Profiling an Entity across Multiple Social Media Platforms
By Shalin Hai-Jew, Kansas State University
In this hyper-social age, the “getting to know you” often happens in a mediated way and from a distance. When people check out other individuals and other entities (groups), they haunt social media sites, the Web, and the Internet, in search of particular “tells” or even “red flags.” Often, the surfaces that are touched are the public-facing ones, with the self (entity)-created public relations messaging and polished claims.
Less familiar approaches for such vetting involve data-mining approaches from these same online spaces. These data tend to be somewhat raw and less-processed, and the techniques (network analysis) for data extraction and analysis involve a somewhat steep learning curve (in terms of the software, the statistics, the data visualizations, and the data analytics).
This entry showcases how IGI-Global looks from different angles using three software tools (listed in the order of presentation): Maltego Chlorine 3.6.0, NVivo 10 (with NCapture), and NodeXL.
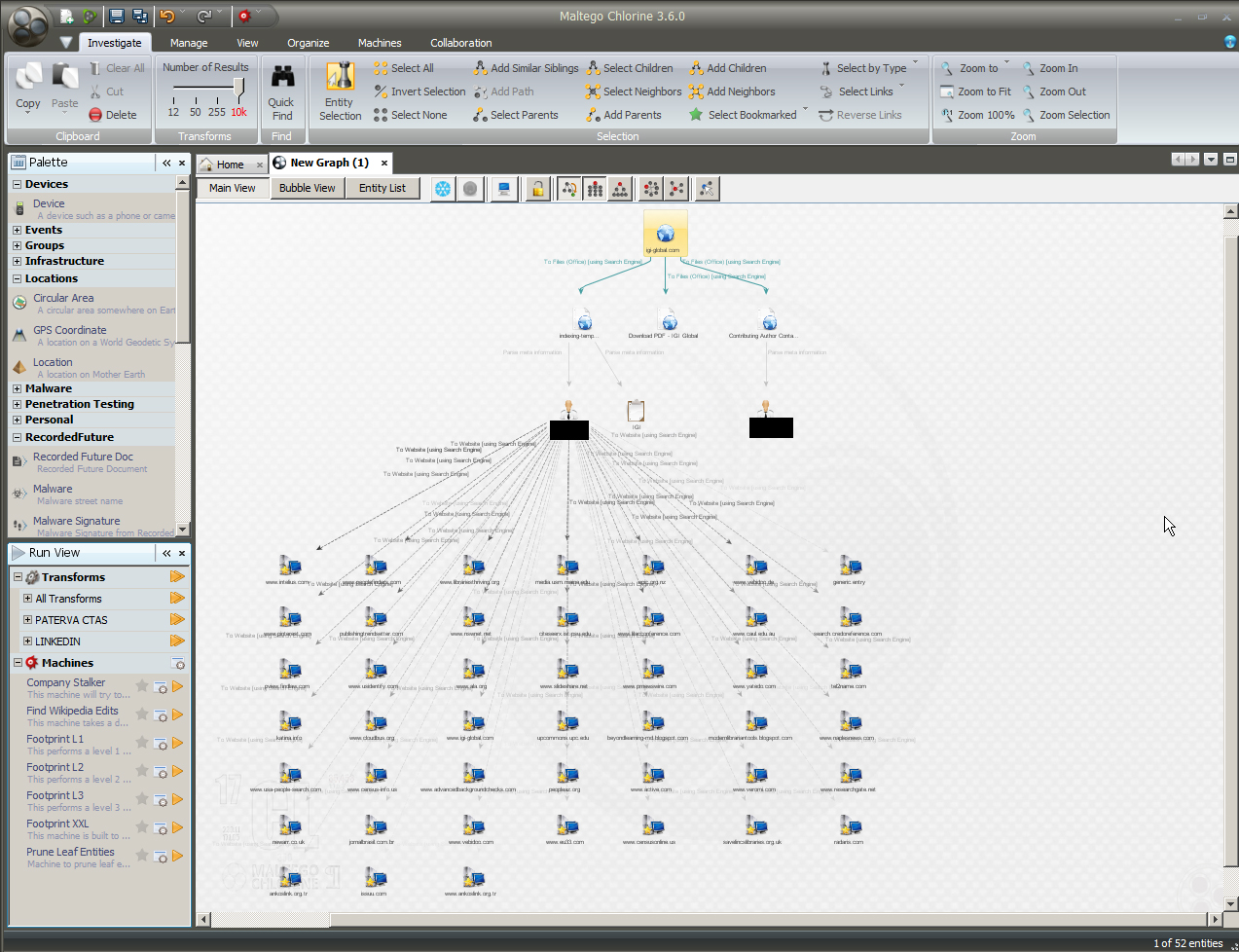
Figure 1: A Zoomed-Out L3 (Level 3) View of the www.igi-global.com Website
One approach involves conducting a footprint of a website. Footprints, depending on their level of extensiveness, captures a wide variety of web- or Internet-based data. For example, in Figure 1, there is a zoomed-out view of the www.igi-global.com footprint. The legend at the bottom right shows a wide range of captured information: Website, AS (Autonomous System), image, BuiltWith Technologies, Netblock, Email address, Domain, URL (Uniform Resource Locator), IPv4 Address, Person, DNS (Domain Name Server) Name, Website Title, and others. There are other elements that may be captured: principals (individuals) on a site and their contact information, hosted documents and images, and others.
Figure 2: A "Company Stalker" Data Extraction of www.igi-global.com
The websites which are closely partnered with the target website may also be footprinted and mapped with the idea that sites that are similar may highlight (similar and different) aspects of the other. There may be some degree of mirroring along with contrastive aspects.
Figure 2 (a redacted version) shows a screenshot of a “Company Stalker” view of the company, one iteration in. This Maltego “machine” is designed to help identify individuals who work at a particular company, to show “social engineering” vulnerabilities (as Maltego Chlorine 3.6.0 is a penetration testing tool). Many companies work to mask their staff in order to protect their workforce, enhance security, and protect intellectual property.
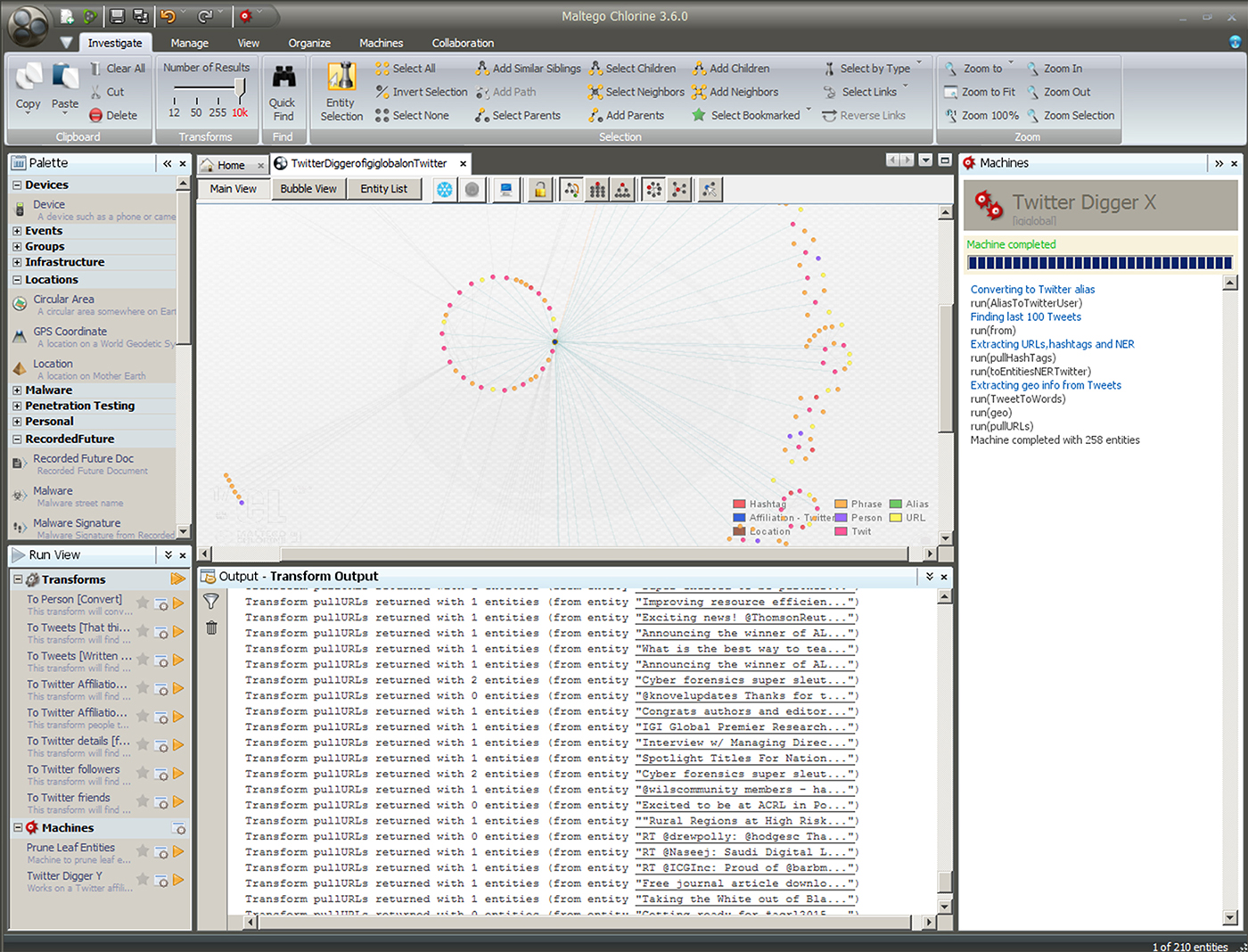
Figure 3: A "Twitter Digger" Data Extraction for @igiglobal on Twitter
In Figure 3, a “Twitter Digger” extraction pulls common linked messaging and (Twitter user account-based) social networks from a particular @igiglobal account on Twitter.
