Scalar's 'additional metadata' features have been disabled on this install. Learn more.
Network Ecologies
Main Menu
Coordinates
Network Ecologies: Designing Scholarly Rigor in Innovative Digital Publication Environments
Network Ecologies Introduction
Archive Architectures
Transmedial Publishing Interfaces for Open Learning Systems
Displacement Paths
Organisms in Reticula
Letters From Distant Lands: Carolingian Intellectuals and Their Network(s)
Living Network Ecologies: A Triptych on the Universe of Fernand Deligny
A three-part introduction to Fernand Deligny from his English-language translator
The Entity Mapper
An Introduction to the Development and Application of the Open-source Software for Visual Data Analysis in Qualitative Research
Journeying A Thousand Miles
A Developmental Network Approach to Mentorship
Networks, Abstraction, and Artificially Intelligent Network(ed) Systems
A conversation with UNC RENCI's Dr. Reagan Moore and Dr. Arcot Rajasekar
Architecture Networks: Interview with Turan Duda and Jeff Paine
Exhibition: Network Ecologies Arts in the Edge
Duke University
Karin Denson & Shane Denson: Sculpting Data
Karin Denson & Shane Denson: Making Mining Networking
Rebecca Norton: The Edge Library
Network Ecologies Symposium
Contributors
Author and Editor Biographies
Imprint
Amanda Starling Gould
88396408ea714268b8996a4bfc89e43ed955595e
Florian Wiencek
ce1ae876f963bfc3b5cf6c3bbd8f57daf911e67f
Franklin Humanities Institute
Archive Architectures – Publishing Infrastructures
1 2016-01-04T11:14:09-08:00 Amanda Starling Gould 88396408ea714268b8996a4bfc89e43ed955595e 2553 5 Archive Architectures – Publishing Infrastructures. Image: © Soenke Zehle, Simon Worthington, Peter Cornwell, Pauline van Mourik Broekman plain 2016-07-18T15:41:02-07:00 Amanda Starling Gould 88396408ea714268b8996a4bfc89e43ed955595eThis page is referenced by:
-
1
2016-01-04T10:44:39-08:00
Technical Plan
29
plain
2016-08-07T15:27:09-07:00
3.1 Summary of Digital Outputs and Digital Technologies
There will be four digital outputs for the project. Two are Open Source contributions to the academic community as public infrastructure. The third output will be a series of digital prototype productions of a transmedia publication to demonstrate the research contribution to the field of Open Access and digital publishing. The fourth outcome will be a prototype workflow for the generation of custom OER (in cooperation with the OER team of the Afro-European Mokolo initiative).
3.1.1 Open Source Public Infrastructure
The following software release would look to be compatible with the following example software frameworks. Data Futures (Westminster University), A-machine (Hybrid Publishing Consortium), Scalar (University of Southern California), Booktype and Superdesk (Sourcefabric), Fiduswriter, Transpect (le-tex), Tamboti (Heidelberg Research Architecture) and Superglue.
3.1.2 Enhanced Transmedia Citation and Reference Management
In such citation and reference management, if text is understood in computational terms as a linear string similar to a point in the linear position of the timeline of a video or the trace of a game thread, then these points can be identified, cited, referenced and used in the context of a publication. The design of such a management system is complex, as the fixed properties of print media are no longer the only parameter and the publication becomes more of a recipe for combining a revision point in a variety of distributed media. These features would be explored in a usable Beta prototype software implementation as part of the rapid prototyping research process.
3.1.3 Platform Independent Publication (PIP) Type
This is a software implementation to test the the Platform Independent Publication type, using existing open document standards. Through the project’s research, co-creation and design research methods, these standards would be implemented in to facilitate their use by academic practitioners.
3.1.4 Transmedia Publications: Hybrid Publishing Consortium Prototypes
A series of hybrid publications would be released as digital publications, making use of the existing HPC material and context. Some of the digital assets would manifest as hybrid digital print objects via print-on-demand digital printing.
