“Autocoding” through Sentiment Extraction and Analysis
Sentiment (Emotion, Mood, Attitude) Extraction
A new feature is a sentiment extraction and analysis tool, a form of automatic text categorization. Computational work in sentiment analysis started over a decade ago, and sentiment was conceptualized as a polarity, with positive and negative on the ends of a pole (or on a positive-negative continuum or on a positive-negative binary category). Sentiment is conceptualized as rational (arrived at through a logical thinking process) or instinctive (arrived at through a fast, impressionistic, and emotion-based process).
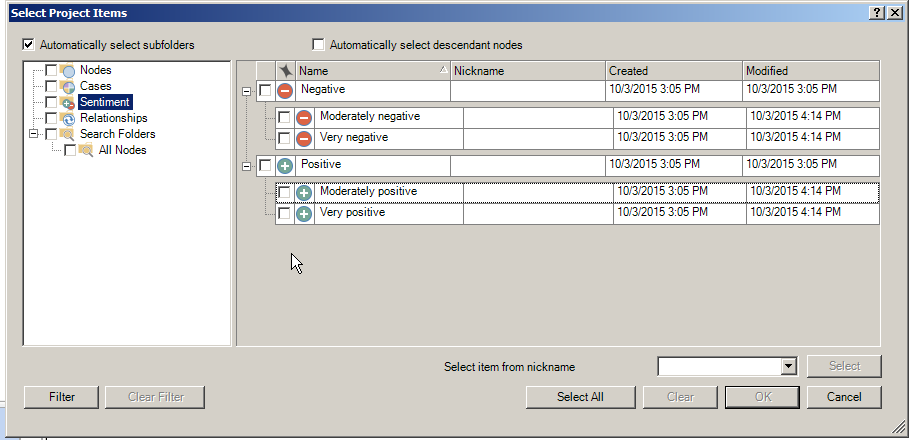
The categories of sentiment in this tool are four-fold: very negative, moderately negative, moderately positive, and very positive. The sentiment analysis is generally achieved by comparing a test set of text against a pre-created labeled dictionary of terms weighted by “sentiment.”