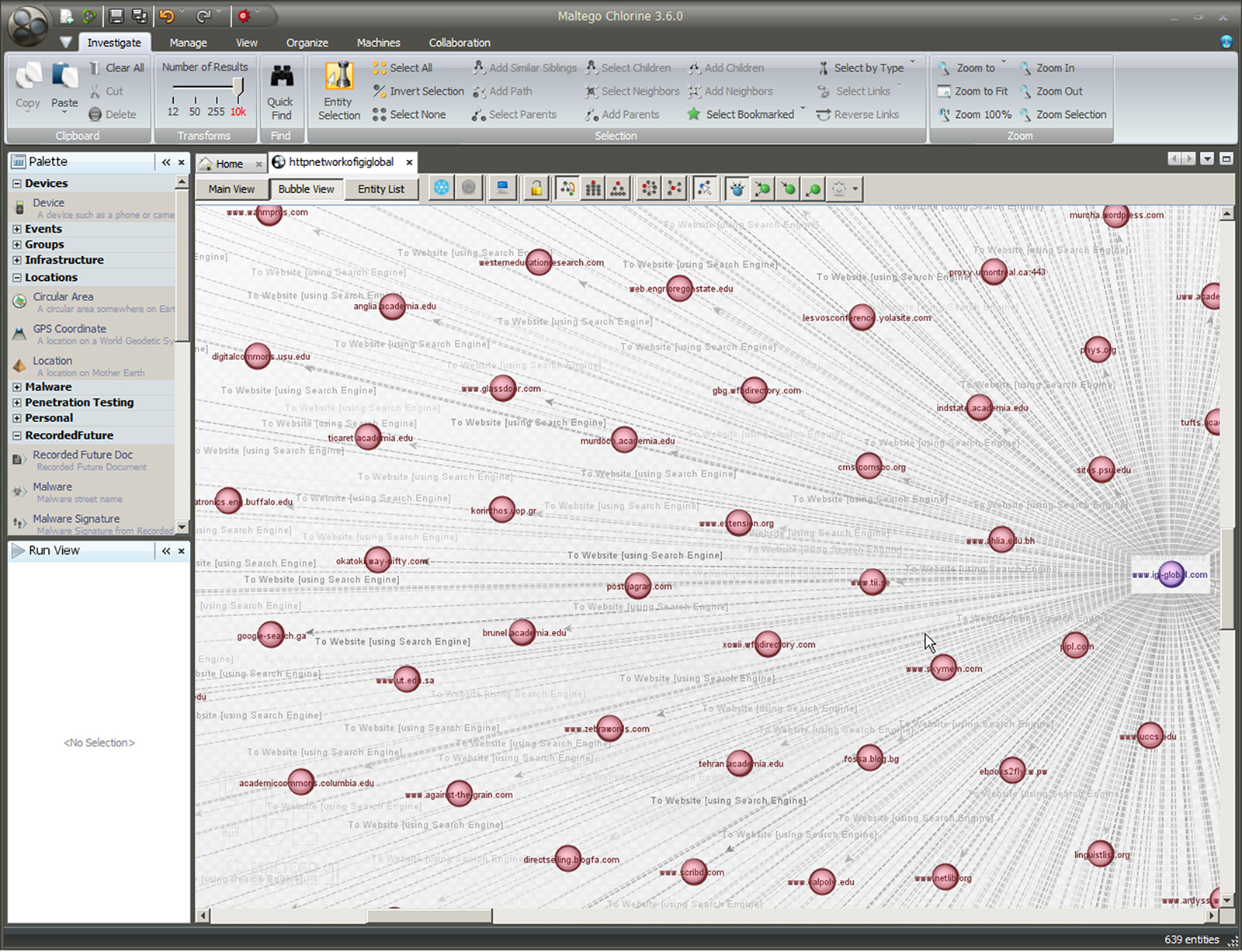
Figure 4: "http network" for www.igi-global.com on the Web
In Figure 4, this shows an “http network” (website network) for igi-global.com to show which sites are connected with http://www.igi-global.com. This network consists of 639 entities, after a one-iteration run. Many of the sites are related to institutions of higher education, libraries, and mass media organizations.
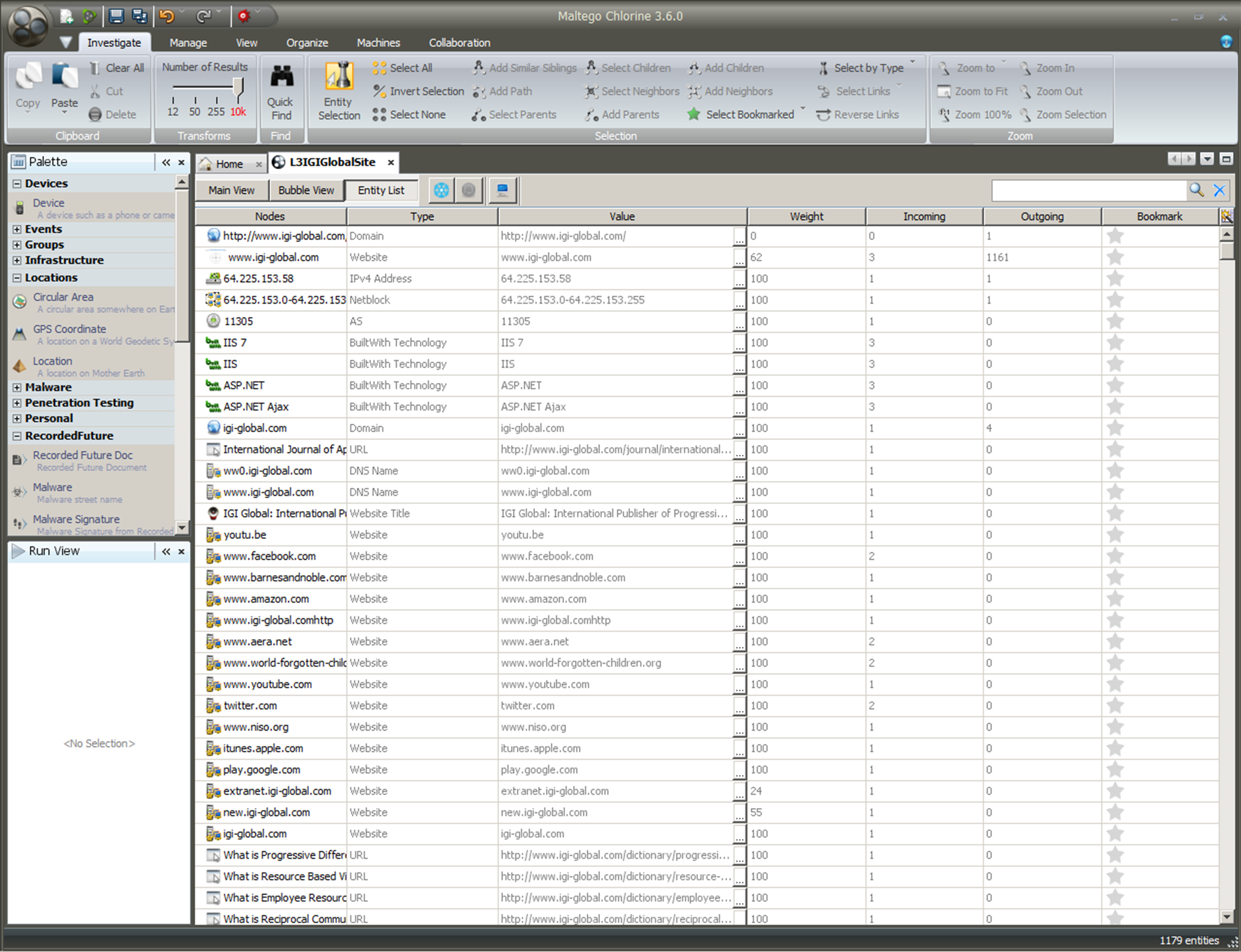
Figure 5: “Entity List” View of the L3 (Level 3) Data Extraction for the www.igi-global Website
Researchers who want to study the connections in depth may go to the “Entity List” view from the data extraction and explore further. Sub-graphs may be extracted and moved to a new graph for further exploration of specific nodes (entities) on the Surface Web, using Maltego Chlorine.
