Figure 3. Ngram of Da's stop words in English
1 media/stopwordsngram_thumb.png 2019-09-27T09:07:09-07:00 Brandon Kaminski 9970f233e3d6dfc7f3f47489507cdc60362d444a 34730 3 from Google Ngrams plain 2019-09-27T10:00:58-07:00 Brandon Kaminski 9970f233e3d6dfc7f3f47489507cdc60362d444aThis page is referenced by:
-
1
2019-09-26T18:45:56-07:00
Computational Literary Studies: The Next Phase of the Analysis of Culture
22
by Brandon Kaminski
plain
2019-09-27T10:16:58-07:00
INTRODUCTION
Attempting to understand the complexities of human culture is no easy feat. Thousands of years of literature define our species, from the great musings of Plato to the novels of Dickens. However, since the 1980s there has been a new field dedicated to this analysis of our culture, Digital Humanities (DH), which uses modern technology in order to continue the meta-research of previous humanities scholars. Online databases of searches, books, and manuscripts are now being analyzed through techniques of DH.
One subfield of DH is Computational Literary Studies (CLS), which primarily utilizes computational text parsing to make conclusions about literary texts. From the parsing, digital humanists have discovered more about styles, word choice, ideals, beliefs, and many other cultural aspects of humanity during the period of literature in question. Many studies have been performed on books all across human history.
THE DEBATE
CLS has been highly praised by some and highly contested by others. Nan Da, a professor of English at the University of Notre Dame, is a staunch critic. She believes that “quantitative visualization is intended to reduce complex data outputs to its essential characteristics [and that] CLS has no ability to capture literature’s complexity” (Da 634). In other words, the use of statistics based primarily on word count as a form of analysis does not account for human emotion, ambiguity, or context within the texts in question. Her article delves into some studies involving word frequency, and says that their results are not meaningful because it is entirely numerical (Da 602).
However, certain studies might show otherwise; many have been able to produce results that have provided new knowledge to their respective disciplines. One such study conducted by Alexander Barron et. al. used the CLS method of text parsing and word counts to study various speeches during the era around the French Revolution. They parsed speeches of French statesmen from many backgrounds both in the National Assembly and in committees. From the word usage data, they were able to define three major variables for the speeches: novelty (the newness of an idea as opposed to conservative preexisting ideas), transience (how short an idea would stay in people’s heads), and resonance (novelty minus transience: how long the newfound idea would last).
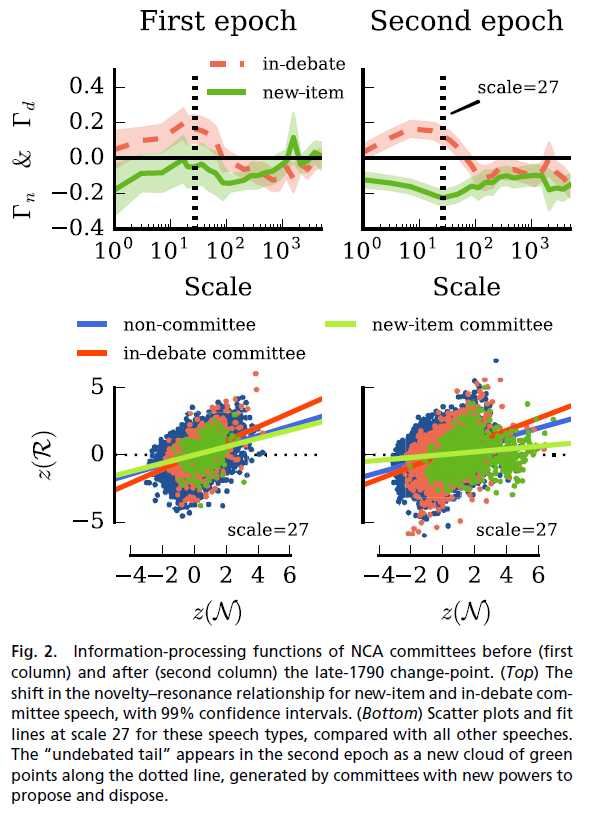
Their most important findings included that “high-novelty speakers are overwhelmingly associated with the left wing and the bourgeoisie, while all of our right-wing speakers, and the vast majority of nobility, are low novelty” (Barron 4609). In other words, new ideas (novelties) were more resonant with the French public, as shown in Figure 1. More importantly, their data showed an increase in resonance within the committees after 1790 (Figure 2, bottom graphs). The high novelty of radicalists and the increased presence of committees provide a well-vested reason for key developments in the revolution, most notably the downfall of the National Assembly and the rise of the Committee of Public Safety (Barron et. al. 4611).
CLS is a truly powerful “quantitative study of culture.”
THE POWER OF CLS
Da would instantly see these quantifiable values and group them together as one entity: “basic measurements and statistical representations of overlapping vocabulary” (Da 605). However, she incorrectly assumes that every single word will be present in the results and therefore throw off the data. Certain words of minimal cultural prevalence like “of” and “if” are what she calls “stop” words: “keep them and they produce the only statistical significance you have; remove them and you have no real results” (Da 623). Once again, she overlooks another key component: certain studies like Barron’s are not actively searching for these words. In fact, they studied the different vocabulary French conservatives, moderates, and liberals used and were able to produce groups of frequent words for each group of people. Different words have varying connotations, and Da’s stop words would not even have any significance on the net result of the speeches’ novelty or resonance in Barron’s study. Even by her standards, this study’s results would be considered valid.
Fig 3-4. Views of Da’s “stop words” in English and French. They take up a large percentage of both languages’ respective vocabularies. Removing them finds the patterns in lesser-used words, something that is prone to producing more significant results in studies like Barron’s.
