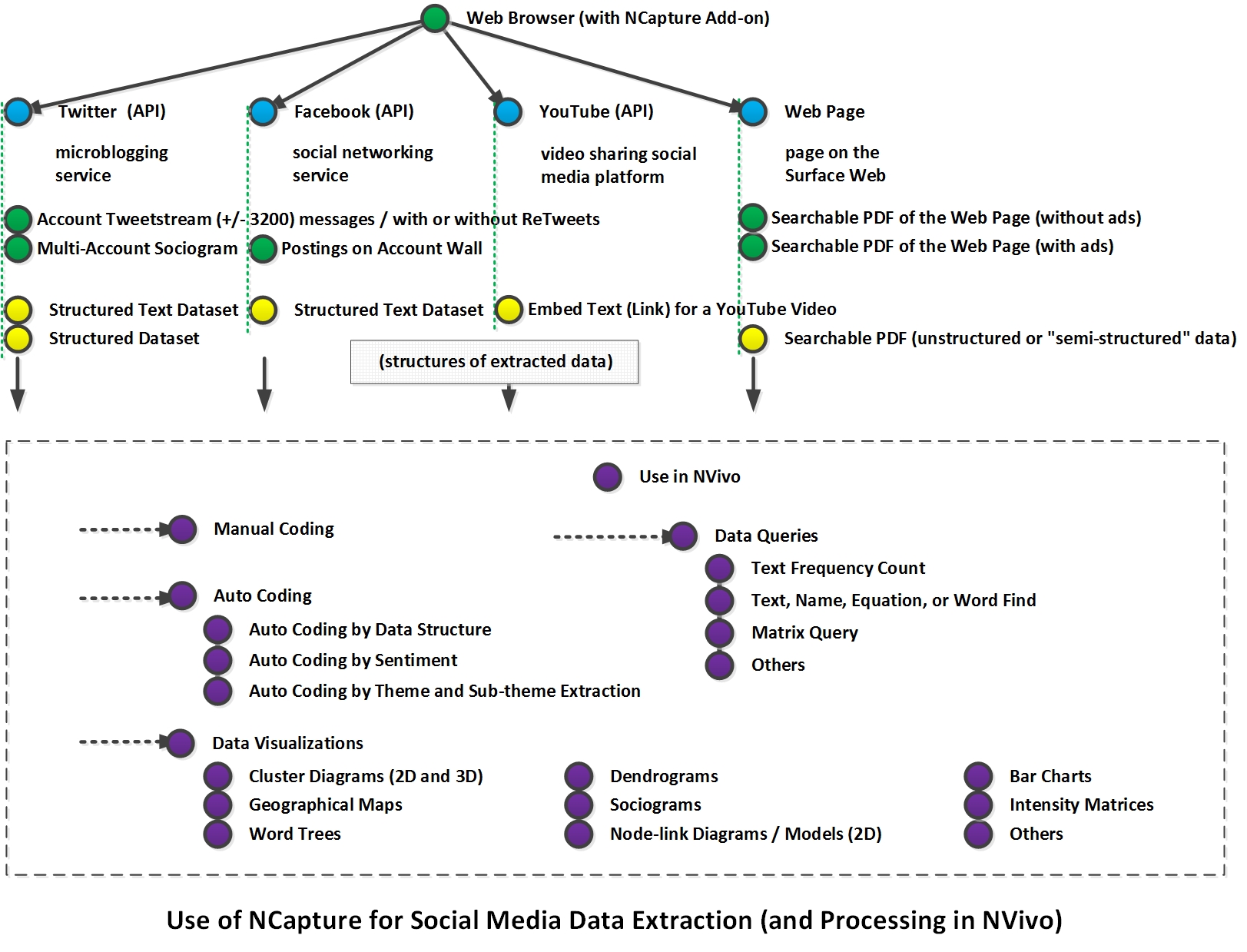
NCapture and the Web, Twitter/X, YouTube, and Other Social Media
* The NCapture web browser add-on on Google Chrome works on the Twitter (X) microblogging site currently. It only works on some aspects of YouTube (it does not seem to be able to scrape comment data from the targeted videos). The add-on does not work on Facebook. [There are other ways to extract the same data using other approaches. All general approaches do require validated accounts on the respective platforms--except for commercial access to full datasets of N=all, but these are relatively expensive.]
Extracting social media data is always partial and limited using NCapture. Given that it is a moving target, developers have to constantly update the app through the web browser, and the dependencies may be too difficult to set up.
As one of the leading qualitative and mixed methods data analysis tools on the market (if not the leading one), NVivo is a tool that has integrated a range of functionalities made possible by other software programs or online tools. It has also moved to capitalize on the copious amounts of publicly available information on the Web and Internet, and social media platforms.
{kind=link}
The NCapture Web Browser Plug-in
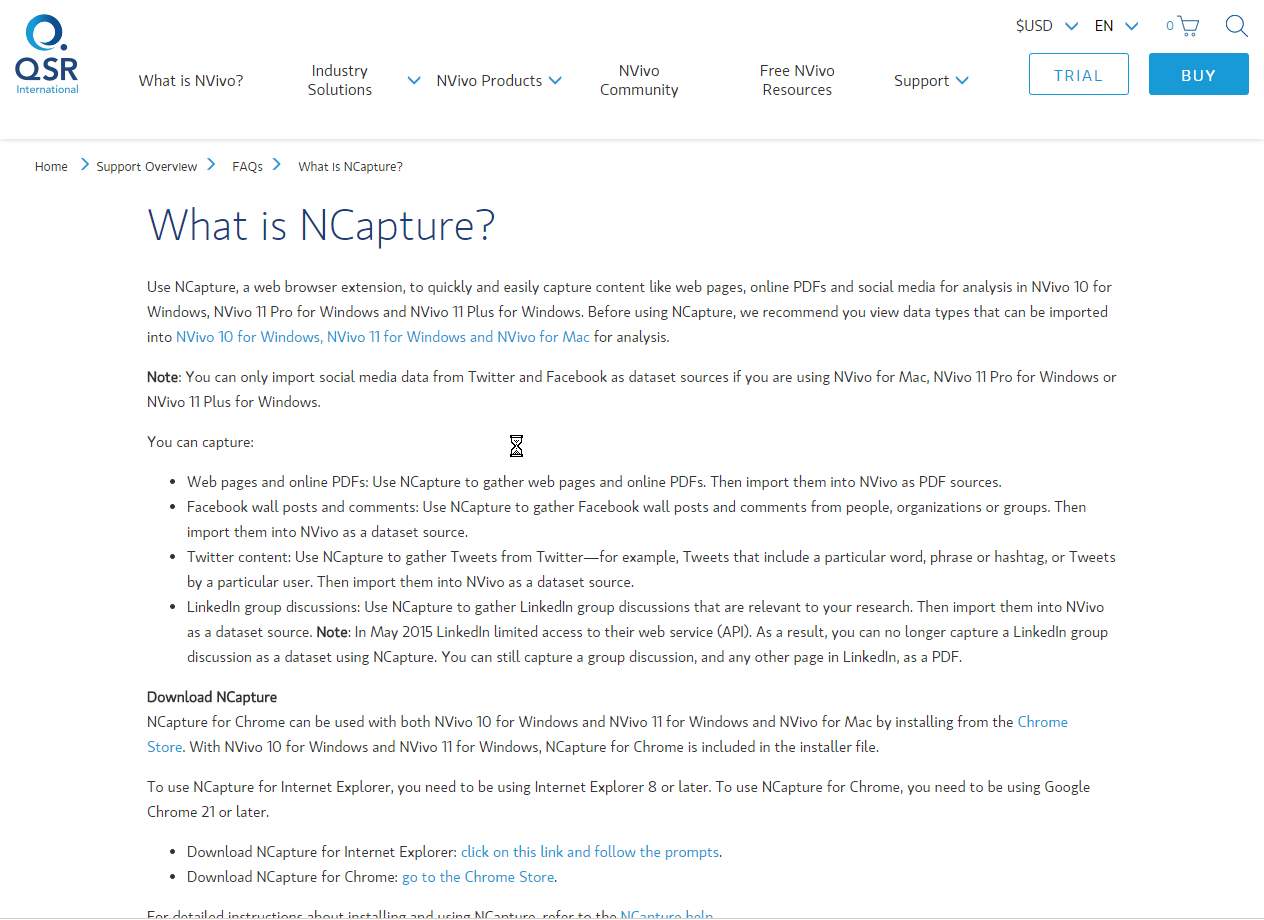
NCapture, a plug-in to the Internet Explorer and Google Chrome web browsers, enables the extracting of data from the Surface Web and various online social media platforms. The extracted data is easily ingested into an NVivo project for coding and analysis. With the retiring of IE, however, neither Facebook nor Twitter work with IE. To access either platform using NCapture, users must use the Google Chrome web browser.
(The main social media platforms that may be accessed currently are Twitter or X and Facebook. The social media platforms generally have to have an application programming interface or "API" that developers may use to develop tools to access the social media platforms' data layer. Some will require authentication in order to access the data, so the service providers may rate-limit and somewhat control access to their data. The availability of various platforms varies with the changes made by the respective platforms. LinkedIn is not working now for data scraping with NCapture now.)
If this was not downloaded and installed early on, it may still be added by going to QSR International’s download site for NVivo 10 for Windows add-ons. There is a version available for Macs that have the Google Chrome browser installed. There is a dedicated page for NCapture downloads.
