"Autocoding" through Machine Learning from Existing (Human) Coding Patterns
Building a Custom Codebook to Saturation from 10% of Data...and Assigning NVivo ("NV") to Code the Rest
"Machine learning" in computer science generally refers to algorithms that are not pre-coded to handle particular types of data or to extract particular types of information. The algorithms extract data patterns and can "learn" from the structured and / or semi-structured data. They can be applied in various practical ways...to predict, to classify, to identify anomalies, to enable natural language, to enable generative adversarial networks, and a number of practical applications. Machine learning can be applied to data to extract models and parameters.
In NVivo, the machine learning is based on either supervised or unsupervised methods (with labeled or unlabeled data). This software enables ML in particular use cases.
##
It is possible to use a human-coded codebook to apply to a larger dataset (of text, from multimodal and other sources). A basic flowchart shows this sequence. Note that the human coding comes first, and that the respective codes have to have examples. The human coding has to be comprehensive since this machine coding is emulative and non-generative (doesn't make its own new nodes).
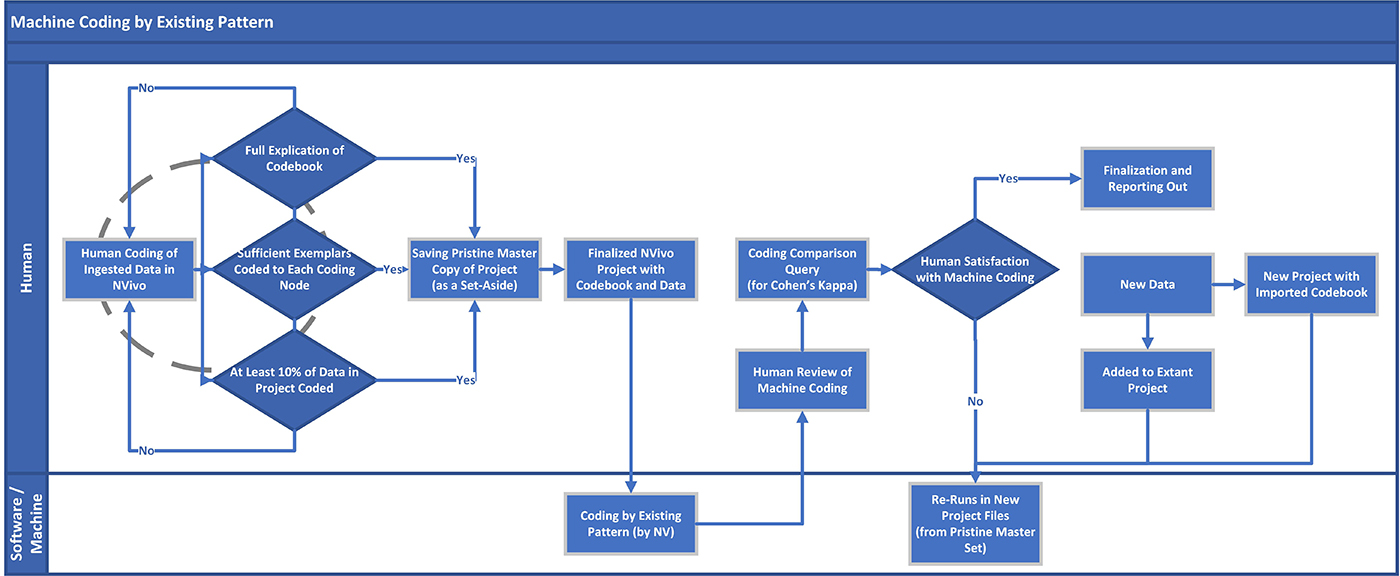{kind=link}
Humans in the Loop
Users of NVivo 10 - 12 and NVivo may apply another form of autocoding (besides the one based on styled text or paragraph breaks / hard returns). This type of autocoding is *not* based on the style of text that has been tagged or the position of a paragraph. This currently experimental type is based on the computer’s "understanding" of how the person coded information (labeled data) to particular human-created nodes (categories or classifications) and then copying that human coder approach by processing the data (based on the example text coded to each node). In other words, this uses a semi-supervised machine learning approach. The machine learning classifier uses some human-created examples (plus) to identify what text to classify into the coding structure.
NVivo 10 (and 11 and 12), in the coding by existing pattern, does *not* add new nodes to the pattern. This approach is limited to the examples created by the human coder. Also, the software does not "remember" or have "memory" of the coding. It does not learn and retain in a conscious way in the way that humans conceptualize learning and memory. The computer is applying an observed pattern to the source data in a fairly limited way.