Since then, the study of sentiment has evolved to various types of emotion analysis. Some types of sentiments are conceptualized as transient and others as dispositional and more long-term. There are various types of integrated sentiment analysis approaches to research to capture sentiment from a variety of sources (and not just the target customer of interest).
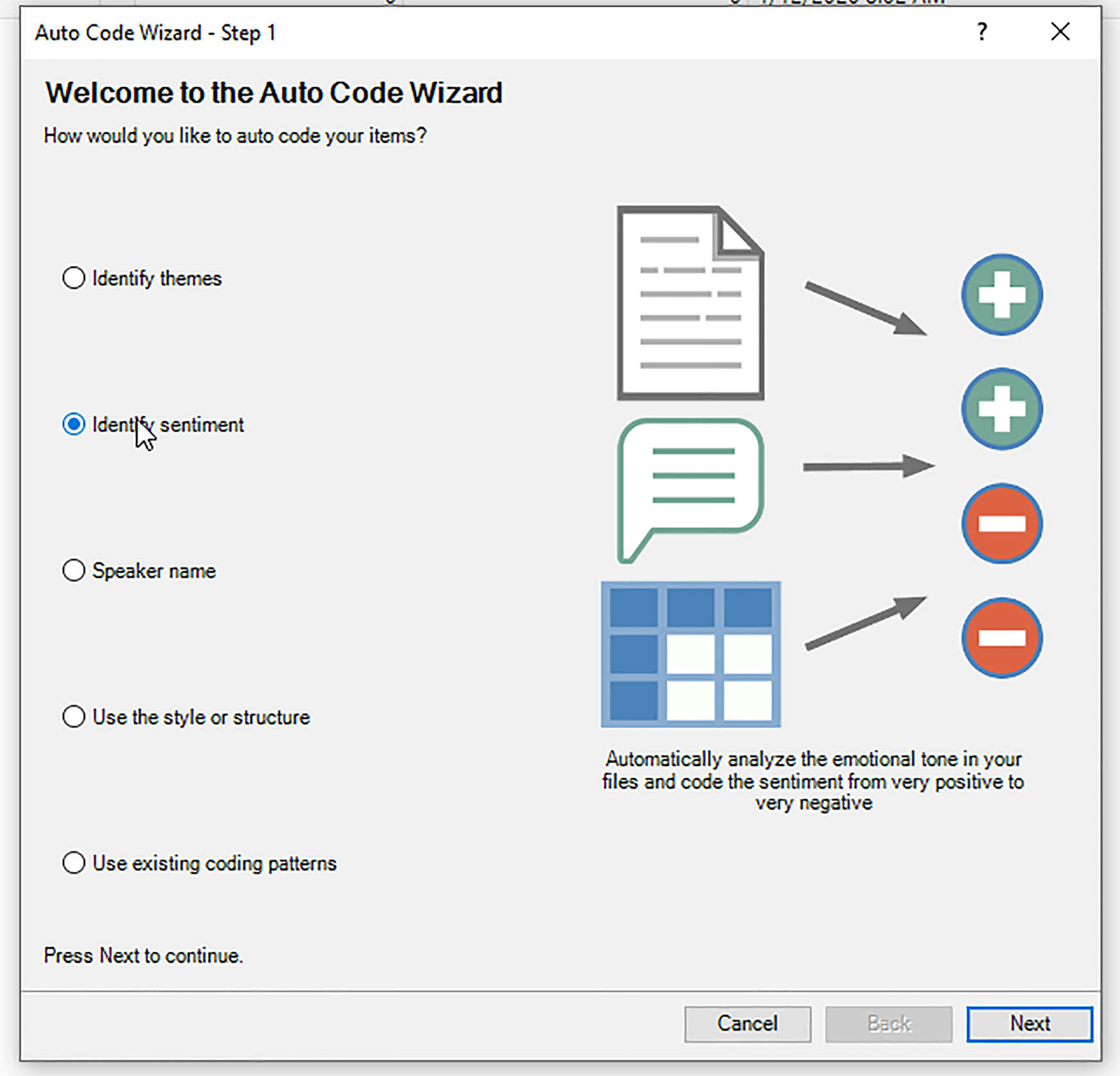
To start this sentiment extraction and analysis process, select the original textual source contents from which the sentiment will be extracted. It is possible to hold down the SHIFT or CTRL keys in order to select multiple files or nodes (or even folders) simultaneously. Click the “Analyze” tab, and select “Auto Code”. The window for the Auto Code Wizard will open.
{kind=link}
Select “Identify sentiment.” Click “Next.”
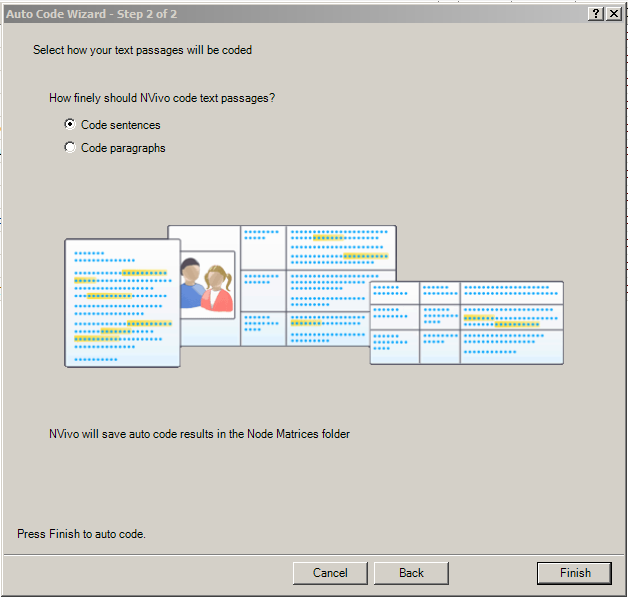
In the next screen, select the level of granularity for the sentiment analysis, whether at the level of sentences or paragraphs (or cells, if relevant).