Figure 6: A Structured Graph View of a "Tweet Analyser" Extraction for “IGI-Global”
To capture a general sense of the various online microblogging conversations (microchats) going on about “IGI-Global” on Twitter, a Tweet Analyser was run using the seeding term “IGI-Global.” By zooming into the above graph, users may identify some of the types of messages being exchanged. The messaging is collected in multiple languages based on how the information was Tweeted out.
Figure 7: Sentiment Analysis of the “IGI-Global” Messaging on Twitter (from Maltego’s Tweet Analyser)
Built into the Tweet Analyser is the AlchemyAPI that enables sentiment analysis of the collected messages. A majority of the messages collected are trending “positive” and some “neutral” in this particular data extraction. A perusal of the “Entity List” gives a sense of some of the types of conversations going on which mention “IGI-Global.” There are also hashtagged conversations, referenced URLs, referenced videos, referenced phrases, Twits (Twitter identities), and dynamic changes to this network over time.
For a fuller understanding, it may help to conduct a number of data extractions here and to also seed various other searches using a number of different terms. [Maltego also enables moving from social media platforms—like Twitter—directly to the Surface Web and other linked online contents, individuals’ names, and so on. The data itself, though, may be quite “noisy” as much of online information is.]
In Part 1, the chatter around “IGI-Global” was captured from Twitter, the microblogging site. In this next part, the @igiglobal TweetStream is captured and mapped. This text corpus comes from the feed that @igiglobal actually controls.
Figure 8: The @igiglobal Landing Page on Twitter with its TweetStream
Another approach involves capturing the target Twitter account’s Tweetstream of messaging to capture a sense of the organization. In Figure 8, the landing page shows 1,579 messaging records (by Twitter’s count). On the main page, it also shows that the account is following (901 following) more social media accounts as follow it (807 followers)—which suggests less of a focus on popularity and more on affirming the accounts that may follow them. In a sense, the focus on following others also shows something of a learning organization stance. There were 95 favorites. Also, @igiglobal joined Twitter in July 2010, for an average of 300 Tweets or so a year or less than one a day.
Figure 9: Word Frequency Count Word Cloud of the Extracted @igiglobal Tweetstream
NCapture of NVivo 10 was used to capture this @igiglobal Tweetstream, and the capture resulted in 1579 messages or a near total extraction of the full set of messaging. A word cloud of the captured text in the Tweetstream gives a sense of the issues of concern @igiglobal, with a focus on research, education, technology, and business. There are not so many references to particular #hashtag campaigns or many other social media accounts @account. Only “http” was added to the stop words list (Figure 9).
Figure 10: The Level of Detail in the Tweetstream Capture using NCapture of NVivo 10
The extractions involve the capture of the unique Twitter ID number, user names, full-text of Tweets, time of Tweet, related hashtags, mentions, physical locations, URLs, Twitter account bio data, and geolocational coordinates (Figure 10).
Figure 11: A Dendrogram of the @igiglobal Tweetstream from Twitter
The TweetStream data may be visualized as a dendrogram, with related words structured on connected branches. This visualization gives a sense of how data is structured proxemically for meaning and a machine-based text summarization. In Figure 11, there are some hints of co-authors and shared interests.
Figure 12: A Three-Dimensional Cluster Diagram of the @igiglobal Tweetstream from Twitter
The same information from the @igiglobal Tweetstream may be visualized in various types of cluster diagrams (ring lattice graphs, bubble diagrams in 2D or 3D, and others). In Figure 12, this data is visualized in a 3D diagram. The color coding indicates co-clustering (such as in appearing in the same Twitter messages), and the sizes of the respective nodes indicate frequency of mentions. In this case, there do not seem to be dominant nodes as they are all about equal in size (close in numerical frequency).
Figure 13: An Interactive Word Tree of “IGI-Global” from NVivo 10
Figure 13, also created in NVivo 10, shows a word tree of the target term “igi global.” This is an interactive word tree. Whenever a phrase to the left or the right of the target term is highlighted, the correlating other half of the messaging is highlighted, so users may benefit from a fast machine-read of the contents and their gist.
Figure 14: IGI-Global Tweetstream Geolocational Map from Tweets and Linked Social Media User Accounts
Figure 14 shows an auto-created geolocational map from the captured Tweets from the @igiglobal TweetStream. This was visualized in NCapture of NVivo 10. The sparseness of usable geolocational data in Tweets (with many researchers suggesting that only 1 – 2% of microblogging messages are annotated with volunteered geolocational information) means that the geographical data should be used is a careful way. This does show a broad geographical span of interest. IGI-Global is, uh, global.
Figure 15: User Network of @igiglobal on Twitter (1 deg.)
So who exactly is in the social network of @igiglobal on Twitter. Specifically, what does a one-degree network look like in terms of those “alters” accounts with direct ties to @igiglobal? It turns out that there are 1,414 members in this direct ego neighborhood. For Figure 15, NodeXL (Network Overview, Discovery and Exploration for Excel) was used for the data extraction and graph mapping. Additional analyses may be run on this network to identify those with greater amounts of interactions with @igiglobal.
This final section highlights the ability to look at the target’s social networks on Wikipedia and YouTube. Also, there is a section on using geolocational information.
Figure 16: IGI_Global Article Network on Wikipedia (1.5 deg.)
On Wikipedia, the IGI_Global article network shows an array of close-in direct ties (sparse) but more complexity as the network is graphed out to 1.5 degrees (in terms of page article transitivity). An article network shows the proxemics of related ideas. In this case, the granularity of the analysis is based on an article on Wikipedia. The data extraction was done using a third-party data importer on NodeXL for online MediaWiki contents (MediaWiki is the understructure for Wikipedia).
Figure 17: IGI-Global’s User Network on YouTube
In terms of IGIGlobal’s formal video network on YouTube, that account currently has no members besides itself. (The channel itself may be a fairly new one.) However, a general video search based on “IGIGlobal” (as a topic) on YouTube finds quite a few videos based on works related to IGI-Global projects. Figure 17 shows the titles of the videos in this particular YouTube video network
Plotting the geographical location of an entity may provide other insights.
Figure 18: Identifying IGI-Global’s Lat-Long Coordinates (in Decimal Degrees) using Google Maps
Finally, using IGI-Global’s mailing address [701 East Chocolate Avenue, Hershey, Pennsylvania] in Google Maps and its “What’s Here?” feature, the publishing company’s exact latitude-longitude coordinates [in decimal degrees, and based on the World Geodetic System (WGS) 1984 ellipsoid] may be obtained (40.292081, -76.634476). These coordinates may then be used to capture recent geotagged Tweets from that location.
Figure 19: Recent Tweets Shared from the Proximity of IGI-Global’s Site (using Maltego Chlorine’s Circular Area “Transform”)
Recent Tweets geotagged to the locale of IGI-Global’s site (with a 1.6 meter radius circular area around the pinpointed location) were captured, and many were about coffee and other morning drinks. There were also details about jobs available. [The broad availability of geospatial data and mapping on the Web and Internet are part of a build-out of "spatial cyberinfrastructure" or "geospatial cyberinfrastructure" and the popularization of so-called "cyberGIS."]
In this hyper-social age, the “getting to know you” often happens in a mediated way and from a distance. When people check out other individuals and other entities (groups), they haunt social media sites, the Web, and the Internet, in search of particular “tells” or even “red flags.” Often, the surfaces that are touched are the public-facing ones, with the self (entity)-created public relations messaging and polished claims.
