Experiments with word embeddings
A possible computational approach to analyzing The Bengal Annual for 1830 might be driven by machine learning algorithms that generate word vectors to represent word meanings. My research question is: how might word vectors facilitate a comparison of canonical and non-canonical literature, or a comparison of how concepts important to Romanticism evolved in the nineteenth century?
To take a step back, word embeddings are high-dimensional vectors of real numbers that map tao a lower-dimension vector space. They are based on the “distributional hypothesis,” which states that “difference of meaning correlates with difference of distribution.” concept that word meanings are generated by the contexts in which they are used, and are often employed to perform machine translation or measure word similarity. Their usefulness is dependent on the breadth and domain-relevance of the larger corpus they are trained on.
In order to examine how ideas that we typically associate with Romanticism are represented in non-canonical Romantic prose and poetry (and how well those ideas map to wider word associations of the period) I am in the early stages of cleaning and annotating the text of the annual. This will help me experiment with different text analysis algorithms that explore concepts in the annual and differences in author vocabularies. Works under investigation might also include The Oriental Annual, as well as other texts from our course that fall outside the traditional canon of Romantic Literature, such as The Woman of Colour: A Tale.
{kind=link}
The close readings of the themes represented in the annual’s poetry and prose are a baseline for understanding differences between the annual’s contents, and the contents of classic Romantic texts like Lyrical Ballads. Concepts like beauty, Orientalism, and gender become more contextual when we formally locate them according to 1) an author's perspective and 2) an author's space and place.
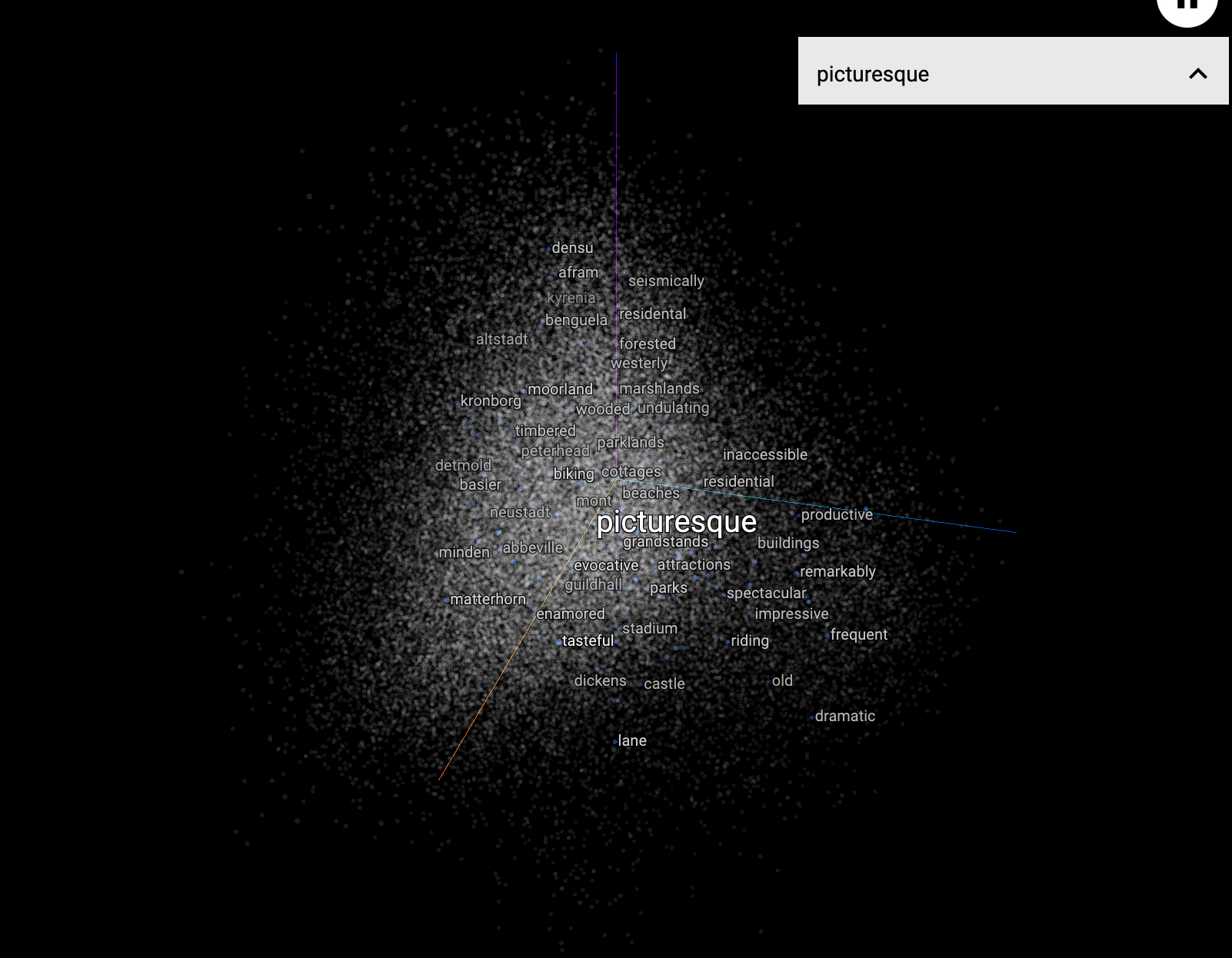
How do these insights compare to the insights that can be generated by state-of-the-art machine learning techniques for representing words as data? Because word meanings evolve over