for text queries (like word or phrase frequency counts, text searches, and others). Nodes may also be used to create node structures and spatial visualizations, which show hierarchical or associational or other relationships between nodes (as phenomena or as concepts). Finally, nodes may be extracted as “codebooks.” Researchers are able to see what codes they used and how these codes inter-relate.
Coding across page break metadata in PDF files
There was a recent query about coding across page breaks in .PDF (portable document format) files. Is there a way to get rid of the header/footer metadata that exists across some PDF files at the page breaks while coding? There are a few possible workarounds.
Another way to use nodes is by highlighting particular interview / survey / e-Delphi study respondent attributes or characteristics to certain nodes, so that their responses may be collated by these attributes [gender, socioeconomic status (SES), location, age group, or other factor] in order to identify themes across respondent characteristics through matrix coding queries. This is achieved by naming column headers based on respondent characteristics and ingesting those datasets or .xl worksheets with the attribute data as particular nodes.
Respondent responses may also be coded to certain nodes based on “autocoding” based on data ingestion. Here, interviews, surveys, observations, Delphi studies, and other research with textual responses may have the questions highlighted with certain headers (like Header 1) and the responses highlighted with certain paragraph or body text styles and ingested into NVivo…which may be set up to automatically code the questions into one set and the answers into another set. This enables the collation of all responses to particular questions to be able to be called up as one group of data for in-depth topical analysis.
Autocoding by machine emulation of human coded patterning option
If a researcher wants, he or she may code a percentage of the contents (at least 10% in the examples given by QSR International) and then enable machine-coding that emulates the human-coding. He or she may then go back and see what information was coded by “NV” and decide whether to accept that coding or not. In other words, there is human oversight over every aspect of the work…even that achieved by the computer. (In such cases, the human has to have created the full codebook already and offered sufficient coded examples for each of the nodes. "NV" or "NVivo" will not create new nodes in this case.)
Researchers may right click on a node and link that node to a memo to add more information (beyond Node Properties). A “memo” is a document that is created within NVivo. Memo-ing (what some call "jotting") enables on-the-fly commenting as well as the collection of cumulative memos for deeper understandings. On a team, memos may be used to surface insights about the research and may be used to hone the research process.
Linking to Memos
Researchers may right click on a node and link that node to a memo to add more information (beyond Node Properties). A “memo” is a document that is created within NVivo. Memo-ing (what some call "jotting") enables on-the-fly commenting as well as the collection of cumulative memos for deeper understandings. On a team, memos may be used to surface insights about the research and may be used to hone the research process.
Memos are exportable, and they are importable...to respective NVivo projects.
Uses of the Completed Coding
Ultimately, the completed coding will be extractable as a structure of interrelated nodes. This structure may be viewed textually and spatially (in a 2D or 3D way). If the original collected information may be considered raw data, the nodes are processed data that have been analyzed and vetted by the human researchers (sometimes aided also by computerized support). The nodes are the extracted network of abstracted concepts extracted from the data.
Within the Nodes space, researchers may create various folder structures to organize the nodes. The nodes themselves may also be structured in (great- great-...) grandparent-parent-child and other structured hierarchies. By default, NVivo alphabetizes nodes at each folder level. NVivo itself does not force any lock-in to the coding or the node structures; nodes are eminently editable.
{kind=link}
About codes and mysteries
Sometimes, there is a cultural fetish about codes: secrecy. Some researchers will try to "one-up" others by showing off their own access to "secret" sub rosa knowledge. A whole lot of codes--think social codes, computer codes, and symbolic codes (languages, maths, etc.), and others--are very much public and open, and they have to be to enable people to collaborate. A secret code unto itself (without the communications function) is gibberish. In terms of coding for qualitative and mixed methods research, the "coding" is generally public, transparent, well-defined, and optimally illuminating. A failure to define the coding is a failure of the research. Any "mystery" should be in the unexplored parts of the domain being explored. While there is not a direct tie between "reproducible" quantitative data analysis and pseudo-reproducible qualitative or mixed methods data analysis, the need to document the steps to data processing is still applicable. These described steps help readers and other researchers evaluate and understand the work. While cases are unique, the abstracted patterns found in qualitative research may be applied in other contexts, so there is always some transferability of the research findings.
