Team or Group Coding in NVivo
Even without the server version of NVivo, researchers are able to work together to collaboratively code shared research—even if they are not co-located and even if they have different versions of the software (Windows, Mac, or Server).
Full stop. [Don't spend money on heightened levels of technologies if those technologies are not needed.]
Team Coded Work Sequence
What might a work sequence of a team-coded project look like?
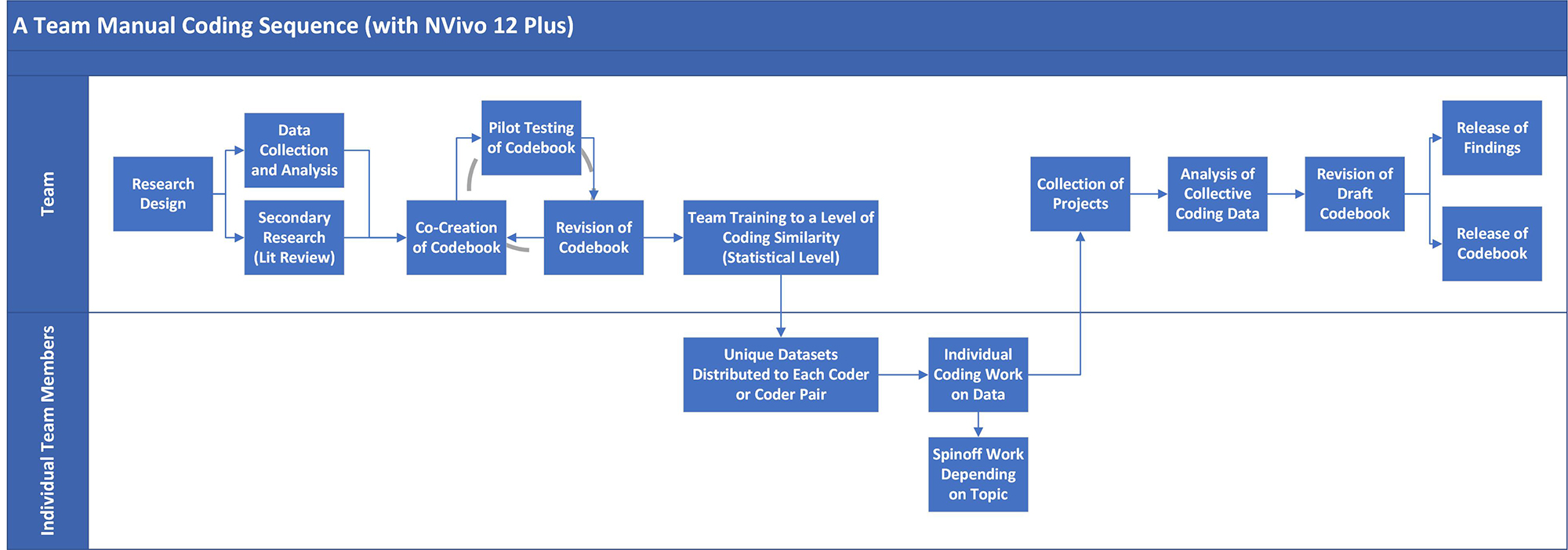{kind=link}
Some Basic Requirements
If a team wants to use multi-coding (from the tech side), there are several basic requirements.
1. Each member of the team should have an up-to-date version of NVivo. Each member should have a registered copy of the tool and their own original initials (which cannot be NV—since that is used by the autocoding feature in NVivo).
2. Each member should enable automated event-logging so there is documentation of when each did what work.
3. Each member of the coding team should have access to the basic dataset (or variations of a base dataset) and the pre-determined codebook (unless the team is using an emergent and / or evolving codebook). A fair amount of thought should go into setting up the project before hand-off to the various team members.
4. There should be a team lead who will integrate all the coded projects with the main synthesized dataset and project. (This main file should be regularly backed up in a location beyond where the main working files are kept.)
[When divergence makes more sense at least initially.... Some teams have co-created a consensus-created codebook by collecting reams of data from their target area, coding individually for divergence, not convergence...and then creating a manual codebook that fully covers the topic area of focus. Then that vetted codebook is pilot-tested...and then used to code a large amount of data or a smaller amount of data in-depth. Do note that this software has a capability to emulate human coders and manual-created codebooks, so if there are very large datasets, automation may be brought into play--assuming that the human-made codebook is comprehensive...and assuming that there are sufficient exemplars coded to each of the categories.]
Interrater Reliability
For some research projects, the "interrater reliability" measure (a statistical measure of similarity between how the team members code the same dataset) will be important as a way to establish the soundness of the coding of the research. If the interrater reliability is high, then the coding fists of the respective compared coders are close, so close that the coding can be trusted. If it is low, then the coding fists of the respective compared coders are distant, and if consensus is required, then the standard will not have been met for identifying the particular construct.