3.2 Hybrid Publishing Consortium, Data Futures and xm:lab—Open Source Publishing Infrastructures
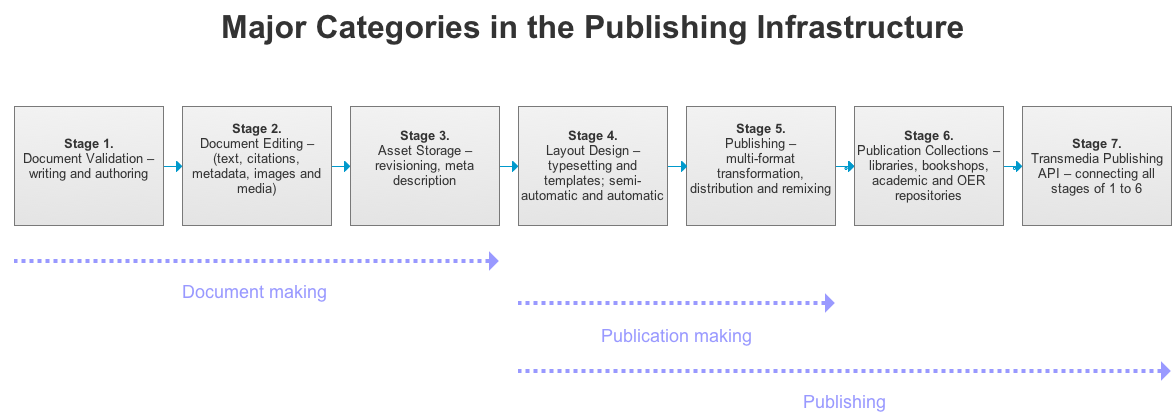
The long term collaboration and objectives of our research network (including HPC, Data Futures, and xm:lab) is to support Open Source infrastructures for transmedia, multi-format, scholarly publishing. Using single source architectures to output format such as; EPUB, HTML5, ODT, DOCX, PDF, PDF for print-on-demand. The stages in the publishing workflow and life cycle can be described as follows:- Document Validation—writing and authoring
- Document Editing—text, citations, metadata and images
- Media Editing
- Layout Design—typesetting and templates; semi-automatic and automatic
- Publishing
- Publication Collections—libraries, bookshops, academic and OER repositories
- Transmedia Publishing API
In this research project we focus on three of these stages: validation, asset management, and a transmedia API.3.2.2 Platform Independent Publishing (PIP) Standards
The objective of the project is to contribute to the working implementation of an open standards-based, transmedia-structured document, for multi-format publishing. A document-interactive validator will be a valuable tool for use by many document repositories containing unstructured documents that are not usable outside of very limited contexts. HTML5 as opposed to TEI or XML is emerging as the industry standard as an ‘intermediary file format’ with associated metadata and document settings, although this still has many problems such as footnote management. The benefits of machine-readable documents are that users can stay within their preferred writing environment while carrying out validation with the use of an API. The PIP standard allows for a variety of semi-automated processes, known as dynamic publishing—layout, multi-format conversion, distribution, rights management, file transfer, translation workflows, document updates, payments and reading metrics.
3.2.3 Innovations vs. Comparable Open Source Initiatives
Our project is defined by these features: it’s service is not a platform or markup language, and it works via an API so it is more like a feature set to add to other platforms. Points of comparison with other platforms include an interactive validator for platform independent, transmedia document for multi-format publishing; multi-format conversion (by connecting to existing A-machine, multi-format transformation engine); and multi-format design template generation and use. Neither current platforms (Fiduswriter, Booktype, Readthedocs, Sharelatex) nor markups and converters (LaTeX, Pandoc, or the python documentation generator Sphinx) meet all three criteria. The project offers a new publication GUI for transmedia OA and OER content, interactive inline validation GUI, web real-time updating GUI Javascript Web technologies, and design template libraries for multi-format layouts.
3.2.4 Software Development: Design Research, Working with the Technology Stack
The software development model establishes a three stage process of ‘Design Research’ for the working group. Firstly, research involves close development with the external open source expert contractors, secondly, testing; thirdly, the running of prototype publication productions as an advanced form of testing. Using this technology stack (validator, assets management and API) provides the design team with structured content and a development environment on which they can then experiment, test, and build templated design layouts for new types of publications. The API model has been chosen as it allows integration with existing open source platforms and encourages user adoption by minimizing workflow disruption caused by platform changes or reskilling.
