A Light Stroll through Computational Stylometry and its Early Potential
By Shalin Hai-Jew, Kansas State University
When people read for pleasure, and they are self-aware about the activity, they realize that their favorite authors offer a combination of stylistic features that create that engagement. For some fictional works, the appeal may come from a variety of factors: the main character, the supporting characters and their interrelationships, the plot twists, the dialogue, the action, and the humor; it may be the genre; it may be the particular time period; it may be the mysteries and riddles.
Figure 1: Tablet Computer (an open-source image)
For some nonfictional works, the allure may come from the author’s access to information, his / her worldview or mental model of the world, and maybe the way he, she, or they express themselves. Author "voice" is a critical factor in both fiction and non-fiction.
Oftentimes, it’s not even just the writing. People consume ideas sometimes through the framework of human personality. Look at book jackets of most popular books, and there are stylized images of authors; there are author back stories that lend credibility to the writing when they actually embody what they write. In an analytical sense, the psychological elements include personality, intelligence (cognitive and affective), mental health, and other factors; these are extracted using stylometric profiling. Sociological factors include culture, gender, age, class, education level, region of language learning, and other factors.
To understand the importance of the author personality frame, note that virtually any author of note has a landing page with the book publisher where personal and professional details are shared; many have Wikipedia pages (albeit many are shut down when they are seen as too self-promoting). Professional authors are very much under public scrutiny, and their life details, their comments and Tweets, their families’ and friends’ comments, are all public fodder. It is no surprise that public authors—particularly those few who sell enormous numbers of texts and foreign rights and movie rights (vs. those on the “long tail”) often pay big money to assiduously protect their public reputations; how authors are perceived affects their readership and their book sales. People are highly responsive to whether they “like” or “dislike” a public personality.
This is partially why co-authorship and ghost writing are tricky things. When a well-known author co-writes with another, the style is invariably different, and those who have habituated to a certain style of writing may feel “betrayed” or “let down.” Ghost writing involves a hidden writer taking on a writing project left unfinished by a late author or continuing a popular writing series under the name of a late author. In such cases, publishing companies often do not share the information of the ghost authorship very publicly; the author himself / herself or the authoring team rarely ever comes to light even as they receive the royalty checks for their work.
Another way to surface reader assumptions is to read works from other time periods, socio-cultural contexts, works written in non-English native languages (or even translations from other languages). Such reading surfaces the role of “meta-knowledge,” assumptions about the world and the subject matter that may not be readily apparent for readers who are immersed in a particular culture (Daelemans, 2013, p. 451). Various literary genres evolve differently over time in different locales and from different histories; genre types affect the organization, the terminology, the writing styles, the assumed purposes for the readership, and what is valued. For years, researchers working to solve attribution problems have been advised to work “within the same genre” when working with lists of candidate authors for a particular work: “Genre effects generally will supersede authorial features in the discrimination process” (Holmes, 1998, p. 111). More recent works suggest that the genres that documents belong to should be considered when selecting features for building the stylometric models (Sapkota, Solorio, Montes-y-Gómez, & Rosso, 2013, p. 473).
The uses of authorial discriminators to distinguish authorship is not a new phenomenon. This basic concept is built on the idea that people tend towards consistency and habit; given that, their behaviors and work may be patterned. In 1851, English logician and mathematician Augustus de Morgan first described and applied this method to the Pauline letters (13 epistles or books in the New Testament). Thomas Corwin Mendenhall, a physicist, conducted follow-on work in stylometry in 1887. Early analyses included frequency distributions (histograms, in this case) of various word lengths as a differentiator, without considering other underlying textual cues (such as genre). Canonical applications of stylometry include studies of the Shakespearean canon and the Federalist papers.
Stylometry, the “metrics” of “style,” refers to quantitative and statistical analysis of literary or writing style. Authorship identification is an issue that has existed since the first document was written. Some researchers conflate stylometry with “authorship recognition,” “authorship identification,” and “authorship attribution,” but these latter are one type of application of practical stylometry. (Authorship attribution involves more than attributing the author’s identity; this work may also involve inference of other characteristics of the author: personality, intelligence, knowledge level, education, lifestyle, sentiments and beliefs, and other features.) Computational stylometry (also known as “computational stylistics”) has very much broadened the work of stylometry. It is thought that some combination of various objectively countable features of a text may be used to identify authorship in a scalable way.
The human stylome hypothesis. In the present computer age, researchers have put forward the “human stylome hypothesis” (van Halteren, Baayen, Tweedie, Haverkort, & Nejit, 2005); this proposal suggests that authors are uniquely distinguishable from others by measuring (counting) particular features of their writings. For this concept to apply, some researchers suggest that it only has to work on a case-by-case basis, with controls for contextual and other information; in such cases, the differentiation only has to occur between an identified author (or author set with groups of authors) with a known stylometric signatures (which some call “writeprints”) and an unknown or contested text or text corpora (body of texts). This is understood as a “closed-world problem” because some of its variables are known. In this context, the situation already helps limit some of the potential noise in the data. Also, such a defined context sometimes enables the (in)validation of the results with other ways of knowing authorship, such as historical, documentary, and other means.
