research in helvetica
The pale gray surface like molded glass, tight cross-hatches and the vaguest sense of a prism—pale pinks and blues if you let your eyes soften. The vertical “I” of the cursor blinking in time, waiting as if tapping toes, and then almost at once—sounds and letters. The soundtrack of fingers on keys, the emphatic note of the space bar. Words seem to appear magically on the screen, and as I watch, I find myself keeping pace, willing the type to keep up with the sound. A sense of relief in the moments where the visual and aural words are in sync—so many, perspectives, study, and a bit of agitation when the cursor falls behind or when the red underline announces a typo—gflancing, direcytions, obliques, extanding. There’s a game in the watching, a competition between eye and ear. My two pointer fingers hunting and pecking for the keys, not quite fast enough.
The making of all the videos and this one especially, resembles the research work of transcription—listening through audio recorded dialogue (in my case interviews and workshop sessions) and typing out the speech as precisely as possible. Unlike this video, where the typing and sound are 1:1, that is, when the speaking is done, the typing ends (no matter the accuracy, precision, or completion), transcribing an interview file may be 4 or more:1. With stops and starts (foot pedals or slowed-down playback), voices speaking over each other, tricky accents, or poor tape, it typically takes at least four hours to transcribe every hour of audio. Sometimes you have to play a four second clip six or seven times before you can make it out. Because it takes so long, and can be quite boring, transcription is the grunt work of qualitative research. Many researchers farm out their transcription to paid services or research assistants, while others consider doing one’s own transcription vital analytical work[i].
The assemblage and In Helvetica in particular, bring forward this usually hidden work of transcription, highlighting (in all the missed words and misspellings) the challenge of doing it well. How hard it is to re-represent something as complex as spoken dialogue—to capture multi-vocal speech, the back and forth of interruptions, voices talking over voices. Furthermore, the recorded transcription of my own analysis functions as a sort of reversal of typical research processes. For example, in a typical qualitative analysis, the researcher would audio or video record an interview, transcribe the interview (or pay someone else to do it), analyze the transcription (by coding, sifting, memoing, or other methods) and write up an analysis that might excerpt portions of the original data (in written form).
{kind=link}
Written into this linear process are a set of assumptions about the kind of methods and media that “count” for scholarly research (writing) and which kinds of writing (academic writing versus memo-ing or coding) should be made public. It’s as though there’s a great big funnel, and media of all kinds flow into the cup—images, audio, reflective writing, etc.—but only some modes are fine enough to pass through the cylindrical tube below, while the rest are discarded or pressed into the contours of academic text.
Following the examples of recent turns in qualitative research including blurred genres, narrative research, and arts-based educational research, my work takes a different path, moving in iterative loops and curves. I transcribed the texts from a series of the participants’ annotated drawings, audio-recorded the transcribed texts, layered and remixed them (as a form of arts-based analysis), transcribed this new text using video to record the transcription, and finally wrote up the methods and analysis here (presented along with audio, video, and image). My process flips the traditional flow of research media from audio-visual, to transcribed text, to analytical text. And by presenting some part of each phase and medium, challenges the implied hierarchies that mark some media and ways of working as data/ in-process and others as scholarly/ final product.