A machine classifier
A machine classifier
The autocoding by pattern tool feature is based on machine pattern recognition and emulation. This then is a kind of semi-supervised "machine learning" based on the "training set" of pre-coded data (by human researchers). The computer "classifies" the text to the various categories (nodes) created by the human researcher. It codes all the data (not just what was left uncoded by the researcher). This autocoding by pattern feature works as a multi-label classifier, but it only uses the existent categories (nodes); it does not create new nodes on-the-fly. (A classifier which is unsupervised is able to offer its own nodes based on statistical analyses of the text.) This autocoding by pattern should be used with human oversight; it is advisable to vet the results and to un-code what may have been inappropriately coded.
Some Early Observations
This section contains some early observations.
Sufficient modeling of the coding
Generally speaking, it helps if the individual or team has coded at least ten percent (10%) of the source materials in a “pilot” (training set) based on the example in the Lumivero, Inc. documentation. This gives the machine a training set from which it can learn what is desired and which it may then emulate a model to apply to the "test set". Researchers are advised to code to sentences vs. paragraphs, so that the narrow focus of the coding is more targeted (and less diffuse). The more information the computer software has to go on, up to a point, the more nuanced its capabilities are.
Predefined nodes (classifications / categories).
It is important to have the nodes already comprehensively identified and defined, so that the computer knows which nodes to code to. The machine does not create its own nodes. It tries to follow the human coder coding to specific or selected nodes (or all nodes) with a high interrater reliability based on machine emulation. "NV" does not presume to create nodes from the data (although it would be pretty cool if it did).
De-duplicating data in the .nvp project
For many researchers, as they create nodes and code, they may create duplicates of data in the process. If there is a lot of duplication, that may amplify into the machine coding, leading to multiple citations and possible mis-counts. Some will set up new .nvp projects in order to be able to run different queries, explorations, and autocoding sorts of functions. The uses of new .nvp projects (with only the necessary elements included) is a way to ensure de-duplication of data. (Instead of rebuilding a totally new project, it is a good idea to save the extant project and remove duplicated elements. This way, the data is as up-to-date as possible.) Or, others may create pristine master .nvp project files and reuse those again and again. (It is important to keep track of the project file versioning and to use clean and clear naming protocols, so there is not confusion.)
Certain types of coding only
"NV" (NVivo) does not capture human sentiment well (because that sort of human-interpreted nuance is not as obvious to this software program). (NVivo 11 Plus has a sentiment analysis feature based on a built-in sentiment dictionary that involves unsupervised machine learning. This new feature works pretty well, but this capability is described on another page.) It does not capture tone or emotion well either. Human coding of audio tapes or video files cannot be handled by the software because there is no voice recognition capability in this software.
Checking the machine coded contents
Just because it emulates the human coder closely does not mean that the coded data makes sense. It is advisable to double check and refine all information coded by “NV” and to decide whether or not to accept the changes into the project. (Anyone who has used machine translation between languages or experienced machine-transcription from audio-to-text will have experienced some of the gaps in understanding between human and machine.)
Creating a backup project before going with machine coding based on human patterning
Researchers are advised to create a backup project before applying this type of autocoding in case they do not like the results. Even though computers can emulate human coding to a Kappa coefficient of 1, the results may not actually make direct human sense. In the case that the new coding is unwelcome, it may help to have an earlier dataset to use that was created prior to the machine-based coding.
It can be tedious to go back and manually undo the various coding. What are some ways to revert to pre-machine-coding if a prior project in an earlier state was not saved?
- One can go into the coded nodes and highlight the machine coding and uncode.
- One can also delete the sources that the machine coded to (if the human did not code those sources) in order to remove the related coding. The sources then can be added back to the project.
- One can export the nodes based on coding by the individual to another project, import the pristine sources, and start manually again.
If a person did not save a project in an earlier state pre-machine-coding and the damage is done, then at least, it is helpful to learn from the mistake and keep going.
There are likely other considerations as well. However, this will suffice for a start.
Autocoding through Pattern Recognition and Emulation
To begin an autocoding-by-pattern recognition process, make sure that there is already some human coding.
In the NVivo project, the Navigation View should be on Nodes. Highlight the nodes that you want to code to in the List View. In the Analyze tab, under the Coding grouping, you will see that AutoCode is now highlighted. When that part of the ribbon is clicked, the Auto Code Wizard window opens.
Select “Auto code using existing coding patterns.” Click "Next".