Others suggest that there have to be identifiable and invariant (not changing over time or contexts) and non-manipulable stylometric signatures for authors over time, and that apply across socio-cultural, historical, and other contexts. At this end of the requirements continuum, an author’s signature has to be a correct and unique identifier—even as his or her writing style changes over time (conceptualized by some as a somewhat predictable rectilinear trajectory) and sophistication. (For individual authors, a higher time gap between “old” and “new” writing by authors has been found to correlate with more obvious and distinct categorizing.) There is also the challenge of how people change their writing styles across different social contexts and genres. At this very high threshold, theoretically and practically, such signatures should apply across languages, too.
At a very basic level, computers are highly efficient at counting, computations, and (latent or hidden) pattern finding. Computational stylometry enables the measure of anything countable in texts, but most often, these include lexical features (terminology/vocabulary of particular domains or individuals), syntactic features (structural aspects of language, such as n-grams, parts of speech, punctuation, and non-context-sensitive function words), and semantic (meaning-based aspects of language) ones.
The preferred types of features are those which are difficult to consciously manipulate, so that it is impervious to human deception. An individual’s stylometric “print” (a writing equivalent of a “fingerprint” and “handwriting”) is conceptualized as comprising latent data which emerges from unconscious and habituated behaviors. Unique and unusual patterns, like obvious turns of phrases, may be used for matching, but these can be fairly easily emulated.
Insights may be gained about larger groups of authors as well. The gender of an author may be identified based on emotional expressivity in the writing. For example, female writing tends to be “more contextual, personal and emotional than male writing, in which the style is typically more impersonal, formal and judgmental” (Montero, Munezero, & Kakkonen, 2014, p. 98). Various documents may be classified to certain types based on extracted features (including “punctuation analysis, sentence length distribution, syntactic analysis, n-gram syntactic analysis, analysis of morphological categories, analysis of morphological tags, frequency of word classes, frequency of word-class bigrams, frequency of stop words, word repetition analysis, Simpson’s vocabulary richness, analysis of typographical errors, and frequency of emoticons” (Rygl, 2014, pp. 55 – 56).
The ability to uniquely describe writing in quantitative terms enables researchers to describe, compare, sort, attribute, and explore texts. These texts may be studied stylometrically in various units of analysis: individual documents, individual messages; author corpuses, select time periods of author production; genres, thematic analysis (across genres); culture-based outputs, and others.
In the research literature, the quantifiable aspects of writing style are set up as individual small-scale cases (with works by known authors vs. unattributed works, or training sets vs. test sets). These analyses are considered “supervised” classifiers because the machine learning algorithms are informed by training sets that model what to “look for.”
There are unsupervised stylometry methods as well, with classifiers applied to data sets to extract clusters of differing patterns based on its own ad hoc self-learning, without human direction. One application of this is to run the algorithms against sets of documents of unknown authorship and to extract author groups based on various types of similarity analyses (based on whatever features exist in the text set). Practically, this should identify the respective authors in the set based on the respective styles observed in the respective documents within that set. [Apparently, the greater the inherent differences between domains in a corpus (“domain broadness”)—such as “chemistry” and “entertainment”—the more effective the cluster analysis for stylometric differentiation. The larger the number of terms, for a more populated similarity matrix, the more informative a cluster analysis. Text corpuses would do well to have sufficient balance of sample types, so that the sample is not all of a few types and a few rare others; cluster analysis may have a difficult type identifier those on the “long tail.”
At the single text level, there are supervised and unsupervised methods for extracting relevant features. A supervised method involves using particular counts of elements theoretically salient to the work of stylometry. In terms of an emergent method of stylometric data extraction, there are a number of statistical methods. For example, the principal components of a text may be extracted, and any multicollinearity between the components may be eliminated using orthogonal rotation (Sapkota, Solorio, Montes-y-Gómez, & Rosso, 2013, p. 464).
Currently, it seems that there is a particular “sweet spot” in terms of numbers of texts and contextual conditions under which stylometry may be effective, with estimates of accurate authorship identification in the 70 – 80% accuracy range. In some contexts, such as closed scenarios with supervised training sets and 2-5 authors from a 15-subject pool, there can be up to 99% accuracy in author identification, or virtual certitude.
Stylometry and auto-generated text. The machine generation of text is already fairly widespread. There are some pretty coherent chatbots on social media platforms like Twitter and email systems that are able to fool people. Such chatbots have been designed with faux circadian rhythms, personalities, and improvisational capabilities (such as going to the Web to find topics to write about and sharing images found online). There are auto-text generators to create faux research papers (SCIgen) that have apparently fooled various gatekeepers of digital repositories. Stylometry has been used to identify auto-generated text. Some researchers have proposed using stylometry to create distractors for automated multiple-choice question generation in order to ensure that the distractors are sufficiently close to the real answer to make multiple-choice exams more difficult (through semantic similarity).
