Ingesting "Internal" Source Contents
Pre-ingestion: Before ingesting digital content into an NVivo project, it helps to think about what format it is in, what data cleaning may be done, and how the data should be structured to enable data exploration, data queries, data visualizations, and other practical uses. The way the data is input...and how it is structured...affects what questions may be asked computationally. Repackaging information may enable different "sets" of information and how these may be engaged.
Ingestion of Internal Sources
The "ingestion" of "internal sources" involves placing digital information into an NVivo project. Ingested sources may be archived, annotated to, highlighted, assessed, and queried in a wide range of ways. NVivo acts like a database in how it manages the information that is placed within it. One of the early steps in setting up an NVivo project involves inputting data, so there is something to analyze. (Of course, digital contents may be ingested into an NVivo file at any time.)
{kind=link}
Nodes, memos, and other materials may be created inside NVivo. These are known as "born digital" data--information that is created in a digital space and in digital format. (Some information is only available in electronic format. Some information may only be captured using computer applications and computer-enabled capabilities.) However, there are all sorts of other digital files that may be relevant to a qualitative or mixed methods research project. These files may be born digital (such as much Web content); others may have been “born paper” or "born analog" or "born experiential" and then digitized.
Digital File Types Usable in NVivo...Contemporary NVivo (on Windows)
Digital files types are identifiable by their file extensions (the letters following the period in the file name).
Texts: .txt, .rtf, .doc, .docx, and .pdfImages: .jpg, .png, .tif, .gif, and .bmp
Audio files: .mp3, .m4a, .wma, and .wavVideo files: .mp4, .mpg, .mpeg, .mpe, .avi, .wmv, .mov, .qt, .3gp, and .mts / .m2ts [These require an installed video player on the computer, separate from NVivo.]
Datasets: .txt, .xls, .xlsx, and ODBC (Open Database Connectivity)
The .qdc codebook format is also usable in NVivo. The proprietary NVivo memo files are ingestible. Classification sheets are ingestible.
Currently, Flash objects (.swf, .flv, and others) are not uploadable. Some versions of Flash video (.mp4) are not directly uploadable. Interactive objects are not uploadable. PowerPoint slideshows (.ppt, .pptx) are not uploadable in their native format but may be uploaded as .pdf with a simple conversion. (Note: .pptx files may also be saved as a range of other file types, including image files and video files and simple text files, so depending on the researcher's needs, a wide range of file versioning options are possible.)
[It is unclear if the software compressed the multimedia or other files.]
* Machine-readable .pdfs. Make sure that all .pdf files are machine readable and are not mere images. Adobe Acrobat Pro, Adobe Reader, and others enable a built in Scan & OCR -> Recognize Text -> Recognize Text...to ensure that the contents may be analyzed for topics, sentiment, and to be coded manually, and so on. [Other file types work better than .pdf. .pdf files can be transcoded into .docx or .txt or .rtf files, and these tend to process much faster than the .pdf, especially for larger text collections (a thousand or more pp. for example).]
NVivo itself does not have built-in media players. Rather, it enables certain codecs (coders-decoders) to play video and audio files. What this means is that how an audio or video file was compressed will affect its accessibility through NVivo. An .mp4 video that has video processed with an unrecognized codec will not be able to be used in NVivo, for example (more on this follows below). In such cases, a researcher will have to return to the original raw video file and re-output the video using a different codec (such as a different audio codec). [If the video file type is wrong, simple transcoding may work. Transcoding involves converting a compressed coded video sequence into another compressed video file type. This process does not require going back to the original raw video file unless the multiple compressions degrade the quality of the video sufficiently that it would be better to start with the least-lossy / lossless original raw video and re-output from there. For example, that raw video might be a .avi format, among others.]
There are some dependencies and caveats in regards to multimedia.