{kind=link}
A General Overview of the Sequence
The sequence generally goes as follows:
- Using either Google Chrome or Internet Explorer (IE) web browsers (with the NCapture add-on downloaded and installed), the researcher surfs to the desired website.
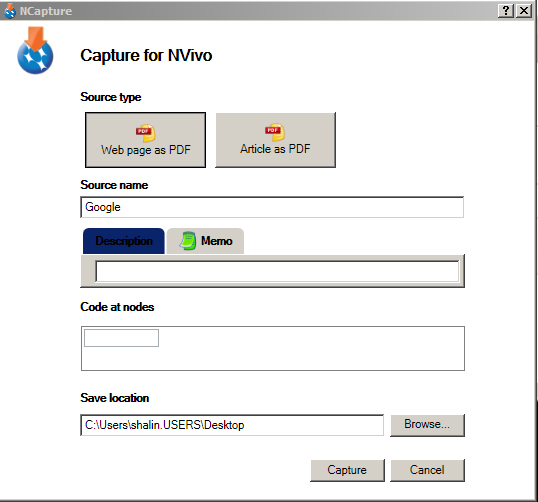
- The user clicks on the NCapture icon.
- He or she (they) decides on whether to do a full page capture with ads included or just acquire the article. He or she (they) can decide what to name the source and how to code this source (to a particular node). [Any sites captured as a page will retain their clickable links.]
- He or she (they) may also choose to add an annotation to this source.
- Then, the researcher clicks Capture.
- The file is then downloaded and saved to a location on the computer.
- The researcher then has to open the proper NVivo project for the captured file. He or she goes to the ribbon and the External Data tab - > From Other Sources -> From NCapture.
- At this time, he or she (they) will be directed to the captures and may choose to ingest some or all of those captures into the project.
- Once that import is done, the online information has been integrated with the project.
- If a particular account is being “monitored” using this tool, it is possible to update matching social media datasets by having the new information integrated (during this ingestion process).
General Workflow Sequences
Surface Web
The Surface Web is the web that is broadly accessible using a web browser. This Web consists of interconnected pages as indicated by the uniform resource locators (URLs) which point to web pages: http... These pages are hosted on web servers (computers) connected to the Internet. People have been able to extract data from web pages...and a variety of other means, including mapping http networks (the networks of interconnected websites and pages), document networks, social media account networks, and others. (These advanced sorts of queries are done with other tools than NVivo.)
{kind=link}
The Surface Web is the web that is broadly accessible using a web browser. This Web consists of interconnected pages as indicated by the uniform resource locators (URLs) which point to web pages: http... These pages are hosted on web servers (computers) connected to the Internet. People have been able to extract data from web pages...and a variety of other means, including mapping http networks (the networks of interconnected websites and pages), document networks, social media account networks, and others. (These advanced sorts of queries are done with other tools than NVivo.)