So as not to be absolutist, this is not to say that all codebooks always have to be released with all research. Even a cursory perusal of the academic research literature shows that codebook releases are not common. However, the researcher and / or research team itself should have clear definitions. If a codebook is to be shared, its elements should be as explicitly defined as possible.
Preservation of Coding and Sources
While it is assumed that a researcher or research team will use a number of coding approaches over time—and based on new information and new insights—it is advisable to preserve nodes and sources even if researchers think that they went down a wrong path or that certain sources are not relevant. It is advisable to have a catch-all folder for “discarded” concepts, nodes, and sources—so that work is not just deleted. Everything that is deleted in NVivo should be considered a “hard delete,” which means that it is irretrievable. (Ctrl + Z does work a few steps in to “undo” some actions. However, once a project is saved with the changes, there is no going back.)
Coding is often non-linear and recursive, rarely if ever linear. Researchers may review their work and realize that what seemed like a dead-end or “stub” should actually be developed further and revisited. This is why it it smarter to take a preservationist approach to the work.
For long-term projects, it may be important to "fix" snapshots of the various codebooks over time. For example, some projects may involve various cohorts of individuals assessed year-over-year for decades. Certainly, additions may be made to the original codebook, and the new coding may be applied retroactively to the prior data. Or spinoff work may require new codebooks to be applied to the collected data.
Summary
To summarize, coding then involves the act of researcher sense-making for data reduction and simplification. Coding nodes (categories) enable the collation of related data as concepts or types of phenomena. Within NVivo, these nodes may be placed in matrices for matrix coding queries. Nodes may also be used for text queries (like word or phrase frequency counts, text searches, and others). Nodes may also be used to create node structures and spatial visualizations, which show hierarchical or associational or other relationships between nodes (as phenomena or as concepts). Finally, nodes may be extracted as “codebooks.” Researchers are able to see what codes they used and how these codes inter-relate.
Some Smaller Points and Work-Arounds
Coding across page break metadata in PDF files
There was a recent query about coding across page breaks in .PDF (portable document format) files. Is there a way to get rid of the header/footer metadata that exists across some PDF files at the page breaks while coding? There are a few possible workarounds.
1) Re-output the PDF file as a .doc, .docx, .txt, or .rtf, and manually omit the between-page data. Re-ingest into NVivo and code. (If the original file in the project is removed, all the codes that were linked to that project also disappear, so be careful about deleting source files.)
2) In the PDF file, use a rectangle object to redact the between-page information. Then, ingest the PDF file into the project. Code, and the redacted information should not show.
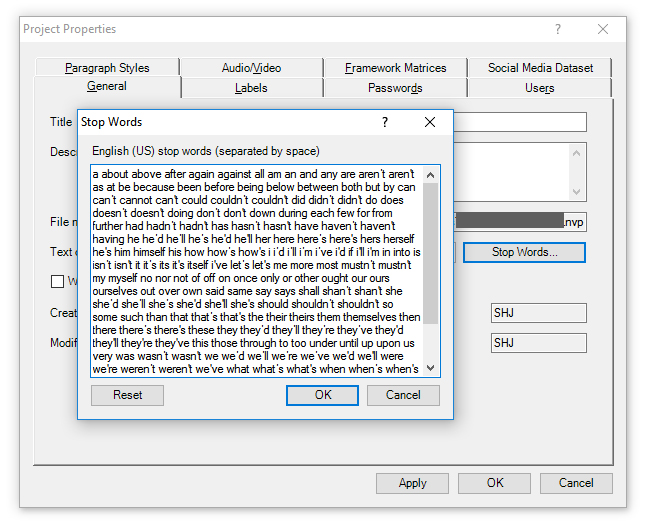
3) In the global level Stop Words List (for the .nvp or .nvpx project), put the in-between page text into the stop words...but be careful not to accidentally stop other words or numbers that may be relevant. For this, go to Files -> Project Properties -> Stop Words ... and add the text to stop coding or recognition of those terms in data queries.
{kind=link}
Discussion of "Manual Coding in NVivo"
Add your voice to this discussion.
Checking your signed in status ...