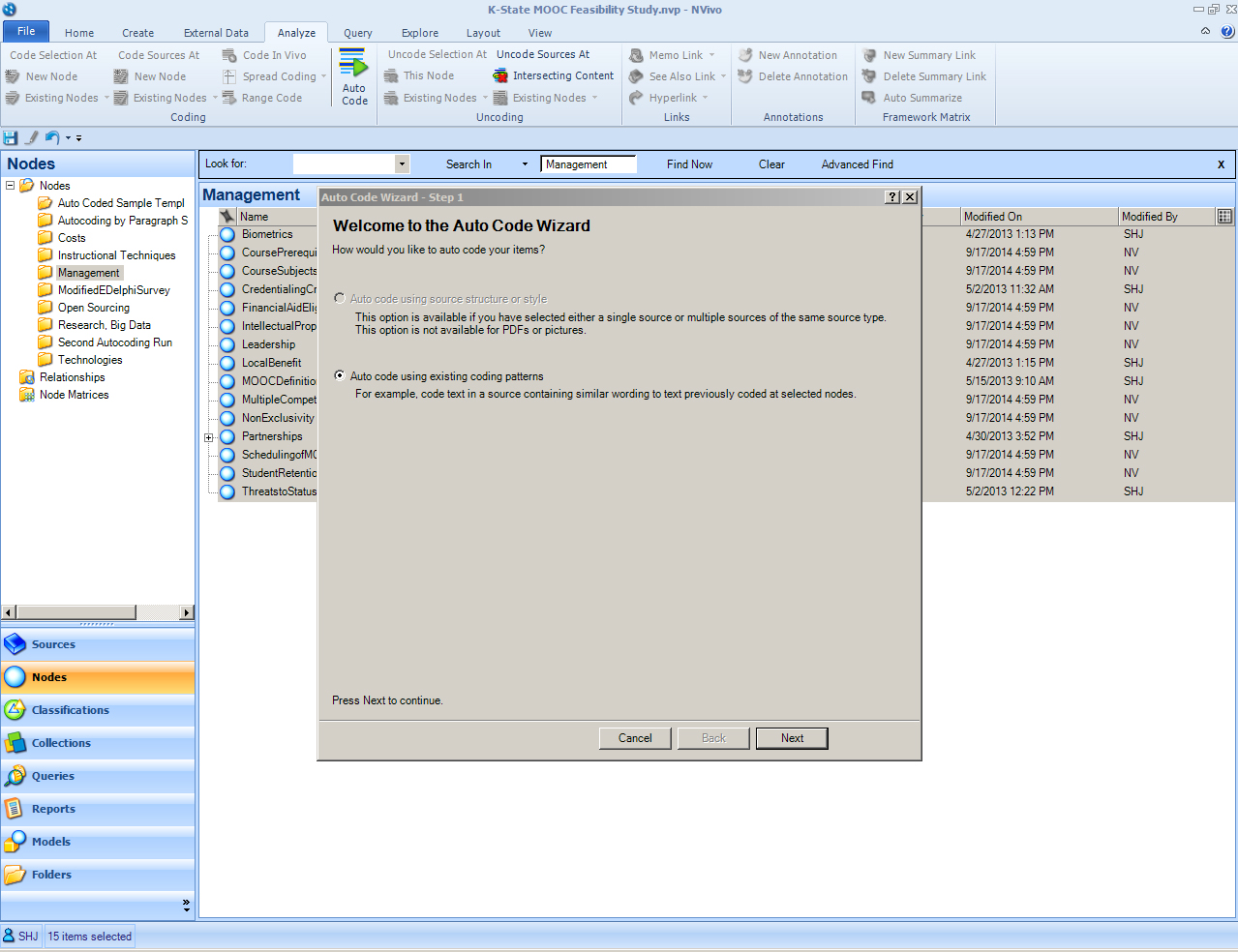{kind=link}
Step 2 of this process asks whether the user wants to code at selected nodes or all nodes. If selected nodes are desired, this is the place to clarify just which nodes should be coded to. Or, a user may choose to have all nodes coded to.
The other question in this step is to decide how much coding the user would like NVivo to create. This is a relative measure, and it may help to conduct some initial autocoding-by-pattern runs in order to get a sense of what level of machine-based coding is optimal. If the slider is set too high towards “More,” there may be irrelevant data coded to particular nodes, which means a user will have a lot of work cleaning up after the computer. If the slider setting is set too low (towards “Less”), then the computer may miss some relevant information that should have been coded but was not. This latter scenario means that the user may have to go back through the nodes and sources to ensure that nothing critical was missed.
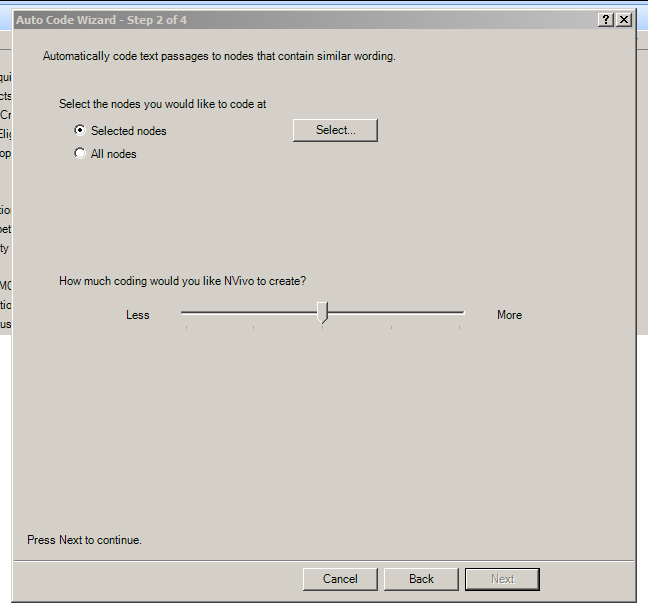{kind=link}
Once the selections are made, click “Next.”