{kind=link}
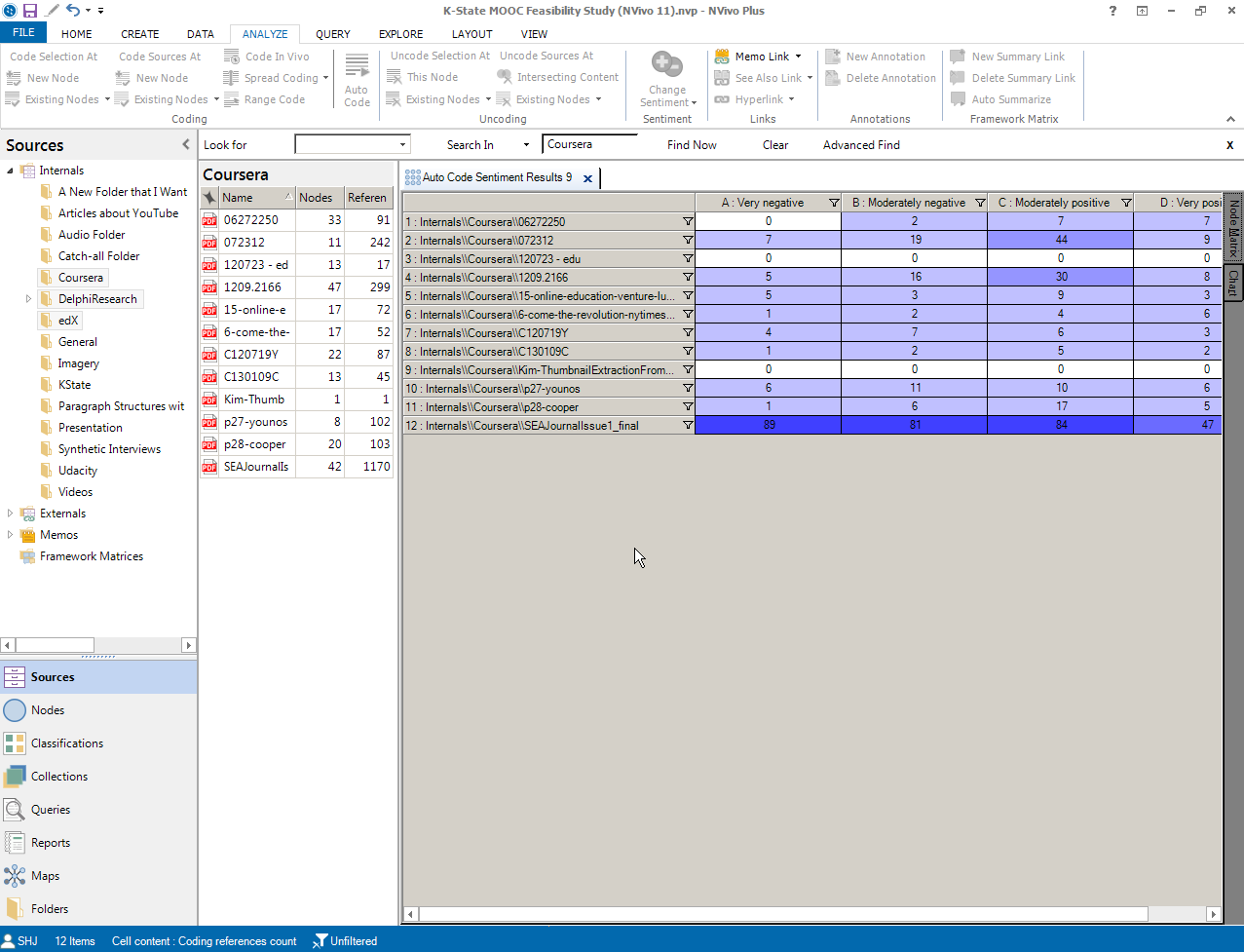
Click “Finish.” What results will be an intensity matrix based on the outcomes. In cells where there is no obvious sentiment, the cell is left unshaded with the number 0. In terms of a high number of coded passages with a certain sentiment, those areas will be reflected by higher numbers in the intensity matrix and darker cells—to indicate the frequency.