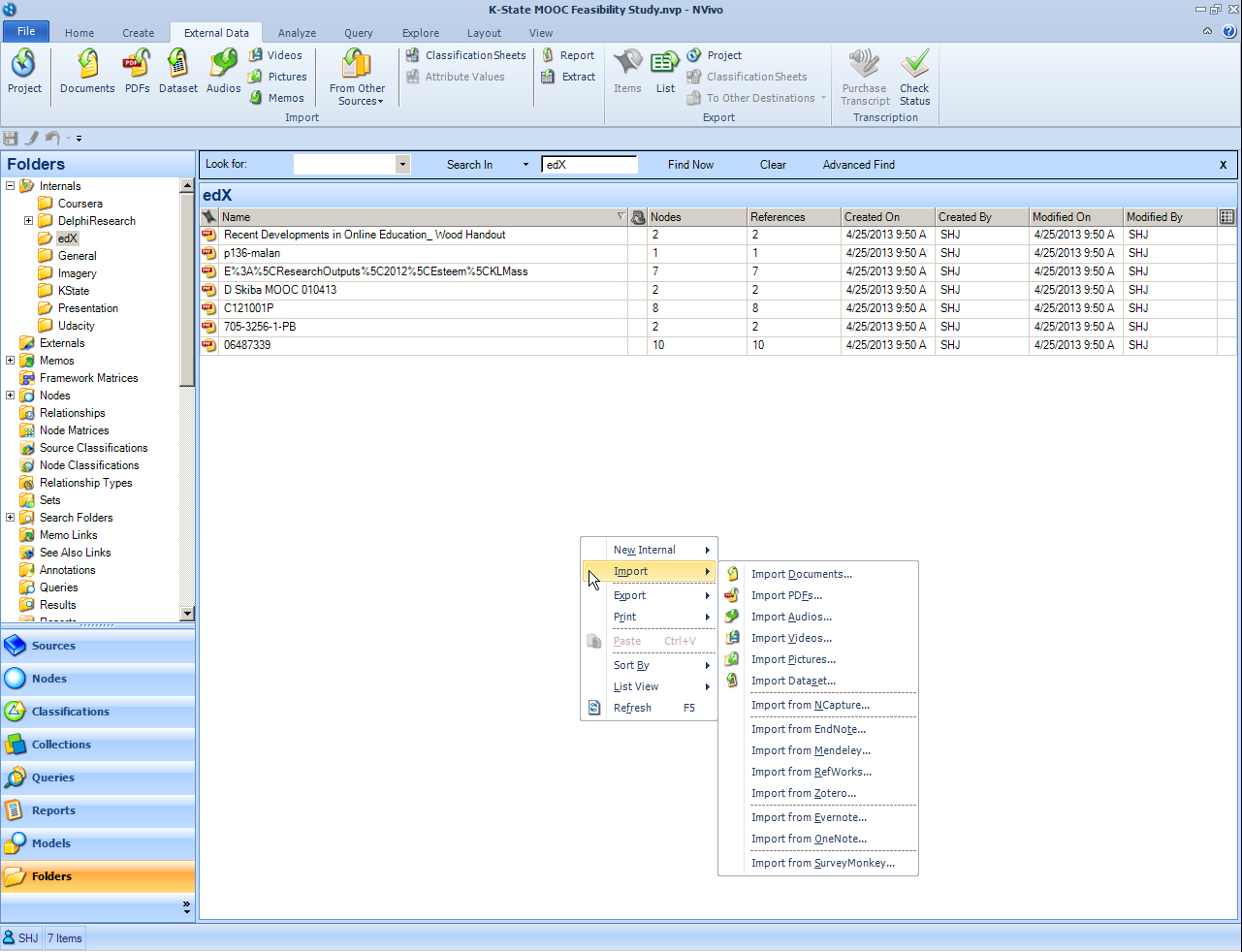
The act of ingesting internal source information into an NVivo project may be done at any time when any of the internal source folders are highlighted in the Navigation View in the left menu bar. There are a number of ways to bring data into an NVivo project.
1. Drag and drop: A user may drag and drop a file into the folder.
Digital File Ingestion
The act of ingesting internal source information into an NVivo project may be done at any time when any of the internal source folders are highlighted in the Navigation View in the left menu bar. There are a number of ways to bring data into an NVivo project.
1. Drag and drop: A user may drag and drop a file into the folder.
All the contents in a folder may be highlighted and dragged and dropped into an NVivo project. (These files may be moved around later.) In such an approach, all the files will have the same time stamp (for the ingestion time).