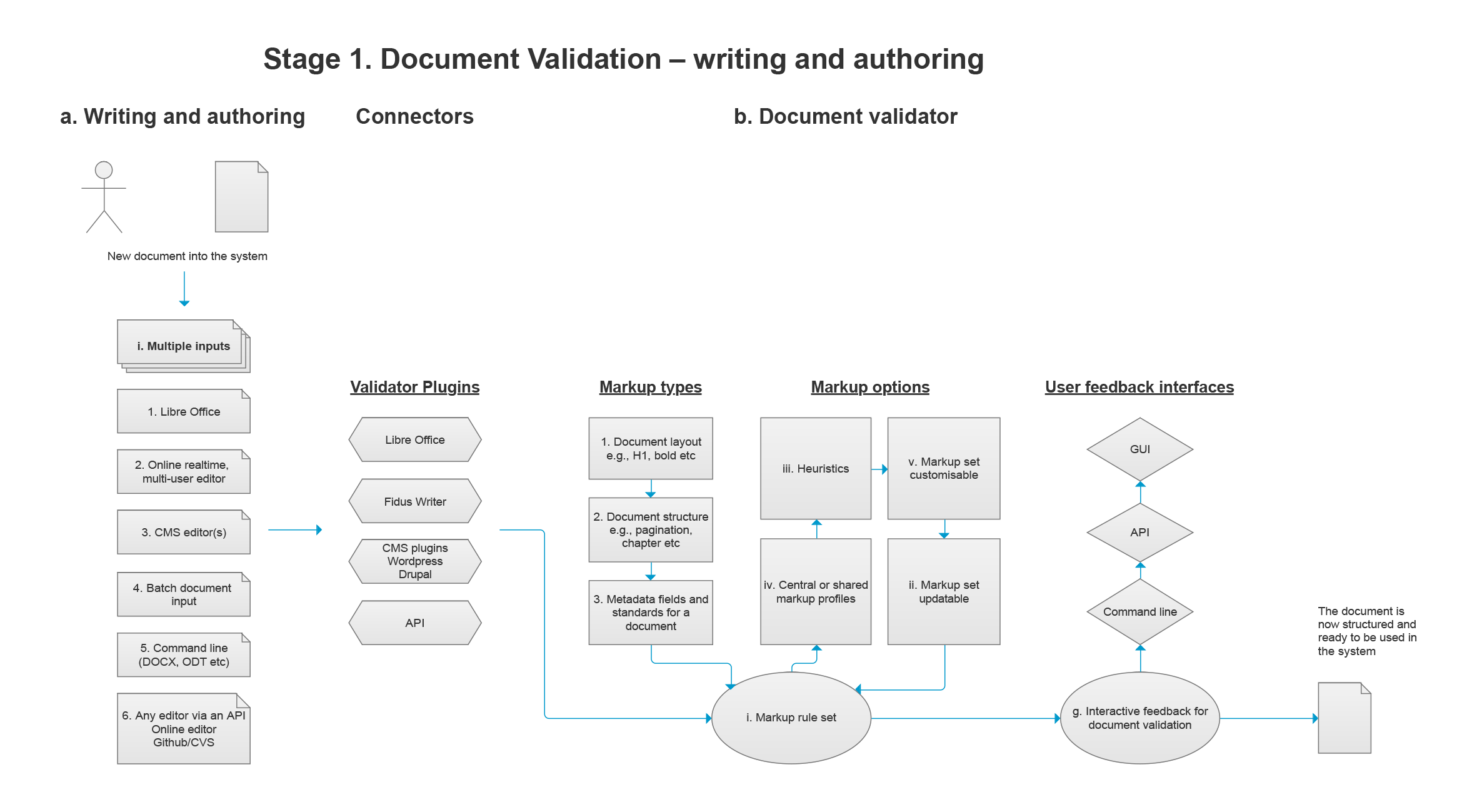
3.2.5 Validation for Document and Publication Structuring
This task creates a validation system for documents and publication files and asset structuring to have semantic information standardized for multi-format digital publishing, including layout, document structure, output format specific settings, and meta-descriptive information. To make a single source structured document, the validation system gives interactive feedback directly via a GUI (to prompt users to make decisions related to structural markup) or via an API.