Research on the number of words required to map a full author identity has converged on 6,500 words (Rao & Rohatgi, 2000). Other researchers suggest a minimum set of 5,000 – 10,000 words approximately. As others have pointed out, in a workplace, people have easily left samples of their own writing in the minimum range for stylometric analysis.
Over time, this text amount requirement has dropped precipitously. Stylometry has been effectively applied to short texts: microblogging Tweets (all 140-characters each), short message service (SMS) communications, instant messaging (IM), comments on a website, and other types of social media postings.
A branch of stylometry involves adversarial stylometry—with those who would identify all writers on one side and those who work to protect anonymity and pseudonymity on the other. Some research work suggests that current stylometric systems are fairly fragile and vulnerable to naïve human “adversaries,” who are just told to mask their own writing style by either obfuscating (hiding, muddying, or confusing) their personal writing style or imitating someone else. Another strategy involves writing less, so offering fewer samples from which stylometric features may be extracted. Such purposeful writing in a non-typical style is fairly effective at throwing some author identification systems off. (Usually, when there are ways to identify weaknesses in stylometric systems, their designers will work hard to create work-arounds against those weaknesses).
An engaging video of some of this type of work was offered in the @CCCen video stream on YouTube on Jan. 4, 2012. This video, titled Privacy & Stylometry (26C3), features the full talk by Michael Brennan and features his work conducted under the guidance of Rachel Greenstadt, both of Drexel University. The talk is titled “Privacy & Stylometry: Practical Attacks against Authorship Recognition Techniques.”
These researchers, and likely others, are working on automated systems to anonymize writing styles in order to protect privacy.
There are a number of text corpuses used in stylometry. Some of these were created as a part of funded research, with individuals who created texts based on directions from the researcher, for study. Some are named corpuses based on historical documents (that are in the public domain and no longer under copyright protections). Other documents are publicly available data sets extracted from social media platforms through their application programming interfaces (APIs).
The data downloaded from social media platforms are different than those of traditional documents. The grammars and lingo are different. It is harder to define authorship. (For Twitter, is a Tweetstream for an account the contributions of one author, a robot, a cyborg, multiple individuals, various combinations of the prior)? One research team defined the lexical features they used to explore microblogging corpora: the “total number of words per tweet, total number of sentences, total number of words per sentences, frequency of dictionary words, frequency of word extensions, lexical diversity, mimicry by length, (and) mimicry by word,” (Bhargava, Mehndiratta, & Asawa, 2013, p. 41). They also looked at more original features, like the extension of words by repeating letters, such as “hiiiii!!!” In terms of syntactical features, they explored the following: the “total number of beginning of sentences (BOS) characters capitalized, number of punctuation per sentence, frequency of words with all capital letters normalized over number of words, frequency of alphanumeric words normalized over number of words, number of special characters, digits, exclamation and question marks, number of upper case letters, (and) binary feature indicating use of quotations” (Bhargava, Mehndiratta, & Asawa, 2013, p. 41). They also explored indicators of whether a Tweet was a re-tweet. They also measured the numbers of hashtags, user mentions, and URLs—each normalized over the numbers of words (Bhargava, Mehndiratta, & Asawa, 2013, p. 41). They also explored the number of occurrences of emojis. For all the “big data” aspects of microblogging messages, the numbers of authors were fairly limited:
The work of stylometry applied to user-generated social media data is still in its infancy and is highly promising. Some questions that may be asked include the following:
This article is a general summary one written at an abstract level. This writing project was pursued because the topic applies to much of the research work applied to social media (an area of interest for the author). Also, a recent challenge posited by a presenter of a webinar that the author attended involved the lack of “computational thinking,” and this issue of computational stylometry seemed to offer an opportunity to explore what this thinking may mean in this context. Also, a number of software tools enable some types of stylometric analysis, which may extend the research work.
Stylometry has been applied to a wide range of empirical and evidence-based research. In political science, the speeches and writings of leaders have been analyzed using stylometry. In history, various documents have been analyzed using style metrics. Stylometry has been applied to literary science, comparative linguistics, language psychology, medical diagnosis (such as detection of Alzheimer’s), social psychology, sociology, education, law, sociolinguistics, and others. Stylometry has played a critical role in forensics, law enforcement, and cybercrime investigations. (There is apparently quite a bit of controversy still about how much may be asserted using stylometry in terms of a high legal standard of evidence.) Plagiarism detection systems use a type of n-gram matching and similarity detection, against large collections of reference documents.
A cursory search online surfaced a few tools. If nothing else, after this article, it is clear that stylometry is much more complex than plugging texts into a window and seeing what happens. However, there is something to be said for light experimentation to learn about functionalities.
AICBT has made an online authorship attribution tool available for public use at http://www.aicbt.com/authorship-attribution/online-software/ for educational and entertainment purposes.
