Creating Codebooks in NVivo (through Reports...through Share)
Simply, a codebook in qualitative or mixed methods research is an authoritative description about how research data is analyzed for a particular project. It is a "coding instrument" that may be heritable and used by others. If it is well designed, with coding to saturation, it may be insightful and revelatory in the particular domain.
Some Features of Codebooks / Code Lists
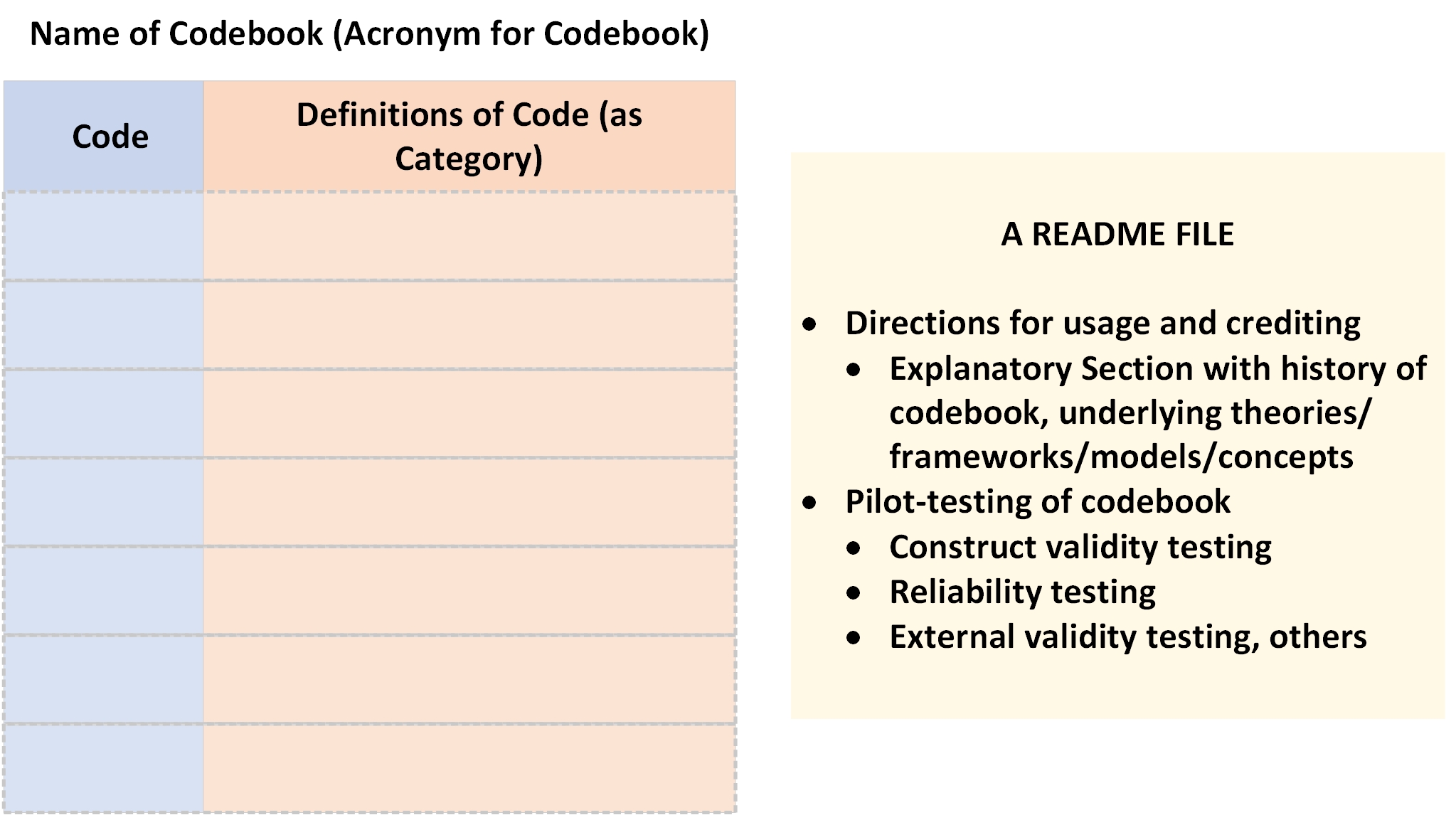{kind=link}
The basic elements of a codebook used in such research may include things such as the research variables [often represented as nominal (discrete and non-continuous) variables with qualitative variances and described in part with categorical data], the prerequisites for an item to fit that category, and examples of items that might fit that category. Depending on the domain, there may be specific criteria and details to define gradations of meaning in the codebook and to help users to differentiate between one categorization or coding vs. another.
Codebooks should include names, so they may be cited. (The acronyms from the codebook names should read well or at least not offensively.) There should also be a README file, with a history of the codebook, credits, and prior pilot-testing research to show the power of the codebook (and various validation measures).
Codebook Creation
A priori, emergent, or mixed codebook creation. There are three general ways that a codebook is defined in terms of how it originates.
1. An “a priori” defined codebook is often based on a particular theoretical approach or model, which defines the variables that the researcher or research team codes to. In this approach, the categories of the nodes are pre-defined based on theories, models, or prior research, or some combination of these elements. This is a more structured approach, and the researcher is somewhat pre-conditioned to look for particular data in a particular way. (This may be done to test a theory or model, or it may be done to apply the theory or model to a new context, or this may be done to test or apply a variant of an extant theory or model.)
2. An “emergent” defined codebook is often based on what the researcher or research team notices as they start reading and analyzing the collected data. There is no pre-existent set of nodes that the researcher codes to. Here, the researcher is engaging with the data to see what may be directly observed. There may not be particular theory or modeling or prior research that informs how this data may be approached. Or it may be that the researcher or research team wants to take a fresh approach.
3. A mixed approach may involve both some initially pre-defined nodes based on theory or models or prior research, and some other emergent nodes that are added on later during the coding process. This approach may begin with a "start list" of codes based on theory or research questions or hypotheses, but the codebook then evolves as the researcher / research team proceeds with the work of coding data and comes across deeper insights...that ultimately affect the form of the codebook.
(In quantitative research, a codebook describes how the data files or data sets were arrived at and structured.)
Manual Coding vs. Autocoding vs. Combined
Codebooks used in qualitative research may also be coded in various ways. A manually coded codebook is one that is created by a researcher / research team interacting with published research and data. Such a codebook is manually created or created by hand. An "autocoded" codebook is one that is created through "machine learning" in either a supervised (human-informed) or unsupervised (non-human informed, but informed by the applied algorithms and dictionaries) way. "Coding by existing pattern" is a supervised machine learning application in NVivo; sentiment analysis and theme/subtheme extraction autocoding approaches are unsupervised machine learning approaches. Finally, codebooks created in a combined way may draw codes from both manual and autocoding methods. In such cases, the methods are important to document along with the sequential applied steps.
