Using “Article Networks” on Wikipedia
By Shalin Hai-Jew, Kansas State University
- How closely connected are words in a document or a body of text (like a Tweetstream)?
- Which ideas are connected to other ideas in the collective (un)conscious in social media, in literature, in content tagging, and in microblogging?
- How have ideas and practices affected different disciplines over time?
Link analysis enables “structure mining” or the examination of structural relationships between entities (words and phrases, for example). Data visualizations from link analyses enable people (and machines) to get a quick sense of related ideas for exploration and insight. There are word trees, cluster diagrams, graphs, and others that express link networks visually.
{kind=link}
On Wikipedia
The first wiki was created by Ward Cunningham in 1994 and released for use in 1995. Wikis are websites that enable distributed collaborative editing of contents. The term "wiki" means "quick" in Hawaiian. Wikipedia is a crowd-sourced and self-organizing encyclopedia that is globally accessible, and it is built on a wiki platform.
{kind=link}
One fun way to get started is to look at article networks on the English-language Wikipedia, which has 4.6 million articles current (as of October 2014). There are other independent Wikipedias based on other languages: Spanish, German, Chinese, Portuguese, Russian, Japanese, French, Italian, and Polish. (With the unicode character set, a range of languages--including those based on characters--may be used for mapping text-based networks. Such networks may be multilingual ones, too.) Wikipedia was built on an open-source MediaWiki understructure. This free online encyclopedia enables access to a wide range of information, all of it released through a generous Creative Commons licensure or full release to the public domain.
{kind=link}
Very simply, this article-article network approach identifies the article pages on Wikipedia which are connected to each other. (This does not capture outlinks from an article.) Looking at these connections may enable understanding of knowledge structures. The focal or "seed" article will be represented at the center of the graph. The articles listed close-in to the center are highly related to the central article. Those farther out on the periphery are less related. Closeness or proximity may be indicated by article relatedness or similarity.
The initial data extractions here involve 1-degree relationships or direct link relationships with the focal article. (A 1.5-degree extraction will show not only the direct links to the focal article but also the connections between the “alters” in the original network—or the articles with direct ties to the focal article. A 2-degree extraction will show not only the original focal article and its direct ties in an ego neighborhood…but the direct ties between the “alters” and their own ego neighborhoods.)
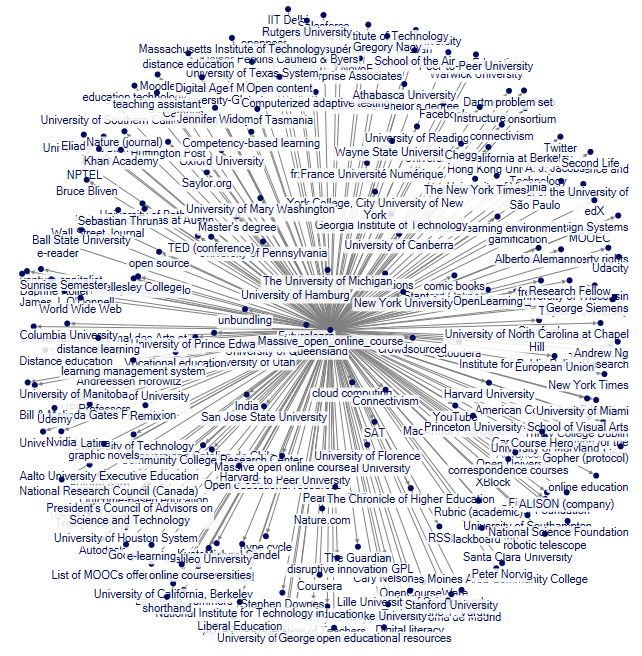
To give a sense of what article-article networks look like from Wikipedia, an extraction was recently done on “Massive open online course”. The “Massive_open_online_course” article network shows an ego neighborhood that relates to a number of universities, related technologies, MOOC platforms, academic publications, and other related pages.
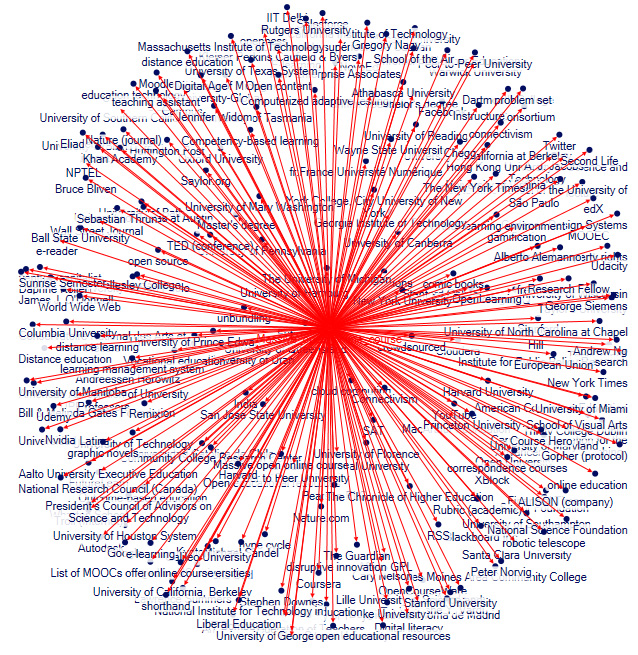
To provide a sense of the one-degree nature of this data extraction, the main node at the middle (“Massive_open_online_courses”) was highlighted, and the direct links (known as “edges) may be seen to all the “alters” of the network. The vertices here all relate to the center article.
