Conducting Data Queries in NVivo
Once there has been a sufficient amount of information ingested into the NVivo project, researchers may want to explore the data using some of the features of NVivo. For example, the researcher may have achieved full saturation in terms of secondary sources for a literature review or a white paper. Or the researcher may have collected some initial groups of survey or focus group or interview responses—as either text data or a mix of quantitative and qualitative data. The researcher may have a set of field notes from some immersive research in a number of related locations. Any and all of this data are query-able.
Those who are using NVivo may choose to ingest data and code it and use that coding in a mostly manual way to extract meaning from the research and call that good. There is not a particular impetus to use further tools in NVivo for some researchers. However, for those who want to use more of the feature set in this tool and to extract insights that are not as readily achievable manually, there are some elegant data queries that may be used.
It helps to set some baseline understandings. The quality of the data analysis depends on multiple factors:
• the quality, provenance, and handling of the ingested data;
• the training of the researcher and research team; and
• the ability to use NVivo in a strategic way.
NVivo enables human-machine analysis of data. This sort of research is not a technologically deterministic one in which the computer software drives the work. The technology enables some features that would not be possible otherwise.
“Structured” data that is ingested would involve datasets from databases and spreadsheet programs. The “structuring” refers to the fact that the data is identified and labeled based on its location in a table or a dataset. Each informational cell then is identified information.
“Unstructured” data refers to information that contains miscellaneous mixes of information, without any pre-structuring of the information. A text corpus, for example, is unstructured data because it is only “a bag of words.” It does not have the placement of elements in different rows and columns. Human-readable structure (in text) is not machine-readable structure. Any structure extracted from texts and text corpuses is extracted based on the counting of semantic terms and phrases, word proximities, word frequency counts, and word networks. (NVivo enables some queries of such texts but not all.)
It may help to consider some examples. Quantitative data are often structured data. Geospatial data are structured data. This data may be captured from multiple-choice surveys, for example. Text-based responses from interviews, surveys, focus groups, and Delphi studies are examples of unstructured data. Extracted text datasets from social media platforms (through their respective application programming interfaces or APIs) contain both structured and unstructured data. Some extractions from online survey tools contain both structured and unstructured data.
Data processing can turn unstructured data into structured quantitative data…and this section will show how that process can work.
In the NVivo ribbon, go to the Query tab. Click it to see some of the various tools that may be used to query the data inside the project.
So what are some of the data queries that may be conducted in NVivo? To acquire an overview, see the information below.
Query Wizard
Those who are using NVivo may choose to ingest data and code it and use that coding in a mostly manual way to extract meaning from the research and call that good. There is not a particular impetus to use further tools in NVivo for some researchers. However, for those who want to use more of the feature set in this tool and to extract insights that are not as readily achievable manually, there are some elegant data queries that may be used.
Some Initial Understandings
It helps to set some baseline understandings. The quality of the data analysis depends on multiple factors:
• the quality, provenance, and handling of the ingested data;
• the training of the researcher and research team; and
• the ability to use NVivo in a strategic way.
NVivo enables human-machine analysis of data. This sort of research is not a technologically deterministic one in which the computer software drives the work. The technology enables some features that would not be possible otherwise.
“Structured” data that is ingested would involve datasets from databases and spreadsheet programs. The “structuring” refers to the fact that the data is identified and labeled based on its location in a table or a dataset. Each informational cell then is identified information.
“Unstructured” data refers to information that contains miscellaneous mixes of information, without any pre-structuring of the information. A text corpus, for example, is unstructured data because it is only “a bag of words.” It does not have the placement of elements in different rows and columns. Human-readable structure (in text) is not machine-readable structure. Any structure extracted from texts and text corpuses is extracted based on the counting of semantic terms and phrases, word proximities, word frequency counts, and word networks. (NVivo enables some queries of such texts but not all.)