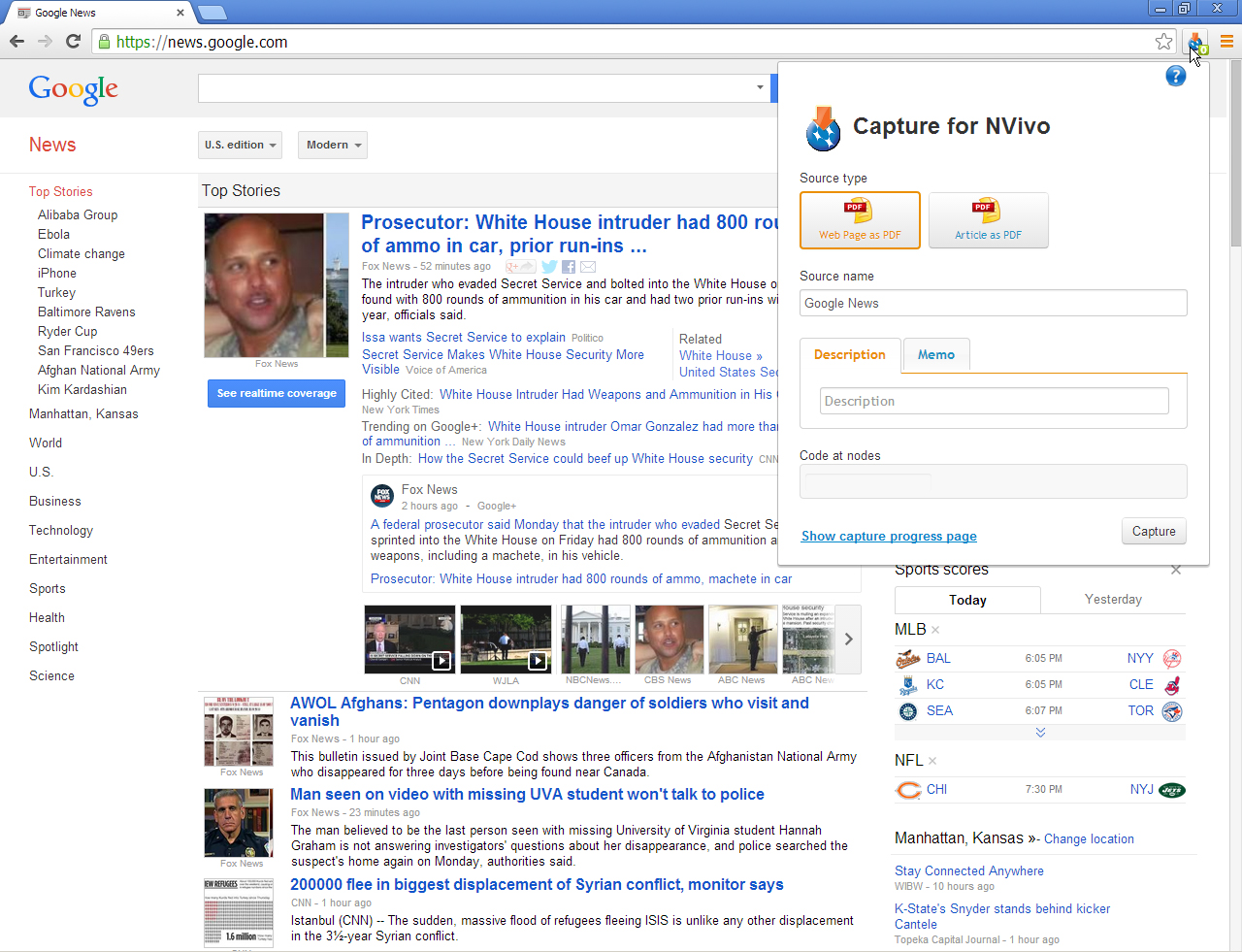
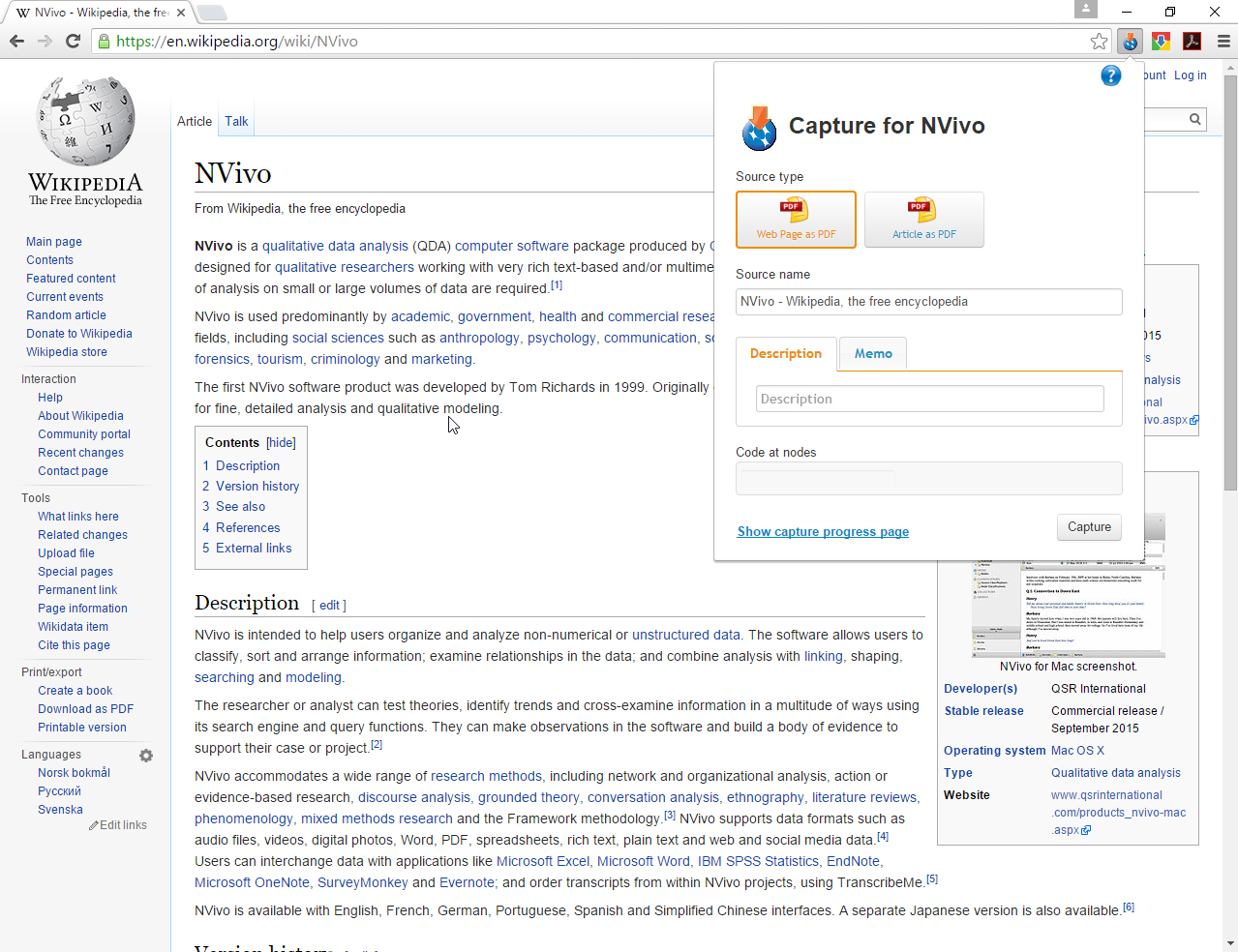
A general extraction from the Web may be achieved with NCapture. NCapture appears in the upper menu bar on browsers and is indicated by an orange down arrow overlaid on a round blue icon.