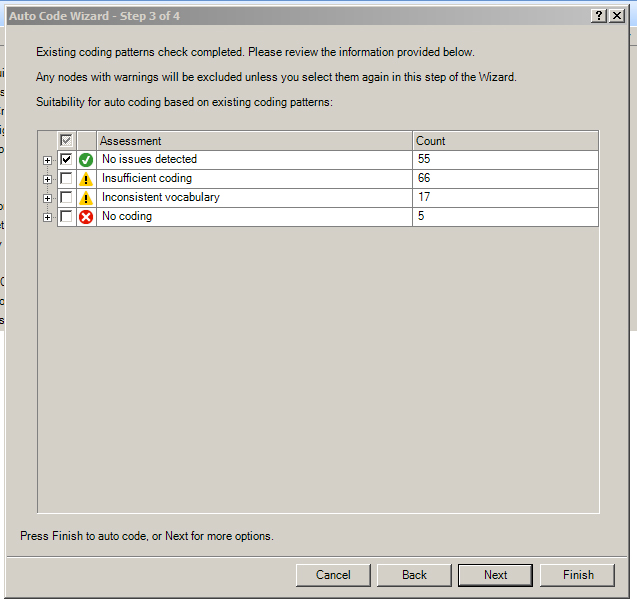
NVivo checks the existing coding patterns. It will report back whether it has sufficient information to go on. (It may be good to capture the report in a screenshot in order to have a sense about how to understand and possibly qualify the resulting coding afterwards.)
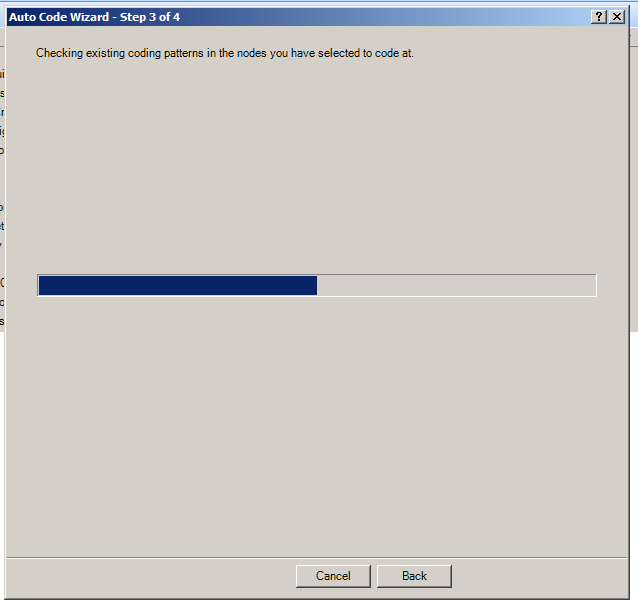{kind=link}
An initial assessment is conducted to analyze existing coding patterns. In the sample below, 66 nodes were found to have insufficient coding to inform the machine how to proceed. Seventeen had “inconsistent vocabulary”. Five had “no coding related”. There were 55 with “no issues detected”. (Optimally, it would be good to go with the 55 nodes with "no issues detected" because the "NV" coding to the other nodes would likely be problematic for the prior reasons listed. The human coding has kicked up a lot of areas of concern because this project evolved from a real-world research project to a showcase project with created nodes for screenshots and experimentation--so no actual real data were coded to some nodes. A self-respecting researcher would have sufficient and accurate code exemplars from the source materials for each of the codes / nodes.)
{kind=link}
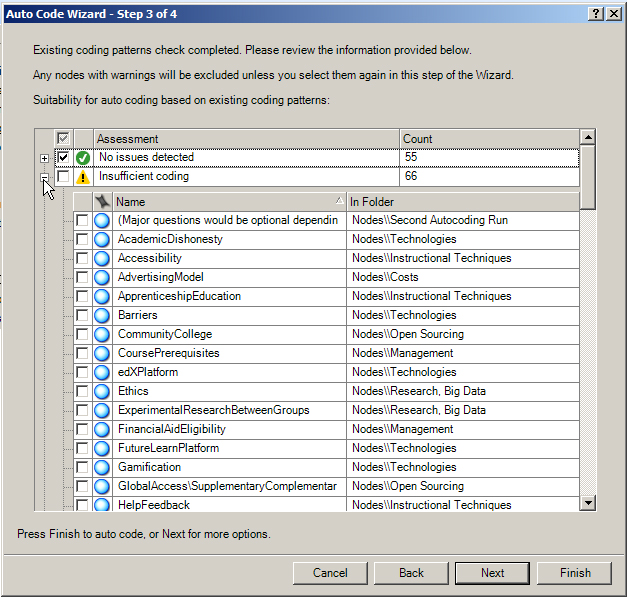
Users may expand the plus signs to the left of the assessments in order to expand the node list that fits under particular categories.