It may help to consider some examples. Quantitative data are often structured data. Geospatial data are structured data. This data may be captured from multiple-choice surveys, for example. Text-based responses from interviews, surveys, focus groups, and Delphi studies are examples of unstructured data. Extracted text datasets from social media platforms (through their respective application programming interfaces or APIs) contain both structured and unstructured data. Some extractions from online survey tools contain both structured and unstructured data.
Data processing can turn unstructured data into structured quantitative data…and this section will show how that process can work.
Some Types of Data Queries
In the NVivo ribbon, go to the Query tab. Click it to see some of the various tools that may be used to query the data inside the project.
So what are some of the data queries that may be conducted in NVivo? To acquire an overview, see the information below.
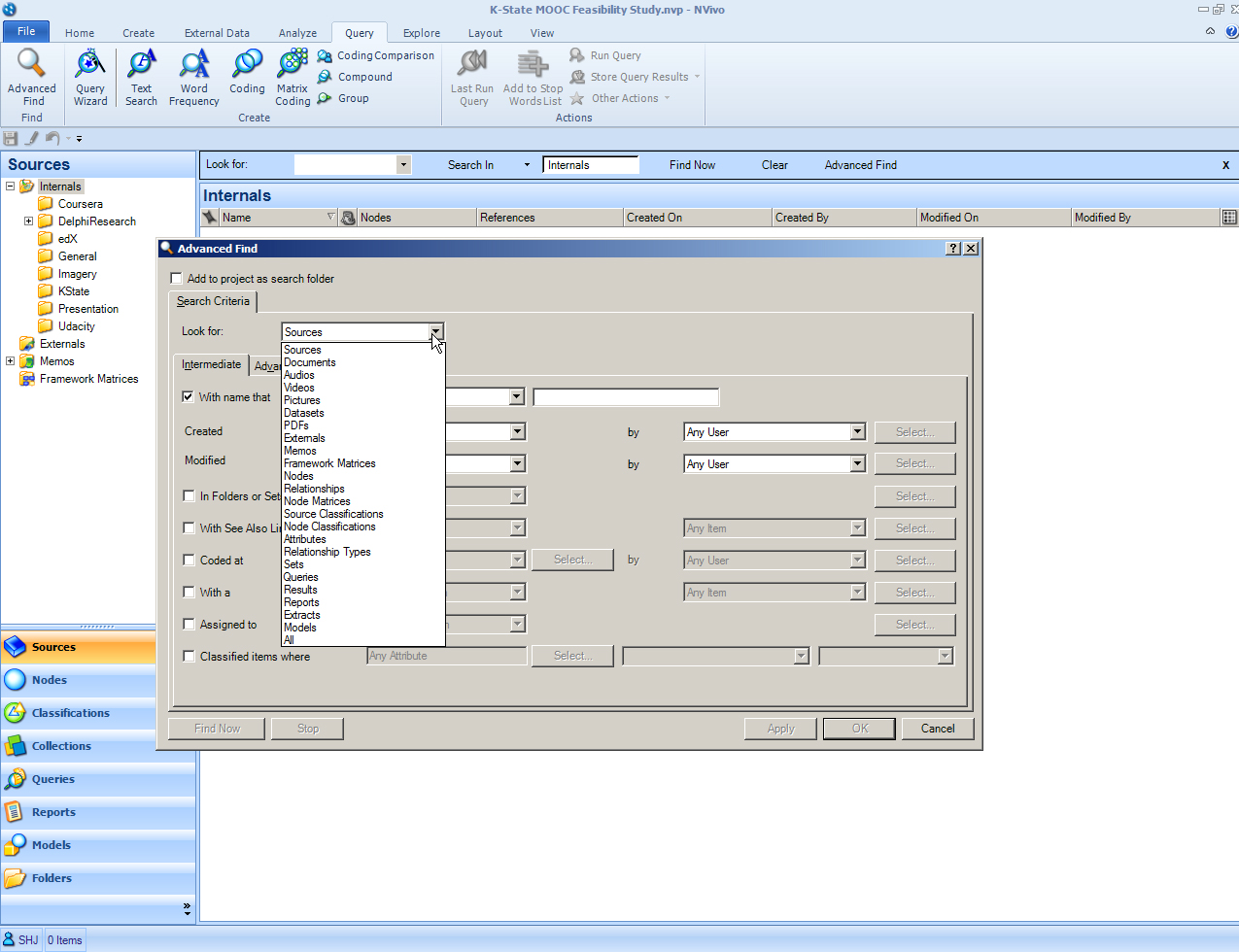
Advanced Find
{kind=link}
“Advanced Find” is a data query capability that enables a user to set various conditions and filters for finding particular information. This requires researcher intimacy with the data (which is generally advisable anyway for quality research), and it enables the calling up of select resources in the List View of the project.