3.2.5.1 Interactive Validator
A validator system ensures that the publication workflow structures documents and publication files according to standards and markup requirements that suit single source publishing workflows. As a result of a successful validation process, documents are machine readable and can be used in a variety of semi-automated publishing workflow processes. The validator has to cover different types of structuring that can be customized, including: typesetting (such as headers, bold, superscript, citation styles, line spacing after paragraphs, etc.); semantic document or publication structuring (picture credits, inline quotes, footnotes, pagination, chapters, and section, etc.); media inclusions (images, audio, video, equations, game sequence, etc.); document and publication file type and publication-ready outputs (PRO)-specific settings (image color profiles, print settings, job description files (JDFs), image resolutions, media queries, custom user output format design or content settings); multi-format document settings (i.e. instructions for conversion of a single source document into a specific format that involves information loss, such as a plain text file); a limited set of descriptive metadata (revision history, author, title, date, etc.).
The validator is also required to be interactive with a GUI and to work in an API environment. The interactive feedback is needed because a purely automated validation and structuring process would not be able to make the correct decisions and the files would end up with incorrect formatting. Instead, with an interactive system for user feedback, the user can intervene and make decisions when prompted to do so. Example cases where user feedback is needed divides into two categories. Firstly, workflow processing errors, for example invisible hyperlinks sitting in a document, which can be flagged up for removal in the way that a word processor’s ‘Navigator’ function allows a user to get an overview of a document. Secondly, common user errors, including not correctly marking up unordered lists, or using empty paragraph breaks rather than paragraph styles to make space between paragraphs.
3.2.5.2 Examples of Interactive Structuring Systems
The type of interactive validator we will be developing will be for inline interaction within a web based word processing authoring environment. Here is an example from the commercial product for structured writing called ‘EasyDITA’: http://easydita.com/explore/author/. Other types of interactive validation systems produce a report, for the user to respond to, by editing their document and then resubmitting for further validation. Examples are the International Digital Publishing Forum (IDPF) EPUB Validator (http://validator.idpf.org/) and W3C HTML Markup Validation Service (http://validator.w3.org/).
Important features of such systems include differentiating between a document and publication, where different structural and metadata requirements are needed. The validation markup and rule set options are: 1. markup set updatable and customizable; 2. heuristics rule sets; 3. centralized or shared markup profiles. Users interact with the validator via the following: 1. GUI; 2. API; 3. command line.
Requirements, Specification and Standards for the Validator. A sample of categories for ‘validation’ and ‘single source’ file recipes includes:- document input types (DOCX, HTML5, ODT, GDoc (subset of ODT));
- publication output types, or what we have termed publication-ready outputs (PROs) that are made up of a combination file type specifications, metadata requirements for the distribution channel, and ‘style guides’ for editors and designers in creating specific publication components for multi-format publishing. Such components include tables of contents, front cover texts, and back cover texts. A PRO profile is needed per output format as one format will not automatically translate to another format, e.g. a print book to EPUB;
- definition of a single source file, which acts as a container for multiple sources of data, for example different image sizes from an external source for responsive web design, or second external citation, bibliographic and metadata for publishing purposes;
- information for multi-format outputting, design and templating, per output format user tweaks;
- types of media assets that could be included in a document or publication;
- types of structure and semantic information: document layout e.g., H1, bold etc;
- document structure e.g., pagination, chapter etc;
- and metadata fields and standards for a document.
3.2.5.3 Validator Schematic
3.3 Publication Asset Storage
The publication asset management component of the technology stack will use a MongoDB-based NoSQL infrastructure, which will provide a highly scalable and proven platform for heterogeneous file types together with multiple application programming language bindings. Shared management facilities and efficient use of potentially large numbers of distributed virtual machines makes MongoDB ideal for prototyping and refining a very flexible asset management system. The partners have significant experience in developing loadable javascript-based environments for GUI workflow development with MongoDB, and experience supporting them on major projects with Heidelberg, Princeton, and Westminster University since 2011, as well as providing asset management for several commercial publishing applications. Avoiding off-the-shelf solutions such as Drupal or Wordpress will reduce the project's vulnerability to third party support requirements, will simplify Open Source licensing, and will improve overall sustainability of the framework produced.