{kind=link}
If users want to continue with the coding even with the limitations identified by NVivo, they may by clicking into the respective boxes to place check marks. (The understanding is that if a person goes forward, there will be some noise in the data—such as from miscoding some sources to some nodes. Such noise may lower the “NV"’s effectiveness as a coder; ironically, this may not lower its interrater reliability score in its mapping to the human coding patterns because it is copying as closely as possible given the machine parameters. An actual Cohen's Kappa coefficient is actually 1 when a human coder's work and that of NV is compared.) After this decision is made, click “Next.”
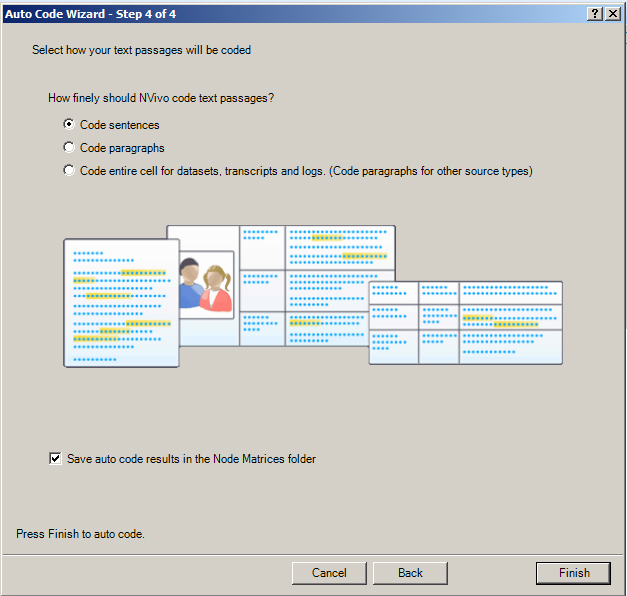
