"Autocoding" through Theme and Sub-theme Extraction
Theme and Subtheme Extraction (Topic Modeling)
NVivo enables the automated extraction of themes and related subthemes from a text set. In this type of automatic text categorization, the computer extracts and creates the categories and then populates those categories with textual data from the target texts. This capability is based on "topic modeling" in machine learning.
{kind=link}
Steps to Automated Theme Extraction from Texts and Text Collections
To identify themes from an extant dataset, first, identify the source files and / or codes which you want to explore. Once those materials are selected, go to the Analyze tab. The Auto Code feature (in the Coding section of the tab in the Ribbon) will be in color, which shows that it is activated. Click the Auto Code button. The Auto Code Wizard window will open. Select “Identify themes.”
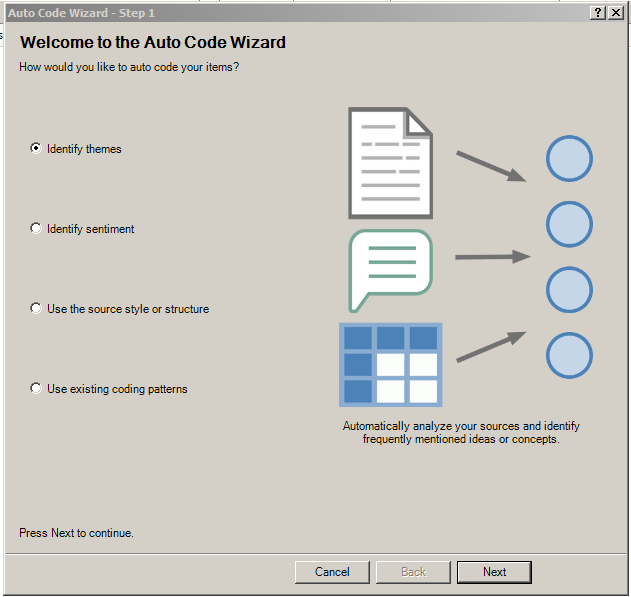{kind=link}
Click “Next.” In Step 2, the themes of the sources have been collected. A node is created automatically for each theme. (These are known as "base words".)
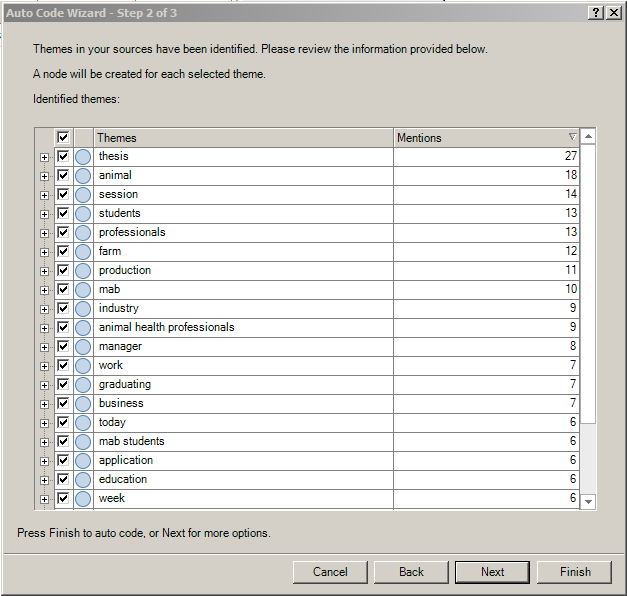{kind=link}
To view the sub-themes (subnodes), click on the plus signs next to each main theme. The sub-themes will display below.
{kind=link}
To include the extracted themes and sub-themes as nodes, leave the default topics checked. To exclude them, uncheck the desired themes and sub-themes in Step 2 of the Auto Code Wizard.
Click “Next.” In Step 3 of 3, a researcher may choose to code by sentence, paragraph, or cell (if the original information is uploaded in datasets of text instead of text documents).
{kind=link}
Click “Finish.”