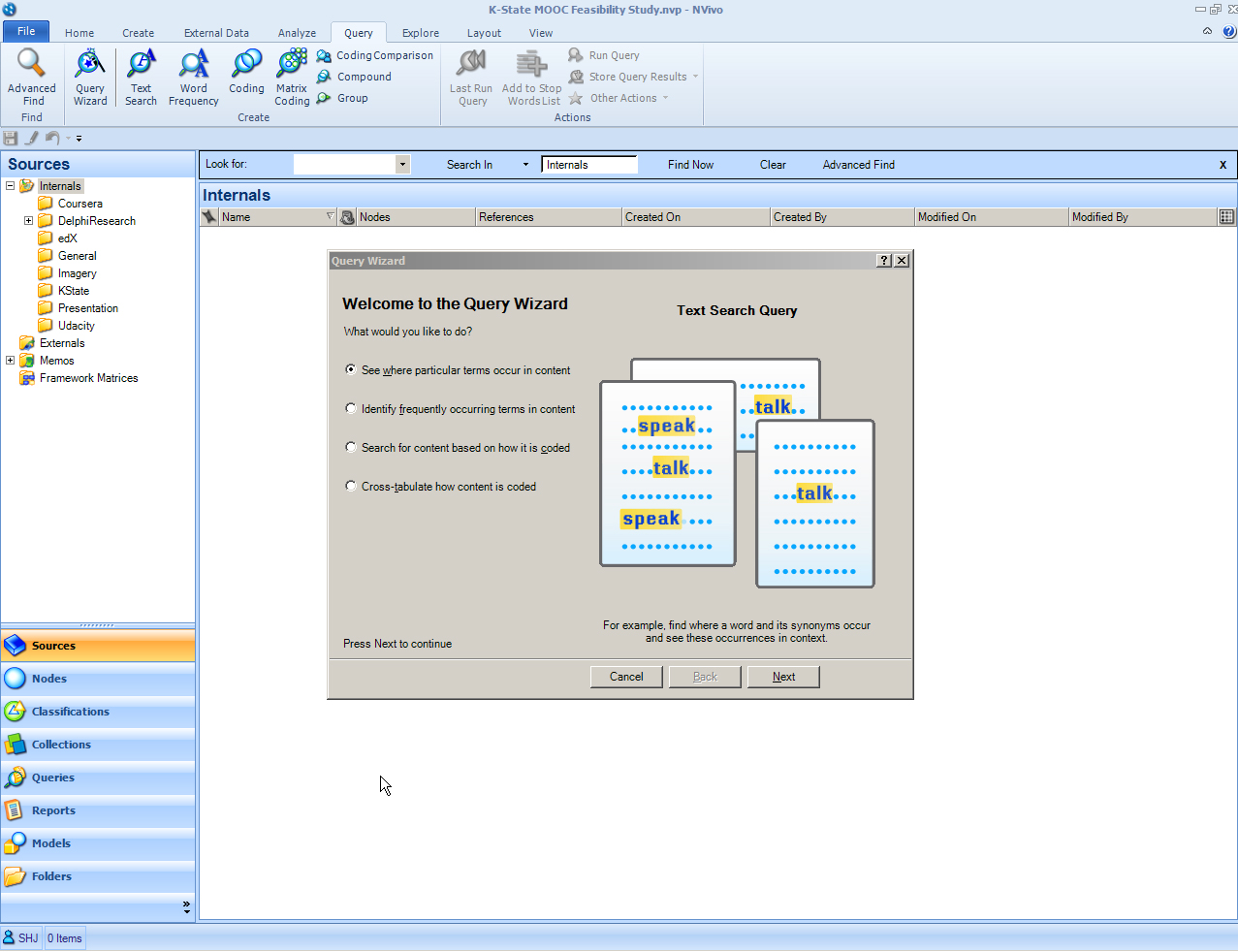
Query Wizard
{kind=link}
The “Query Wizard” enables the major text queries albeit in a step-by-step process and without the typical verbiage. The selections read:
• See where particular terms occur in context (word search and word tree)
• Identify frequently occurring terms in content (word frequency count)
• Search for content based on how it is coded (advanced search)
• Cross-tabulate how content is coded (matrix query)
This wizard will take a user through each of the necessary steps in defining the parameters of the particular data extraction.
What follows are some more direct queries.
Direct Data Queries
Text Search Query
{kind=link}
A basic text query enables researchers to find all instances of a particular word, phrase, concept, equation, or other data “string” anywhere in the project or in a particular part of the project (such as the sources, the nodes, single files, data sets, or other subsets of the data). A text query is used to track the occurrences of a particular concept (represented symbolically using symbolic language) and the contexts of those occurrences, through the research project or parts of the project.
This tool is helpful for a quick machine skim of massive amounts of secondary research to identify particular works which address concepts that the researcher may want to explore in more depth. It is helpful to understand the “gist” and “word sense” of a particular term and how it is used in the various contexts of a project. It is helpful to draw out meanings from Tweetstream datasets. These provide fast-identification of potentially relevant information.
All queries may be saved to a file (in the Queries space of the Navigation View). These may be re-run based on the same parameters especially after new information has been included.
Note that there is a Special button to the right of the text field in which the search may be define. A right click on that button results in a drop-down menu.
{kind=link}
“Special” text searches. To summarize the Special button briefly, each of the above features will be briefly addressed.