One trial run using AICBT's Online Authorship Attribution Tool:
Figure 2: Word Clouds of the Tweetstreams for @SIDLIT and @TEDTalks
For fun, the Tweetstreams for @SIDLIT and @TEDTalks were Authors 1 and 2 respectively, and the unknown text was actually an email from one of the individuals who Tweets via @SIDLIT--which is Tweeted by multiple individuals. The results are, not surprisingly, mixed.)
Figure 3: A Simple Stylometry Data Run: Functional, Lexical, and Punctuation Analysis
There are downloadable tools for local machine processing of texts. One common linguistic analysis tool is Linguistic Inquiry and Word Count (LIWC), pronounced "luke."
Bhargava, M., Mehndiratta, P., & Asawa, K. (2013). Stylometric analysis for authorship attribution on Twitter. Big Data Analytics. V. Bhatnagar & S. Srinivasa, Eds. In the proceedings of the Second International Conference. Mysore, India. Dec. 2013. 37 – 47.
Daelemans, W. (2013). Explanation in computational stylometry. Computational Linguistics and Intelligent Text Processing. A. Gelbukh, Ed. In the 14th International Conference, CICLing 2013. Samos, Greece. Part 2.
Holmes, D.L. (1998). The evolution of stylometry in humanities scholarship. Literary and Linguistic Computing: 13(3), 111 – 117.
Montero, C.S., Munezero, M., & Kakkonen, T. (2014). Investigating the role of emotion-based features in author gender classification of text. Computational Linguistics and Intelligent Text Processing. A. Gelbukh, Ed. In the 15th International Conference, CICLing 2014. Kathmandu, Nepal. Proceedings, Part II.
Rao, J.R. & Rohatgi, P. (2000). Can pseudonymity really guarantee privacy? In the Proceedings of the 9th Conference on USENIX Security Symposium.
Rogers, S.P. & Krishnan, K. (2014). Chapter 7—Social Platforms. Social Data Analytics: Collaboration for the Enterprise. 75 – 91. Elsevier / ScienceDirect.
Rygl, J. (2014). Automatic adaptation of author’s stylometric features to document types. Text, Speech, and Dialogue. P. Sojka, A. Horák, I. Kopeček, & K. Pala, Eds. In the proceedings of the 17th International Conference. Brno, Czech Republic. Sept. 8 – 12, 2014.
Sapkota, U., Solorio, T., Montes-y-Gómez, M., & Rosso, P. (2013). Computational Linguistics and Intelligent Text Processing. A. Gelbukh, Ed. In the 14th International Conference, CICLing 2013. Samos, Greece. Part 2.
van Halteren, H., Baayen, H., Tweedie, F., Haverkort, M., Neijt, A.: New machine learning methods demonstrate the existence of a human stylome. Journal of Quantitative Linguistics 12(1) (2005) 65{77).
Shalin Hai-Jew works as an instructional designer at Kansas State University.
When people read for pleasure, and they are self-aware about the activity, they realize that their favorite authors offer a combination of stylistic features that create that engagement. For some fictional works, the appeal may come from a variety of factors: the main character, the supporting characters and their interrelationships, the plot twists, the dialogue, the action, and the humor; it may be the genre; it may be the particular time period; it may be the mysteries and riddles.
{kind=link}
Figure 1: Tablet Computer (an open-source image)
For some nonfictional works, the allure may come from the author’s access to information, his / her worldview or mental model of the world, and maybe the way he, she, or they express themselves. Author "voice" is a critical factor in both fiction and non-fiction.
Oftentimes, it’s not even just the writing. People consume ideas sometimes through the framework of human personality. Look at book jackets of most popular books, and there are stylized images of authors; there are author back stories that lend credibility to the writing when they actually embody what they write. In an analytical sense, the psychological elements include personality, intelligence (cognitive and affective), mental health, and other factors; these are extracted using stylometric profiling. Sociological factors include culture, gender, age, class, education level, region of language learning, and other factors.
To understand the importance of the author personality frame, note that virtually any author of note has a landing page with the book publisher where personal and professional details are shared; many have Wikipedia pages (albeit many are shut down when they are seen as too self-promoting). Professional authors are very much under public scrutiny, and their life details, their comments and Tweets, their families’ and friends’ comments, are all public fodder. It is no surprise that public authors—particularly those few who sell enormous numbers of texts and foreign rights and movie rights (vs. those on the “long tail”) often pay big money to assiduously protect their public reputations; how authors are perceived affects their readership and their book sales. People are highly responsive to whether they “like” or “dislike” a public personality.
This is partially why co-authorship and ghost writing are tricky things. When a well-known author co-writes with another, the style is invariably different, and those who have habituated to a certain style of writing may feel “betrayed” or “let down.” Ghost writing involves a hidden writer taking on a writing project left unfinished by a late author or continuing a popular writing series under the name of a late author. In such cases, publishing companies often do not share the information of the ghost authorship very publicly; the author himself / herself or the authoring team rarely ever comes to light even as they receive the royalty checks for their work.