In this case, for the sake of the example, the user will accept the suggestions of NVivo and simply proceed without the questionable nodes. Step 4 asks how finely the system should code information—at the sentence, paragraph, or cell levels. This points to the level of granularity in the analysis that is used in the project. The default setting is to sentences (which is what Lumivero (formerly QSR International) advises in its documentation). There is another default setting—which is to save the autocode results into the Node Matrices folder.
{kind=link}
Once the necessary decisions have been made, click “Finish”.
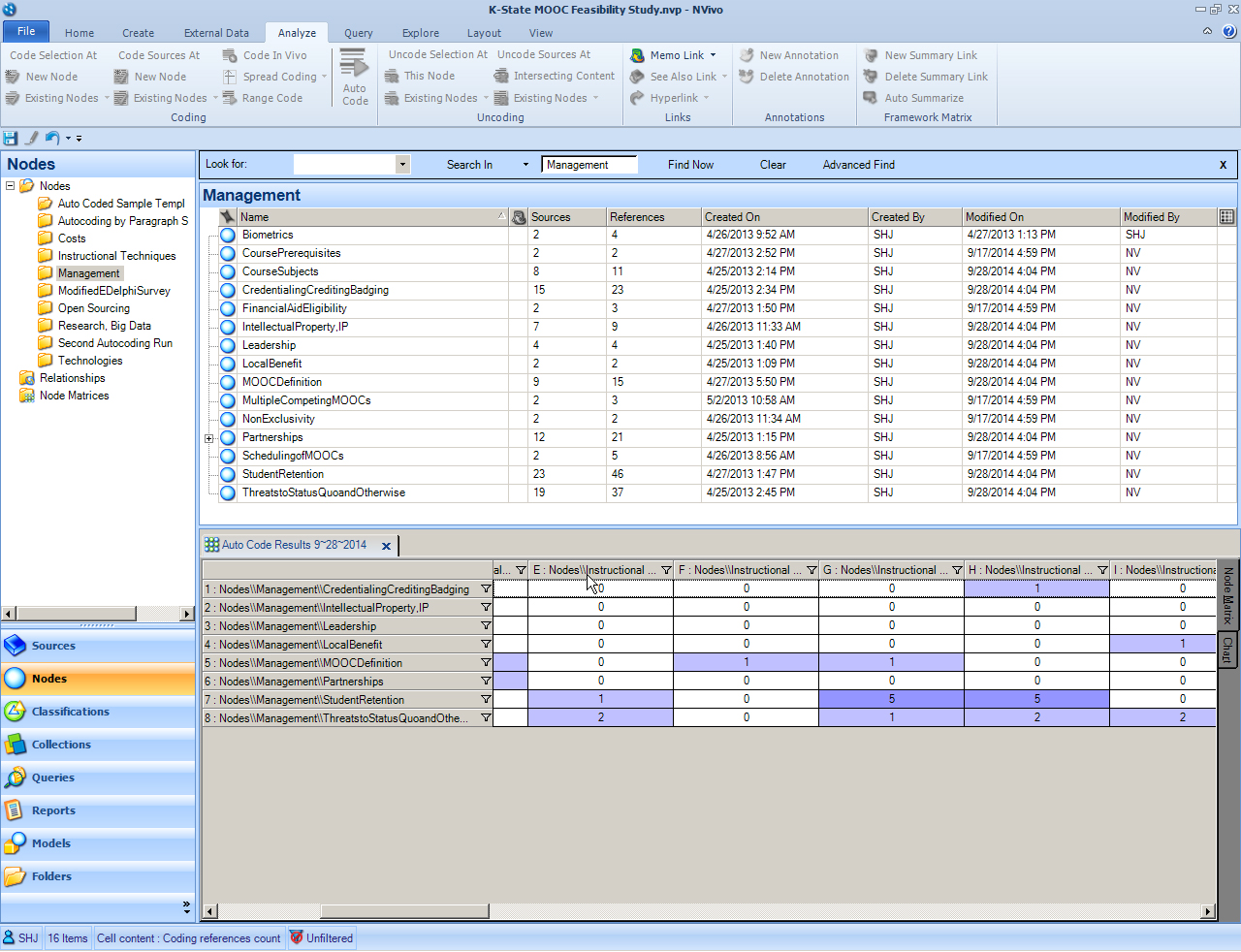
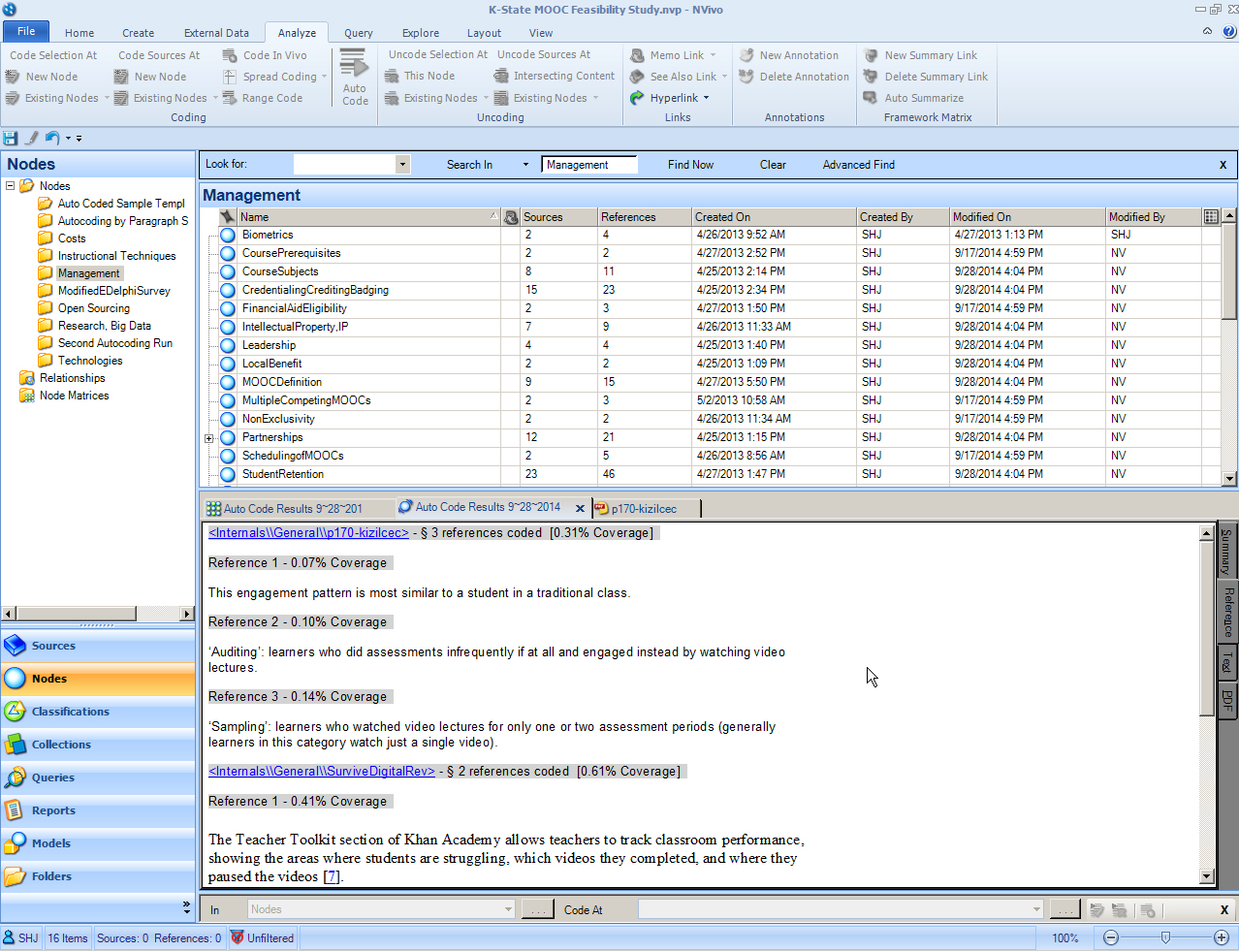
What results is a focus on the main selected nodes, with overlaps of coded information presented in a table. The darker the color of the cell, the more freshly coded data there is (represented by the number in the cell).