An important aspect of the work already conducted by the partners on automated transformation of digital collections is the ability to create and tune metadata exports to multiple XML standards representations, including both MODS and VRA Core4. In addition, a number of workflows already exist to parse asset structures and automate the creation of MongoDB data structures. Together, these sub-components will provide the project with a mature environment for distributed teams of contributors, allowing them to build fully-searchable digital collections of publications' components and create Library of Congress-compliant metadata. The resulting structure can remain as BSON in MongoDB or be exported into other ecosystems such as Tamboti (which uses the native XML eXistdb). Additionally, MongoDB's multiple application programming language bindings enable it to be interfaced rapidly with other components such as Zotero, and allow structured APIs to be implemented for additional project-specific elements of the technology stack.
These tools will be used to build sub-components of the technology stack with the following functionality:- contributor GUIs controlling decomposition of source documents into individual elements and their integration into a managed collection which can be searched effectively;
- creation of element metadata (using MODS, VRA Core, etc where possible) and editing elements in line, together with version control;
- delivery of versioned publication elements to processing modules;
- output template management, editing and version control;
- interfaces with citation management systems, e.g. Zotero;
- interfaces with other content distribution networks.
3.4 Transmedia Publishing API
An Application Program Interface (API) is the way in which our systems’ modular components can communicate with other systems on the internet securely. This means that the functionality we are researching and developing (validation, publication asset structuring, templates) can be integrated into these other systems that we are connecting to. The proposed API allows access to internal modules (Validator, Assets, Design Template Library, and Multi-format Transformer) as well as to external services. Additionally, the use of the API allows the project to use external functionality. For example, link to the software ecosystem called A-machine, with its multi-format transformation software, currently developed by the Hybrid Publishing Consortium. Using the API model of service provision best suits the introduction of solutions to common problems in the Open Access workflow. The API model is one where external features and services like citation management platforms like Zotero and university library distributors such as EBSCO can be integrated. Another benefit of the API model for service distribution is that users can stay within their familiar writing environments. This has the added benefit of encouraging adoption of new services like ours. For these major reasons we see using an API as being the best way to benefit the Open Access community.
3.4.1 Functionality Areas and Use Cases for the API
The API will have four functionality areas:- Validation rule set. An external document editing system will be able to have our rule set applied to its documents to raise appropriate flags when a questionable content section is encountered (and to have these flags passed to other systems, and, if appropriate, allow changes and edits to be made to the remote document). The result would be that remote documents could be structured for multi-format conversion.
- Assets and asset structuring meta description framework. The effect here is that remote systems could store their content on our system, then make use of that content in different ways to, for example, extract all citations or images and captions from an archive and then extract and use these components on a granular level.
- Templates for authoring and using templates. Templates could be added to the system for use in making multi-format publications using the transformer engine.
- Transformer. A multi-format conversion engine. After a set of content has been approved by the validator, it could then be sent to the transformer with instructions to use a specific template and be outputted to a number of formats (EPUB, responsive HTML, HTML Book-in-browser, PDF, PDF for print-on-demand [PoD] etc).
The API is used in- Validation (other systems can have their content structured via use of our API);
- Assets (currently this is for testing purposes, to evaluate how multi-format publications can be stored as a single source master file, which acts as a recipe for its various publication format outputs and can accept different sources to be combined to make these output documents, combining media from different sources. e.g., Pandora, Tamboti and Open Journal System (OJS) etc.);
- Templates (this requires connection to content distribution networks (CDN), so that designers can author templates in software and graphic design libraries they are familiar with, like Bootstrap. The research challenge here for the projects design team is in effect to create modified Bootstrap models for apps, mobile, EPUB etc. Examples would be the open licensed and open source frameworks BakerFramework or PugPig (http://pugpig.com/) and famo.us; The CDN model needs to work for template use, too, so that users in another system can check out a template we are creating);
- Transformer multi-format conversion (send files for multi-format conversion to our engine A-machine and receive back the output files).