{kind=link}
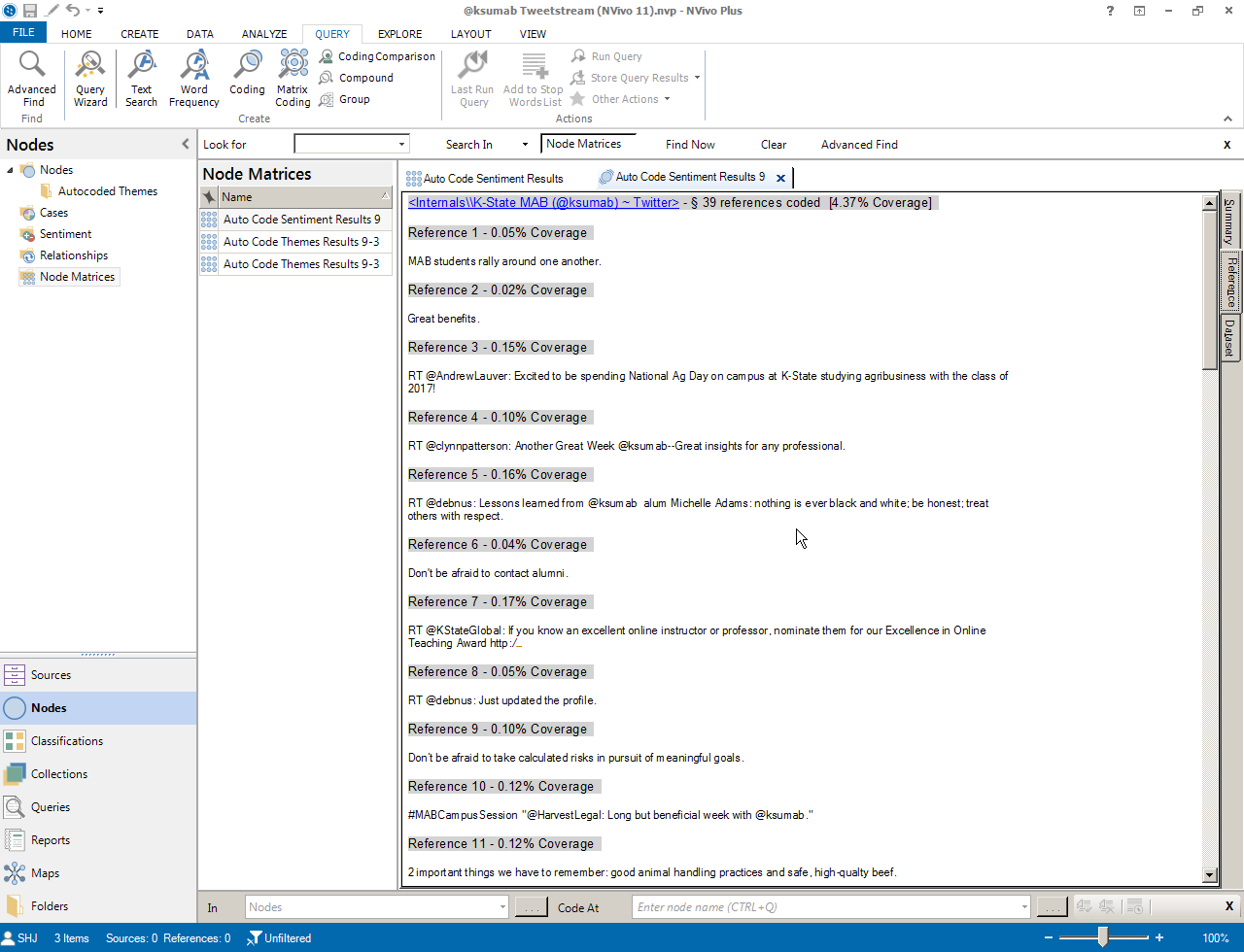
Researchers may explore the categorized data by double-clicking on respective cells to which what text was coded to which category of sentiment. (A majority of the text will generally be considered "sentiment neutral"--but the amount of text which is "positive" or "negative" will vary based on the text genre type. Lists of words do not work as well as texts with full sentences given the ability to select coding by sentence or paragraph.) The textual data also shows the percentage coded and offers a live link to the original source file.
{kind=link}
Users may also highlight words, phrases, sentences or paragraphs...and right-click to get a dropdown menu...and "Uncode Selection" to remove that text from an autocoded sentiment category for that query. Removing those words or string data from the set will not change the underlying sentiment dictionary (or set) but will change the outcomes of that particular sentiment autocoding.
Or, the researcher may re-code the selection to another sentiment category. In this case, he or she would highlight the text, right-click, and "Code Sources to Existing Node" (in the Nodes -> Sentiment folder). This is a way to change the polarity of the original source contents. This also does not change the underlying sentiment dictionary or set against which new texts are run, but it will change the sentiment query run on the particular textual data.