Example: Article Networks from Wikipedia
To give a sense of what article-article networks look like from Wikipedia, an extraction was recently done on “Massive open online course”. The “Massive_open_online_course” article network shows an ego neighborhood that relates to a number of universities, related technologies, MOOC platforms, academic publications, and other related pages.
{kind=link}
To provide a sense of the one-degree nature of this data extraction, the main node at the middle (“Massive_open_online_courses”) was highlighted, and the direct links (known as “edges) may be seen to all the “alters” of the network. The vertices here all relate to the center article.
{kind=link}
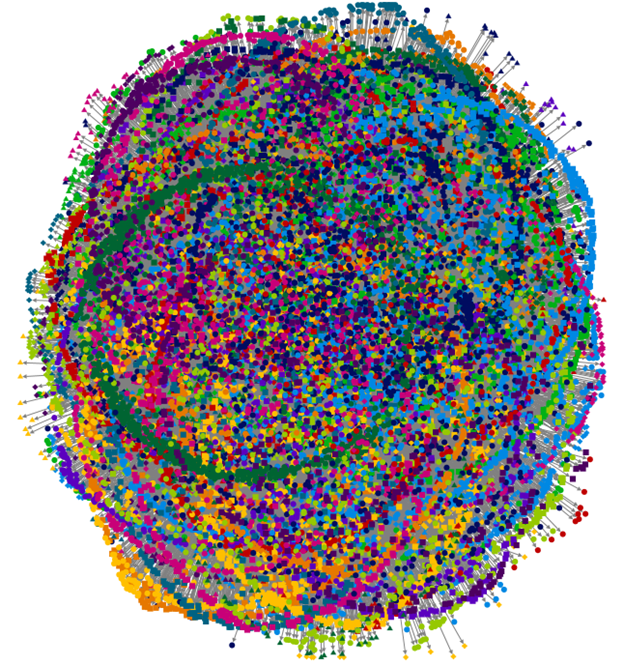
To give a sense of what the same focal node (“Massive_open_online_course”) would look like with a 1.5 degree crawl, please see the following. The 1-degree network has 232 vertices, 231 unique edges, and it is all expressed as one group. Just 1.5 degrees out, there are 19,390 vertices and 25,835 unique edges and 48 clusters or groups. The size of the 1.5-degree graph also means that the Harel-Koren Fast Multiscale layout algorithm required up too much computational expense on a laptop, so the visualization was built using the Fruchterman-Reingold force-based layout algorithm.
To avoid taking up too much space, this graph will be expressed without labels on the vertices (nodes). Each shape is a node in the graph, and they each represent an article or page. At the middle is still the focal node article. (All such graphs come with datasets from which the graphs are drawn. Those datasets--stored in tables--will be helpful for analysis in addition to the extracted visuals.)
{kind=link}
A User-Based Article Network
An article network may be applied to any of the 4.7 million pages of Wikipedia (or actually any wiki with a MediaWiki understructure that is properly set up on the server and is public).
A “user” page may be crawled in order to see what the user has been editing or writing on Wikipedia. To this end, an extraction was done on “sadads” on Wikipedia (aka Alex Stinson at K-State). A glance on his article network may indicate something of his expertise and passions.
{kind=link}
The downloadable dataset is accessible at the NodeXL Graph Gallery. (This information was included here with Alex Stinson's express permission.)
The Techno
{kind=link}
There are widely available computer programs used to create content-based link networks from texts and text corpuses. For these examples, the free and open-source tool Network Overview, Discovery and Exploration for Excel (NodeXL) was used. This is downloadable from Microsoft’s CodePlex platform, courtesy of the Social Media Research Foundation.
About the Author
Shalin Hai-Jew works as an instructional designer at Kansas State University.
| Previous page on path | Cover of C2C Lantern (Fall 2014 / Winter 2015), page 13 of 20 | Next page on path |
Discussion of "Using “Article Networks” on Wikipedia"
Add your voice to this discussion.
Checking your signed in status ...