time, literary scholars can only use word embeddings usefully if they have better datasets (or corpora) that match their intended period of scholarly inquiry. To understand how such a problem is being addressed across disciplines, I look at the following three case studies (from sociology, corpus linguistics, and literary critique) to learn how scholars are using novel frameworks to generate and study word embeddings diachronically.
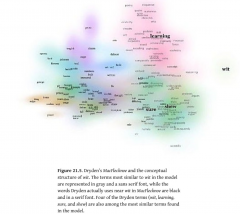
“Spaces of Meaning: Vector Semantics, Conceptual History, and Close Reading”
Michael Gavin, Collin Jennings, Lauren Kersey, and Brad Pasanek
Debates in Digital Humanities
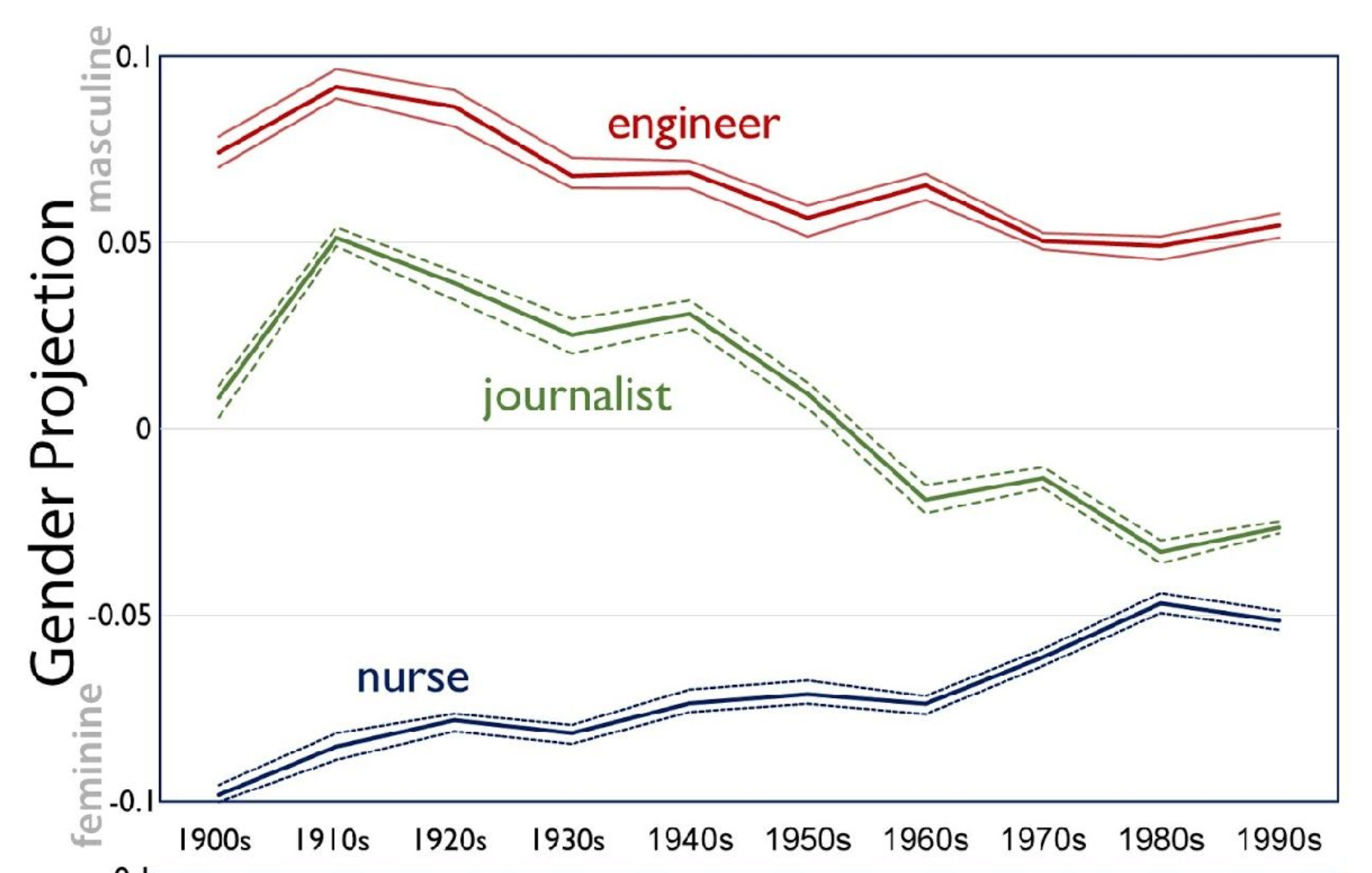
"The Geometry of Culture: Analyzing Meaning through Word Embeddings"
Austin C. Kozlowski, Matt Taddy, James A. Evans
University of Chicago and Amazon
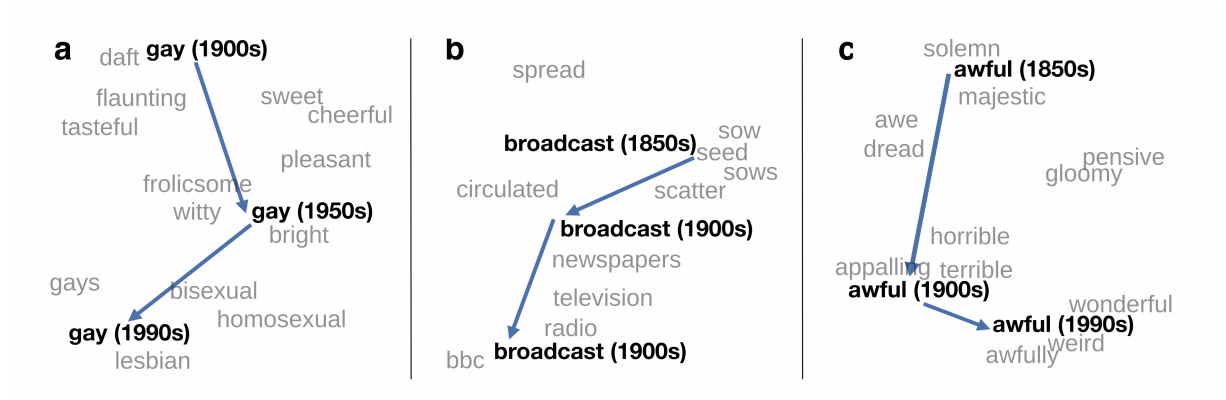
"Diachronic Word Embeddings Reveal Statistical Laws of Semantic Change"
William L. Hamilton, Jure Leskovec, Dan Jurafsky
Department of Computer Science, Stanford University
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}