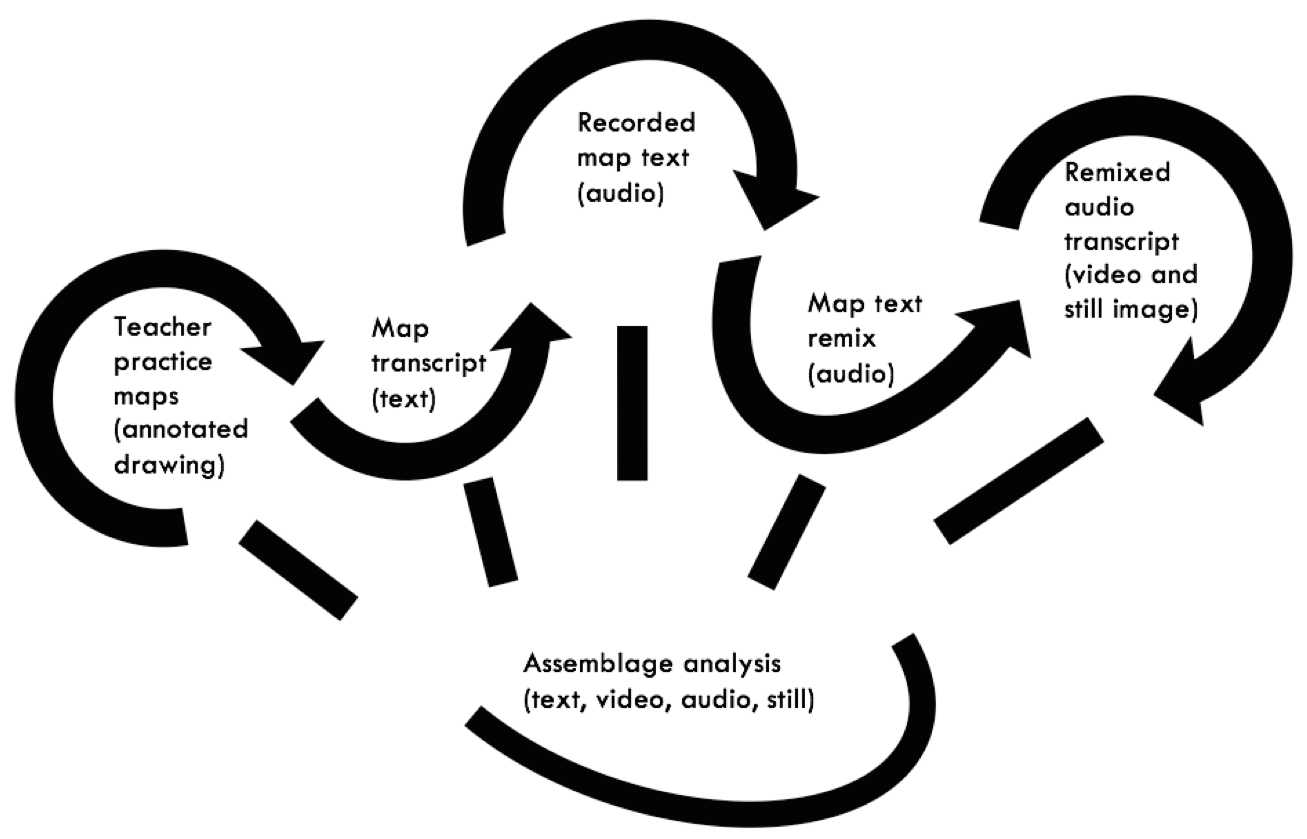{kind=link}
The assemblage references and challenges research processes in other ways too. The repeated phrases in the audio piece (eyes, high-fives) and the iterative and repetitive process of writing, recording, listening, and writing in multiple ongoing loops brings the work of “immersing oneself in the data,” to life. This is another often hidden element of qualitative research—the process of close reading, over and over again, of looking at images for long stretches, day after day. Sometimes, in the absence of a note or memo, there’s nothing to show for these hours upon hours, no trace of all that looking and wondering, noticing and not-yet-knowing what to “make of it.”
The assemblage takes up, twists, and makes visible my own methodological process as a tool of researcher reflexivity. As Luttrell (2010, p.4) suggests, “reflexivity is about much more than researcher self-conscious awareness. It is about making the research process and decision making visible at multiple levels: personal, methodological, theoretical, epistemological, ethical, and political.” So, in addition to making my own perspectives and positionality clear, I work—through the texts and sounds and shapes of this assemblage—to make my process accessible, to bring readers/viewers/listeners into my decision making, into the feel of materials, the theoretical orientations, and to highlight the parts of research work that aren’t always seen. Finally, these multimodal and often invisible elements of research, speak conceptually with the teachers’ texts as records of their own invisible labor. Their practice maps, insist on marking the everyday work—joining the labor of hauling school supplies with lesson planning with worrying about kids in tough circumstances. Their portrayals complicate thin public tropes about teachers and teacher work, instead painting a picture of teacher practice as thick and multifaceted—physical, emotional, intellectual, mundane and enmeshed with care.
[i] I transcribed about 60% of my 35+ hours of audio-recorded workshop and interview data.
{kind=link}
{kind=link}