Bulk importing CSV data from spreadsheets using the Transfer tool
The steps for importing a spreadsheet are straight forward: create a spreadsheet (e.g., in Google Spreadsheets or Excel), add rows that constitute pages, make each column heading match Scalar's brand of metadata fields, then export a Comma Separated Values (CSV) document for use importing. Here are the steps in detail:
- Create a spreadsheet
- The first row should hold the metadata field names. For example: "dcterms:title" "dcterms:description" "art:url" "sioc:content" (see more below)
- Add rows that constitute pages and media. For pages make sure there is content in the "sioc:content" field that constitutes the text of the page (see our example.csv for uploading pages). For media make sure the "art:url" field has a value representing the URL to the media file (see our example.csv for uploading media).
- Export the spreadsheet as a Comma Separated Values (CSV) text file
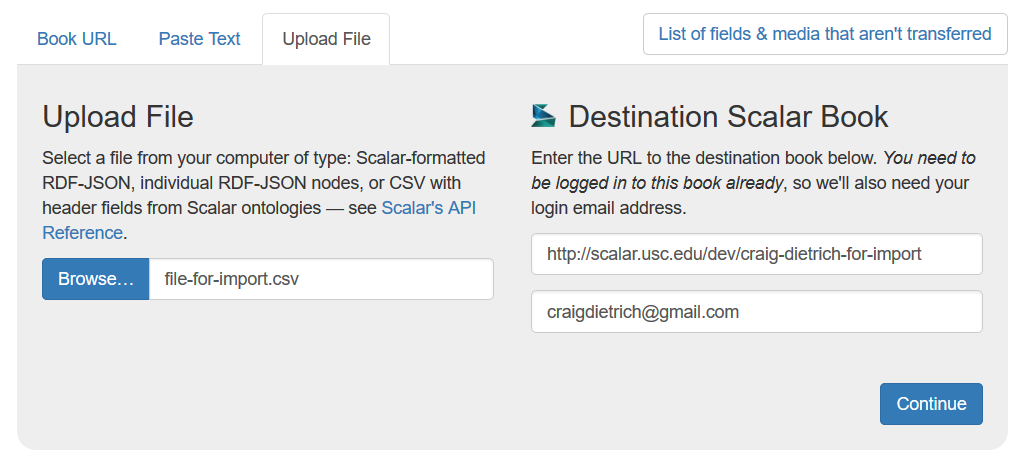
- Head over to the Transfer tool, then click on the "Upload File" tab. The "destination book" fields should already be filled in if you came to the tool via your Scalar book
- Choose your CSV file, the click Continue
- That's it! You should now have pages and/or media present in your Scalar book.
{kind=link}
Any Dublin Core fields can be used as column headings. For example: "dcterms:title" "dcterms:description" "dcterms:source" (dcterms:title is required). In addition, you must have one of: "art:url" or "sioc:content". Scalar supports other ontology prefixes such as: "bibo:(field name)" "iptc:(field name)" "id3:(field name)".
Note that if you include a "scalar:slug" column and populate it with the slugs of existing pages or media, then the importer will update those items with the new data, instead of creating new items. The "slug" is a unique identifier that consists of the last segment of a Scalar URL, usually derived from the item's title. For example, the slug for this page is "bulk-importing-spreadsheets-using-the-transfer-tool".
This page has paths:
- Advanced Topics Curtis Fletcher
{kind=link}