{kind=link}
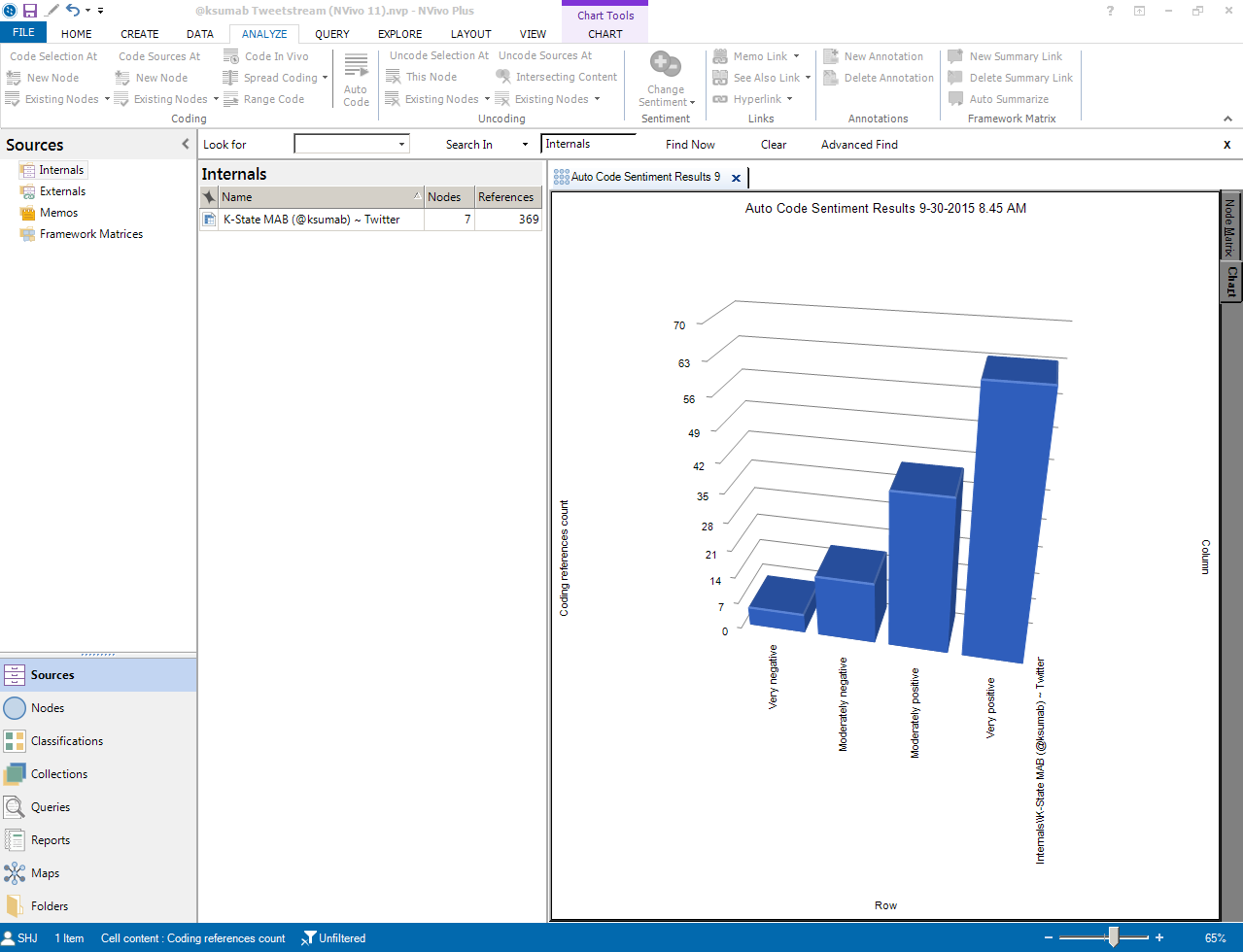
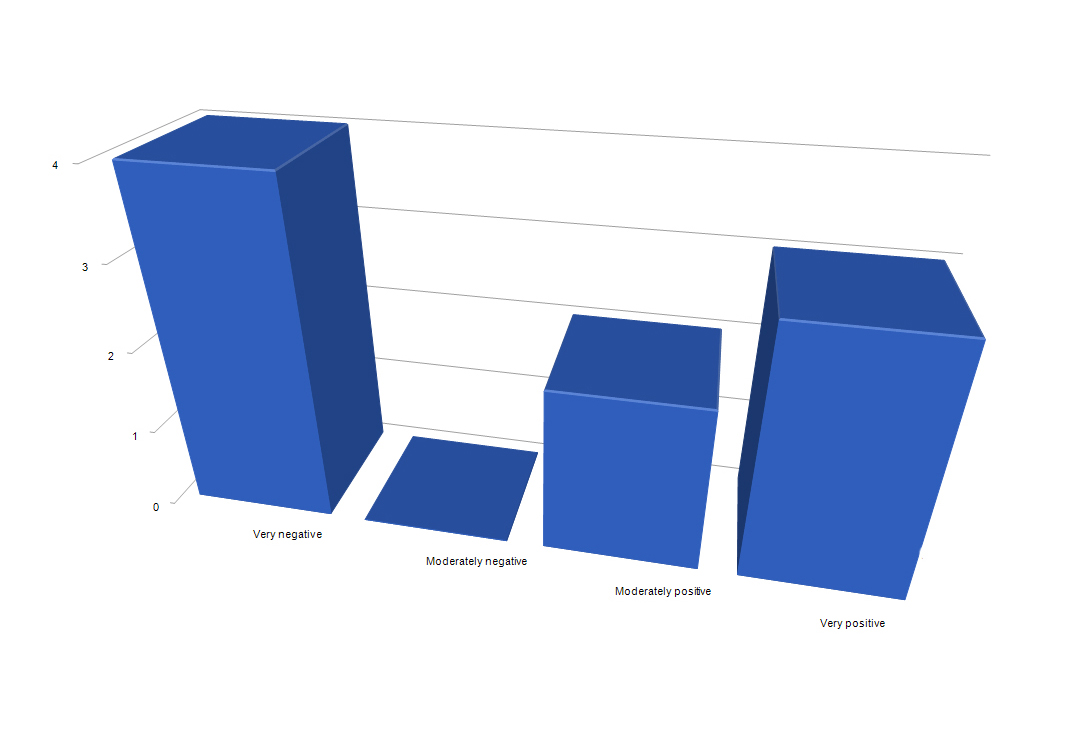
The results of the sentiment analysis may also be portrayed as a three-dimensional bar chart.
{kind=link}
Exploring the Sentiment-Labeled Data
While the sentiment analysis designation is a general type of textual summary, there are micro-level understandings that may be extracted. By clicking on the respective cells of the intensity matrix extracted for sentiment analysis, researchers will be able to see what text as placed into which category--which may be informative of both the original set of information (and also how the pre-labeled sentiment dictionary works).
There may well be other downstream applications as well from the extracted labeled text. For example, the sentiment-labeled text may be exported and analyzed in a program that sets up auto-created text networks to show interrelationship between the words (proxemically or within sentences). A text network (expressed as a graph) is sometimes able to provide a kind of text summarization through network text analysis.
What is Not Captured
Per the QSR International site, this sentiment analysis tool does not capture the following: "sarcasm, double negatives, slang, dialect variations, idioms, and ambiguity" ("How autocoding sentiment works"). Humor is not included either. There is clearly room for human "close reading" of the source documents. This is still the case with NVivo 12 Plus.
Also, coded text may be uncoded or recoded to the proper categories for a more accurate frequency count for each category...
Data Pre-processing and Data Post-processing
To capture certain types of data, researchers may pre-process data to enhance the findings of the sentiment analysis. Various types of data pre-processing may include adding or removing punctuation, labeling or tagging information, and other efforts. (Data pre- and post-processing may be done in a range of tools. For "big data" datasets, these are usually handled in the cloud...on spaces like Google's BigQuery...or on other cloud platforms with other frameworks. For smaller text sets, these may be processed using programming languages like R or Python. For small sets, software tools like MS Word and Excel are totally sufficient, with the help of text editors like Notepad to clean off formatting.)
Some sentiment analysis tools enable customizations: the identification of particular terms of interest, labeling emphases, and other types of processing. (One approach involves the use of XML tags to pull out textual features of interest. There are automated methods to apply various types of tags--such as parts of speech tagging. Once tags are emplaced, various scripts may then be written to extract meaning from the text or text corpuses.)
Finally, researchers may also post-process data after the sentiment analysis tool has been run. For example, if an individual disagrees with the labeling of particular text as positive or as negative, then he or she may remove that designation from the data.