Less familiar approaches for such vetting involve data-mining approaches from these same online spaces. These data tend to be somewhat raw and less-processed, and the techniques (network analysis) for data extraction and analysis involve a somewhat steep learning curve (in terms of the software, the statistics, the data visualizations, and the data analytics).
Checking out IGI-Global Multiple Ways (Part 1 of 3)
This entry showcases how IGI-Global looks from different angles using three software tools (listed in the order of presentation): Maltego Chlorine 3.6.0, NVivo 10 (with NCapture), and NodeXL.
Footprinting the Website (on the Surface Web)
{kind=link}
One approach involves conducting a footprint of a website. Footprints, depending on their level of extensiveness, captures a wide variety of web- or Internet-based data. For example, in Figure 1, there is a zoomed-out view of the www.igi-global.com footprint. The legend at the bottom right shows a wide range of captured information: Website, AS (Autonomous System), image, BuiltWith Technologies, Netblock, Email address, Domain, URL (Uniform Resource Locator), IPv4 Address, Person, DNS (Domain Name Server) Name, Website Title, and others. There are other elements that may be captured: principals (individuals) on a site and their contact information, hosted documents and images, and others.
{kind=link}
Figure 2: A "Company Stalker" Data Extraction of www.igi-global.com
The websites which are closely partnered with the target website may also be footprinted and mapped with the idea that sites that are similar may highlight (similar and different) aspects of the other. There may be some degree of mirroring along with contrastive aspects.
Figure 2 (a redacted version) shows a screenshot of a “Company Stalker” view of the company, one iteration in. This Maltego “machine” is designed to help identify individuals who work at a particular company, to show “social engineering” vulnerabilities (as Maltego Chlorine 3.6.0 is a penetration testing tool). Many companies work to mask their staff in order to protect their workforce, enhance security, and protect intellectual property.
{kind=link}
Figure 3: A "Twitter Digger" Data Extraction for @igiglobal on Twitter
In Figure 3, a “Twitter Digger” extraction pulls common linked messaging and (Twitter user account-based) social networks from a particular @igiglobal account on Twitter.
{kind=link}
Figure 4: "http network" for www.igi-global.com on the Web
In Figure 4, this shows an “http network” (website network) for igi-global.com to show which sites are connected with http://www.igi-global.com. This network consists of 639 entities, after a one-iteration run. Many of the sites are related to institutions of higher education, libraries, and mass media organizations.
{kind=link}
Figure 5: “Entity List” View of the L3 (Level 3) Data Extraction for the www.igi-global Website
Researchers who want to study the connections in depth may go to the “Entity List” view from the data extraction and explore further. Sub-graphs may be extracted and moved to a new graph for further exploration of specific nodes (entities) on the Surface Web, using Maltego Chlorine.
{kind=link}
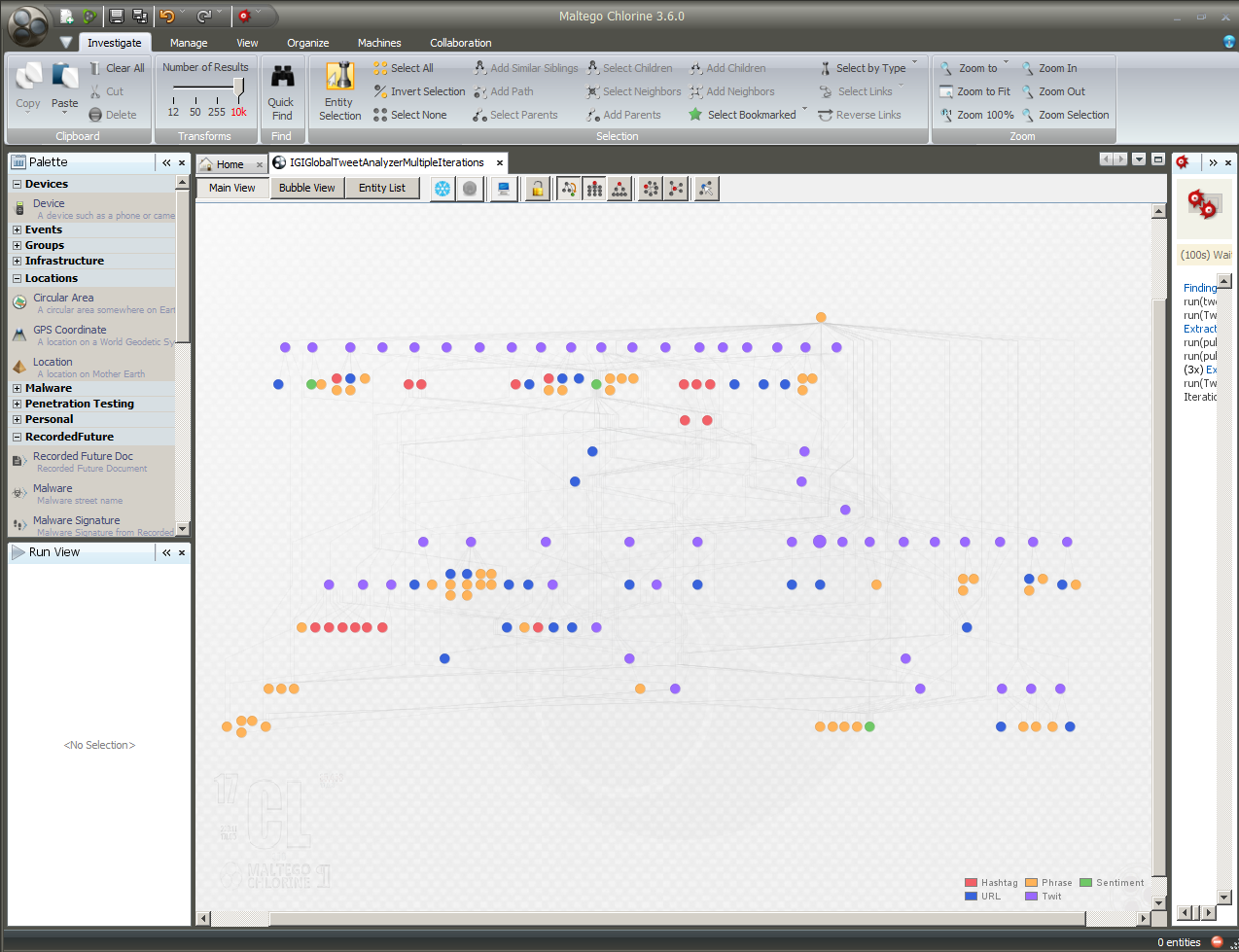
Figure 6: A Structured Graph View of a "Tweet Analyser" Extraction for “IGI-Global”
To capture a general sense of the various online microblogging conversations (microchats) going on about “IGI-Global” on Twitter, a Tweet Analyser was run using the seeding term “IGI-Global.” By zooming into the above graph, users may identify some of the types of messages being exchanged. The messaging is collected in multiple languages based on how the information was Tweeted out.