Wildcard searches. In a search, a “wildcard” is a character that stands in for a number of variations for any other characters that could appear in that spot or that sequence. Here, a “wildcard” feature enables the swapping out of any one character in a search, so that multiple versions of a word or word variations (with the “?” swapped out for a vowel, for example) may be searched for and identified with one search. A wildcard search indicated by an asterisk (*) may stand in for zero or more characters in that location. (Think of the “wildcard” as a placeholder.)
b?t: bit, bat, bot, bet, but
b*t: bit, bat, bot, bet, but, beat, Brit, boot, beaut, braut, beret, BLT, etc.
In NVivo, wildcard characters cannot be used as the first character of a string; further, it can only be used in single terms (words or equations), not phrases.
Boolean operators. There are also Boolean operators that may be applied to a text query search. The use of AND means that any source in the text search. The use of AND means that any source in the text search should have both or all of the search terms linked by the AND. The “AND” requires the two features in any of the sources found and delivered to the researcher.
In a search using the OR operator, any source identified has to have one or the other of the terms on either side of the OR. Of multiple words or phrases are listed without any operator indicated, the “OR” is assumed by NVivo. So any one occurrence of any of the words or phrases will be sufficient to call up a source in that text search query.
The NOT is used to add specificity and disambiguation. The way this is used is to have a first desirable search term with the NOT following and then a term that follows the NOT to indicate what is not desired. The idea is that the first and latter term may be somewhat close in meaning but that only the first term (and its meaning) is desirable to eliminate extraneous sources in the text search. The NOT serves to prohibit a particular string of data in the text search.