Codebooks in Qualitative Research
So how is a codebook used in qualitative research? A codebook is used by a researcher or a research team to help “norm” the coding, so that all the members of the team generally align with some degree of similarity in terms of how they process the research data. (A solid codebook is important for some types of multi-coding. A team may also begin without a codebook but collaborate around the separate individuated codebooks and define one together before proceeding with the formal coding of the full dataset.) A codebook essentially operationalizes the coding based on theory, models, and / or prior research.
A fully evolved codebook is sometimes published along with the research. Other times, it is not published, but its information is used as part of the methodologies section of a published work. This is not only used by the researchers, but other researchers who want to either replicate or conduct follow-on research may use the codebook to guide and inform their work. Some codebooks are published in a stand-alone way, along with a lot of documentation (and sometimes even a related dataset).
Using the Collective Nodes as a Codebook
In NVivo, each node may be elaborated on and described with text. Each node may be named and re-named. Each node may be placed in relation to other nodes through the direct description of relationships. They may be structured in relationship to each other in terms of a hierarchy in the Navigation View (with child, grandchild, greatgrandchild, greatgreatgrandchild nodes, etc.). Coding nodes may be conceptualized as mutually exclusive or not. In the first context, once data is coded, it cannot be recoded at another node; in the latter context, data may be multi-coded to different locations.
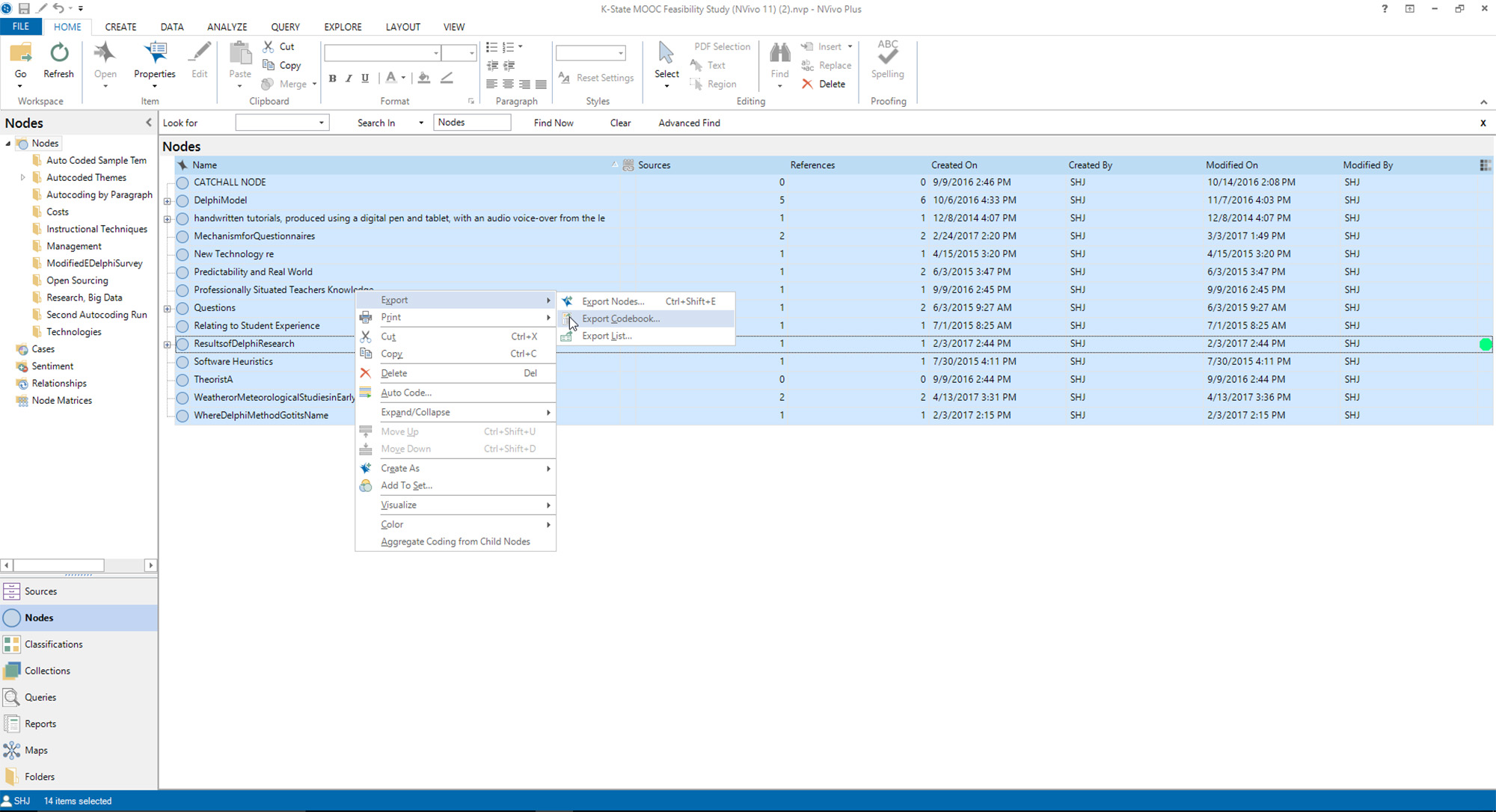
A Simple Codebook Export from Nodes (Codes)
The simplest way to make a codebook is to go to the desired nodes to include, highlight the desired ones, and export the codebook.
{kind=link}
An Overview of Some Steps to Creating a Codebook from NVivo
To create a “codebook” from the node structure in NVivo, it is helpful to make sure that each node is properly named; each node should also be sufficiently described—so that it is clear what information should be coded to that node (whether exclusively or non-exclusively). The descriptions should be sufficiently comprehensive. If the descriptions are described as phrases, then generally all descriptions should be written as phrases; if they are written as full sentences, then generally all descriptions should be written as full sentences—for parallel construction.