{kind=link}
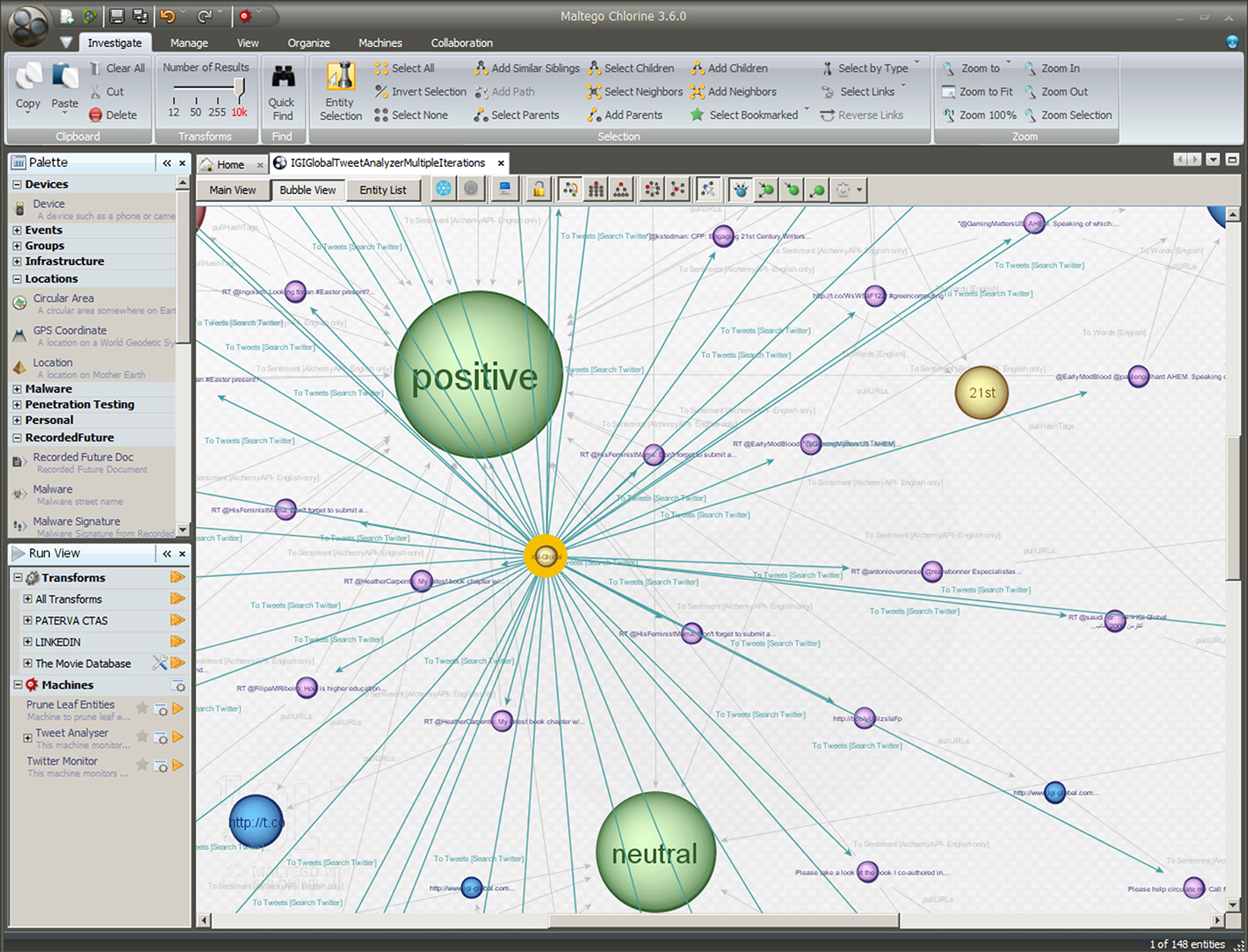
Figure 7: Sentiment Analysis of the “IGI-Global” Messaging on Twitter (from Maltego’s Tweet Analyser)
Built into the Tweet Analyser is the AlchemyAPI that enables sentiment analysis of the collected messages. A majority of the messages collected are trending “positive” and some “neutral” in this particular data extraction. A perusal of the “Entity List” gives a sense of some of the types of conversations going on which mention “IGI-Global.” There are also hashtagged conversations, referenced URLs, referenced videos, referenced phrases, Twits (Twitter identities), and dynamic changes to this network over time.
For a fuller understanding, it may help to conduct a number of data extractions here and to also seed various other searches using a number of different terms. [Maltego also enables moving from social media platforms—like Twitter—directly to the Surface Web and other linked online contents, individuals’ names, and so on. The data itself, though, may be quite “noisy” as much of online information is.]
Checking Out IGI-Global Multiple Ways (Part 2 of 3)
In Part 1, the chatter around “IGI-Global” was captured from Twitter, the microblogging site. In this next part, the @igiglobal TweetStream is captured and mapped. This text corpus comes from the feed that @igiglobal actually controls.
Microblogging Chatter
{kind=link}
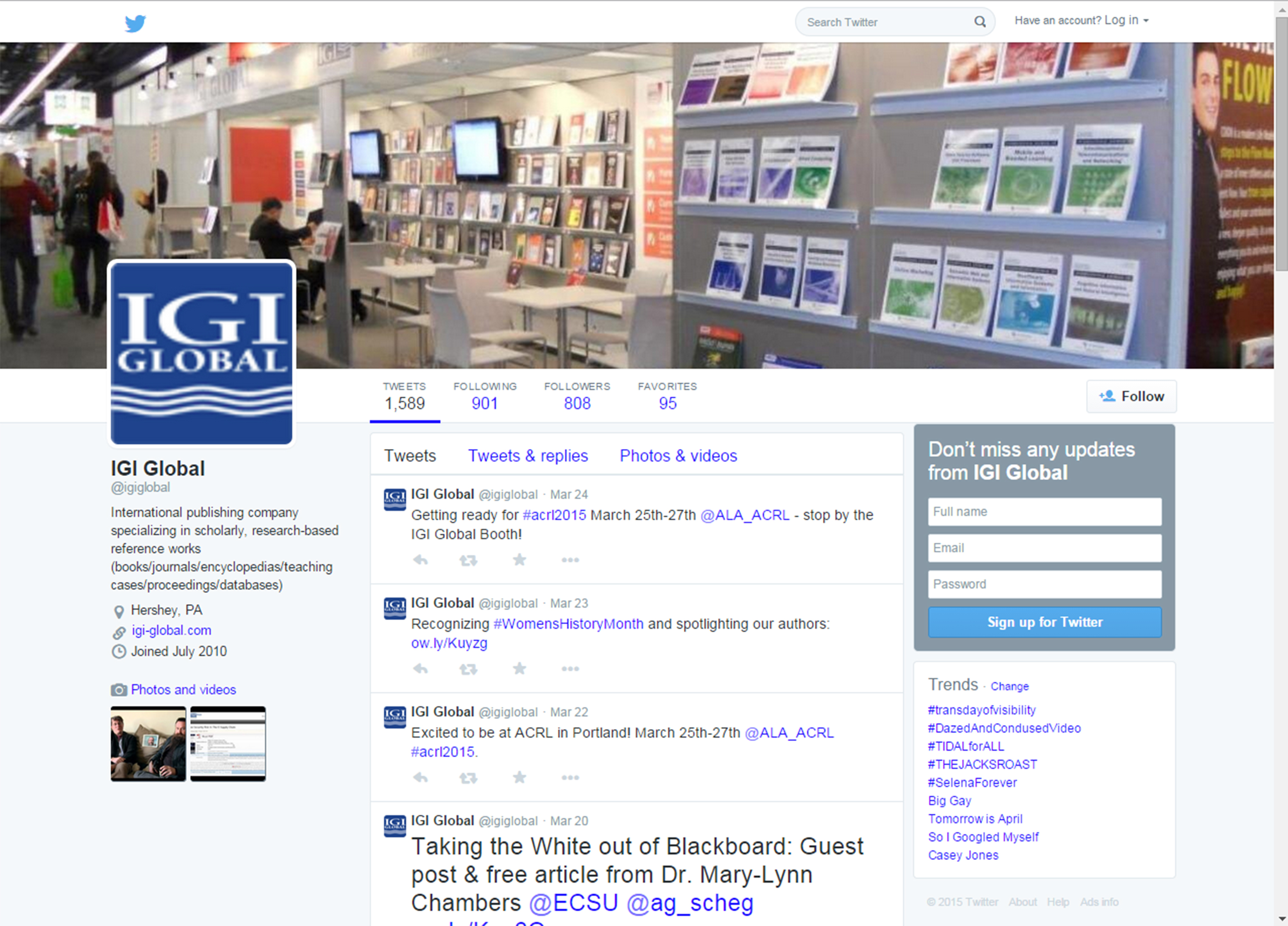
Figure 8: The @igiglobal Landing Page on Twitter with its TweetStream
Another approach involves capturing the target Twitter account’s Tweetstream of messaging to capture a sense of the organization. In Figure 8, the landing page shows 1,579 messaging records (by Twitter’s count). On the main page, it also shows that the account is following (901 following) more social media accounts as follow it (807 followers)—which suggests less of a focus on popularity and more on affirming the accounts that may follow them. In a sense, the focus on following others also shows something of a learning organization stance. There were 95 favorites. Also, @igiglobal joined Twitter in July 2010, for an average of 300 Tweets or so a year or less than one a day.
{kind=link}
Figure 9: Word Frequency Count Word Cloud of the Extracted @igiglobal Tweetstream
NCapture of NVivo 10 was used to capture this @igiglobal Tweetstream, and the capture resulted in 1579 messages or a near total extraction of the full set of messaging. A word cloud of the captured text in the Tweetstream gives a sense of the issues of concern @igiglobal, with a focus on research, education, technology, and business. There are not so many references to particular #hashtag campaigns or many other social media accounts @account. Only “http” was added to the stop words list (Figure 9).