{kind=link}
On a website, the web page may be downloaded as a PDF (portable document format) file with advertisements intact, or it may be downloaded with only the article extracted. The downloaded file is searchable (screen reader readable) and codable (as-is all other similarly collected files).
To achieve this, a researcher surfs over to the desired page (maybe with the help of a search engine). He or she clicks on the NCapture button. He or she selects "Web Page as PDF" or "Article as PDF." The "Web Page as PDF" captures the page and all side matter, including ads and side contents. The "Article as PDF" captures only the main feature piece.
{kind=link}
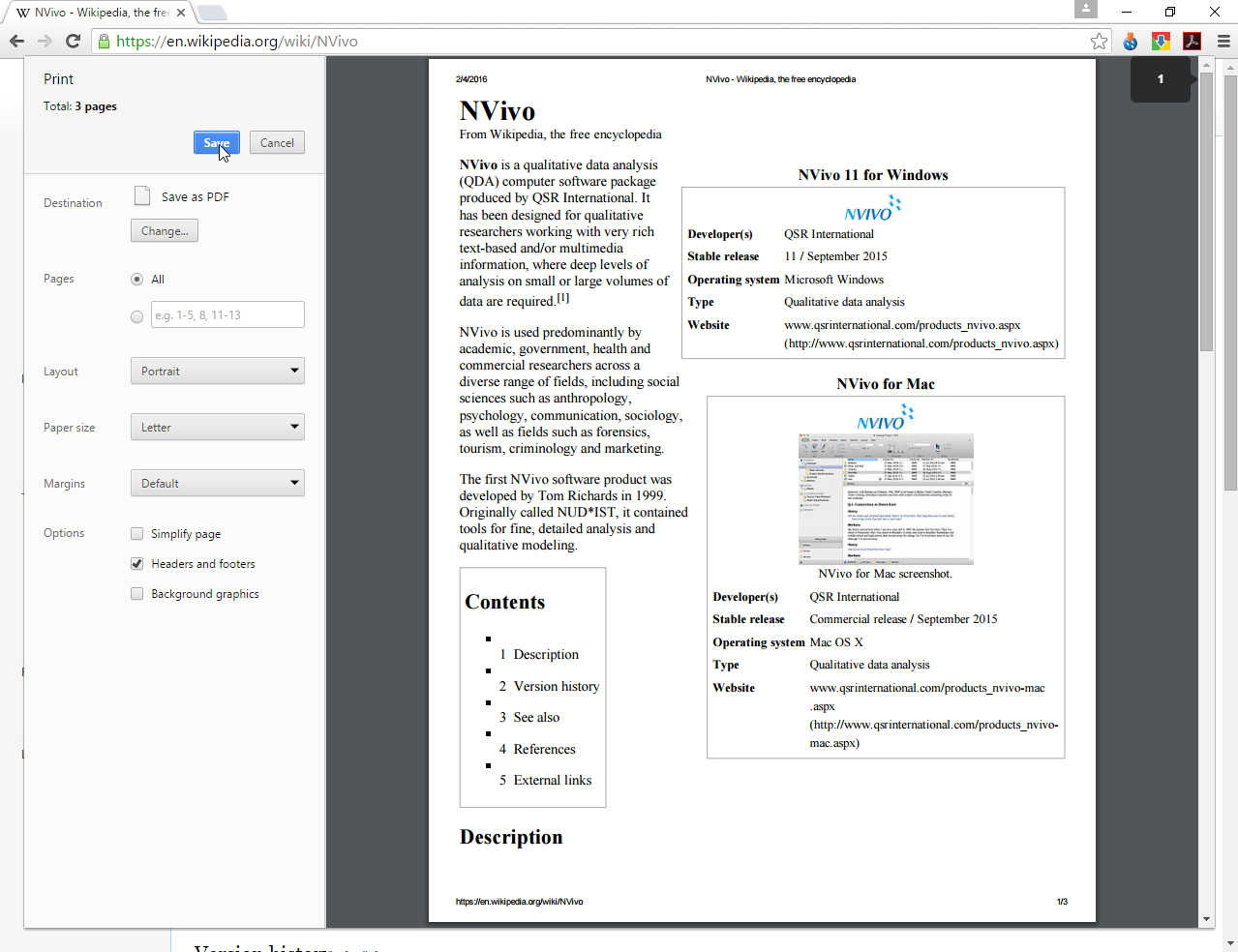
Caveat. In most cases, instead of using NCapture to invest contents, it is generally better to surf to the web page, CTRL + S (save) the web page as a PDF, and then upload the page into NVivo from Data tab -> PDFs, etc. Or, based on other settings, this might be better with CTRL + P (print) to print the web page as a PDF, and then upload the page into NVivo. Going the NCapture route results in much larger files, and these can gum up the project (which has a 10 GB size limit on local computers). The less the size of the data, the more nimble your computer will be in analyzing the data...and the more data it can handle.
{kind=link}
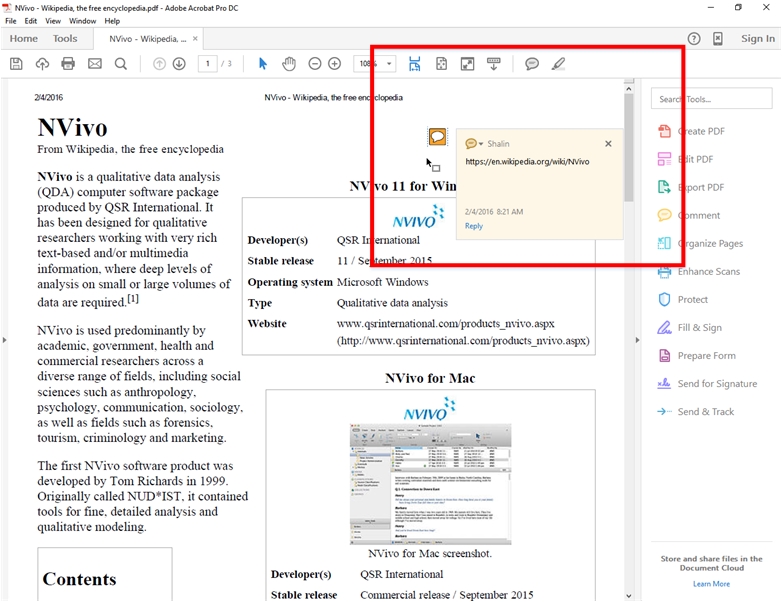
Make sure to eyeball the capture first. Some PDF printers capture only part of a web page, and some also have poor difficult-to-read layout. Make sure that the name of the PDF capture is informative and readable before saving. After saving, one additional piece of information should be added to the document. It may help to capture the web page address / URL and right click on the PDF and add a sticky note with the URL. The URL is not usually captured as part of a print PDF function right from the browser. In research, if a web page is used, the URL is sometimes required as part of the bibliographic citation.