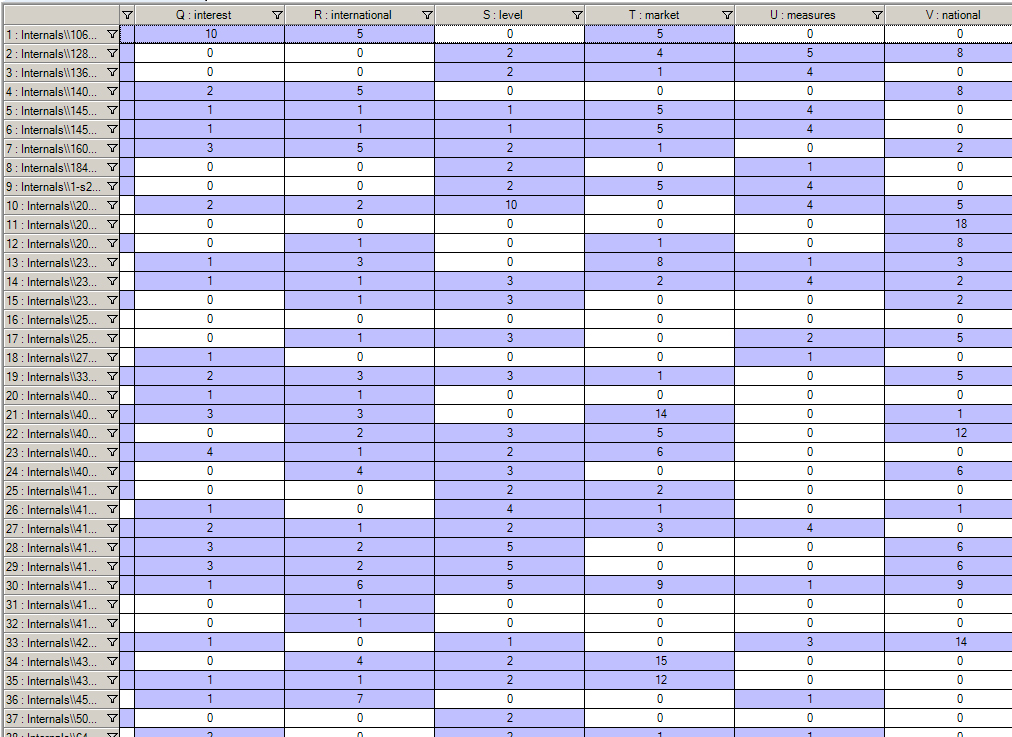
The results are shown in an intensity matrix (with the main themes in the top row). This matrix is scrollable horizontally (and vertically) based on the data distribution.
An Interactive Intensity Matrix
{kind=link}
The matrix is interactive, and a double-click on a cell will bring users to a page with the coded contents from the original source data. The following shows the results by sentence.
{kind=link}
The uses of an intensity matrix may become a little more clear when a full text corpus is used as a basis for theme and sub-theme extraction. Here, the original sources (listed in rows) may be selected based on their contents for human "close reading" (given their machine-identified relevance in terms of containing particular concepts and terms-of-interest).
{kind=link}
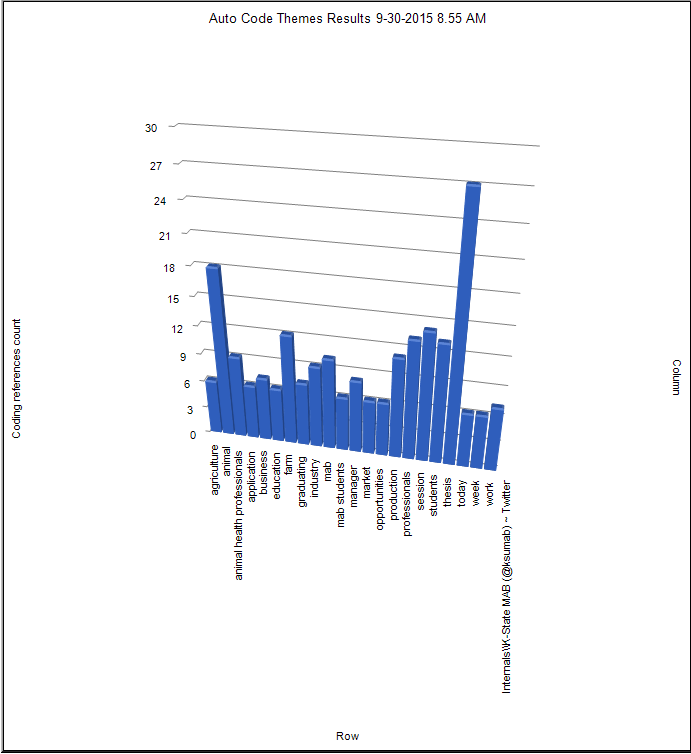
An Interactive, Zoomable, and Drag-able 3D Bar Chart Visualization
The results may also be viewed as a 3D bar chart. (The data may be filtered first--such as by the number of occurrences...or by topic...or some other way) instead of just going with the alphabetical order of the extracted themes. Themes may also be removed from the dataset.