{kind=link}
Double-clicking on the cells of interest will show the complete sentences (or paragraphs or cells) that the machine identified as indicating that it should be coded.
{kind=link}
Clicking on the links in the Detail View will take the user back to the original sources, which have now been highlighted by “NV.” (The Coding Stripes Feature: The Coding Stripes were turned on in order to show some of the NV coding, indicated by a yellow stripe. A mouseover that stripe shows that “NV” was the original coder. Coding Stripes may be double-clicked to highlight its reference in the original source or document.)
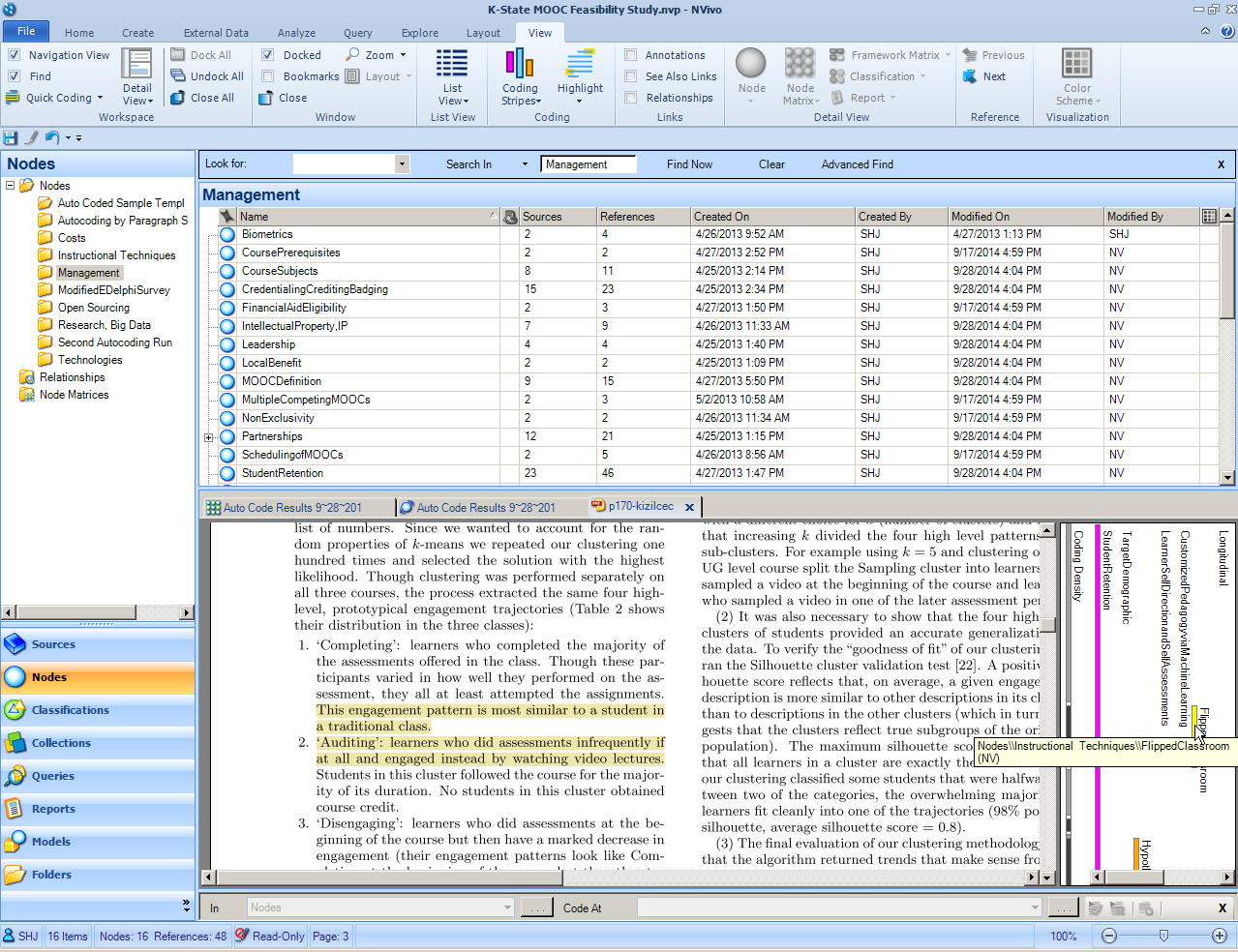{kind=link}
In this scenario, all the coding by “NV” was automatically accepted into the existing nodes. (Later, a user could conduct a Coding Comparison Query in order to see where the machine and the human differed, if both coded to everything…or if both coded to at least a discrete part of the project.)