{kind=link}
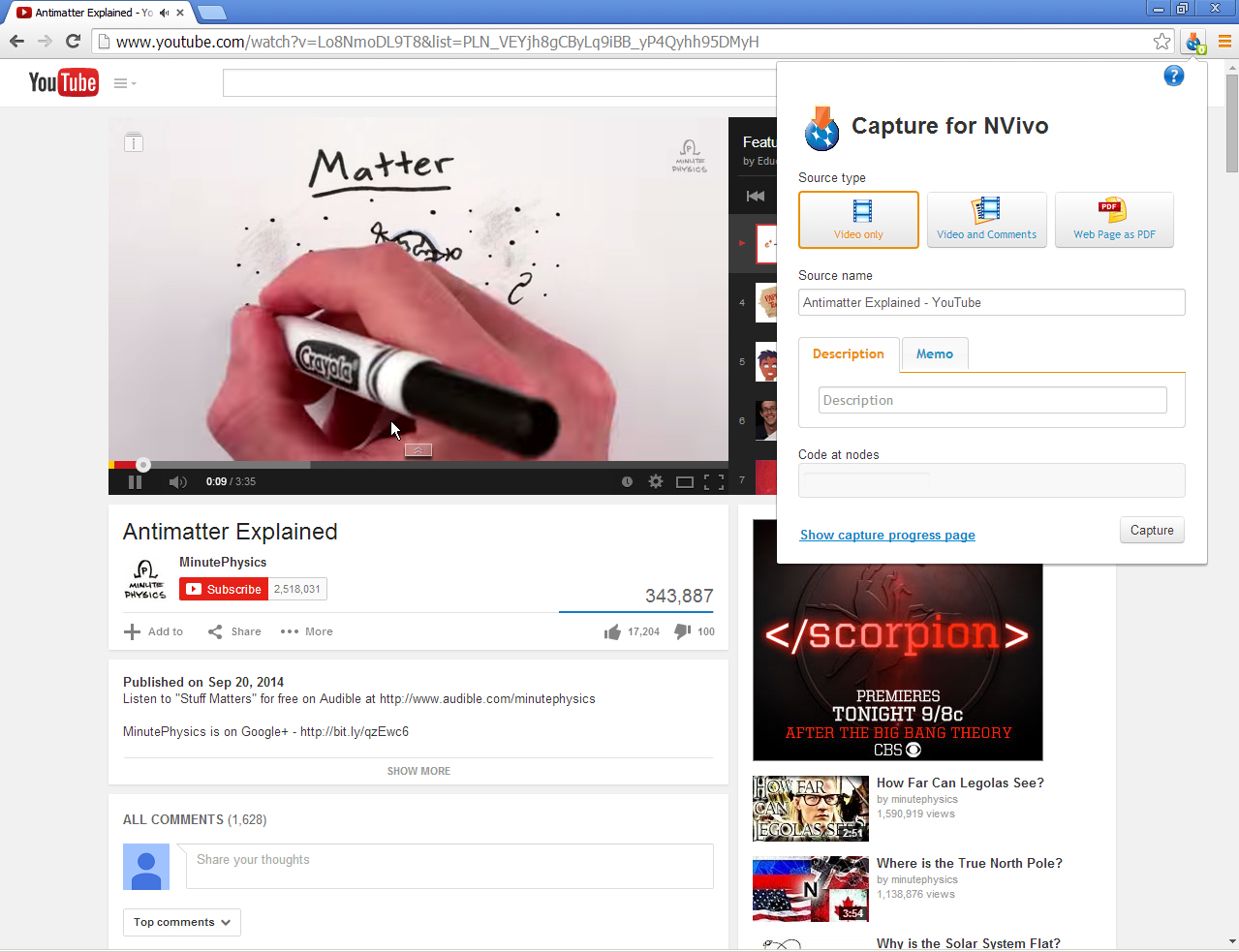
YouTube (acquiring links to videos, acquiring transcripts, and acquiring comments)
{kind=link}
To acquire a link to a YouTube video, proceed to the YouTube site. Find the desired video. Click on the NCapture icon. Select the terms of the link acquisition, and insert the proper labels and textual information. Proceed with the acquisition. Then, ingest the link into the project.
(Linking to video vs. downloading the video: When embedding video, the video itself is not downloaded; rather, NVivo enables an embed link to the YouTube video. If the video were removed from YouTube, the link would not go to any destination. If the researcher really needs a protected copy of the video, he or she can generally quite easily find a freeware tool that enables the download and saving of a video from YouTube...or, in a clumsier and more effort-ful way, to use a screen capture tool to capture a video as it is playing.)
The YouTube video will open in the video folder and will be annotatable based on the placement of the playhead. Again, NVivo does not enable coding by visuals, audio, or videos—only by text. If the video is going to be analyzed in a highly granular way, then a whole verbatim text-transcript should be done, so it is wholly searchable and analyzable and codable. If the video is used in a broad way, then some time-based annotations and maybe some notes may suffice. How the video is treated is in the researcher’s purview.
Google enables access to transcripts on videos with closed captioning. These include any video on their platform in any language. Go to the video. At the bottom, there should be a "cc" button indicator. Click the "..." ellipses at the bottom right under the video screen. Select "Open transcript." Copy the transcript into a file (.txt, .rtf, .docx, or other such file type). Save the file. Load the file into NVivo for analytic inclusion. [Note, some transcripts are autocoded ones using the AI capabilities of Google. Others are human-edited transcripts. The difference should be fairly clear when viewing the respective transcripts. Optimally, the transcripts are accurate. In some cases, they may be enriched with additional non-auditory information.]
The latest form of NCapture enables the pulling of "comments" from the respective videos as well.
To capture the transcripts from videos with cc (closed captioning), you can acquire these from the "open transcript" from the ellipses at the bottom of the video.
Social Networking Site
First, make sure that all the contents in the social networking site is fully loaded (and the indicator in the web browser is not still spinning).