In other cases--such as when the respective coders are each looking for different things--the "consensus" or "dissensus" is not particularly relevant. In such cases, while the raters are examining the same dataset, there will be overlapping (or "simultaneous") coding based on different focuses. As another example when interrater reliability may not be important is in the preliminary or exploratory coding phases when a provisional codebook is being evolved, and the coding team will benefit from a wide span of possible codes. In initial coding, there should be openness to all possible theories and coding interpretations. In later refinements, it may be that the coding team converges on a codebook and an agreed set of codes and their meanings; at that point, interrater reliability may become more relevant.
In some domains, there are validated coding systems that are used. In such cases, when teams are engaged in coding, interrater reliability may be critical to show effective distributed coding. (Usually, there are described protocols for research team member training.)
Importing (Sub)Projects into another NVivo (Master) Project
So how will the team lead import the other coded projects into the main NVivo project? That is done through the ribbon and the "External Data" tab. Go to the far left button of that tab which reads "Project." Go through the necessary steps there to integrate the other projects in whole or in part.
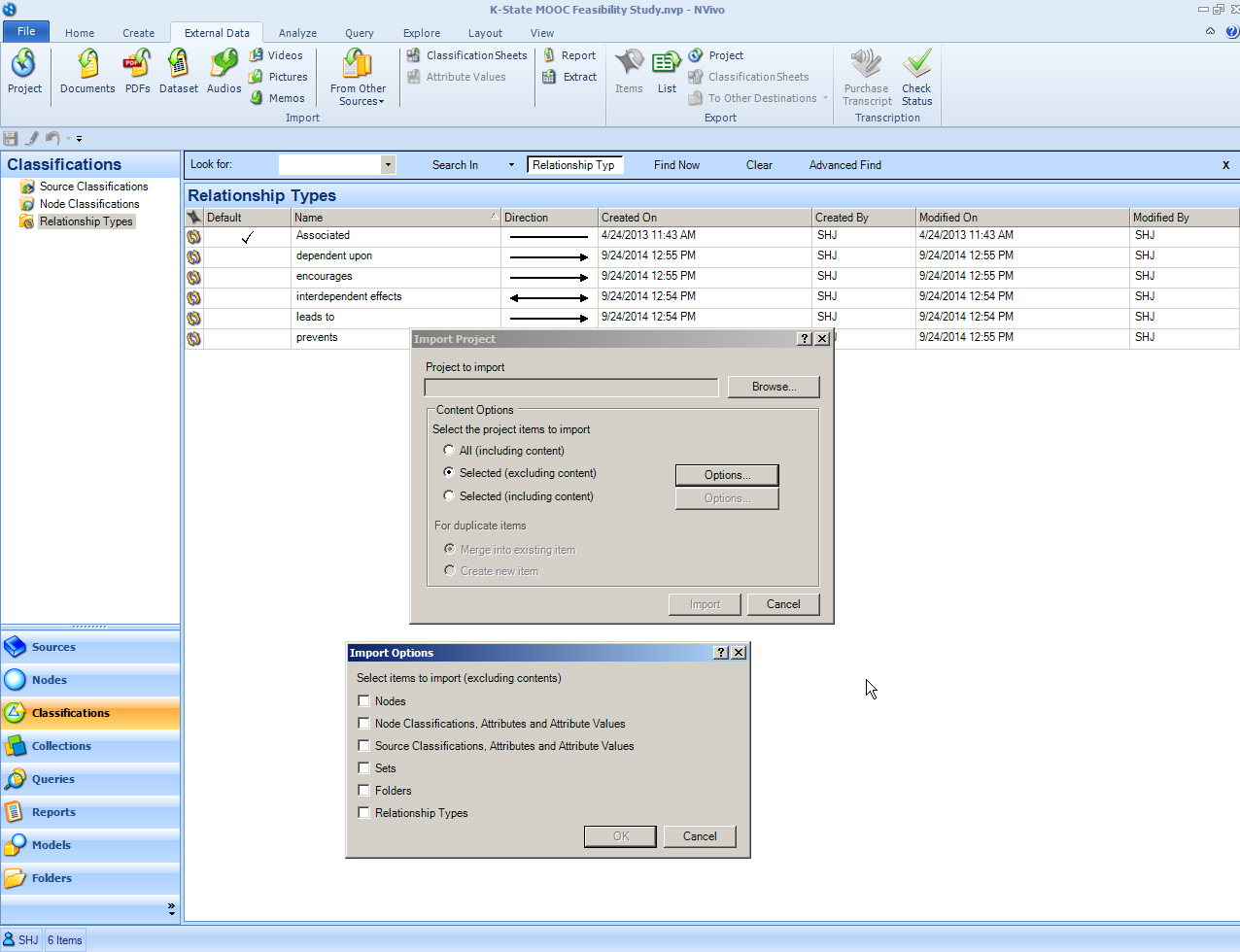{kind=link}
Please also see the "Opening (Converting) an Existing NVivo Project" if that applies to your work.
Discussion of "Team or Group Coding in NVivo"
Add your voice to this discussion.
Checking your signed in status ...