Autocoding Refinement
As noted earlier, it is assumed that there will be human oversight and analysis of the coding achieved by machine. It will be important to omit the code which is not appropriate to a particular node. It is simple enough to highlight the coding and delete on a case-by-case basis.
Projected Practical Scenarios for Usage of Autocoding by Patterning
So when would machine-coding based on human patterning be possibly helpful. After all, most research fields require “close readings” of texts by in-field experts. There may be contexts in which there are “big data” sets that may not be humanly readable given the volume. Web-scale contents from social media platforms could be one example of such a large set. In such cases, "distant reading" by machine counts and machine text summarizations may be desirable. (Franco Moretti of Stanford University coined the term "distant reading." This term refers to the uses of computational methods to consume texts and resultant data visualizations--graphs, maps, networks, trees, and other representations--to represent textual contents. This approach does not preclude human "close reading" except in cases when such consumption is not possible. This latter case of non-consumptive reading is one in which machine algorithms may be used to explore and probe copyrighted textual contents which are not made available for direct human reading.) Machine coding could be used to analyze sentiment…with a training set by human coders to indicate which type of emotions or attitudes fit into which categories (and at what strength or “direction”).
Others have suggested that this pattern-based coding tool could be used to differentiate between particular speakers or interview subjects based on unique “tells.” (In this case, all known speakers have their works set up in respective nodes. These are human-coded. Then, unknown transcripts may be introduced…and machine-coded. Those nodes that share high similarity may be probed further for potential likeness. (Theoretically, coder “hands” or “fists” could be remembered by the machine and applied to new data.)
When *Not* to Autocode based on Human Patterning
Lumivero highlights some contexts when it may not be advisable to use this human-based patterned autocoding. Nodes that are coded based on sentiment should not be autocoded because NVivo does not apparently capture sentiment--in the sense of word choices, direction of sentiment, degree or strength of sentiment. (There are text analysis tools that achieve this, but generally, such tools require a fair amount of setup and adjustment, and also reliance on various training text sets that indicate sentiment.) Likewise, nodes that deal with "attitudes, tones, or emotions" should not be included in pattern-based autocoding. Any nodes that involve interpretation of the data (such as through a close reading) will not do well. And finally, if coding is based on speaker captured on either audio files or videos, researchers should do the coding; they should not hand this over to the machine.
What NVivo captures in the patterned autocoding includes coding of certain disambiguated term-based phenomena, with words that are original or in original order. NVivo captures words and their synonyms well. The clearer the coding, the easier it is for machine emulation. It may be helpful to think of NVivo as more of a generalist tool without the tailored nuances of pre-set text analysis "thesauruses" and sophisticated stopwords lists. Computers may be trained to handle nuances well, but it's questionable how much training may be done within a dataset for accurate patterned autocoding. (Researchers would do well to code the work sufficiently and then run the autocoding feature on a test version of the project to see what the outcomes are...and then to review the outcomes. It is important to keep a version of the project "pristine" and separate from any patterned autocoding in case the results are not what the researcher or research team wanted. There is value in reading through the "NV" coding to get a sense of how the computer was emulating the human coding.)
For More...
For more information on autocoding by pattern, visit the Lumivero site. It would help immensely for Lumivero to share more information about the various algorithms running for "autocoding by existing pattern". An analogical feature in SPSS is its post hoc "Automatic Data Preparation" report which lists step-by-step all the machine processes that went on under the covers for its Automatic Linear Modeling" (inferential analysis based on data and one output variable). That step-by-step approach in describing what the machine did does a lot to disambiguate algorithmic processes and makes that research much more transparent and reportable.
Think about the possibilities, though...if this capability can truly capture a full expert human being's coding "fist" or unique hand...which may be applied to data...to extract what is important. This could--ideally--work as a kind of expert analysis system (with some caveats). New data may be processed using an expert's hand, with varying results, depending on which expert coding "hand" is applied.
Addendum: Automated Feature Extraction / Generation
There are widely publicly available software tools that enable automated feature generation from text corpuses/corpora, but this is not that kind of feature or software tool. In order to take the text out of an NVivo project to run in other software tools, this apparently requires a manual process. (There is no apparent automated way to extract all text--whether as single files or as a synthesized text file--from an NVivo project file for processing elsewhere. There can be a general text frequency count applied to all contents, but what is returned is a table with a count of the top 1000 words only in descending order--and not a total text extraction...and not with any preservation of textual context.)
Discussion of "'Autocoding' through Machine Learning from Existing (Human) Coding Patterns"
Add your voice to this discussion.
Checking your signed in status ...