{kind=link}
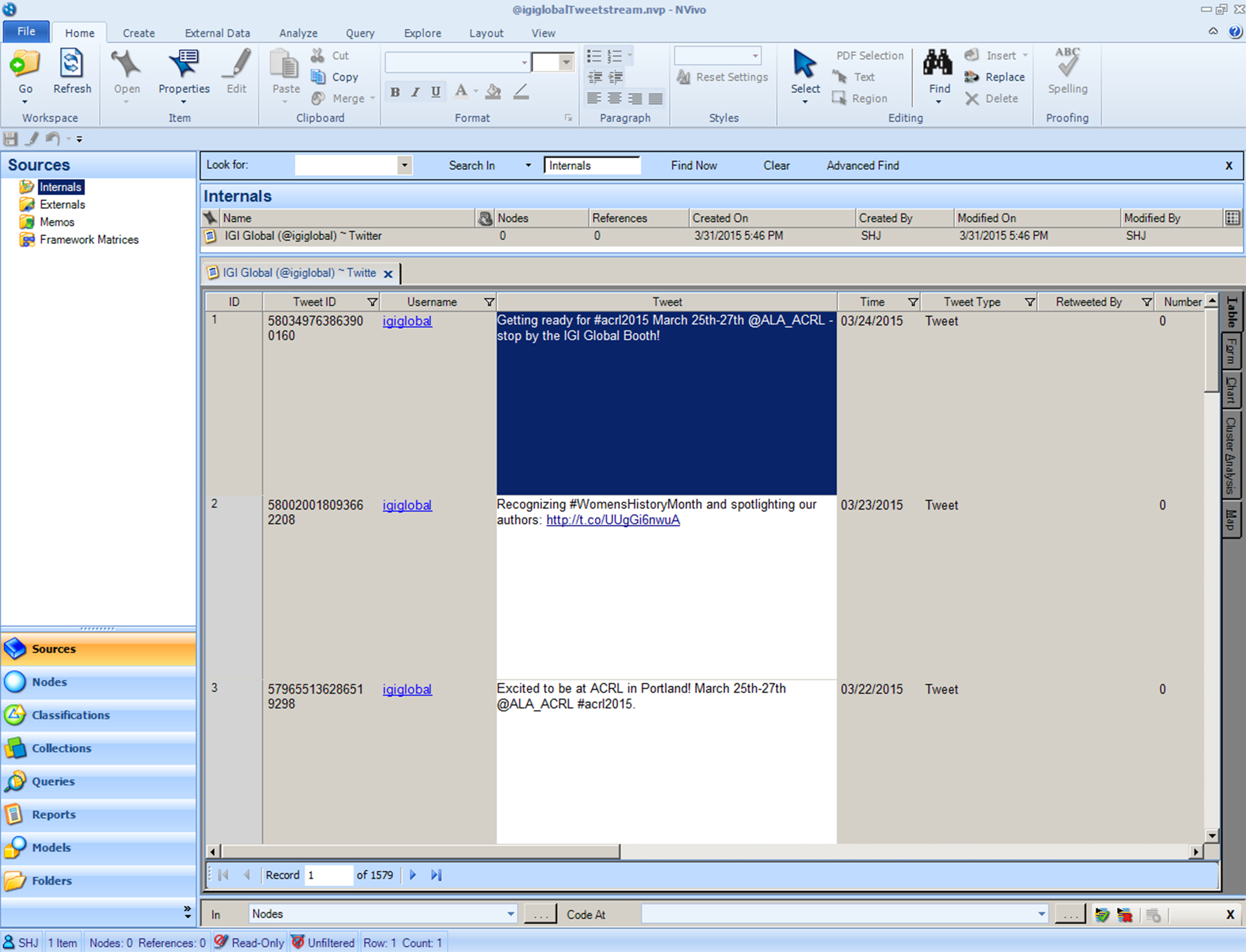
Figure 10: The Level of Detail in the Tweetstream Capture using NCapture of NVivo 10
The extractions involve the capture of the unique Twitter ID number, user names, full-text of Tweets, time of Tweet, related hashtags, mentions, physical locations, URLs, Twitter account bio data, and geolocational coordinates (Figure 10).
{kind=link}
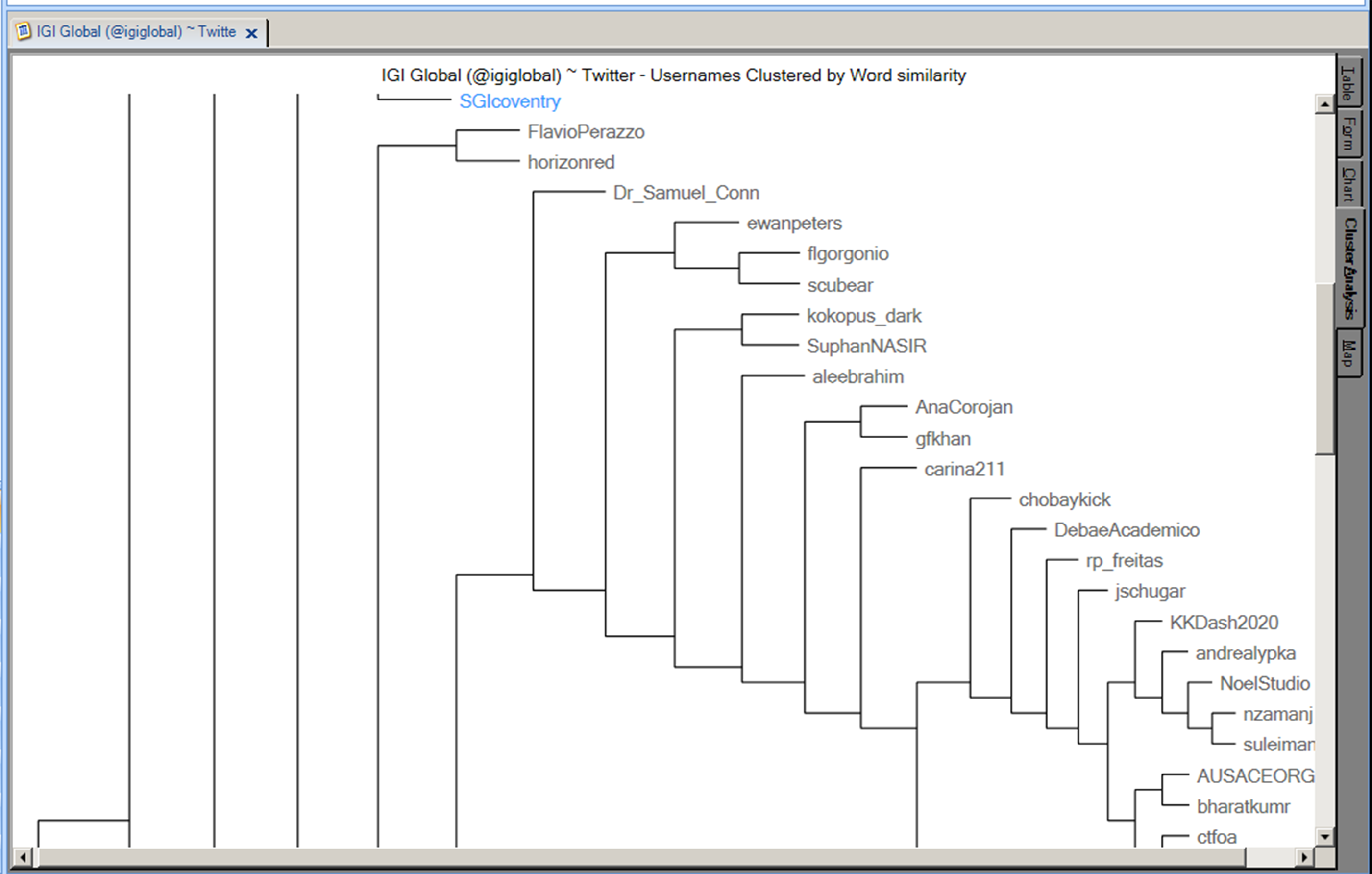
Figure 11: A Dendrogram of the @igiglobal Tweetstream from Twitter
The TweetStream data may be visualized as a dendrogram, with related words structured on connected branches. This visualization gives a sense of how data is structured proxemically for meaning and a machine-based text summarization. In Figure 11, there are some hints of co-authors and shared interests.
