Tools & Methods
In approaching my research of the novels, I first considered which digital tools to utilize. I also needed to address the limitations of my process.
{kind=link}
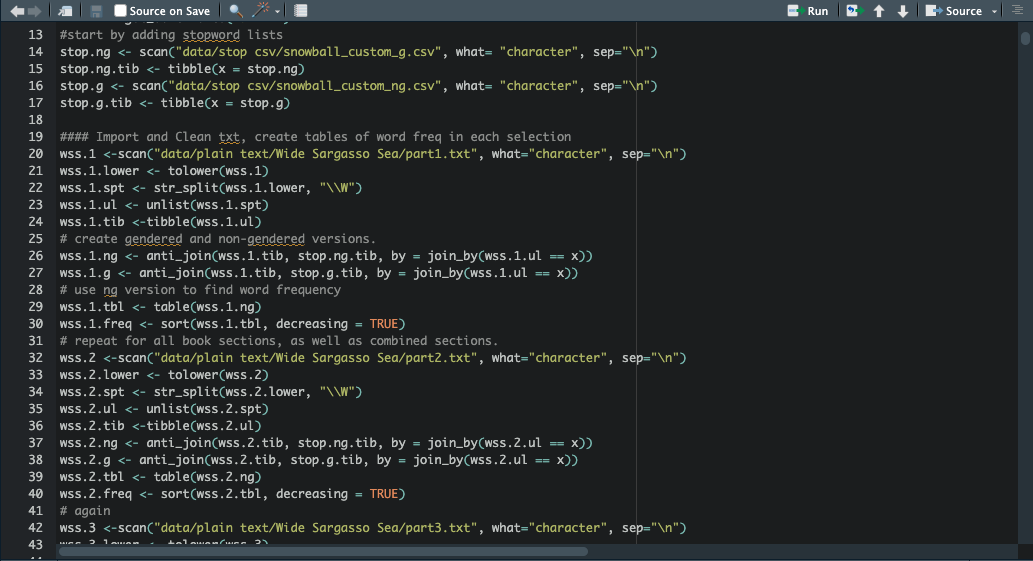
I already had some background programming in R for text mining, though I had to develop this skill as I worked. As a GRA in the Perry-Castañeda Library Scholars Lab I decided to make use of our resources, digitizing a copy of Wide Sargasso Sea from the collection with our scanners. Here I encountered the greatest hindrance to my research, as I was advised to limit my scans to 3 sections to remain within the boundaries of fair use. I endeavored to work with a representative sample by choosing the longest parts of the novel’s 3 acts. While Jane Eyre is not under copyright, I selected 3 chapters from it as well to maintain relatively similar sample sizes. For this, I downloaded the text from Project Gutenberg and selected three chapters that involve Bertha and the parallels between Jane's and Antoinette’s stories.
{kind=link}
After making the selections, I scanned WSS and performed Optical Character Recognition(OCR), and cleaned up the text using Google Docs. For my scripting in R, I used RStudio with a number of plug-ins for text manipulation and mining. Tidyverse and Tidytext were the primary modules used, with GGPlot2 used to create visualizations. I began with basic exploratory searches, looking at top word frequency and bigrams, then refined my searches using these initial results and popular themes in existing criticism such as the use of clothing to denote social status in Rhys novels (Joannou, 2015, p. 123).
This page has paths:
- Intemperate and Unchaste Willem Borkgren