2. Right-click in the work pane with the Internals or an Internals folder highlighted. As can be seen in the screenshot above, the “import” function enables the importing of documents, PDFs, audio files, video files, pictures, and datasets (as general categories). It helps to know which formats are ingestible. To over-generalize, virtually all basic digital formats of the above digital file types are ingestible, just not PowerPoint slideshows. (Such slideshows can easily be transcoded into other formats that are usable in NVivo.)
3. Ingestion through the external data tab: Or, in the ribbon across the top, go to the External Data Tab, and click on the type of files you want to ingest. Browse to the location where you want to access the file or files. If you have a number of files you want to ingest, you can highlight them all and import them all at once (assuming the contents are all in the same file).
In the mix, there can be a wide range of data and content
2. Right-click in the work pane with the Internals or an Internals folder highlighted. As can be seen in the screenshot above, the “import” function enables the importing of documents, PDFs, audio files, video files, pictures, and datasets (as general categories). It helps to know which formats are ingestible. To over-generalize, virtually all basic digital formats of the above digital file types are ingestible, just not PowerPoint slideshows. (Such slideshows can easily be transcoded into other formats that are usable in NVivo.)
3. Ingestion through the external data tab: Or, in the ribbon across the top, go to the External Data Tab, and click on the type of files you want to ingest. Browse to the location where you want to access the file or files. If you have a number of files you want to ingest, you can highlight them all and import them all at once (assuming the contents are all in the same file).
From the Web and Internet. If a researcher or research team wants to access materials from the Web or Internet, from content networks like YouTube, from microblogging sites like Twitter, from social networking sites like Facebook, he or she can go to NCapture for the data extraction. (Or if he or she has acquire a large number of NCapture extractions, those may be imported en masse at a later time.) (Side Note: YouTube "ingestions" are only "embed text" functions. They do not involve an actual moving of the video files to the project as a media or video object. If the video is removed from the YouTube archive, the original embed text will point to a non-functioning link.)
Third-party bibliographic tools. Likewise, if the researcher or research team is using a third-party citation tool, he or she may access contents from commercial tools like EndNote, Mendeley, RefWorks, or the free and open-source Zotero (Firefox plugin). Reference management tools enable NVivo to automatically classify sources based on type and to include a range of bibliographic metadata. These various tools enable annotations of research, accessing and organizing online data (including from library-based databases), and the creation and exporting of bibliographic information according to different citation methods.
Note-taking tools: If he or she takes notes using Evernote or OneNote, imports may be made from those tools as well.
Online surveys: Finally, if he or she has created a survey or number of surveys in Survey Monkey, those may be ingested into the NVivo tool in through the Internals source view. A recent integration includes the ability to access Qualtrics surveys and data through an application programming interface (API). In both of these cases, there is some autocoding of the data that is being ingested into NVivo.
In the mix, there can be a wide range of data and content
- Primary research that has never been published (or seen outside of the team) before (survey research, field notes, experimental data, pseudo-experimental data, and others)
- Gray literature or informal information sources (brochures, whitepapers, ads, and others
- Social media data (social communications, shared imagery, textual communications, video, audio, art, and others)
- Secondary research that has been vetted and published through official and trusted sources
- Public datasets (from government, from academia, and others)
- Multimodal files (maps and underlying data, simulations, games, interactive videos, websites, and others)
All similar file types in a folder.
It is possible to select all items or some items in a folder and upload those altogether at once. This saves on time for the uploading. That said, if autocoding processes are going to be run over the files, most laptops and desktop machines can only handle a certain limited amount (500 .pdfs or so), but the limits depend on the file types and the file sizes, etc.
Double copies uploaded?
When uploading additional files after a first set has been uploaded, it is possible to have double-copies. There is not an obvious way to delete double copies except to go through the alphabetized list manually and remove those with (2) or (3) or (4), etc., behind the file names. Note that any related codes to that file will be removed as well.
A Note on Transcription (from Audio, Video, or Multimedia Content)
Note that there is no automatic transcription of any of the audio or video. [With the current online versions of NVivo, a paid transcription service that combines automated transcription and human oversight of some of the transcription is available.]
Audio and video may be coded to directly (even without any transcript) based on the placement of the playhead on the audio voice print / audio sound timeline, or to the video and its correlating sound line. If the annotations are sufficient for the work, then it may be that transcripts may not be necessary. (In this case, the audio and video are treated like “External” data that is not fully ingested into the project.)