A “proximity” search enables the searching of sources in which two words are in proximity to each other. This is set up with two terms followed by a tilde and a number (“focus now”~10). The number indicates the largest proximity of words between the two selected terms. So if a researcher remembered the gist of a sentence and wanted to recover the source which contained that concept but couldn’t remember exact contiguous words, then this type of proximity search would be helpful. A two-word proximity search follows below.
{kind=link}
A “fuzzy” search is one in which NVivo conducts approximate string matching to search for both exact text searches but also similar ones based on known synonyms for the select terms. In this case, the sources pulled up (with select terms highlighted) will be for the specific terms and for synonymous or similar-meaninged ones (in terms of meanings or semantics). Also, there can be a kind of “pattern matching” for other searches possibly based on phrase structures and meanings.
Those who would prefer to use special characters in the text search criteria window may refer to the Other special characters table. Those who want direct information about special characters and operators may go to the direct link
These queries may be saved and run again later with the same settings later. (Find saved queries in the Queries folder of the Navigation View.)
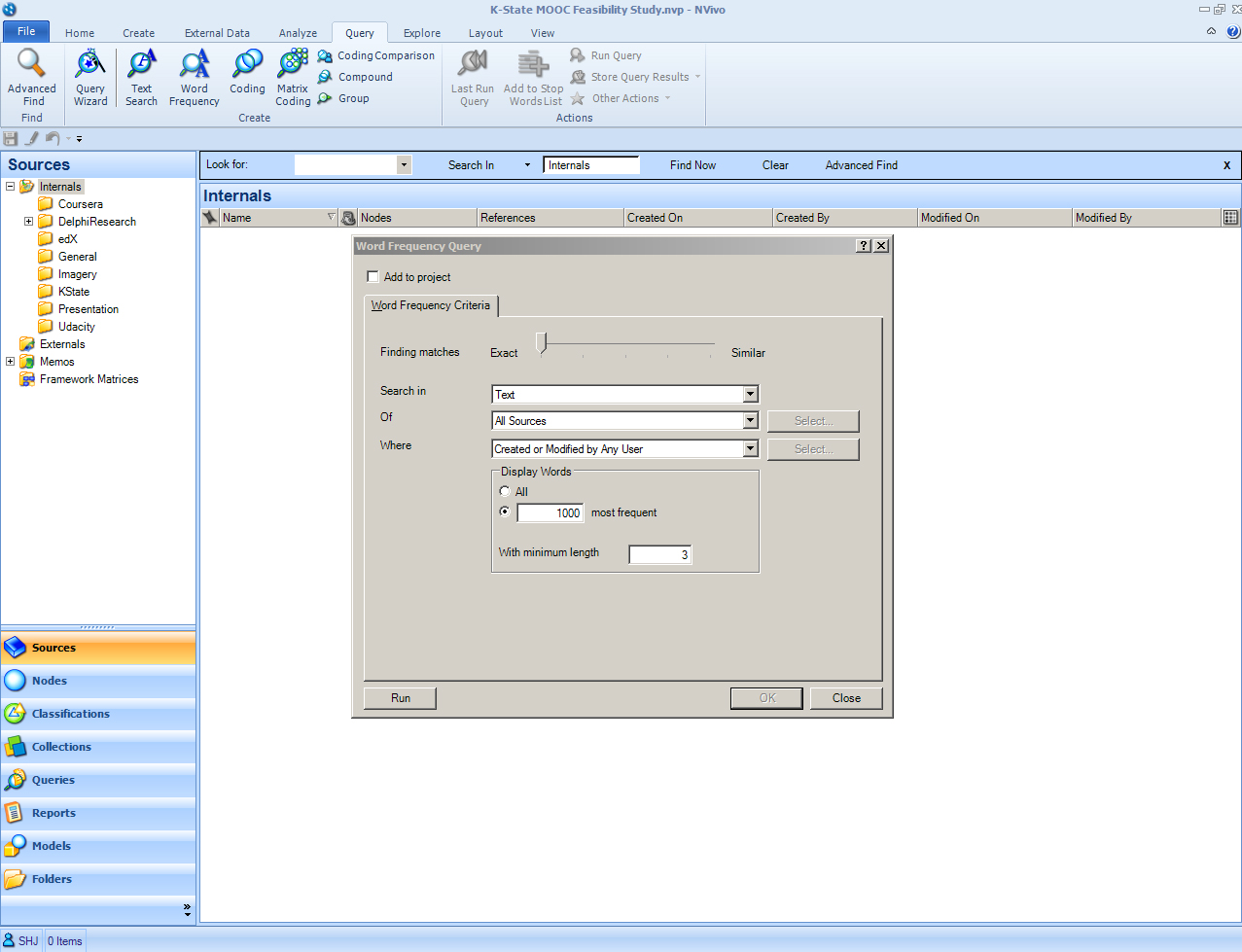
Word Frequency Count Query
A word frequency count provides researchers with an overall sense of the most common semantic-based words in a data set, document, text corpus, or research set (or some mix of the data). Users may decide whether to display all words or the 1000 most frequent or some subset of that. Words that are identified are usually at least 3 characters in length minimum. There is a built-in stop-words or delete-words list which disallows the inclusion of common syntax-based words. The user has to select what will be searched (Text, Annotations, or Text and Annotations). He or she has to define where the data should come from: All Sources, Selected Items, or Items in Selected Folders. The query may be limited to the items handled by a particular researcher (user). Once the desired parameters are set, click “Run” at the bottom left. The status or process bar at the bottom left will show the progress.
{kind=link}
When the run is completed, the summary data is shown as a table. The researcher may go through the list and add more words to the stop words list by right clicking on a particular word and clicking on “Add to Stop Words List”. Click OK. Or, a researcher may select a list of words to “stop” and click OK.