Chaining Data Queries
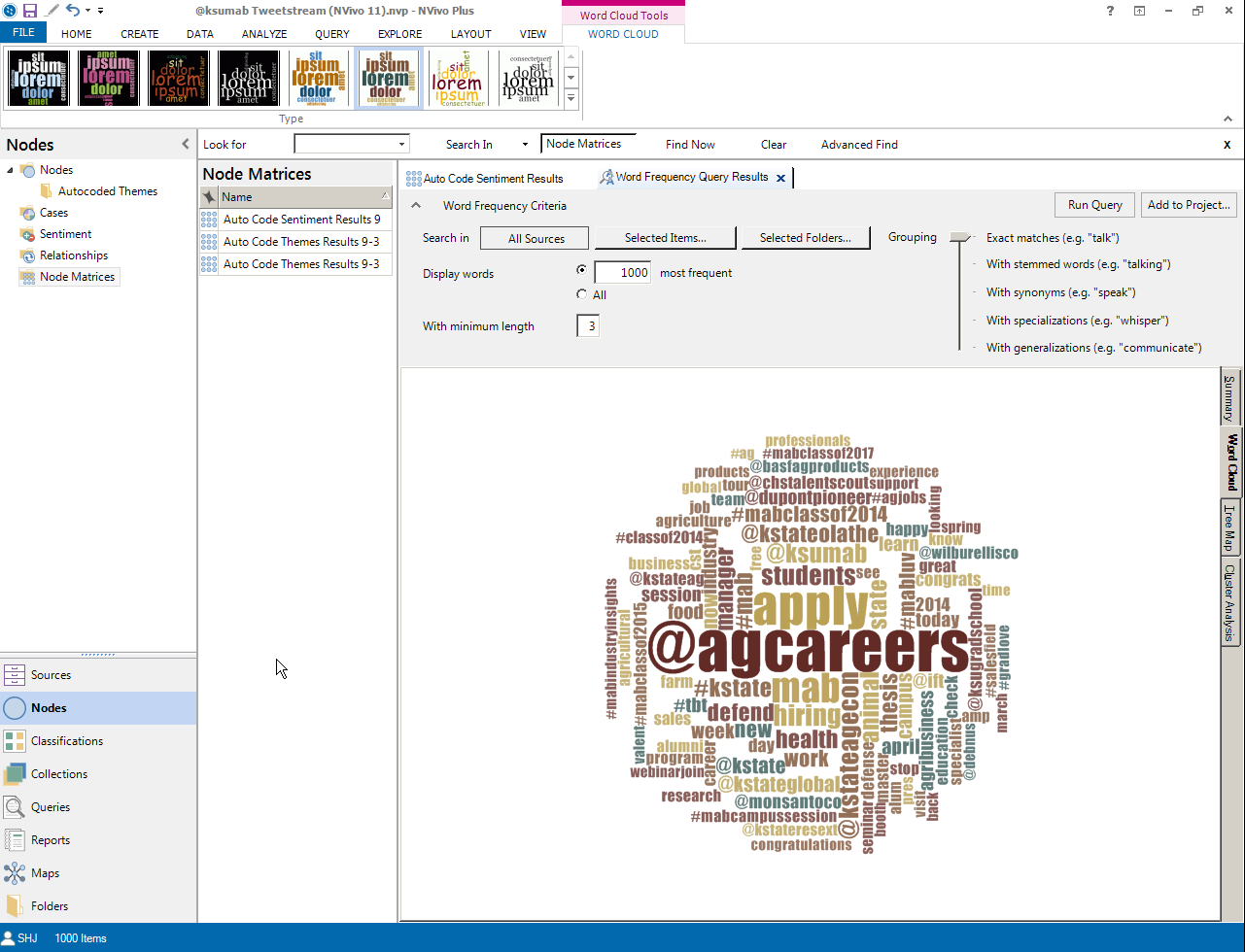
Researchers may also "chain" (sequence) their various queries...so they may take the results of the sentiment analysis and run further queries. For example, a text frequency count may be run against particular nodes labeled as "very negative," "moderately negative," "moderately positive," and "very positive." That would result in the most common words found in each category and may provide insight about what people find to be "very negative," "moderately negative," and so on.
If there are particular terms (or phrases) of interest, those may be used in text search queries. This way, particular phenomena indicated by certain terms may be explored in the textual context in which they occur.
It's possible to run matrix coding queries based on the extracted nodes. For example, it is possible to compare the "very negative" and "very positive" nodes to see what issues co-occur and about which people are highly polarized (in terms of sentiment).
And so on. There are myriad sequences which may be applied which may offer sentiment-based insights. (It's a good idea to document the sequence as one goes...and if one wants to repeat complex sequences, it's a good idea to encode these into macros within NVivo 11 Plus, so they may be run and re-run as new data is incorporated.)