Another way to surface reader assumptions is to read works from other time periods, socio-cultural contexts, works written in non-English native languages (or even translations from other languages). Such reading surfaces the role of “meta-knowledge,” assumptions about the world and the subject matter that may not be readily apparent for readers who are immersed in a particular culture (Daelemans, 2013, p. 451). Various literary genres evolve differently over time in different locales and from different histories; genre types affect the organization, the terminology, the writing styles, the assumed purposes for the readership, and what is valued. For years, researchers working to solve attribution problems have been advised to work “within the same genre” when working with lists of candidate authors for a particular work: “Genre effects generally will supersede authorial features in the discrimination process” (Holmes, 1998, p. 111). More recent works suggest that the genres that documents belong to should be considered when selecting features for building the stylometric models (Sapkota, Solorio, Montes-y-Gómez, & Rosso, 2013, p. 473).
A Long History of “Stylometry”
The uses of authorial discriminators to distinguish authorship is not a new phenomenon. This basic concept is built on the idea that people tend towards consistency and habit; given that, their behaviors and work may be patterned. In 1851, English logician and mathematician Augustus de Morgan first described and applied this method to the Pauline letters (13 epistles or books in the New Testament). Thomas Corwin Mendenhall, a physicist, conducted follow-on work in stylometry in 1887. Early analyses included frequency distributions (histograms, in this case) of various word lengths as a differentiator, without considering other underlying textual cues (such as genre). Canonical applications of stylometry include studies of the Shakespearean canon and the Federalist papers.
Computational Stylometry or the Metrics of Writing Style
Stylometry, the “metrics” of “style,” refers to quantitative and statistical analysis of literary or writing style. Authorship identification is an issue that has existed since the first document was written. Some researchers conflate stylometry with “authorship recognition,” “authorship identification,” and “authorship attribution,” but these latter are one type of application of practical stylometry. (Authorship attribution involves more than attributing the author’s identity; this work may also involve inference of other characteristics of the author: personality, intelligence, knowledge level, education, lifestyle, sentiments and beliefs, and other features.) Computational stylometry (also known as “computational stylistics”) has very much broadened the work of stylometry. It is thought that some combination of various objectively countable features of a text may be used to identify authorship in a scalable way.
The human stylome hypothesis. In the present computer age, researchers have put forward the “human stylome hypothesis” (van Halteren, Baayen, Tweedie, Haverkort, & Nejit, 2005); this proposal suggests that authors are uniquely distinguishable from others by measuring (counting) particular features of their writings. For this concept to apply, some researchers suggest that it only has to work on a case-by-case basis, with controls for contextual and other information; in such cases, the differentiation only has to occur between an identified author (or author set with groups of authors) with a known stylometric signatures (which some call “writeprints”) and an unknown or contested text or text corpora (body of texts). This is understood as a “closed-world problem” because some of its variables are known. In this context, the situation already helps limit some of the potential noise in the data. Also, such a defined context sometimes enables the (in)validation of the results with other ways of knowing authorship, such as historical, documentary, and other means.
Others suggest that there have to be identifiable and invariant (not changing over time or contexts) and non-manipulable stylometric signatures for authors over time, and that apply across socio-cultural, historical, and other contexts. At this end of the requirements continuum, an author’s signature has to be a correct and unique identifier—even as his or her writing style changes over time (conceptualized by some as a somewhat predictable rectilinear trajectory) and sophistication. (For individual authors, a higher time gap between “old” and “new” writing by authors has been found to correlate with more obvious and distinct categorizing.) There is also the challenge of how people change their writing styles across different social contexts and genres. At this very high threshold, theoretically and practically, such signatures should apply across languages, too.
At a very basic level, computers are highly efficient at counting, computations, and (latent or hidden) pattern finding. Computational stylometry enables the measure of anything countable in texts, but most often, these include lexical features (terminology/vocabulary of particular domains or individuals), syntactic features (structural aspects of language, such as n-grams, parts of speech, punctuation, and non-context-sensitive function words), and semantic (meaning-based aspects of language) ones.
The preferred types of features are those which are difficult to consciously manipulate, so that it is impervious to human deception. An individual’s stylometric “print” (a writing equivalent of a “fingerprint” and “handwriting”) is conceptualized as comprising latent data which emerges from unconscious and habituated behaviors. Unique and unusual patterns, like obvious turns of phrases, may be used for matching, but these can be fairly easily emulated.
Insights may be gained about larger groups of authors as well. The gender of an author may be identified based on emotional expressivity in the writing. For example, female writing tends to be “more contextual, personal and emotional than male writing, in which the style is typically more impersonal, formal and judgmental” (Montero, Munezero, & Kakkonen, 2014, p. 98). Various documents may be classified to certain types based on extracted features (including “punctuation analysis, sentence length distribution, syntactic analysis, n-gram syntactic analysis, analysis of morphological categories, analysis of morphological tags, frequency of word classes, frequency of word-class bigrams, frequency of stop words, word repetition analysis, Simpson’s vocabulary richness, analysis of typographical errors, and frequency of emoticons” (Rygl, 2014, pp. 55 – 56).