{kind=link}
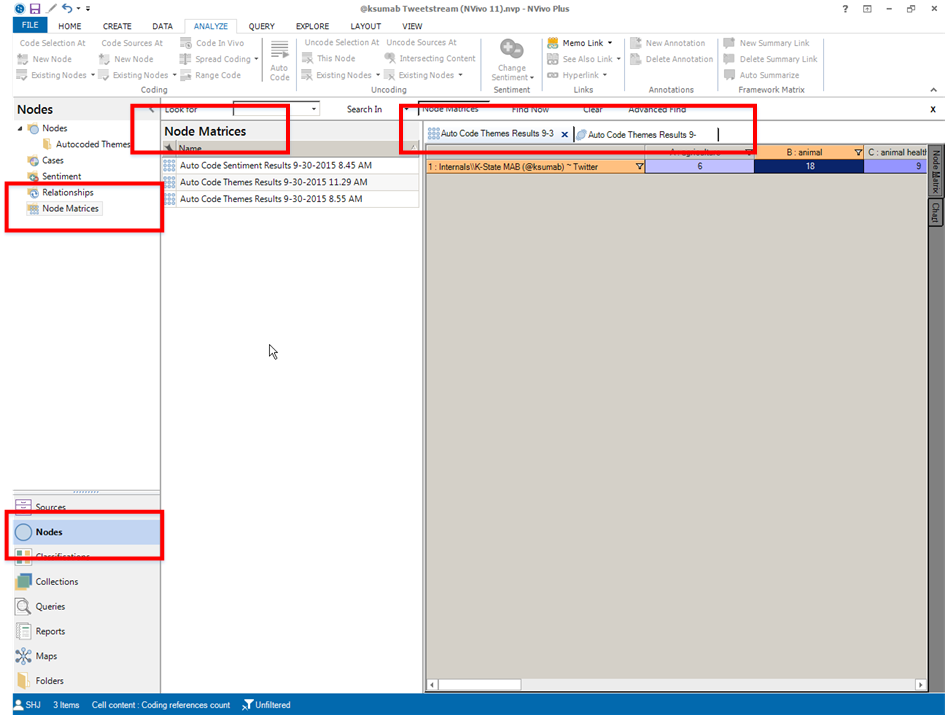
The results will be coded in the Node Matrices folder. To access the captured themes, click “Nodes” at the bottom left, select the “Node Matrices” folder, and in the List View, select the desired matrix.
A Node Visualization of Extracted Themes and Sub-themes
{kind=link}
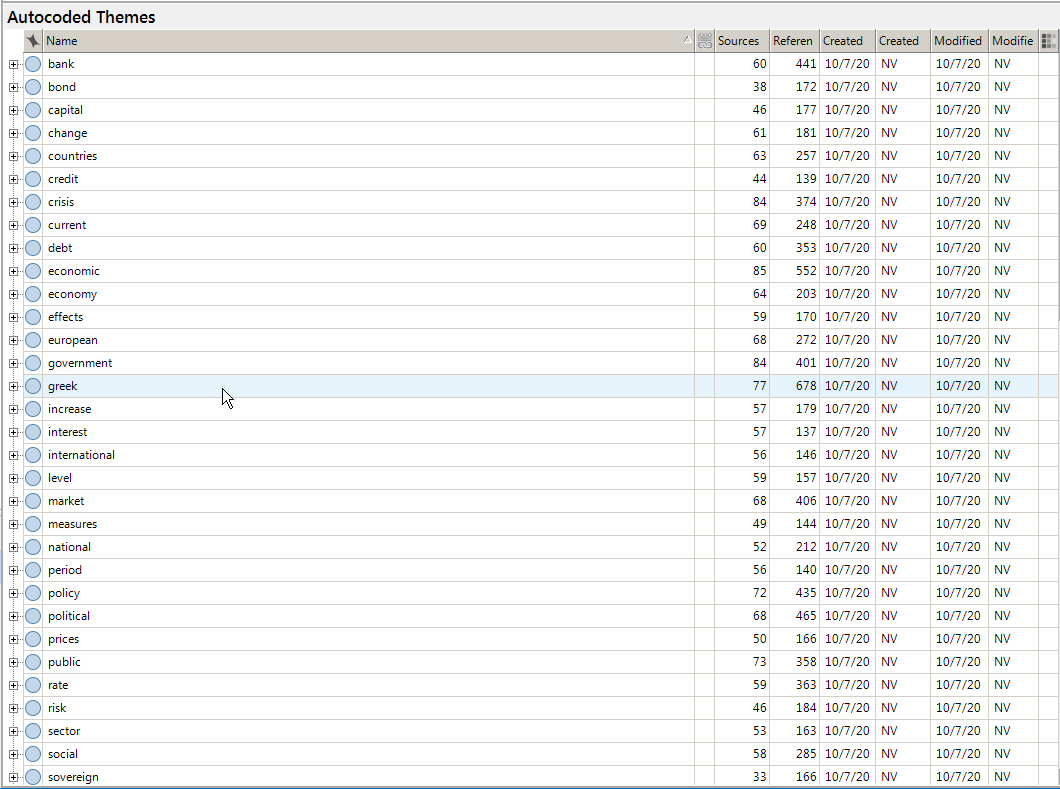
From the node view, an extracted set may look like the following. Do note that the sub-nodes (sub-themes) have not been expanded with the plus signs (in the visualization below).
{kind=link}
Autocoded theme extraction is a kind of unsupervised machine learning through extracting the structure of the underlying text data (to make it more human-consumable).
A Basic Threshold Amount of Text for Automated Theme Extraction
For the theme extraction tool to work, it is helpful to have a fair amount of text for the theme and sub-theme extraction. The extractions are usually done at the level of sentences, paragraphs, or cells. When running a theme extraction, it is important to ensure that the proper unit of extraction (sentence, paragraph, or cell) is set. If a text corpus contains sentences and paragraphs, that enables a level of theme extraction that may not be achievable with only a list of terms, for example. There are no hard and fast rules though since some lists contain terms that are more likely to be "thematic" and others less so.