{kind=link}
Sentiment analysis is an area of study within natural language processing (NLP).
With Larger Text Sets
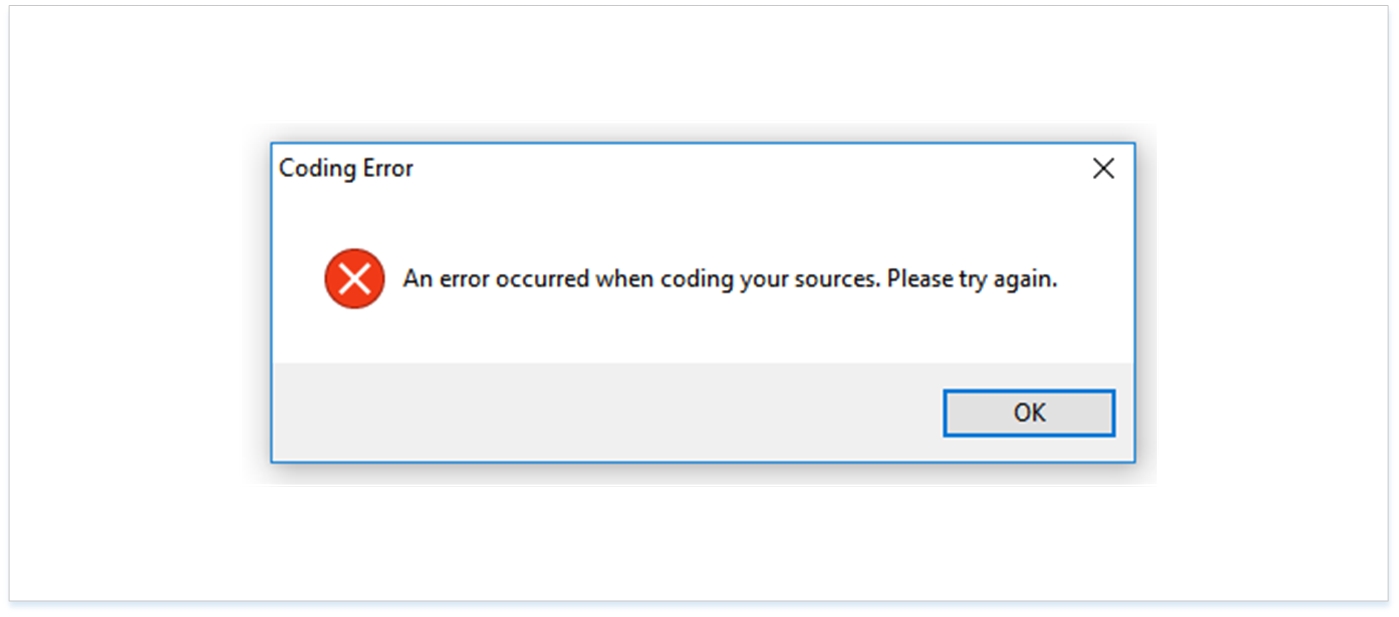
Sometimes, if text sets are too large, the locally-installed version of NVivo 11 Plus will not work. In such cases, a pop-up message will appear.
{kind=link}
One approach may be to chunk out the text into smaller non-overlapping parts, run the sentiment analysis on the smaller parts one after the other, increment the Sentiment Nodes, and then create visualizations and downloadable data tables from the cumulative sentiment node matrix. (Note that the gridlines behind the sentiment bars show the number of citations from the sources.)
This is a tested workaround.
As a side note, the author tried combining the underlying text using Adobe Acrobat Pro DC and then outputting that into Word as a large file and then changing that into a .txt or a .rtf to lower file complexity and size. That seems to help in some cases, but it does not sufficiently help with large sets (hundreds of text files and millions of words) of text data. Running a sentiment analysis on a very large text set often results in a majority of the text found to be "neutral" and then only a few citations for the respective sentiment categorizations. A screenshot follows. Note the y-axis with only a few citations in a sentiment analysis of a text with 202,000 words.
{kind=link}
A Note about Sentiment and Action
A general assumption about human emotion is that it is a motivating factor to the person taking certain actions. Anger is motivating to action, for example. Emotions are part of personality. Reading into the social-psychological and psychological literature can benefit the researcher.
Discussion of "“Autocoding” through Sentiment Extraction and Analysis"
Add your voice to this discussion.
Checking your signed in status ...