Supervised and Unsupervised Classifiers
The ability to uniquely describe writing in quantitative terms enables researchers to describe, compare, sort, attribute, and explore texts. These texts may be studied stylometrically in various units of analysis: individual documents, individual messages; author corpuses, select time periods of author production; genres, thematic analysis (across genres); culture-based outputs, and others.
In the research literature, the quantifiable aspects of writing style are set up as individual small-scale cases (with works by known authors vs. unattributed works, or training sets vs. test sets). These analyses are considered “supervised” classifiers because the machine learning algorithms are informed by training sets that model what to “look for.”
There are unsupervised stylometry methods as well, with classifiers applied to data sets to extract clusters of differing patterns based on its own ad hoc self-learning, without human direction. One application of this is to run the algorithms against sets of documents of unknown authorship and to extract author groups based on various types of similarity analyses (based on whatever features exist in the text set). Practically, this should identify the respective authors in the set based on the respective styles observed in the respective documents within that set. [Apparently, the greater the inherent differences between domains in a corpus (“domain broadness”)—such as “chemistry” and “entertainment”—the more effective the cluster analysis for stylometric differentiation. The larger the number of terms, for a more populated similarity matrix, the more informative a cluster analysis. Text corpuses would do well to have sufficient balance of sample types, so that the sample is not all of a few types and a few rare others; cluster analysis may have a difficult type identifier those on the “long tail.”
At the single text level, there are supervised and unsupervised methods for extracting relevant features. A supervised method involves using particular counts of elements theoretically salient to the work of stylometry. In terms of an emergent method of stylometric data extraction, there are a number of statistical methods. For example, the principal components of a text may be extracted, and any multicollinearity between the components may be eliminated using orthogonal rotation (Sapkota, Solorio, Montes-y-Gómez, & Rosso, 2013, p. 464).
Currently, it seems that there is a particular “sweet spot” in terms of numbers of texts and contextual conditions under which stylometry may be effective, with estimates of accurate authorship identification in the 70 – 80% accuracy range. In some contexts, such as closed scenarios with supervised training sets and 2-5 authors from a 15-subject pool, there can be up to 99% accuracy in author identification, or virtual certitude.
Stylometry and auto-generated text. The machine generation of text is already fairly widespread. There are some pretty coherent chatbots on social media platforms like Twitter and email systems that are able to fool people. Such chatbots have been designed with faux circadian rhythms, personalities, and improvisational capabilities (such as going to the Web to find topics to write about and sharing images found online). There are auto-text generators to create faux research papers (SCIgen) that have apparently fooled various gatekeepers of digital repositories. Stylometry has been used to identify auto-generated text. Some researchers have proposed using stylometry to create distractors for automated multiple-choice question generation in order to ensure that the distractors are sufficiently close to the real answer to make multiple-choice exams more difficult (through semantic similarity).
<BEGIN SIDEBAR>
“Adversarial Stylometry”
“Adversarial Stylometry”
Research on the number of words required to map a full author identity has converged on 6,500 words (Rao & Rohatgi, 2000). Other researchers suggest a minimum set of 5,000 – 10,000 words approximately. As others have pointed out, in a workplace, people have easily left samples of their own writing in the minimum range for stylometric analysis.
Over time, this text amount requirement has dropped precipitously. Stylometry has been effectively applied to short texts: microblogging Tweets (all 140-characters each), short message service (SMS) communications, instant messaging (IM), comments on a website, and other types of social media postings.
A branch of stylometry involves adversarial stylometry—with those who would identify all writers on one side and those who work to protect anonymity and pseudonymity on the other. Some research work suggests that current stylometric systems are fairly fragile and vulnerable to naïve human “adversaries,” who are just told to mask their own writing style by either obfuscating (hiding, muddying, or confusing) their personal writing style or imitating someone else. Another strategy involves writing less, so offering fewer samples from which stylometric features may be extracted. Such purposeful writing in a non-typical style is fairly effective at throwing some author identification systems off. (Usually, when there are ways to identify weaknesses in stylometric systems, their designers will work hard to create work-arounds against those weaknesses).
Privacy & Stylometry (YouTube)
An engaging video of some of this type of work was offered in the @CCCen video stream on YouTube on Jan. 4, 2012. This video, titled Privacy & Stylometry (26C3), features the full talk by Michael Brennan and features his work conducted under the guidance of Rachel Greenstadt, both of Drexel University. The talk is titled “Privacy & Stylometry: Practical Attacks against Authorship Recognition Techniques.”
These researchers, and likely others, are working on automated systems to anonymize writing styles in order to protect privacy.
<END SIDEBAR>
There are a number of text corpuses used in stylometry. Some of these were created as a part of funded research, with individuals who created texts based on directions from the researcher, for study. Some are named corpuses based on historical documents (that are in the public domain and no longer under copyright protections). Other documents are publicly available data sets extracted from social media platforms through their application programming interfaces (APIs).