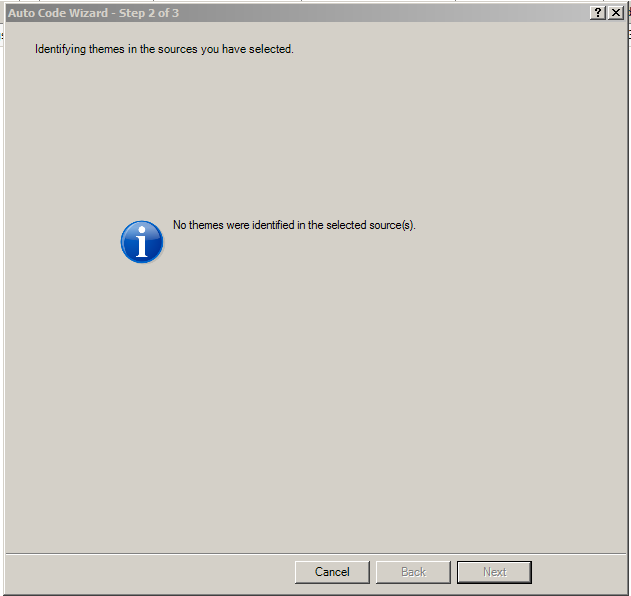
Sometimes, no themes are found from the sources. In those cases, the following message may be seen.
{kind=link}
Computational "Distant Reading"
In the literature, the use of computers to decode texts is sometimes referred to as "distant reading" (a term coined by Franco Moretti of the Stanford University's Literary Lab). This term is in comparison to human "close reading" of text. "Distant reading" is a statistical-based approach to text analysis and is seen as a complement to close reading.
There are other tools that enable different types of "distant reading." Automated sentiment analysis (enabled by NVivo 11 Plus) is one capability often included in distant reading. There are also various network graphs that show interrelationships between words--based on proximity, semantics, co-occurrence, and other relationships.
Engaging Bigger Data
{kind=link}
For larger text sets, it is possible to ingest the respective files into NVivo 11 Plus and process them in batches and update (increment) the respective top-level theme and child-level sub-theme nodes. This will result in a more dispersed theme-subtheme structure, but at least it enables the processing of large datasets.