{kind=link}
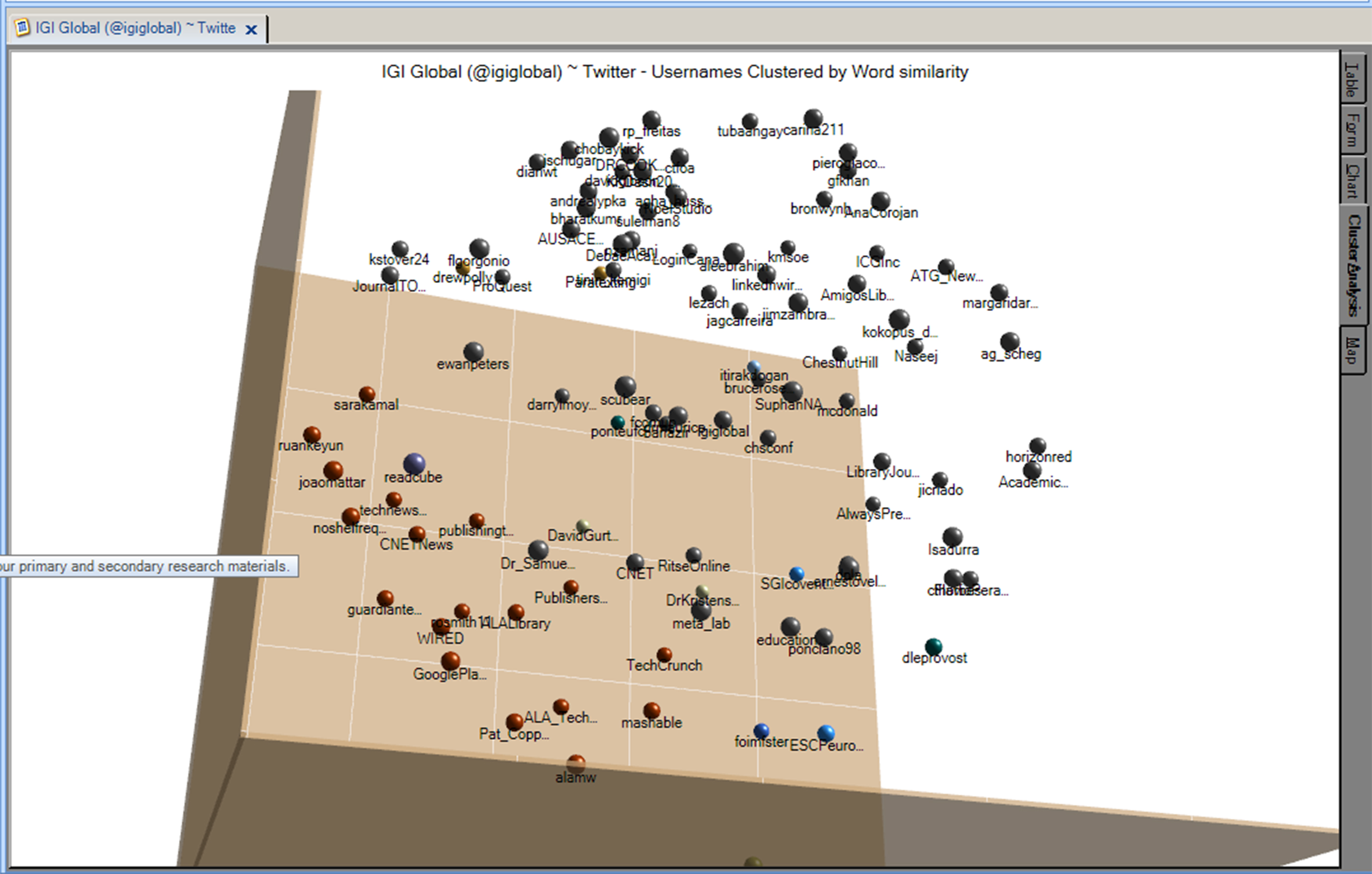
Figure 12: A Three-Dimensional Cluster Diagram of the @igiglobal Tweetstream from Twitter
The same information from the @igiglobal Tweetstream may be visualized in various types of cluster diagrams (ring lattice graphs, bubble diagrams in 2D or 3D, and others). In Figure 12, this data is visualized in a 3D diagram. The color coding indicates co-clustering (such as in appearing in the same Twitter messages), and the sizes of the respective nodes indicate frequency of mentions. In this case, there do not seem to be dominant nodes as they are all about equal in size (close in numerical frequency).
{kind=link}
Figure 13: An Interactive Word Tree of “IGI-Global” from NVivo 10
Figure 13, also created in NVivo 10, shows a word tree of the target term “igi global.” This is an interactive word tree. Whenever a phrase to the left or the right of the target term is highlighted, the correlating other half of the messaging is highlighted, so users may benefit from a fast machine-read of the contents and their gist.
{kind=link}
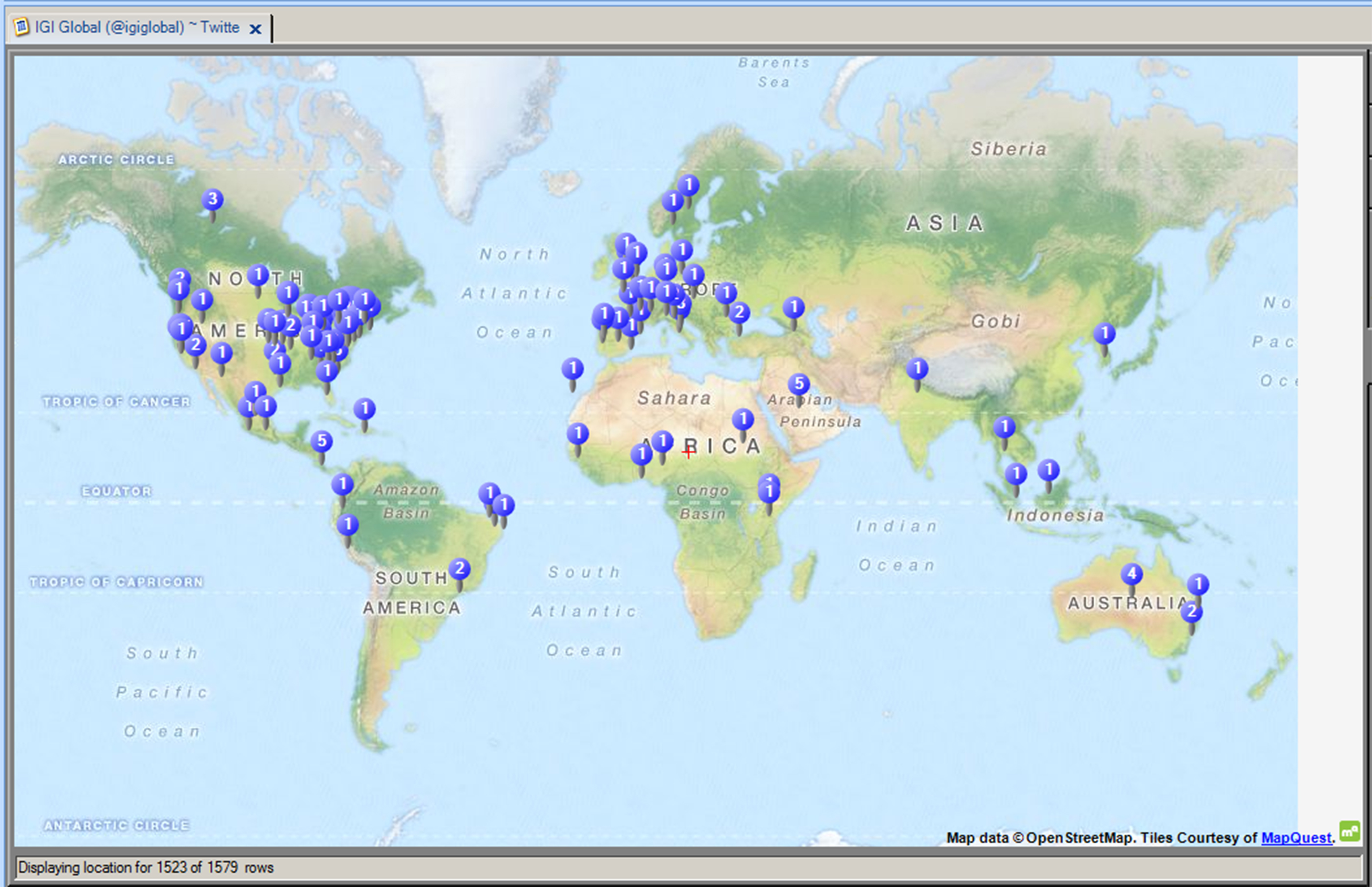
Figure 14: IGI-Global Tweetstream Geolocational Map from Tweets and Linked Social Media User Accounts
Figure 14 shows an auto-created geolocational map from the captured Tweets from the @igiglobal TweetStream. This was visualized in NCapture of NVivo 10. The sparseness of usable geolocational data in Tweets (with many researchers suggesting that only 1 – 2% of microblogging messages are annotated with volunteered geolocational information) means that the geographical data should be used is a careful way. This does show a broad geographical span of interest. IGI-Global is, uh, global.