The data downloaded from social media platforms are different than those of traditional documents. The grammars and lingo are different. It is harder to define authorship. (For Twitter, is a Tweetstream for an account the contributions of one author, a robot, a cyborg, multiple individuals, various combinations of the prior)? One research team defined the lexical features they used to explore microblogging corpora: the “total number of words per tweet, total number of sentences, total number of words per sentences, frequency of dictionary words, frequency of word extensions, lexical diversity, mimicry by length, (and) mimicry by word,” (Bhargava, Mehndiratta, & Asawa, 2013, p. 41). They also looked at more original features, like the extension of words by repeating letters, such as “hiiiii!!!” In terms of syntactical features, they explored the following: the “total number of beginning of sentences (BOS) characters capitalized, number of punctuation per sentence, frequency of words with all capital letters normalized over number of words, frequency of alphanumeric words normalized over number of words, number of special characters, digits, exclamation and question marks, number of upper case letters, (and) binary feature indicating use of quotations” (Bhargava, Mehndiratta, & Asawa, 2013, p. 41). They also explored indicators of whether a Tweet was a re-tweet. They also measured the numbers of hashtags, user mentions, and URLs—each normalized over the numbers of words (Bhargava, Mehndiratta, & Asawa, 2013, p. 41). They also explored the number of occurrences of emojis. For all the “big data” aspects of microblogging messages, the numbers of authors were fairly limited:
Given just 200 tweets per author, and 10-15 suspects, we obtain an F-score in the range of (85.59% to 90.56%). However, if the number of suspects is increased to 20, the F-score drops drastically to a low value of 64.48%. Evidently in case of lesser number of tweets, we need to narrow down on our list of suspected authors. For 250 tweets per author, again best results have been achieved with 15 authors, where the F-score reaches 94.79%. With increase in data, we have an increase in F-Score for 20 authors (from 64.48% to 71.49%) indicating how an increase in content might be required with more number of users. With 300 tweets, again our best F-score is 88.64% with 15 authors. The F-score for 20 authors further increases with increase in number of tweets under consideration (Bhargava, Mehndiratta, & Asawa, 2013, p. 45).
The work of stylometry applied to user-generated social media data is still in its infancy and is highly promising. Some questions that may be asked include the following:
- Based on style, does an individual or group have multiple accounts on a social media platform? Across a range of platforms?
- Are there latent themes (suggesting interests and motives) in the messaging on a particular social media account?
- How are certain styles diffusing on the Internet? On particular social media platforms?
- What mix of style metrics suggests a particular author type?
- What mix of style metrics suggests a particular social media platform (as genre)?
Conclusion
This article is a general summary one written at an abstract level. This writing project was pursued because the topic applies to much of the research work applied to social media (an area of interest for the author). Also, a recent challenge posited by a presenter of a webinar that the author attended involved the lack of “computational thinking,” and this issue of computational stylometry seemed to offer an opportunity to explore what this thinking may mean in this context. Also, a number of software tools enable some types of stylometric analysis, which may extend the research work.
Stylometry has been applied to a wide range of empirical and evidence-based research. In political science, the speeches and writings of leaders have been analyzed using stylometry. In history, various documents have been analyzed using style metrics. Stylometry has been applied to literary science, comparative linguistics, language psychology, medical diagnosis (such as detection of Alzheimer’s), social psychology, sociology, education, law, sociolinguistics, and others. Stylometry has played a critical role in forensics, law enforcement, and cybercrime investigations. (There is apparently quite a bit of controversy still about how much may be asserted using stylometry in terms of a high legal standard of evidence.) Plagiarism detection systems use a type of n-gram matching and similarity detection, against large collections of reference documents.
Some Hands-On Resources
A cursory search online surfaced a few tools. If nothing else, after this article, it is clear that stylometry is much more complex than plugging texts into a window and seeing what happens. However, there is something to be said for light experimentation to learn about functionalities.
AICBT has made an online authorship attribution tool available for public use at http://www.aicbt.com/authorship-attribution/online-software/ for educational and entertainment purposes.