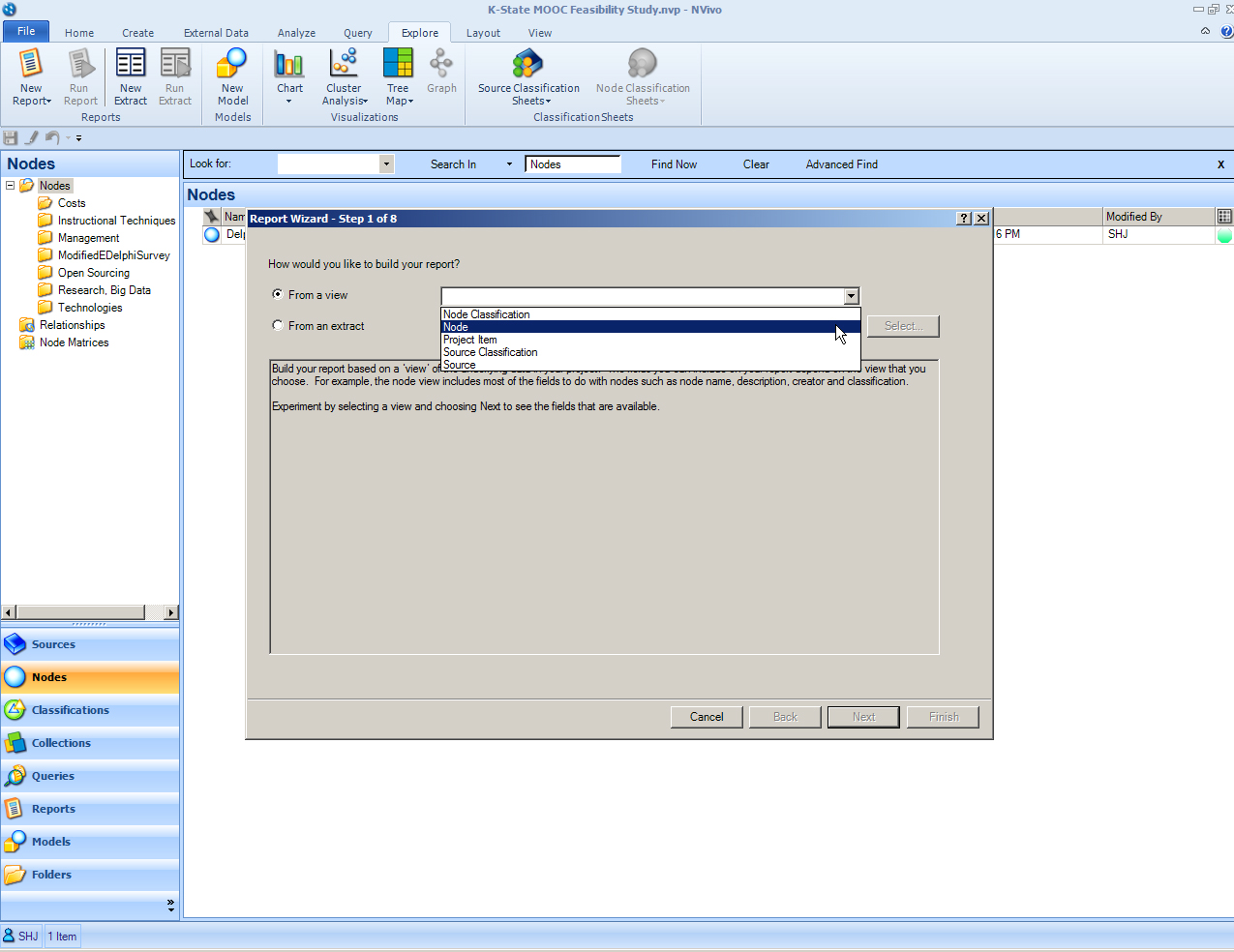
To begin the creation of a codebook, go to the ribbon. Click on the Explore tab. Go to the New Report button in that tab. The pop-up Report Wizard Window enables two choices: “From a view” or “From an extract”. For this first example, stay with the first radio button for “From a view.” In the dropdown menu, select Node.
{kind=link}
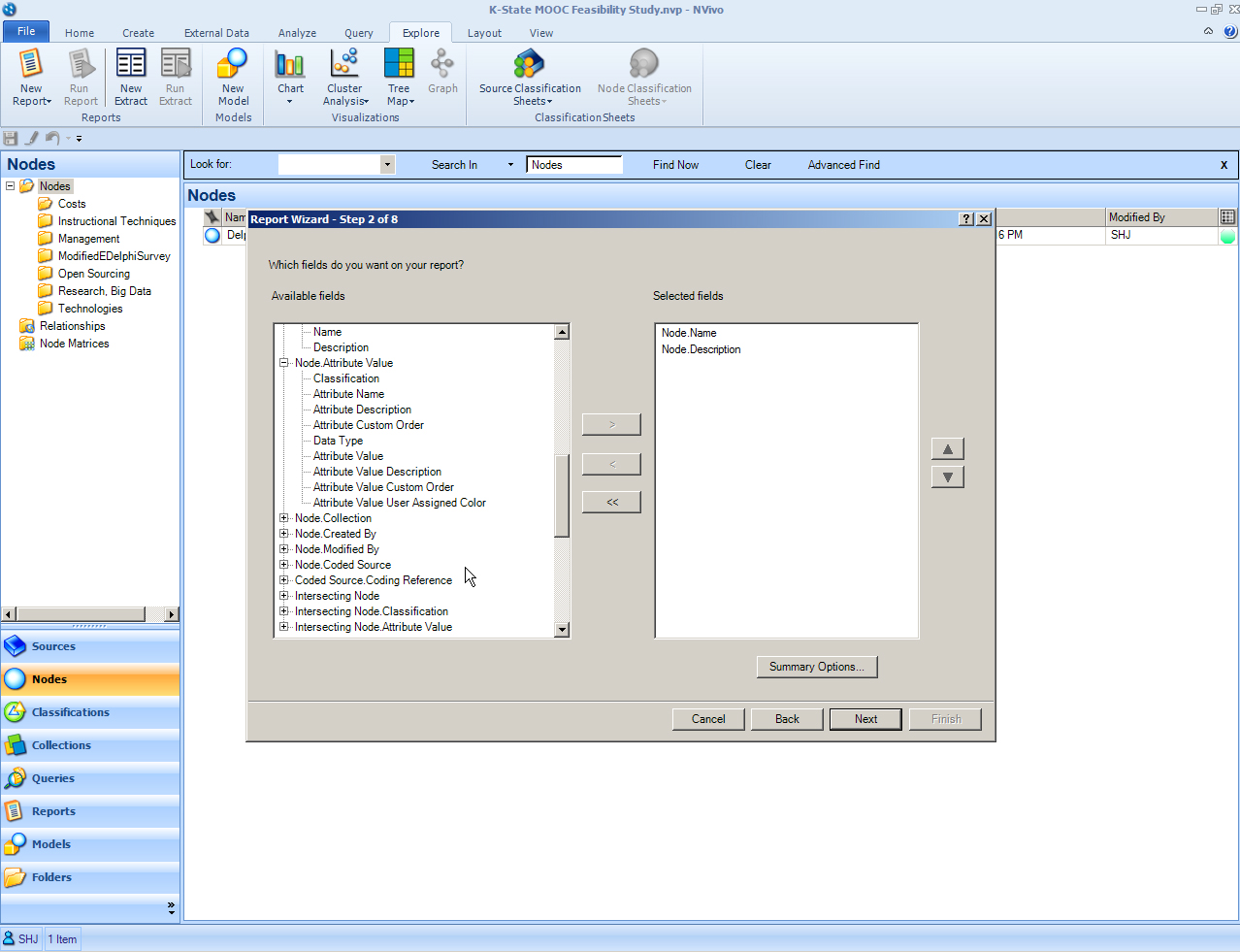
In the next screen, you will be asked to select your preferred fields from the left menu. Click on the plus signs to reveal the full selections under each heading. Click on the selected fields to choose them, and then click on the right arrow to move them to the selected window to the right. If you want to choose two selections at a time, you may hold down the shift key and then click with your mouse on the selections.
