Constructing Data
Collecting
In her book New Digital Worlds Roopika Risam writes that "the opportunity to intervene in the digital cultural record—to tell new stories, shed light on counter-histories, and create spaces for communities to produce and share their own knowledges should they wish—is the great promise of digital humanities" [2]. According to this vision of digital humanities, collection building should not be a straightforward matter of digitizing the written and material records as they have been preserved by governments, libraries, and museums. Rather, it should entail critical decisions about: what to collect and why; how to organize, manage, and disseminate collections; and who participates in these processes. This type of critical inquiry has begun to coalesce in new digital collection methods ranging from participatory, performing, and post-custodial archives, to cultural protocols for indigenous archival materials (Native American, Aboriginal and Torres Strait Islander).Collecting Activity
In the first activity of this section, you will upload five to ten digital objects related to a research or teaching interest of your choosing, and develop a short statement describing your collection. For the purposes of this workshop we will use Scalar, a free and open-source authoring and publishing platform developed by the Alliance for Networking Visual Culture at the University of Southern California [3].To begin, register an account and duplicate the existing book titled "Portfolio Template DHRI@A-State."
Then, follow the import media directions (linked via the annotation above) to create a media file for each of your selected items. Keep track of where your items come from and title them "Item 1," "Item 2," "Item 3," etc. At this stage, do not add any additional information to your items. We will add titles, descriptions and metadata in the next activity.
After you have imported your collection items, go to the "Data for Humanist" page to write a short statement describing your collection as it currently stands or as you imagine it in expanded form. Navigate to the "Data for Humanist" page by pressing the blue "Continue" button pictured above, or via the main menu tab. Once you get there, press the edit button and begin typing. Your statement should include information about the collection's scope (i.e. subject area, chronological period, geographical area, genre, and/or media type), and a discussion of the collection's objectives in light of the above discussion.
Encoding
For digital collections, item information is frequently encoded in relational databases. A relational database is a structured set of data that contains a series of formally described tables from which data can be queried or organized in different ways. This structure enhances searching, browsing, and exhibition functions by enabling users to access items and reassemble collections based on tabular information.To create a collection with these functions, you can either build a relational database from scratch or use a content management system, such as Scalar, that functions as a relational database [4].
Either way, before getting started you will want to develop a metadata schema for your collection. Metadata, or data about data, "provides a means of indexing, accessing, preserving, and discovering digital resources" [5]. While metadata can serve different functions related to these tasks, in this workshop we will be primarily concerned with its descriptive function [6]. Specifically, you will learn how to encode individual items with descriptive metadata and develop a schema to ensure that all of the items in your collection are described consistently to facilitate human and computational analysis.
To create your metadata schema, it is generally advisable to build upon established ontologies and/or controlled vocabularies. Not only will this help you structure your data, but, ultimately, it will increase access and allow you to integrate your collection into Linked Data initiatives. For the purposes of this workshop, you will build a schema based on Dublin Core (DC), which is one of the most popular ontologies for describing digital resources. Dublin Core consists of fifteen elemental terms (contributor, coverage, creator, date, description, format, identifier, language, publisher, relation, rights, source, subject, title, and type) and a series of qualified terms that extend or refine the original fifteen elements. Many DC terms, in turn, can be linked to controlled vocabularies, such as those developed by the Library of Congress and the Getty Institute, to increase access and provide additional structural support.
Before building a metadata schema based on Dublin Core, it is worth drawing attention to DC alternatives and critiques. While Dublin Core is explicit in its cross-disciplinary aim to transcend the "boundaries of information silos on the Web and within intranets," you may have reasons to use a more specialized ontology, such as the VRA Core for visual culture, the PBCore for audiovisual content, and the IPTC for media resources [7]. Alternatively, you may have reasons to eschew established ontologies and vocabularies altogether; be it to 'decolonize knowledge' or "represent uncertainty, historical contingency, conflict, variation, instability, and multidimensionality" [8]. The stakes of eschewal in today's networked knowledge society, however, are high. As Michelle Schwartz and Constance Crompton write about their decision to reject "existing data models and international standards" in Lesbian and Gay Liberation in Canada (an interactive digital resource for the study of lesbian, gay, bisexual, and transgender history in Canada from 1964 to 1981) "in an age where we recognize the right to be forgotten, we must also weigh the danger... of hiding our history" [9].
Encoding Activity
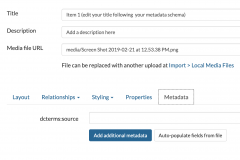
In this activity you will develop a metadata schema for your collection based on Dublin Core, and follow your schema to encode each of your imported items. As the previous discussion should make clear, the objective of this activity is to practice using metadata to structure your collection, not to convince you that all collections should be encoded with Dublin Core.To create your schema: consult the Dublin Core Elements and Qualifiers manuals; note that each term is optional and can be repeated; and remember that many DC terms can be paired with controlled vocabularies. Your schema should include directions and examples for titling, describing, and adding DC metadata to your collection items (along the lines of the example below).
dcterms: Spatial
Direction: Provide GPS coordinates of the place where the original analogue item was created. You can search for coordinates using this website. Put the DD coordinates (separated by a ",") in Scalar's dcterms: spatial field. (Note that GPS coordinates must be formatted in this manner to create maps in Scalar).
Example: 41.65606, 0.87734
After completing your schema on the "Data for Humanist" page of your portfolio, use the search button to navigate to each of your item pages and edit them to include the appropriate titles, descriptions, and metadata.
This page has paths:
- Data for Humanists Andrea Davis
This page references:
- Roopika Risam, New Digital Worlds
- Collection Building Platforms
- Metadata Functions
- Custom Database
- Schwartz and Crompton, "Remaking History"
- Ontology
- Trevor Owens, "Defining Data for Humanists: Text, Artifact, Information or Evidence?"
- Controlled Vocabulary
- Relational Databse
- Gilliland, Introduction to Metadata
- Adding Additional Metadata
- Portfolio Template DHRI@A-State
- Encoding
- About Dublin Core
- Dublin Core Terms
- Editing a Media Page
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}