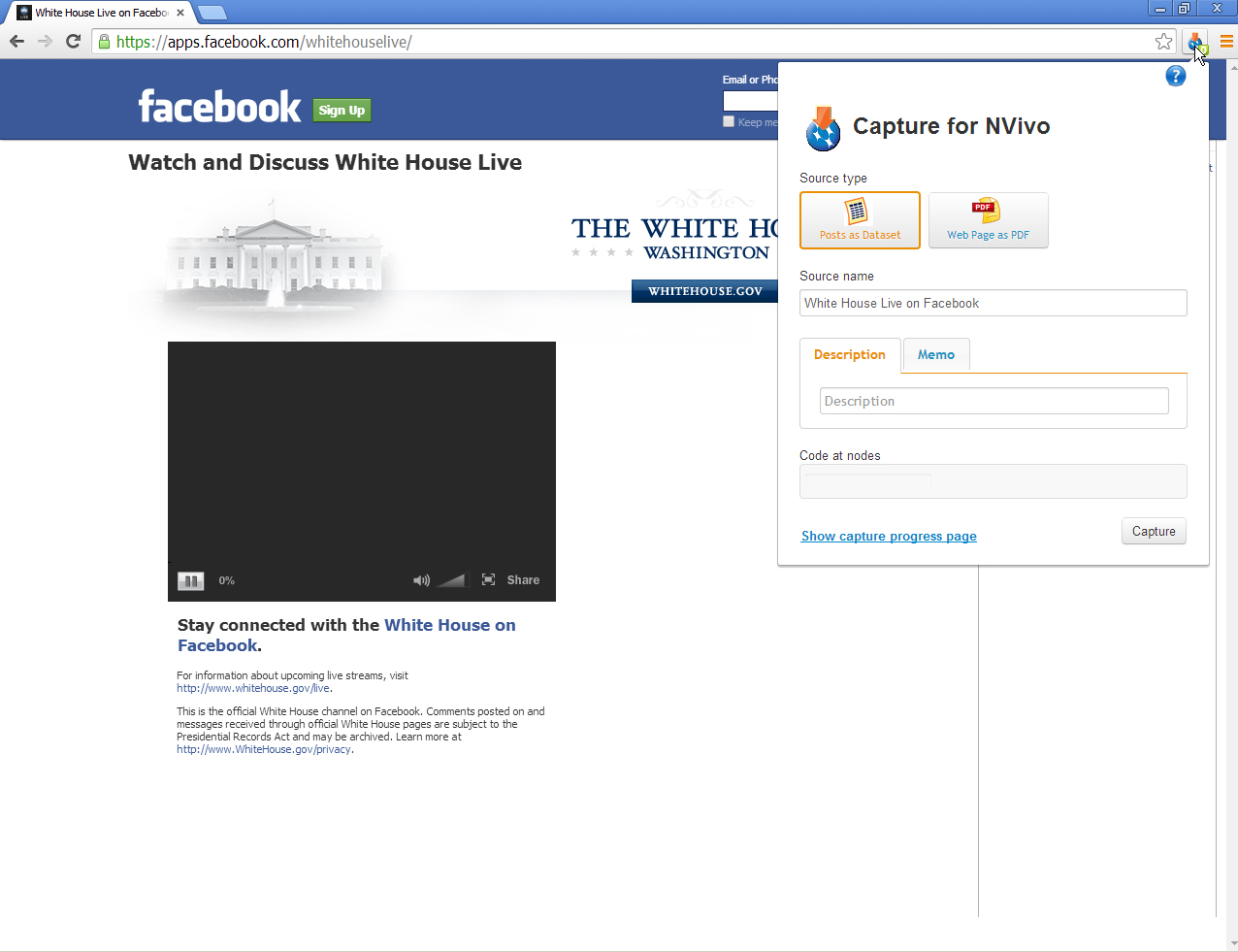{kind=link}
To extract data from Facebook, go to a particular account on Facebook (not the generic top level). Decide whether the posts to the site should be downloaded as a dataset or whether the web page itself is of interest. Input the requisite information for how this extracted data should be treated inside NVivo. Download the data. Open NVivo. Import the data.
{kind=link}
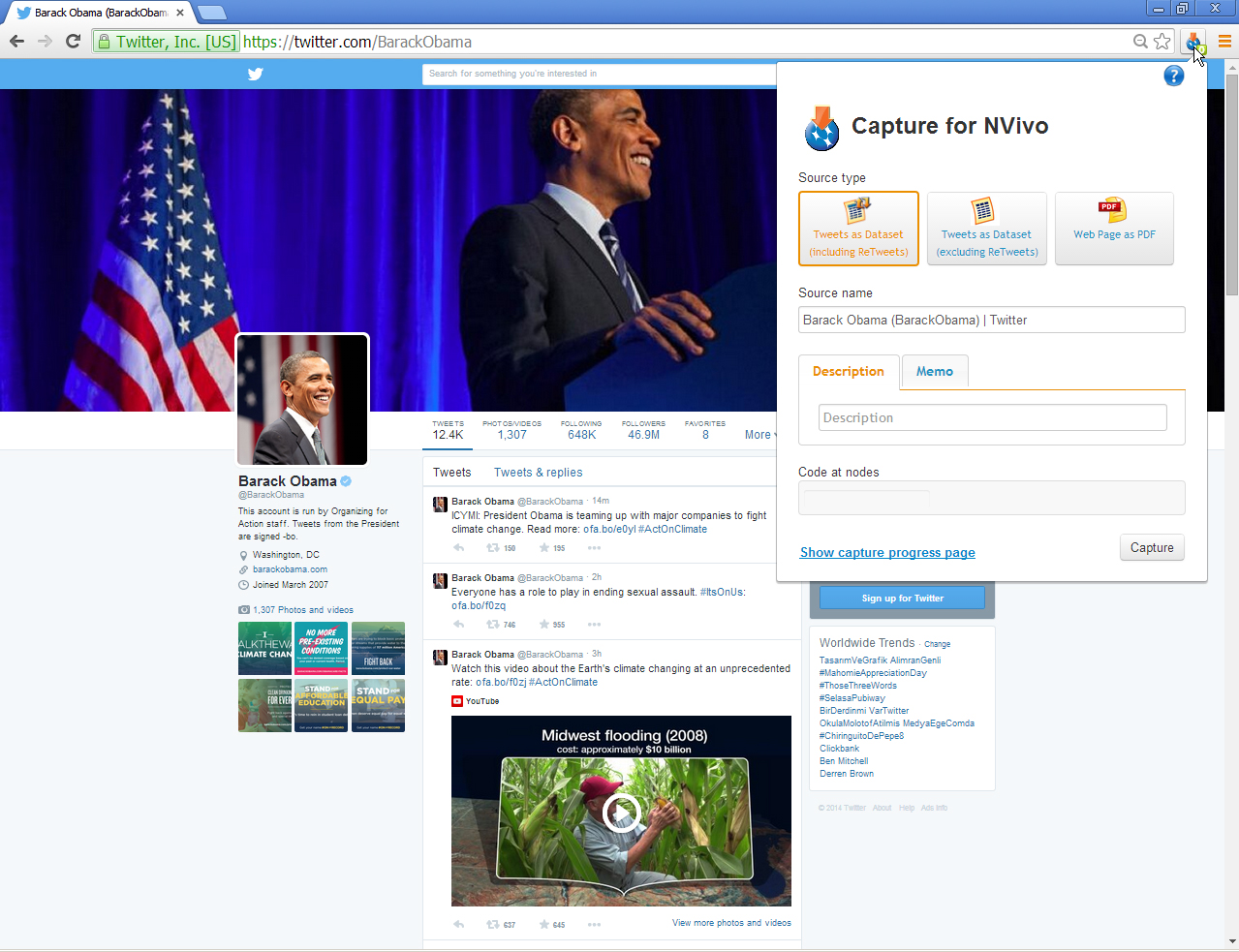
Finally, NCapture may also be used to extract microblogging messages from a Twitter account’s Tweetstream (known as a user stream) or even from a #hashtag conversation on Twitter. A Tweetstream is a collection of messaging around a particular @user account on Twitter, and it goes back in time. Approximately 3,200+ total messages (of one account) may be captured based on the Twitter API. In terms of #hashtag conversations, those collect ad hoc discussions around a labeled topic, and the Twitter API for these only goes back about a week. Those who want full datasets will have to go through a commercial vendor (Gnip). The #hashtag search captures a small percentage of the most recent Tweets with the designated #hashtagged label. The data is time-limited cross-sectional semi-synchronous data; other tools enable the capture of "continuous" data (but still not the full set given the Twitter API limits).