{kind=link}
Figure 15: User Network of @igiglobal on Twitter (1 deg.)
So who exactly is in the social network of @igiglobal on Twitter. Specifically, what does a one-degree network look like in terms of those “alters” accounts with direct ties to @igiglobal? It turns out that there are 1,414 members in this direct ego neighborhood. For Figure 15, NodeXL (Network Overview, Discovery and Exploration for Excel) was used for the data extraction and graph mapping. Additional analyses may be run on this network to identify those with greater amounts of interactions with @igiglobal.
Checking Out IGI-Global Multiple Ways (Part 3 of 3)
This final section highlights the ability to look at the target’s social networks on Wikipedia and YouTube. Also, there is a section on using geolocational information.
Tapping an Open and Crowd-Sourced Encyclopedia
{kind=link}
Figure 16: IGI_Global Article Network on Wikipedia (1.5 deg.)
On Wikipedia, the IGI_Global article network shows an array of close-in direct ties (sparse) but more complexity as the network is graphed out to 1.5 degrees (in terms of page article transitivity). An article network shows the proxemics of related ideas. In this case, the granularity of the analysis is based on an article on Wikipedia. The data extraction was done using a third-party data importer on NodeXL for online MediaWiki contents (MediaWiki is the understructure for Wikipedia).
A Video Network on YouTube
{kind=link}
Figure 17: IGI-Global’s User Network on YouTube
In terms of IGIGlobal’s formal video network on YouTube, that account currently has no members besides itself. (The channel itself may be a fairly new one.) However, a general video search based on “IGIGlobal” (as a topic) on YouTube finds quite a few videos based on works related to IGI-Global projects. Figure 17 shows the titles of the videos in this particular YouTube video network
Geolocational Information
{kind=link}
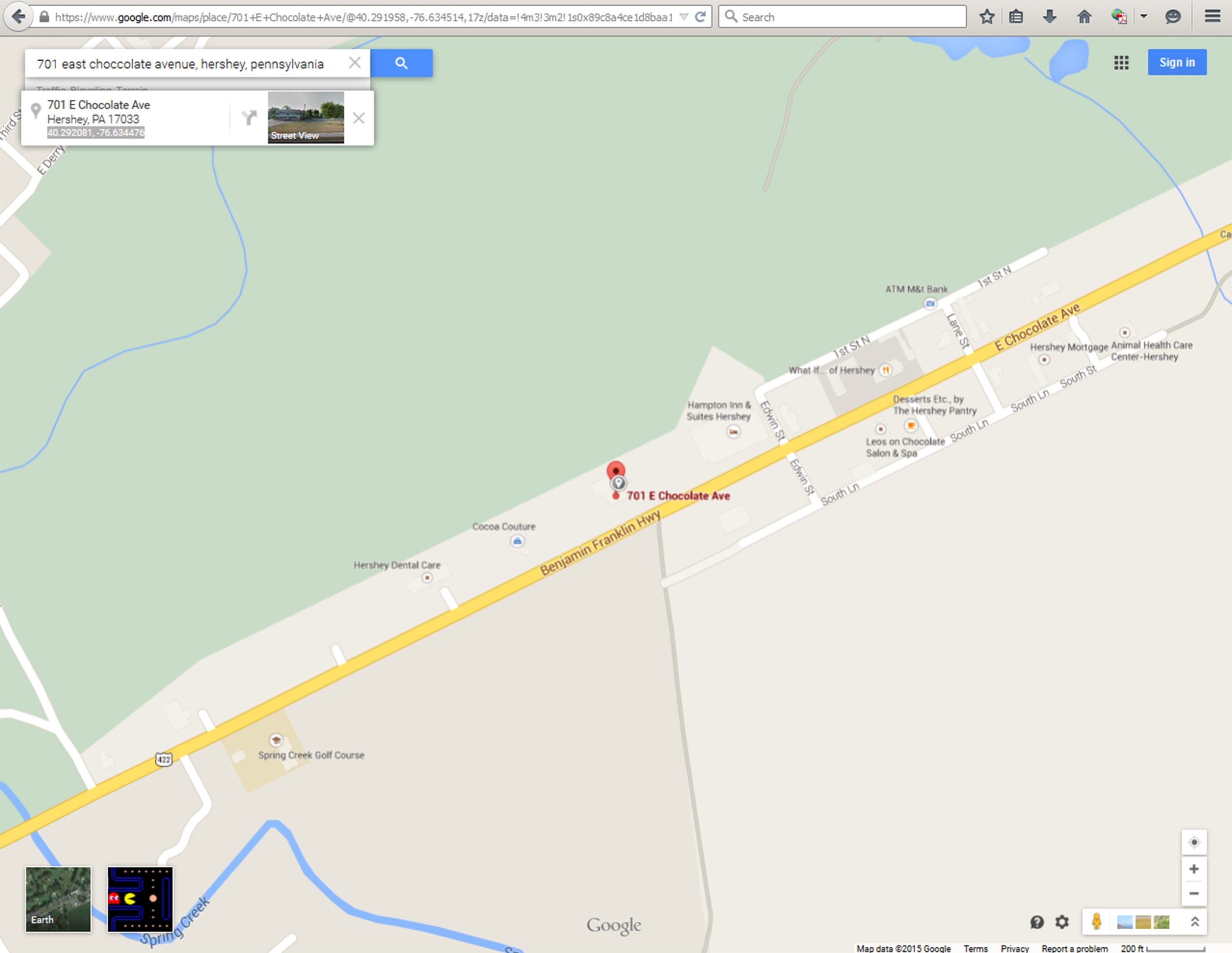
Figure 18: Identifying IGI-Global’s Lat-Long Coordinates (in Decimal Degrees) using Google Maps
Finally, using IGI-Global’s mailing address [701 East Chocolate Avenue, Hershey, Pennsylvania] in Google Maps and its “What’s Here?” feature, the publishing company’s exact latitude-longitude coordinates [in decimal degrees, and based on the World Geodetic System (WGS) 1984 ellipsoid] may be obtained (40.292081, -76.634476). These coordinates may then be used to capture recent geotagged Tweets from that location.
{kind=link}
Figure 19: Recent Tweets Shared from the Proximity of IGI-Global’s Site (using Maltego Chlorine’s Circular Area “Transform”)
Recent Tweets geotagged to the locale of IGI-Global’s site (with a 1.6 meter radius circular area around the pinpointed location) were captured, and many were about coffee and other morning drinks. There were also details about jobs available. [The broad availability of geospatial data and mapping on the Web and Internet are part of a build-out of "spatial cyberinfrastructure" or "geospatial cyberinfrastructure" and the popularization of so-called "cyberGIS."]
These entries focused on tapping social media, the Surface Web, and the Internet for information to profile a particular online entity using more raw information. The focus here has been on data visualizations and less on the actual underlying data and graph metrics.
There are many other approaches that were not mentioned here. If there is a trending conversation about the organization, there are ways to identify those who are most active in the discussion and what they’re saying. There are ways to map aliases to personally identified individuals and their contact information. There are ways to scrape images (as thumbnails) from image-based accounts. There are ways to analyze text corpora using software programs that may illuminate emergent network structures. There are many as-yet unexploited methods to learn and to know the social world more deeply with extant tools and methods.
Shalin Hai-Jew works as an instructional designer at Kansas State University. She has worked with IGI-Global on several publishing projects. This work was created as an initial proof-of-concept for the manual mapping of an entity across multiple social media platforms using multiple software tools. This method is described in a draft chapter which has been provisionally accepted in a forthcoming text. Her email is shalin@k-state.edu.
There are many other approaches that were not mentioned here. If there is a trending conversation about the organization, there are ways to identify those who are most active in the discussion and what they’re saying. There are ways to map aliases to personally identified individuals and their contact information. There are ways to scrape images (as thumbnails) from image-based accounts. There are ways to analyze text corpora using software programs that may illuminate emergent network structures. There are many as-yet unexploited methods to learn and to know the social world more deeply with extant tools and methods.
About the Author
Shalin Hai-Jew works as an instructional designer at Kansas State University. She has worked with IGI-Global on several publishing projects. This work was created as an initial proof-of-concept for the manual mapping of an entity across multiple social media platforms using multiple software tools. This method is described in a draft chapter which has been provisionally accepted in a forthcoming text. Her email is shalin@k-state.edu.
| Previous page on path | Cover, page 16 of 28 | Next page on path |
Discussion of "Profiling an Entity across Multiple Social Media Platforms"
Add your voice to this discussion.
Checking your signed in status ...