Once this is done, the text frequency query has to be re-run in order to apply the new stop words list to the data set. To achieve this, the researcher has to start again at the ribbon
{kind=link}
At this point, click “Run” again. The resulting table will be listed in descending order with the most popular words at the top and the least-used ones on the bottom. At the far right column is the weighted percentage in terms of numbers of occurrences of that word in the set.
Various data visualizations are available at the far right. The data may be turned into word clouds, tree maps, or cluster analyses.
{kind=link}
Coding Query
A basic coding query in an NVivo project involves analyzing the intersection between two variables such as between a node and another node, or a node and an attribute (such as some characteristic around which respondents are grouped). The output here involves a temporary document (unless saved) with the intersected extracted information.
Begin with the NVivo ribbon. In the Query tab, click on Coding. A window will open.
{kind=link}
The “Add to project” saves the scripting so that the parameters of this data extraction may be re-used (from a folder in the Queries space in the Navigation View). It is a good idea to name this clearly, so it’s clear where the data is being drawn from.
(Note: Make sure that the “Aggregate Coding from Child Nodes” is checked for the nodes so that even nodes with sub-nodes may be selected for coding queries—as well as matrix coding queries.)
{kind=link}
Go through the Coding Query window, and select the items that will be cross-referenced. If more complex coding queries are desired, go to the Advanced tab and list combined datasets (or multiple nodes). Click “Run” at the bottom left.
For this example, a coding query was run on a node focused on initial MOOC investments vs. a node focused on open-source contents and global access issues. That cross-reference resulted in 10 references.
To save this coding query, right click on the active pane and click Store Query Results in the dropdown menu. Select the location for the results. Name and describe the results.
The following is a video about how to conduct a coding query in NVivo 10 but with a focus on extracting responses based on attribute data.
Matrix Coding Query
Coding Comparison
Compound
Group
| Previous page on path | Cover, page 14 of 25 | Next page on path |
Discussion of "Conducting Data Queries in NVivo"
Add your voice to this discussion.
Checking your signed in status ...