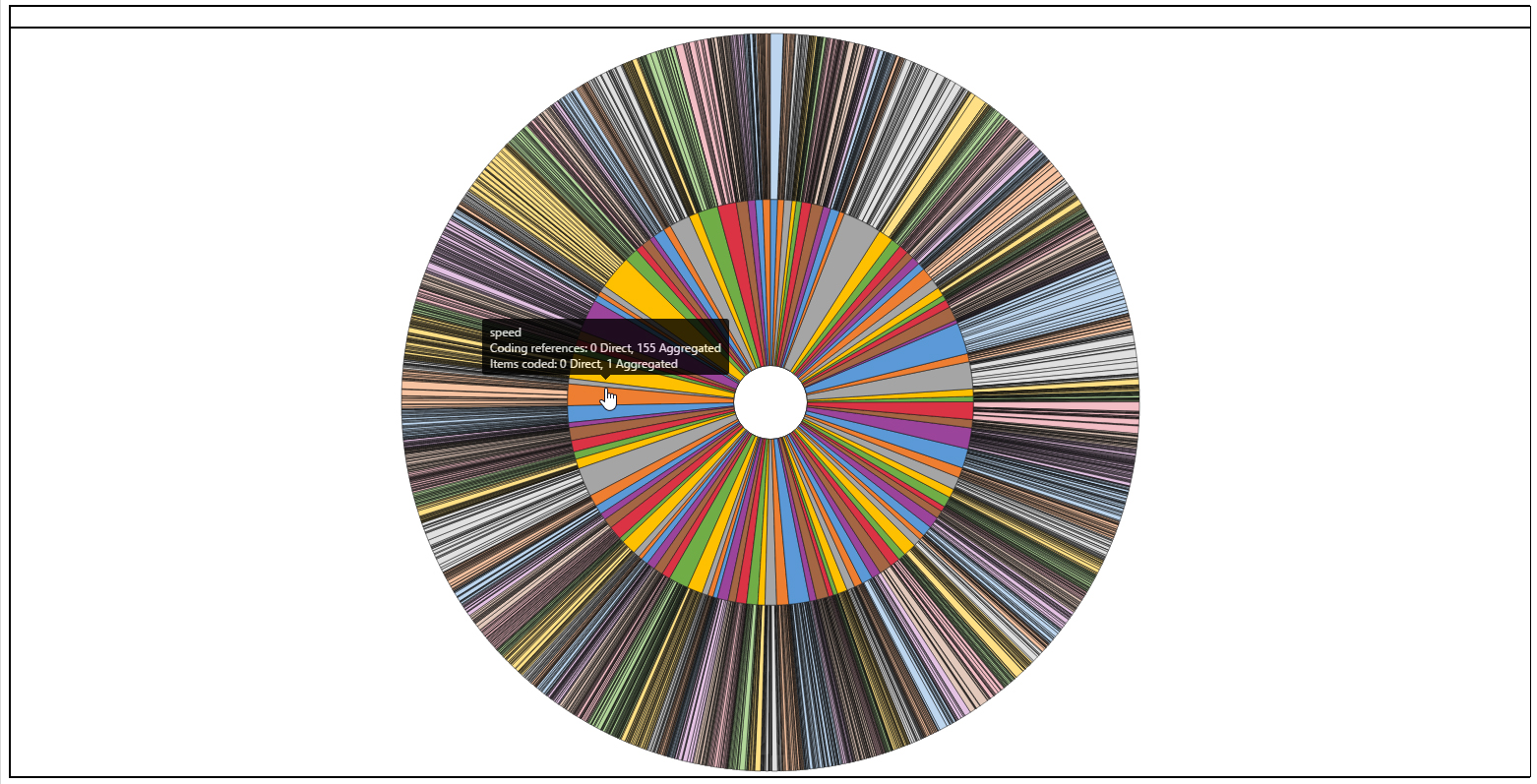
The finalized theme-subtheme node matrix may be visualized as a hierarchy chart (treemap diagram or sunburst diagram), with various color palette overlays.
And, the large autocoded theme nodes may be exported (as a .xlsx, .xls, .sav, or .txt file) for further analysis in other software programs.