{kind=link}
Once the selected fields have been selected, the researcher will be asked if he or she wants to filter the results (to provide more granular data) and then also if he or she wants to group particular levels of data. Once that is done, the researcher should click on to the next screen. The next screen involves placing the various pieces of data into a preferred order in the report.
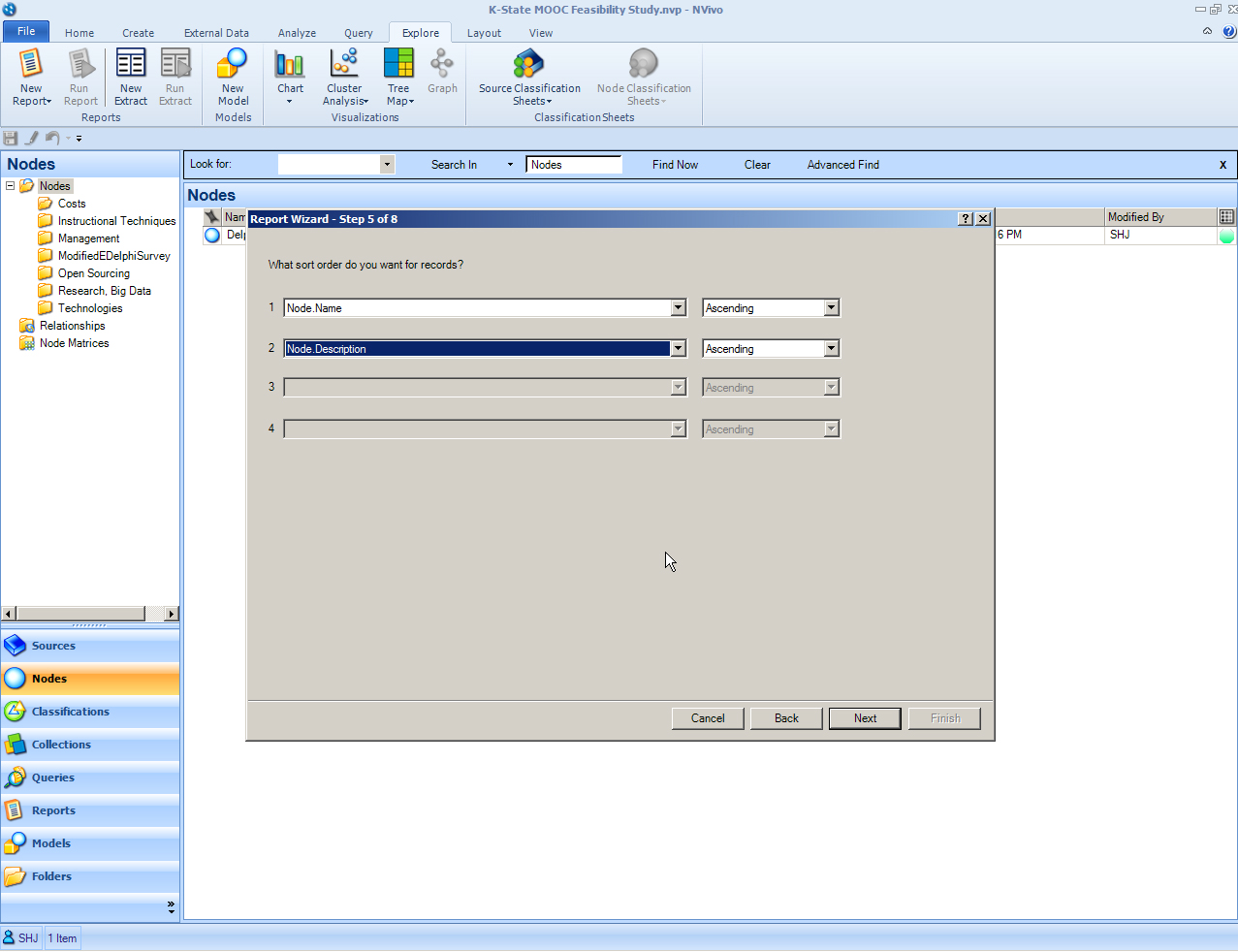{kind=link}
The next screen requires that the researcher define the general layout of the elements of the report, whether in a columnar or a tabular format, and then whether to go with portrait or landscape layout.
{kind=link}
Next, the researcher has to select from a few report styles in terms of font, colors, and other aspects of look-and-feel.
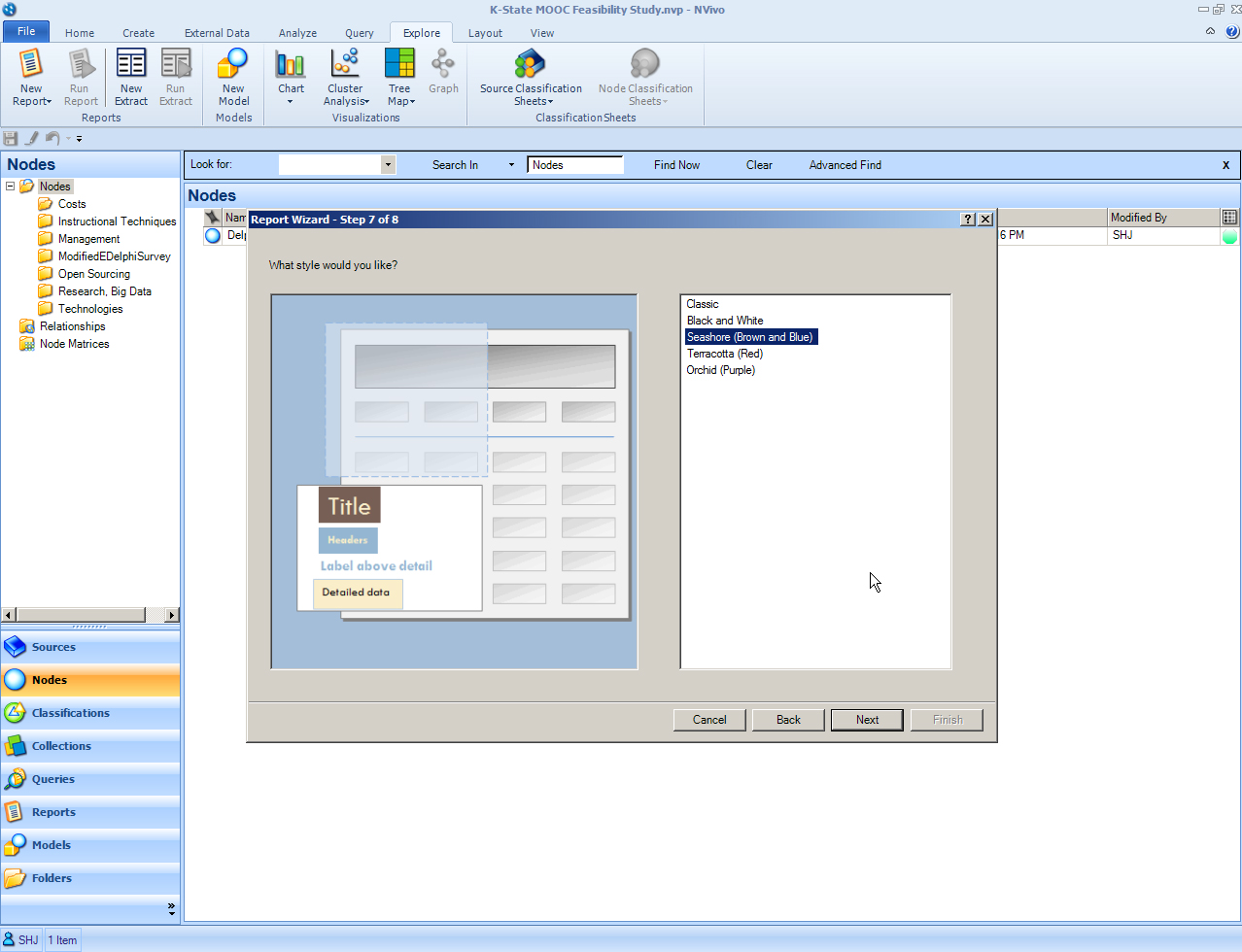{kind=link}
The last step involves naming the report and adding a descriptor. If this report is just for internal use, these fields do not have to be pristine. If this report may be used for presentation or even publication, it is important to make sure that the fields are wholly correct. Additional revisions are possible if the report is exported as a Word file; however, if it is saved as a fixed PDF format, then the report should be as correct as possible at the time of export.