One trial run using AICBT's Online Authorship Attribution Tool:
{kind=link}
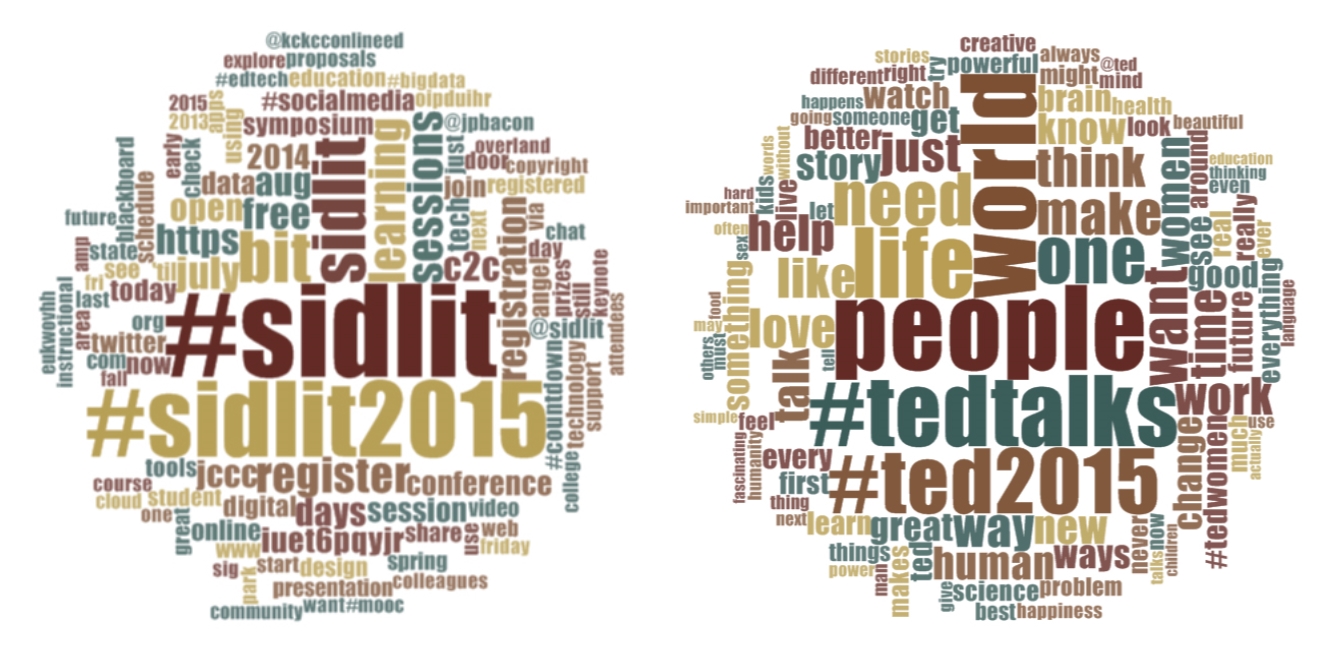
Figure 2: Word Clouds of the Tweetstreams for @SIDLIT and @TEDTalks
For fun, the Tweetstreams for @SIDLIT and @TEDTalks were Authors 1 and 2 respectively, and the unknown text was actually an email from one of the individuals who Tweets via @SIDLIT--which is Tweeted by multiple individuals. The results are, not surprisingly, mixed.)
{kind=link}
Figure 3: A Simple Stylometry Data Run: Functional, Lexical, and Punctuation Analysis
There are downloadable tools for local machine processing of texts. One common linguistic analysis tool is Linguistic Inquiry and Word Count (LIWC), pronounced "luke."
References
Bhargava, M., Mehndiratta, P., & Asawa, K. (2013). Stylometric analysis for authorship attribution on Twitter. Big Data Analytics. V. Bhatnagar & S. Srinivasa, Eds. In the proceedings of the Second International Conference. Mysore, India. Dec. 2013. 37 – 47.
Daelemans, W. (2013). Explanation in computational stylometry. Computational Linguistics and Intelligent Text Processing. A. Gelbukh, Ed. In the 14th International Conference, CICLing 2013. Samos, Greece. Part 2.
Holmes, D.L. (1998). The evolution of stylometry in humanities scholarship. Literary and Linguistic Computing: 13(3), 111 – 117.
Montero, C.S., Munezero, M., & Kakkonen, T. (2014). Investigating the role of emotion-based features in author gender classification of text. Computational Linguistics and Intelligent Text Processing. A. Gelbukh, Ed. In the 15th International Conference, CICLing 2014. Kathmandu, Nepal. Proceedings, Part II.
Rao, J.R. & Rohatgi, P. (2000). Can pseudonymity really guarantee privacy? In the Proceedings of the 9th Conference on USENIX Security Symposium.
Rogers, S.P. & Krishnan, K. (2014). Chapter 7—Social Platforms. Social Data Analytics: Collaboration for the Enterprise. 75 – 91. Elsevier / ScienceDirect.
Rygl, J. (2014). Automatic adaptation of author’s stylometric features to document types. Text, Speech, and Dialogue. P. Sojka, A. Horák, I. Kopeček, & K. Pala, Eds. In the proceedings of the 17th International Conference. Brno, Czech Republic. Sept. 8 – 12, 2014.
Sapkota, U., Solorio, T., Montes-y-Gómez, M., & Rosso, P. (2013). Computational Linguistics and Intelligent Text Processing. A. Gelbukh, Ed. In the 14th International Conference, CICLing 2013. Samos, Greece. Part 2.
van Halteren, H., Baayen, H., Tweedie, F., Haverkort, M., Neijt, A.: New machine learning methods demonstrate the existence of a human stylome. Journal of Quantitative Linguistics 12(1) (2005) 65{77).
About the Author
Shalin Hai-Jew works as an instructional designer at Kansas State University.
| Previous page on path | Cover, page 18 of 28 | Next page on path |
Discussion of "A Light Stroll through Computational Stylometry and its Early Potential"
Add your voice to this discussion.
Checking your signed in status ...