In other cases, full transcriptions of the audio and video may be necessary. In such cases, there are integrated third-party transcribers who may be hired on to transcribe the audio or video (usually at around $1.50 - $3 a media minute). Others will upload videos to their unlisted YouTube channels in order to attain the downloadable transcripts (as .srt, .vtt, or .sbv formats) and to edit these within Notepad or some other text editor for verbatim correctness. (Machine translations of audio data--even with Google's YouTube's application of big data--tend to be maybe only 50 - 60% accurate, so these almost always require human intervention for correctness. Audio is highly noisy information. Also, the computers used to actualize these voice-based transcriptions have not been "trained" to the particular voices in a video.)
In other cases, full transcriptions of the audio and video may be necessary. In such cases, there are integrated third-party transcribers who may be hired on to transcribe the audio or video (usually at around $1.50 - $3 a media minute). Others will upload videos to their unlisted YouTube channels in order to attain the downloadable transcripts (as .srt, .vtt, or .sbv formats) and to edit these within Notepad or some other text editor for verbatim correctness. (Machine translations of audio data--even with Google's YouTube's application of big data--tend to be maybe only 50 - 60% accurate, so these almost always require human intervention for correctness. Audio is highly noisy information. Also, the computers used to actualize these voice-based transcriptions have not been "trained" to the particular voices in a video.)
---
{kind=link}
[Jeremy Sher (OverlappingElvis) created a node.js script that enables users to convert YouTube .sbv transcript files to NVivo text format. This command-line tool is available for download on GitHub at https://github.com/OverlappingElvis/sbv-to-nvivo. Thanks to Jeremy for this share!]
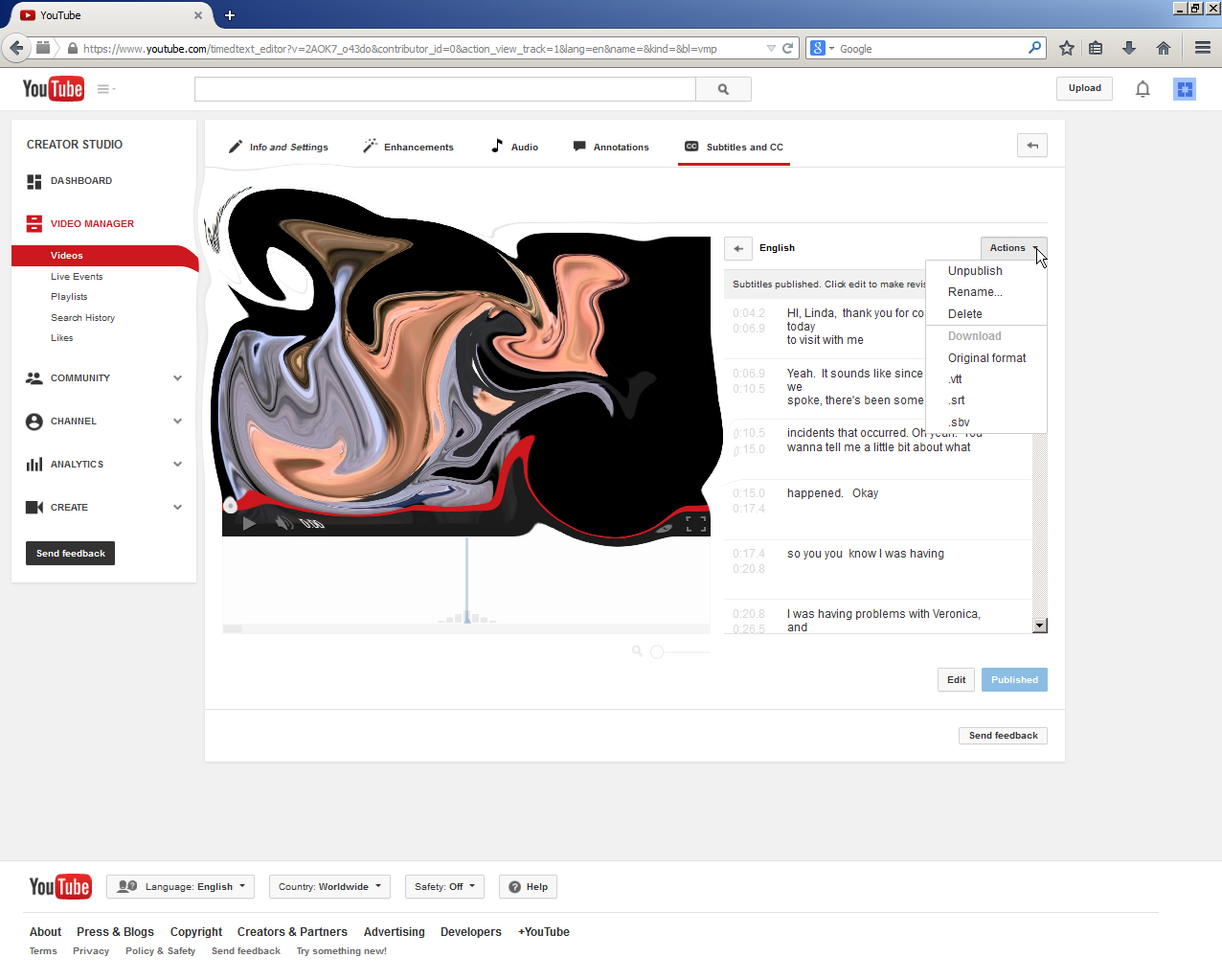
A screenshot follows below of an internal YouTube channel. It shows what the interface looks like after the user has gone to the Video Manager page.