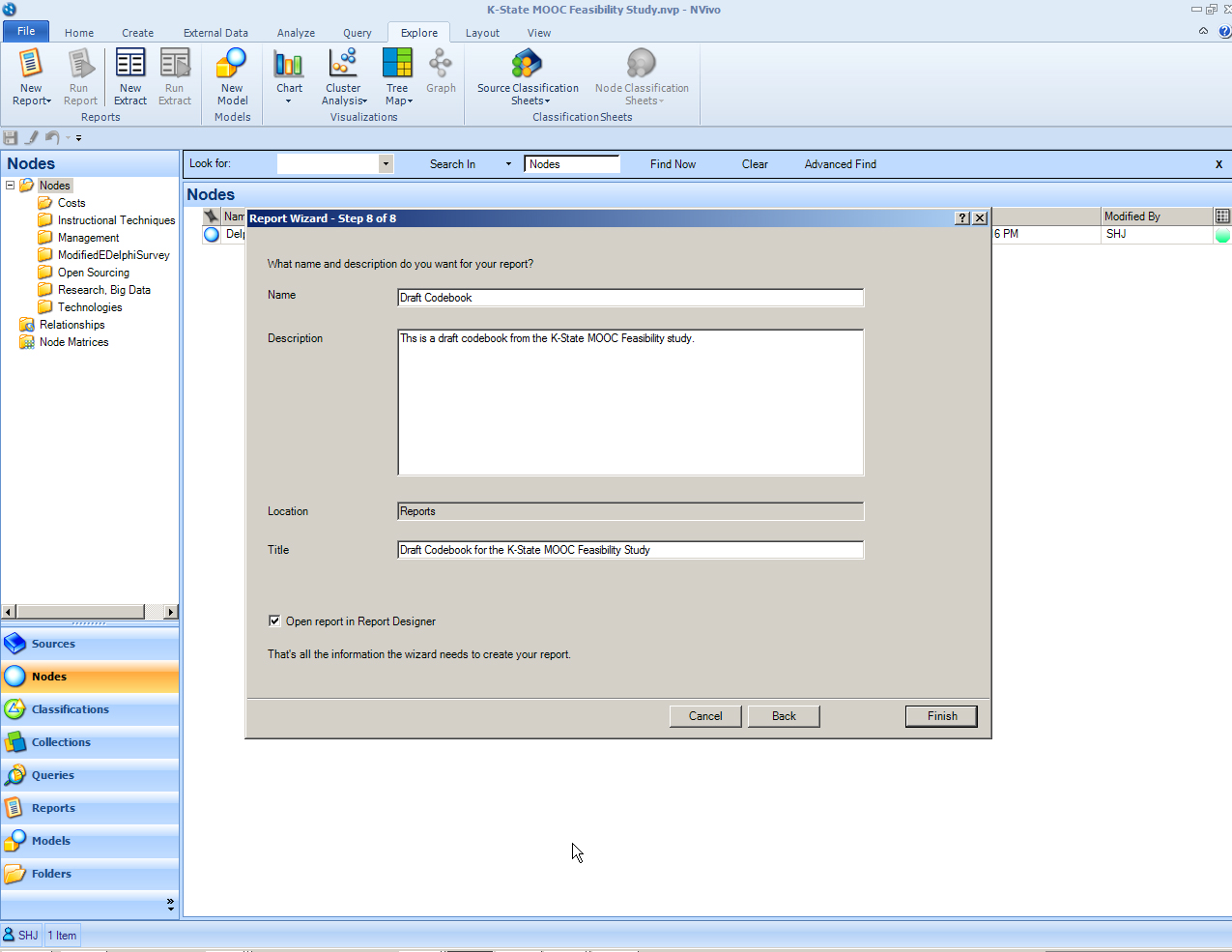{kind=link}
The following shows a screenshot of what a report might look like. This version has a lot of empty space though. (It may be a good idea to copy the text out into a text editor and re-import into a new Word file for improved layout processing.)
{kind=link}
The above sequence is one of many that may be followed to export different forms of codebooks.
Another codebook example may be done by creating a spatial layout view of the nodes through data visualizations--for visual interest and for information.