Barron’s study was fabricated to include many different speeches from the same period in order to better discover its heteroglossia, which often included vocabulary being reused differently from statesman to statesman. According to the authors, “heteroglossia makes linguistics and rhetoric (the reception, influence, and propagation of language within a community) core components in the quantitative study of culture. Tracking changes in speech patterns within a social body allows us to examine cultural evolution: the circulation, selection, and differential propagation of speech patterns in the group as a whole” (Barron et al. 4608).Tracking changes in speech patterns within a social body allows us to examine cultural evolution: the circulation, selection, and differential propagation of speech patterns in the group as a whole..."
According to Da, CLS “is not artificial intelligence but humans working in summary statistics” (Da 638). Summary statistics is indeed a part of the CLS process; humans must collect test data as well as understand the results that the computer calculates. What she fails to realize is that through these human statistics, the computer can apply them at a much larger scale. Traditional literary analysis might be strong when analyzing individuals, but how would it fare in the context of every individual that comprises a culture? Barron raises the point that the digitization of historical archives presents a fundamentally new way to answer these big-picture-oriented questions (Barron 4607), and he is exactly right. Traditional analysis would never be able to successfully describe an intellectual corpus that large, nor that many of its core aspects, in nearly the time that CLS methods can due to the technology being so new and efficient. For this, CLS is a truly powerful “quantitative study of culture.”
CONCLUSION
Even though the field is up-and-coming, Computational Literary Studies has already shown promise. The ability to analyze so much literature at once has provided us with new knowledge that would have been previously unattainable. Although this study of culture may be “quantitative” and critical academics like Da may believe it loses the human touch, it combines each person’s touch in order to create a better understanding of a culture as a whole in a given time period, as shown in Barron et. al.’s study on speeches of the French Revolution. I believe that this technology can only improve; soon, the human race will be able to construct the best view yet of our diverse history.
BIBLIOGRAPHY
Barron, Alexander, Jenny Huang, Rebecca L. Spang, and Simon DeDeo. “Individuals, institutions, and innovation in the debates of the French Revolution.” Proceedings of the National Academy of Sciences of the United States of America, vol. 115, no. 18, 2017, pp. 4607-4612. https://doi.org/10.1073/pnas.1717729115
Da, Nam. “The Computational Case against Computational Literary Studies.” Critical Inquiry, vol. 45, no. 3, 2019, pp. 601-639. https://www.journals.uchicago.edu/doi/full/10.1086/702594
{kind=link}
{kind=link}
{kind=link}
{kind=link}
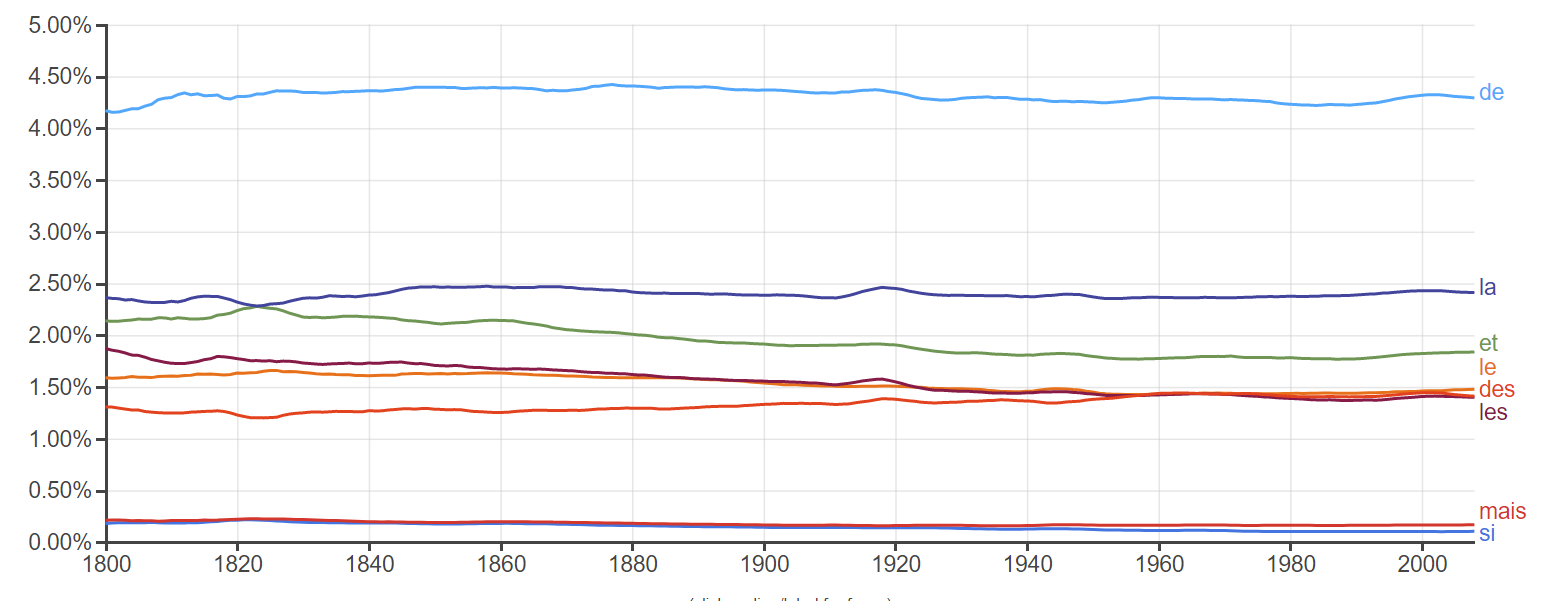{kind=link}