Creator Studio -> Video Manager -> The Transcript
---
Creator Studio -> Video Manager -> The Transcript
{kind=link}
For those who want to read about some of the challenges of automatically transcribing YouTube videos, H. Liao, E. McDermott, and A. Senior's "Large scale deep neural network acoustic modeling with semi-supervised training data for YouTube video transcription" (2013) provides a sense of the challenges and also the ways Google is trying to improve the accuracy rate.
Dealing with Unrecognized Multimedia File Formats
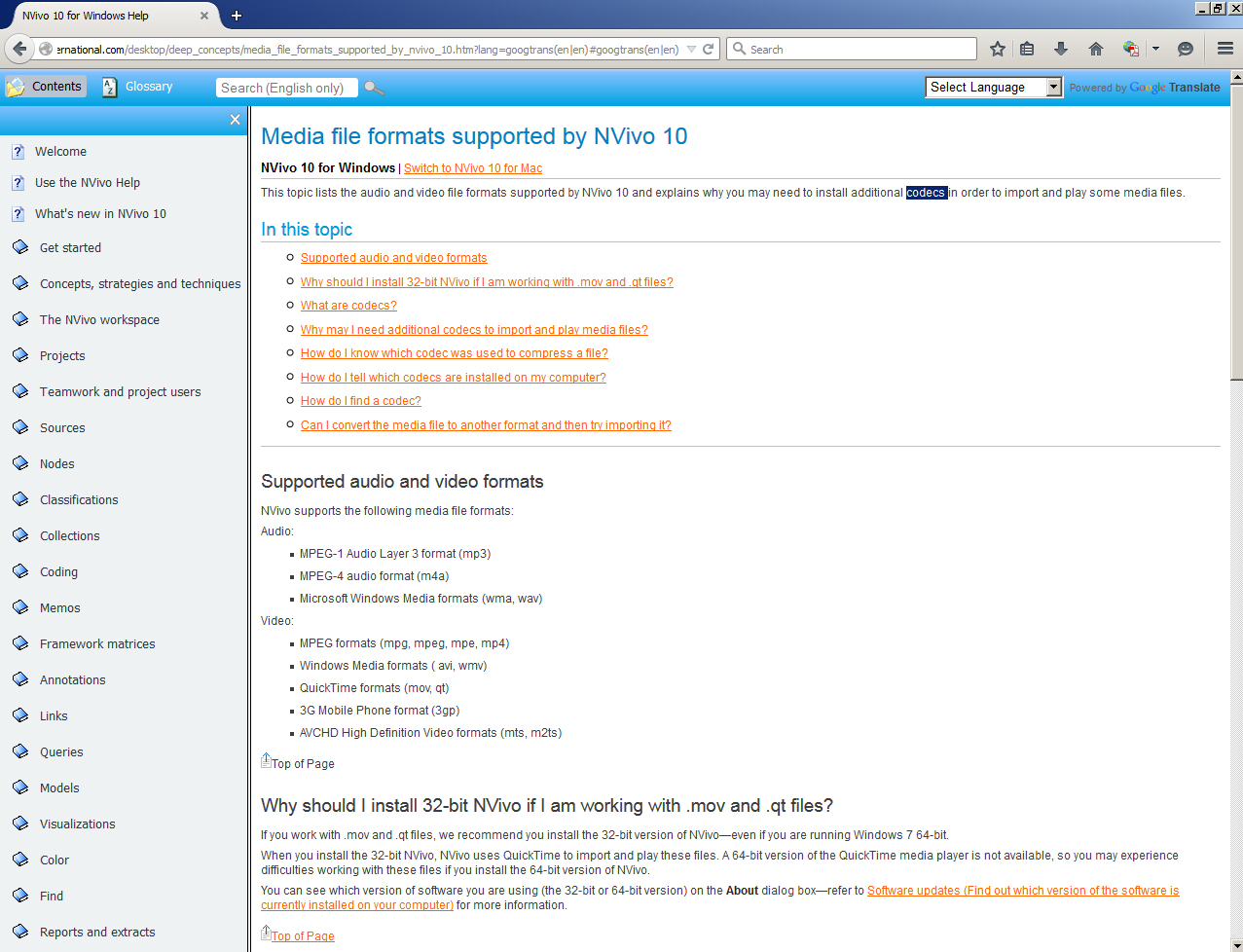
Sometimes, when trying to ingest data into NVivo, a message appears that suggests that the file is in an unrecognized file format.
"This media file is not a recognized format." Some researchers have tried to ingest video files into their NVivo project only to receive a pop-up message. The software then routes users to a page with additional details. Through some light troubleshooting, it seems that NVivo does not support the Advanced Audio Coding (aac) audio codec, so the software project will not enable the inclusion of any video files or any audio files that use this codec. To ensure that the video or audio files ingest properly, it is important then to transcode the files using a different codec. The supported codecs are listed in QSR International's "Media file formats supported by NVivo 10" page.
{kind=link}
Another "work-around" is to transcribe the video and audio files into rich transcripts, which may be ingested into NVivo and coded there. The "rich" aspect of transcripts would suggest highly descriptive transcription, which involves descriptive details about the context (visual, auditory, and otherwise). In other words, if there is music playing in the background, that should be noted. If there are nuances in the human interactions, that should be noted. If there are cultural insights that may not be documented otherwise, that may be included in the notes.
On Data Governance Procedures for Organizing Multi-Structured Data