Explorations of Other "New Report" Extractions
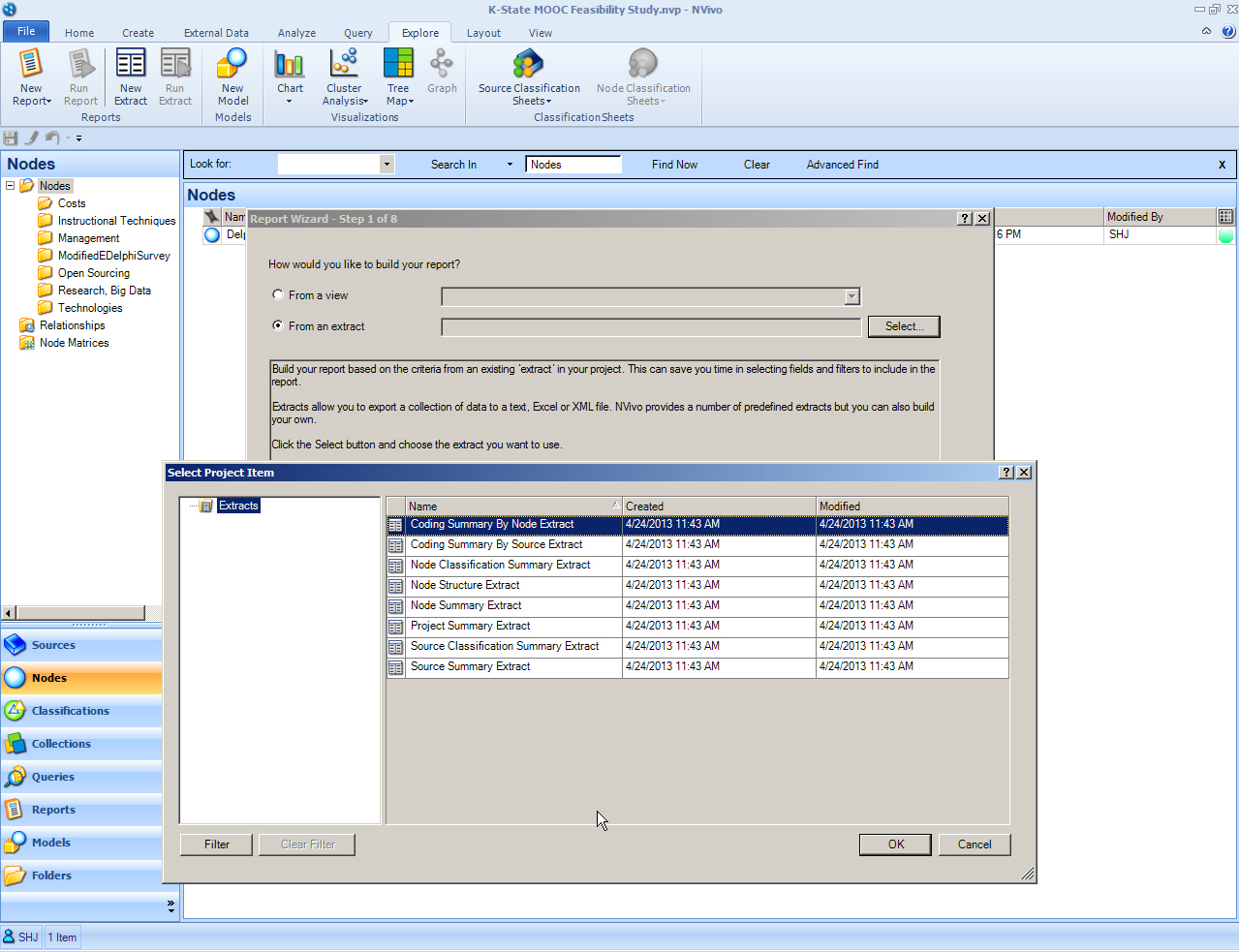{kind=link}
An "extract" seems to be a selected piece of data from select general information, fields, or filters (based on pre-sets).
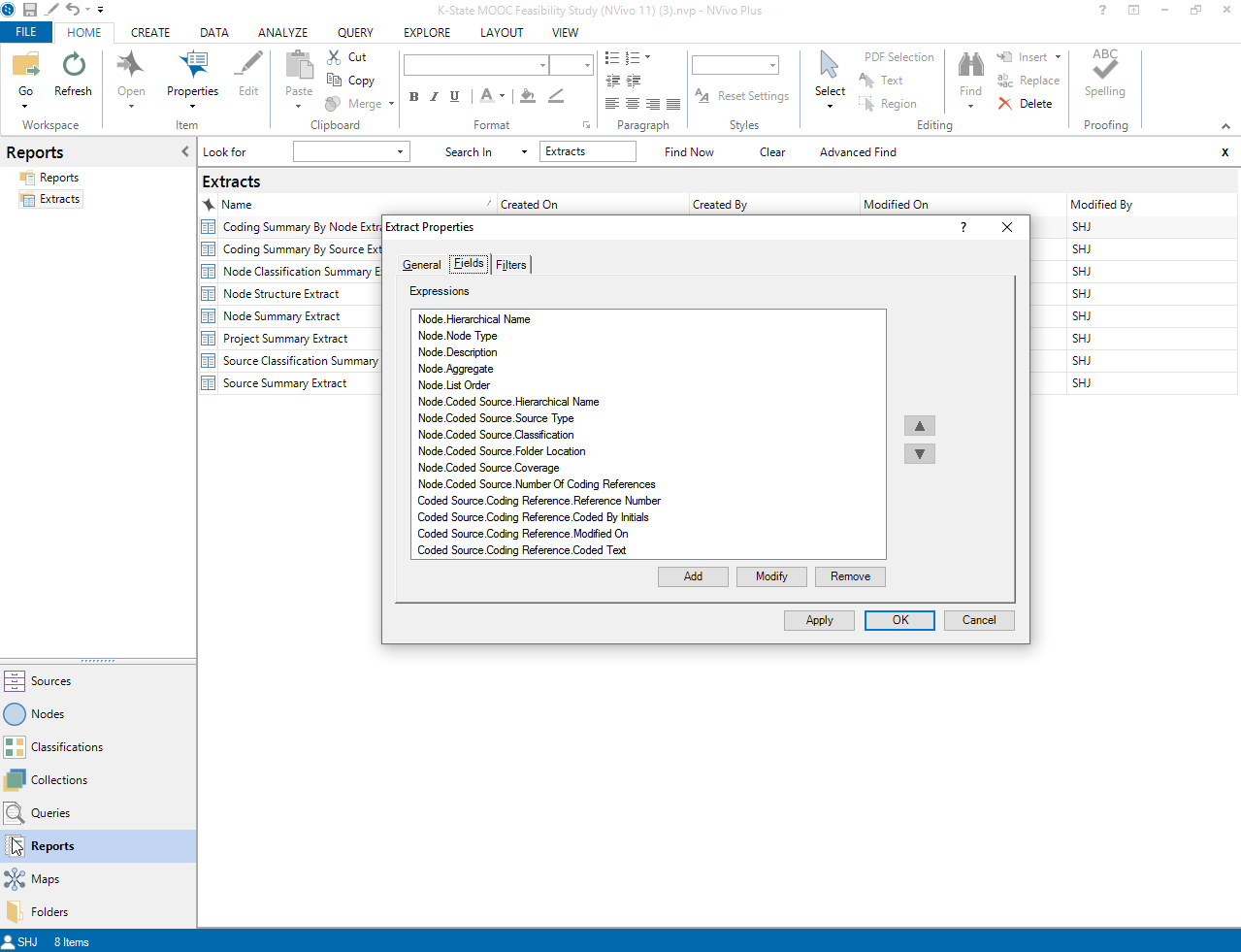{kind=link}
The above context assumes that the co-published article will include data in the Research Design / Methodologies and Appendices sections about the origination, operationalizing, refinement, revision, and finalization of the codebook. In the following brief sections, a few other considerations are added.
Super Fast Codebook Export in Latest NVivo
In the latest NVivo, a person may right-click on the code in the menu and export the highlighted part as its own codebook. If several parts are desired, a higher level section may be selected (or a folder) to capture all the coding within into a codebook.