Basically, go to the particular page on Twitter. Decide whether you want to extract Tweets as a dataset (instead of just capturing the web page as a .pdf). Define the parameters of the data extraction, such as whether you want to include retweets in the dataset or not. Include the information for how NVivo should ingest the data. Download the dataset. Open NVivo. Ingest the extracted information.
Processing a Twitter Dataset using the Autocoding Wizard
Once the dataset of Tweets has been uploaded (whether as an NCapture set or from some other capturing source), click on it to activate options to process it in NVivo.
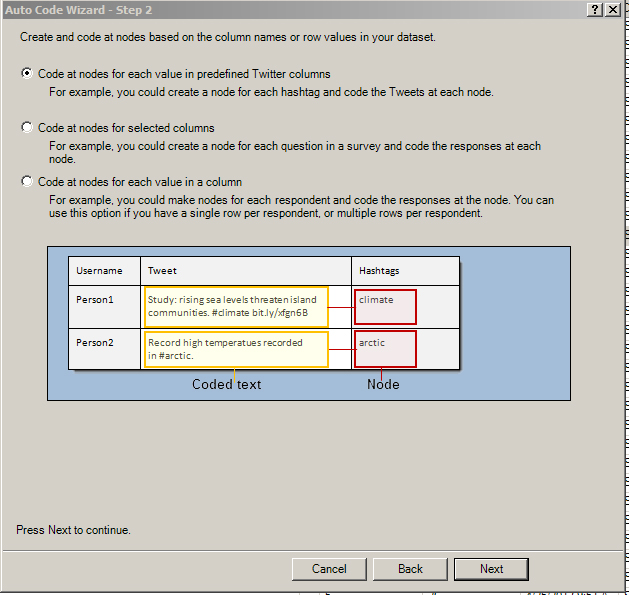
In the ribbon, go to the Analyze tab. In the Coding area, click on the AutoCode option (which should be in color, not grayed out). Select "Auto code using source structure or style."
{kind=link}
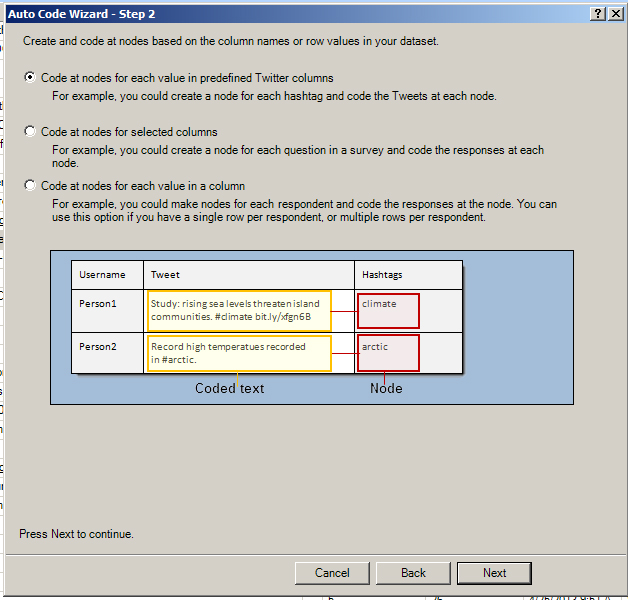
Follow the steps to select how you want the data coded--by hashtags as nodes with related Tweets coded to those nodes; with selected columns as the nodes and the related coded text in the cells as the related data inside the node; or with each respondent as the node and all related captured text as the included data inside the node. (It is important to really think through how you want to ingest the data into NVivo. You can always delete what you've ingested in the Nodes area and re-process. You can always process the data in multiple ways for different types of queries--for full exploitation of the data.) The three visuals below show these various approaches. Node cells are highlighted in pink, and the data cells are highlighted in yellow.
{kind=link}
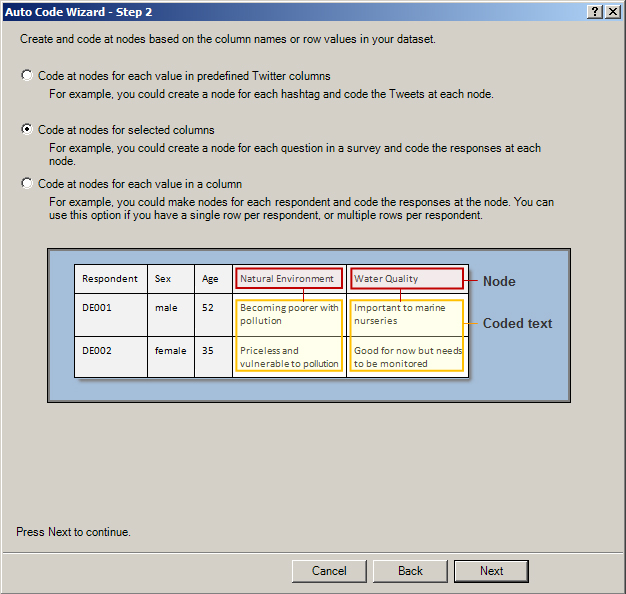{kind=link}
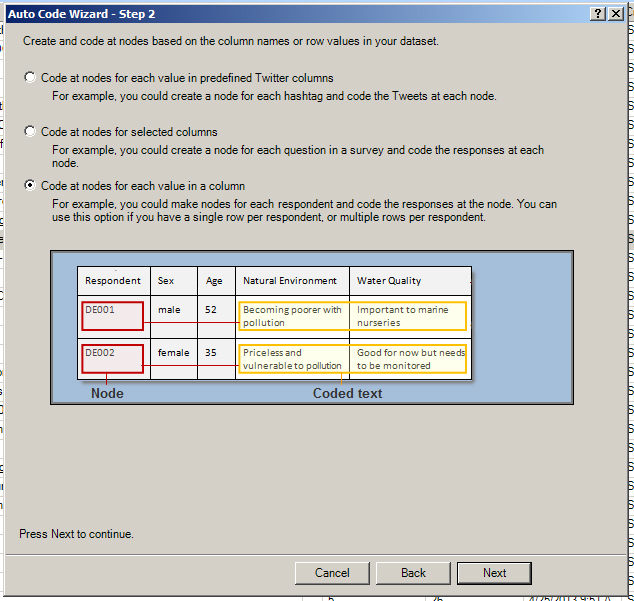{kind=link}
A Few Additional Notes
Researchers need to know what they have in the extracted data since this is data in-the-wild (vs. tailor-captured data). That exploration will help them properly query what was collected. On a deeper level, only the researcher and researcher team will decide what he, she, or they can assert from the downloaded data. This will be based in part on their professional judgment.