Researchers generally have a variety of criteria for inclusion of data. The data should be relevant (ultimately) to the research, for example; it has to have some informational value. Because the data in qualitative, mixed, and multi-methods projects tend to be multi-structured (or "unstructured"), it may be helpful to create some sort of organizational structure for the ingested data, through naming protocols, folder structures, and other features. NVivo is very flexible in terms of enabling users to move contents in and out of folders, to re-name ingested contents, and so on.
At a high level, a researcher may want to consider how folders may be created and organized.
- Should folders be organized by multimedia types? (audio, video, text, and other file types each in their own folders)?
- Should they be organized by time period or phases?
- Should they be organized by function? (literature review, research design, etc.)
- Should they be organized by who created the particular data?
- Should they be organized by theoretical approaches?
Further, if the folders are nested (which enables combining various organizational features), how should they be organized?
- What metadata should be included with each file? What notes?
If there is a clear logical structure, it will be much easier for researchers to find contents and to achieve their work. This may be set up prior to data ingestion, during data ingestion, or after all the data has been ingested.
Text Versioning
Finally, while all sorts of multimedia may be included in a project in NVivo, the queries and autocoding and machine learning require text versions of all data.
NVivo is not "aware" of audio or video files' contents, without the transcriptions.
About File "Hard" Deletion
If a file is deleted, related coding in coding nodes (codes) and relational ties, and such, also disappear. A destructive "hard delete" is not recommended; however, there is not a clear way to "mute" files or their coding either, if that is desirable. [Do save pristine master copies before doing anything that results in hard deletions.]
Discussion of "Ingesting 'Internal' Source Contents"
Add your voice to this discussion.
Checking your signed in status ...