Remember that the codebook does not come out in the order of the codebook in the project...but in alphabetical order...so some repositioning may be required to get it to look a different way.
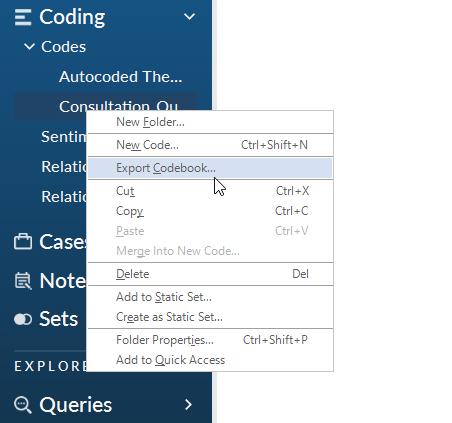{kind=link}
Release of Related Datasets?
In practice, codebooks (code lists) may be linked to particular data--from which that codebook was originated or refined or co-evolved. In those cases, the datasets are sometimes co-published with the release of the codebook. This release, though, assumes that the author has rights to the data (not so, if the articles and texts are under copyright ownership).
Stand-alone Codebooks
Codebooks are shared for multiple reasons:
- illuminating the linked research,
- enabling other researchers to use the codebook for data analytics (and research design),
- enabling other researchers to test the efficacy of the codebook,
- and others.
Depending on the purpose of the sharing, the codebooks may be shared within a research work, alongside a dataset, or in a stand-alone way. Stand-alone codebooks tend to include more information to enhance their applicability and usage. Stand-alone codebooks should contain critical elements which enable their proper usage and transfer to other research contexts. (Codebooks that are emergent or created from the underlying data should not "overfit" to that data but should be sufficiently general to be applied to other similar research contexts and similar data.)
Codebook history
Within the codebook, it is important to explain how the codebook was created. If certain published sources were used to inform the building of the codebook, those sources should be cited as well (within the narrative part of the codebook and within a related bibliographic listing).
Documentation of processes
It is important to describe how the codebook was arrived at and important decision junctures. Many modern codebooks are arrived at through a mix of BOTH manual and computational processes. The sequence of the codebook creation will be important to describe as well as data processing sequences (the codes extracted from data are sensitive to sequential and methodological processing). Also, it is important to know how the codebook was handled and processed to the final form and the decisions that were applied for its creation.
Codebook validation / invalidation
For codebooks that have been around a while, there will be a track record of usage and insights about (in)validation. That data may be helpful for those who may adopt the codebook (especially if there are other competitor codebooks available). How well did the codebook work for research design? For expression of a particular model or framework or theory? How well did the codebook work for particular data? For data analytics?
Related datasets?
Linked datasets may be shared, assuming that may be done without contravening copyright or intellectual property rights.
Examples of coded contents
Also, it may help to share some raw coded text within each code variable to further describe what goes into each code category.
Citation of the original codebook
In general, a shared codebook may be used by other researchers for their work as long as they cite the source. The general assumption, too, is that researchers may use part of the codebook only or the whole thing, depending on what the researcher is trying to achieve. Also, some researchers may build on the codebook by adding sections that apply to their own research contexts. Again, the assumption is that the citation will be given and the usage will be accurately described. Non-citation of the original codebook can result in accusations of plagiarism. Also, if there is a proper and preferred citation method for the codebook, that should be shared.
If there are extra restrictions to the re-use of the codebook, that should be noted.
Crediting
If the codebook's development was funded by an organization, it would be important for credit to be given to the funding sources.
Not for research reproducibility
Note that the uses of a codebook are not for direct reproducibility or repeatability (or for any sort of resulting idempotence)--because those approaches are not assumed in qualitative research; rather, codebooks may apply in multiple research situations that are aligned, but will usually be applied to different data by different researchers (with different ego-based subjectivities and backgrounds)...and so result in different insights.
Contact information for the codebook author.
If the codebook creator(s) wants to leave contact information within the codebook, that would be helpful so that others using this resource may contact him / her / them with insights, questions, and commentary.
Other Report Functionalities
Reports can also be used to output data on various types of queries, based on various combinations of coding, sourcing, and so on. This page only provides a particular "use case" in the research context.
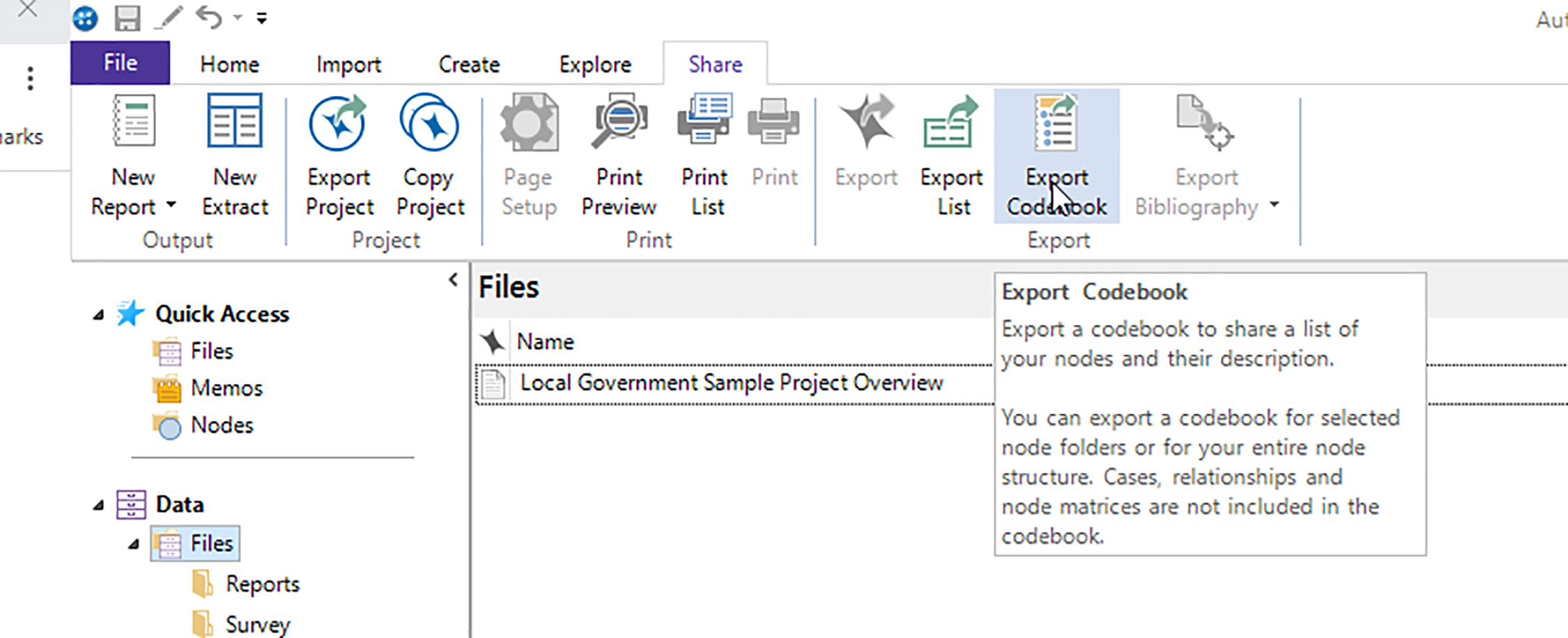
Exporting Codebooks through Share -> Export Codebook in NVivo
The Reports feature may be bypassed totally by using the new "Export Codebook" feature in the Share tab in NVivo
{kind=link}
This file comes out as a Word file.