On a surface level, what may be asserted from the downloaded data will depend on a variety of factors. The provenance of online data may be questionable given the uses of anonymized accounts and pseudonymous handles for various accounts. Online accounts may represent a person, a group, a robot (such as auto-tweeting accounts, including sensors), and cyborgs (accounts with both human and robot messaging). It may be difficult to track the provenance of data with any certitude—unless one has access to additional information.
Also, the information captures may not include 100% of the information. The microblogging captures from a Tweetstream may number several thousand microblogging messages, but that may represent varying percentages of the entire microblogging dataset. Also, the messages captured tend to be the most recent ones, so they are limited to a particular time period. Microblogging messages tend to be succinct and coded to the particular audience, so cultural and linguistic understandings are important. It may be critical to extract and explore all relevant Tweeted imagery and videos and URLs, which will require further data downloads and captures.
The captured information may be manually coded. It may be supervised machine-coded (based on machine emulation of human coding, thus the term "supervised"). Text analyses may be run on the data for unsupervised autocoding (such as the automated extractions of text corpus networks). There may even be sentiment analysis of the text sets (likely using an additional tool complementary to NVivo or wholly outside NVivo, like AlchemyAPI).
This section offers a very early version of consideration of data analysis.
Maintaining a Data Accounting Log
It makes rational sense to maintain some sort of basic data accounting log when using a wide range of data types over a time span. The time element is of particular importance when dealing with social media-based data because much of it is dynamic (particularly microblogging data), and most of it is time-sensitive. To be relevant, the data may have to be captured periodically or even continuously. A data accounting log may help a researcher keep track of what information was captured when, and when to conduct more data extractions.
Also, researchers sometimes talk of "future worlds" in the context of data analysis. The idea is that in the future, there may be other methods that are applicable to extracting information from data. Proper documentation of the data will enable future users of that data to know what they are looking at, and it may better enable them to extract information and ultimately knowledge from the data.
The Professional Ethics of Using Social Media Data
The following image is "Social Media" (by Geralt on Pixabay). This is released for free use with a Pixabay license.
{kind=link}
Another salient issue regarding the handling of social media platform data involves the ethics of the uses of these sources for research. What are some common ethical considerations?
- Is the social media information being used in research private or public?
- Have those who shared the information been sufficiently made aware of the research for informed consent?
- Are common users participating in online social networks (OSNs) and social media platforms aware of what is knowable from what they share (through data mining, stylometry, network analysis, and other techniques)? Are users aware that trace and metadata are collected along with their shared contents?
- How can individuals (and their information) be sufficiently de-identified (in a way so that they are not re-identifiable with a little work)?
- How can researchers differentiate actual "personhood" of those behind social media user accounts as compared to algorithmic agents or 'bots?
- How can researchers identify children (whose data involves even greater protections under the Children's Online Privacy Protection Act) from a set of user accounts?
- How verifiable are the assertions about social media data ? Are there ways to cross-validate such data and to attain "ground truth"? How can the uncertainties be accurately represented to strengthen the research?
Pro-research oversight stance: On the one hand, researchers have argued that people who share information on social media are not generally aware of the many ways their information may be mined for meanings and ideas. They are not aware of the “data leakage” that occurs whenever they decide to include EXIF (exchangeable image file format) data in their images or videos. They are not aware of the potential of location tracing based on their mobile app check-ins to certain hotspots. They have not given their explicit permission to use their data for research. Most social media information is trackable to personally identifiable information (PII). Some suggest that if the Internet is used for the collection of survey information, Internet Protocol (IP) addresses should not be captured because these may be identifiable to a person and a physical location by sophisticated researchers.
Institutional Review Board (IRB) oversight is necessary even when researchers are using widely available datasets of people’s information to provide perspective in the potential misuse of such data (whether by the researcher...or even further downstream). Having Institutional Review Board (IRB) oversight also protects researchers and also protects the general public—particularly as the research may evolve into more dangerous territory.
Institutional Review Board (IRB) oversight is necessary even when researchers are using widely available datasets of people’s information to provide perspective in the potential misuse of such data (whether by the researcher...or even further downstream). Having Institutional Review Board (IRB) oversight also protects researchers and also protects the general public—particularly as the research may evolve into more dangerous territory.
Anti-research oversight stance: On the other hand, researcher have argued that this data is widely, legally, and publicly available (without a special need for creating user accounts to access much of the information). The argument goes: People have signed away their rights when they agreed to the various end user license agreements (EULAs) on the social media sites. It is in-feasible for researchers to provide informed consent and to acquire permissions again. Going through IRB review may be costly in time and effort.
Both sides have valid points. This decision is in the purview of the researcher and research team, the sponsoring organizations, the grant funding organizations, the research compliance oversight agencies, and other stakeholders.
Note: On January 12, 2016, Microsoft will end support for Internet Explorer, and this will be replaced by Microsoft Edge. NCapture does not currently work with Edge. Windows 10 actually still has Internet Explorer (IE) built in, and the NCapture add-on to that web browser still works well.
As of late 2021, neither Twitter nor Facebook have been designed for use with Internet Explorer / IE anymore, so extracting data from those platforms will not be possible while using NCapture on IE. NCapture on Google Chrome works fine on Twitter, but as of late November 2021, the tool does not seem to work on Facebook.
Note 2: Beyond NCapture, there are a number of other web browser add-ons that enable mass scraping of image data from websites. It is worthwhile to explore these capabilities.
| Previous page on path | "Using NVivo" Cover, page 4 of 5 | Next page on path |
Discussion of "NCapture and the Web, Twitter/X, YouTube, and Other Social Media"
Add your voice to this discussion.
Checking your signed in status ...