3.5 Technical Methodology
At the project’s core, we would use co-creation and design research methods to establish the software requirement to address the two central research concerns—transmedia referencing and citation, and document portability. Our research approach includes the following elements:- Hybrid Publishing Consortium—for the project, the context of the existing HPC prototypes provides an experimental framework to keep our research horizon open to extra-academic innovation practices.
- Rapid Prototyping—a workable transmedia publishing framework will be established early on to experiment with the incorporation of a wide array of content types in publication prototypes.
- Discourse Analysis—focusing on how technology is shaped by the social, methods such as the discourse analysis approach of T-PINC - Technology, Power, Ideology, Normativity and Communication (Koubek, University of Bayreuth), will be employed to better understand the forces acting on technology development.
- Software Requirements Process—conventional software methods such as Sommerville’s software requirements process will also be employed, with three repeated phases—requirements gathering, specification and validation.
- Open Source—design methodologies of open code review will be used. All research publishing will be carried out as Open Access, under Creative Commons Attribution ShareAlike 3.0 license.
3.5.1 Comparative Software Tools Assessment
A comparative assessment of available approaches and open source tools, including:- Data Futures—NoSQL repository migration and long term preservation system. Flexible and custom workflows. http://www.data-futures.org/
- A-machine—publication multi-format digital conversion, automatic design templating and distribution. Hybrid Publishing Consortium. http://consortium.io/ and http://a-machine.net/
- Scalar—multi-media authoring and publishing. http://scalar.usc.edu/
- Public Library—book scanning and digital librarianship of contemporary reading and books. With connections to Open Library, Archive.org project. https://openlibrary.org/ and https://www.memoryoftheworld.org/
- Amara, Participatory Culture Foundation—Crowdsourcing annotation. http://www.amara.org/
- Textus, OKF—Document annotation. http://textusproject.org/
- Zotero—citation management, Roy Rosenzweig Center for History and New Media, http://zotero.org/
3.5.2 Standards and Formats
For documents OASIS, W3C and IDPF open formats are used. Primarily this will be HTML5 and EPUB3, with attention to emerging EDUPUB W3C and IDPF initiatives announced in a January 2014 W3C call with contributions from publishers Pearson and O’Reilly. http://www.idpf.org/epub/profiles/edu/. For citation and referencing purposes this would make use of a combination of Dublin Core (DC), Open Archive Initiative (OAI), and open Citation Style Language (CSL). Additionally, we would use a set of collections and bibliographic management meta description frameworks, Visual Resources Association (VRA) Core 4.0 and Metadata Object Description Schema (MODS) from the US Library of Congress and Text Encoding Initiative (TEI) for text.
3.5.3 Hardware and Software
Software used in the project will be MongoDB, Ruby, Transpect from le-tex, Scalar, A-machine framework, Linux, NodeJS, Linux, GitHub. Book scanner from the Public Library project http://www.ahrc.ac.uk/News-and-Events/Events/Pages/The-Public-Library-Project.aspx
3.5.4 Data Acquisition, Processing, Analysis and Use
Core data for the project would come from the ‘Typemotion’ publication and exhibition. Other data would come from partners as well as from stakeholders. Data analysis would be carried out in consultation with industry stakeholders such as Westminster Data Futures project, HPC, Fiduswriter, and le-tex.
3.6 Technical Support and Relevant Experience
Core technical lead comes from the Westminster Data Futures project, HPC, Sourcefabric, Fiduswriter, and le-tex.
3.7 Preservation, Sustainability and Use
3.7.1 Preserving Data
Data Futures specializes in long term data preservation. Data and code would be stored on the Data Futures’ distributed and secure long term digital preservation network.
3.7.2 Ensuring Continued Access and Use of Digital Assets
Published material and software code would be published under open licenses. With published materials being in Green Open Access repositories covered by CLOCKSS (Controlled LOCKSS) support. Code would be published on the open repository GitHub and registered with the UK and EU Open Source research repositories. For example: http://sparceurope.org/resources-repositories/.
{kind=link}
{kind=link}