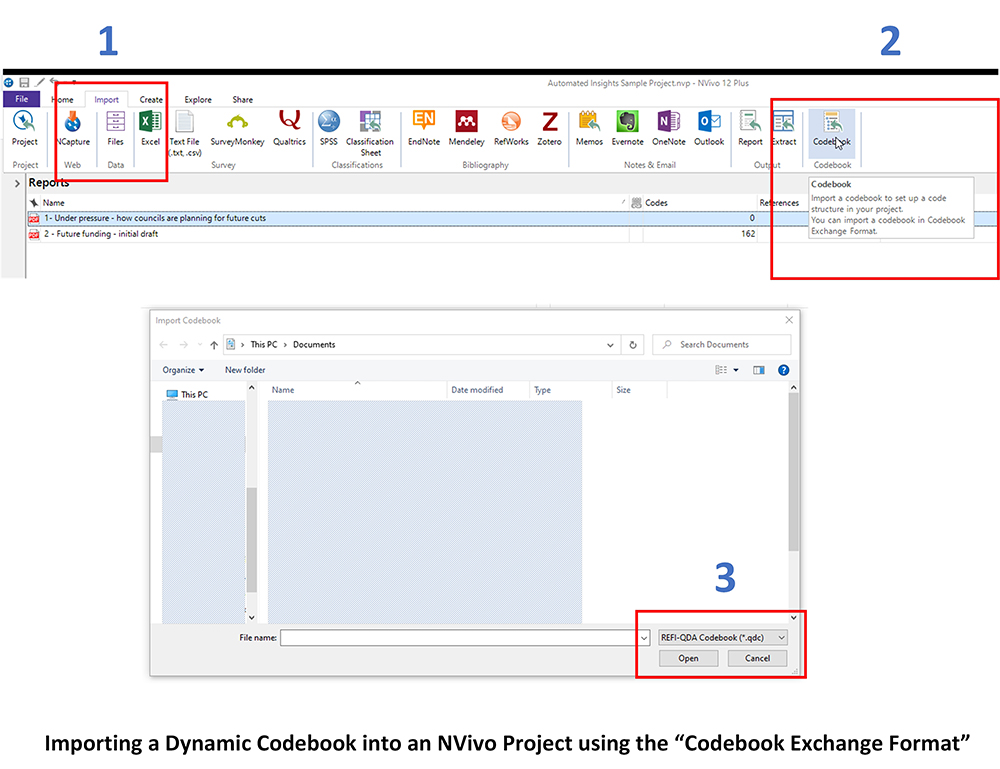
An Importable (Heritable) Codebook into another NVivo Project
But what if you want a codebook that can be imported into another .nvp or .nvpx project and used to code other data? In this case, you would want a .qdc format file to import. This file is in Codebook Exchange Format. To achieve this, go to Import tab -> Codebook area -> Codebook button, and select the .qdc file in the REFI-QDA Codebook format.
{kind=link}
To export such a dynamic codebook file to share, you would go to the Share tab -> Project area -> Export Project -> REFI-QDA... (Such files are eminently email-able and sharable in other ways.) "REFI" stands for "Rotterdam Exchange Format Initiative," and "QDA" stands for "Qualitative Data Analysis." The REFI standard enables interoperability between "Qualitative Data Analysis Software" (QDAs) and Computer-Assisted Qualitative Data Analysis Software (CAQDAS) programs. The .qdc file format type is in the Codebook Exchange Format.
The codebook does not include the coded data...but usually just the name of the coding category and a description to explain what data go into the respective categories.
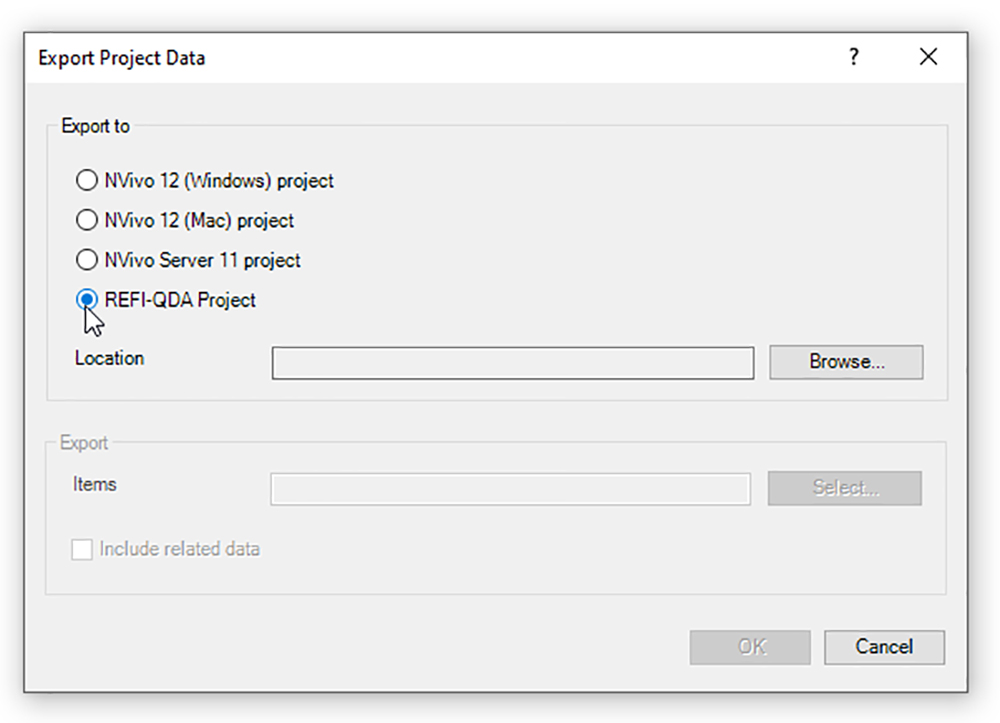{kind=link}
For all the excitement, though, the REFI-QDA is just the categories of the codes in alphabetical order and some directions about what goes into each coding category. The examples of code that go into each category are not part of the codebook.
| Previous page on path | Manual Coding in NVivo, page 2 of 3 | Next page on path |
Discussion of "Creating Codebooks in NVivo (through Reports...through Share)"
Add your voice to this discussion.
Checking your signed in status ...