{kind=link}
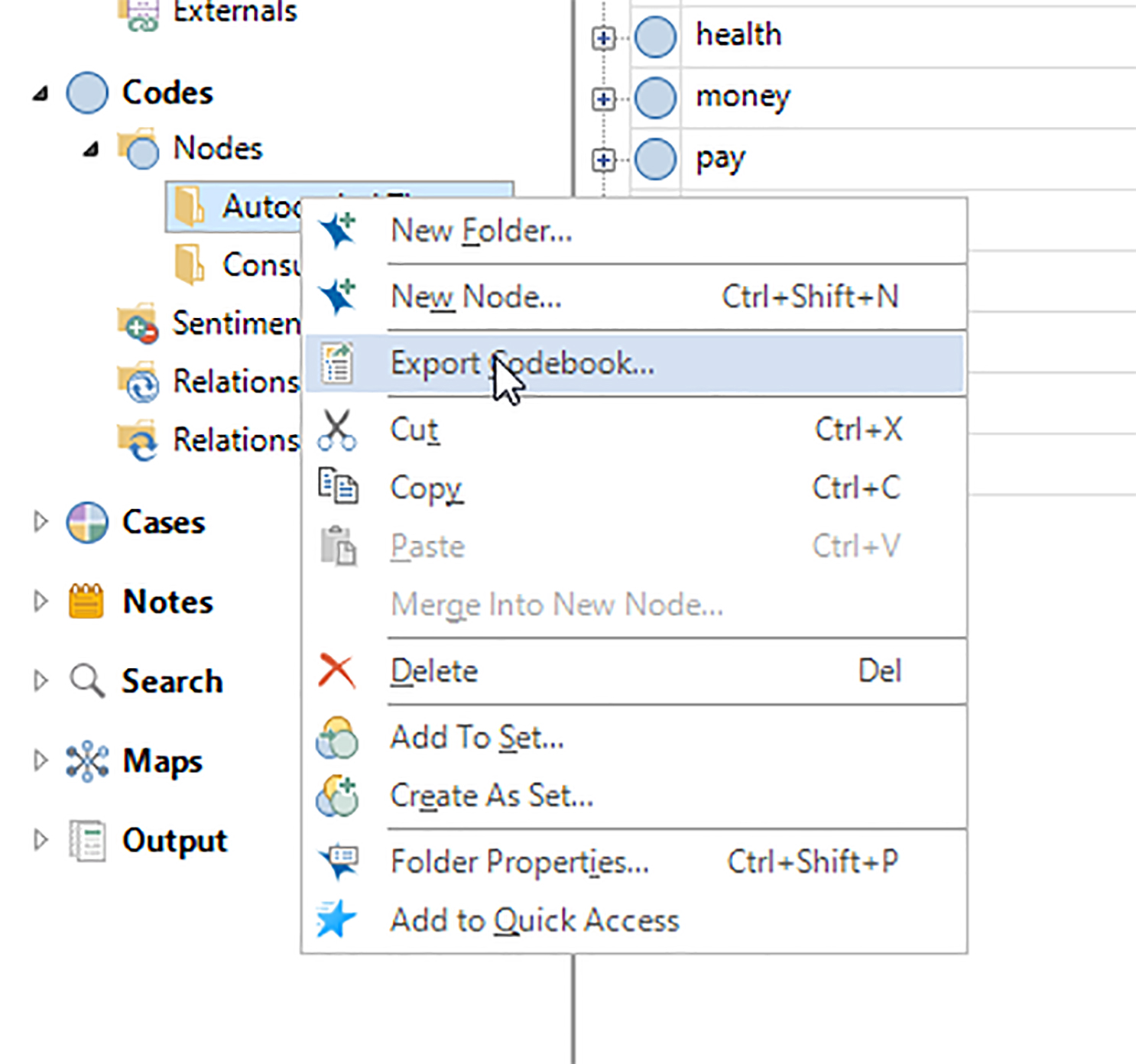
Exporting a Text Set of the Themes and Subthemes
To export a text set of the themes and subthemes, go to the Codes in the Left Navigation bar. Go to "Nodes." Identify the autocoded nodes that you want to export (as themes and subthemes). Select Export Codebook.
{kind=link}
Discussion of "'Autocoding' through Theme and Sub-theme Extraction"
Add your voice to this discussion.
Checking your signed in status ...