The Detriments of Computational Literary Studies
Digital Humanities is a complex, growing field that pertains to the use of digital texts, social media posts, and citable sources in traditional english literary studies. While it is considered to be a newer field, Digital Humanities has actually been around since the turn of the century and as a result has grown to contain other smaller subdivisions including Computational Literary Studies (CLS). CLS is defined by Nan Z. Da, author of “The Computational Case Against Computational Literary Studies,” as the “the statistical representation of patterns discovered in text mining fitted to currently existing knowledge about literature, literary history, and textual production” (602). This definition is informative of the scope of CLS, but the argument that follows is overwhelmingly controversial. Multiple scholars, including Da, are critical of how CLS has decreased the need for accountability and has diminished classical interpretations of texts which are undermined by digitization. Many highlight that CLS diminished the methodology and insights incorporated in traditional literary studies. However, academic studies, along with various social media platforms, have shown how Digital Humanities has grown to be applicable to many modern day literary studies. In this essay, I will prove that, while there are benefits, Digital Humanities has a detrimental societal impact because of the way it prevents society from being able to fully interpret and understand texts when they are digitized because it puts a distance between the source and the reader.
“academic professionals wield the label ‘digital humanities’ instrumentally amid an increasingly monstrous institutional terrain defined by declining public support for higher education," (Kirschenbaum 59)
Many scholars believe that the growing CLS field can have a negative impact on society as it grows in a reckless, careless manner. In Da’s article, she criticizes Digital Humanities and the way it puts literary texts through computer analysis to count word frequencies rather than helping readers understand the intricacies of the texts. Da primarily states that CLS is a facade of qualitative data in her claim: “The first are papers that present a statistical no-result finding as a finding; the second are papers that draw conclusions from its findings that are wrong” (607). By categorizing the two types of CLS papers, she takes a bold stance about the results of CLS by undermining the progress made in the field to revolutionize Digital Humanities and, thus, enhance the humanities as a whole. She insinuates that the basis of CLS data is false because there are no-results from the studies. Additionally, Da is suggesting that the conclusions of these studies are usually incorrect because the difficulty involved with using online sources leads to false findings. Similar negative impacts are highlighted in Matthew Kirschenbaum’s article “What is Digital Humanities and What’s it Doing In English Departments?” For example, there are multiple examples of ways in which CLS has proven detrimental to budding scholars as it allows academics to “wield the label ‘digital humanities’ instrumentally amid an increasingly monstrous institutional terrain defined by declining public support for higher education,” (59). According to Kirschenbaum, Digital Humanities as a whole has caused a decline in the support of higher education because of the ways it detracts from the importance it carried in the past. Furthermore, it echoes Da’s sentiments that Digital Humanities has become a scapegoat for scholars attempting to dodge searching for concrete evidence and, thus, it minimizes the importance of traditional academics.
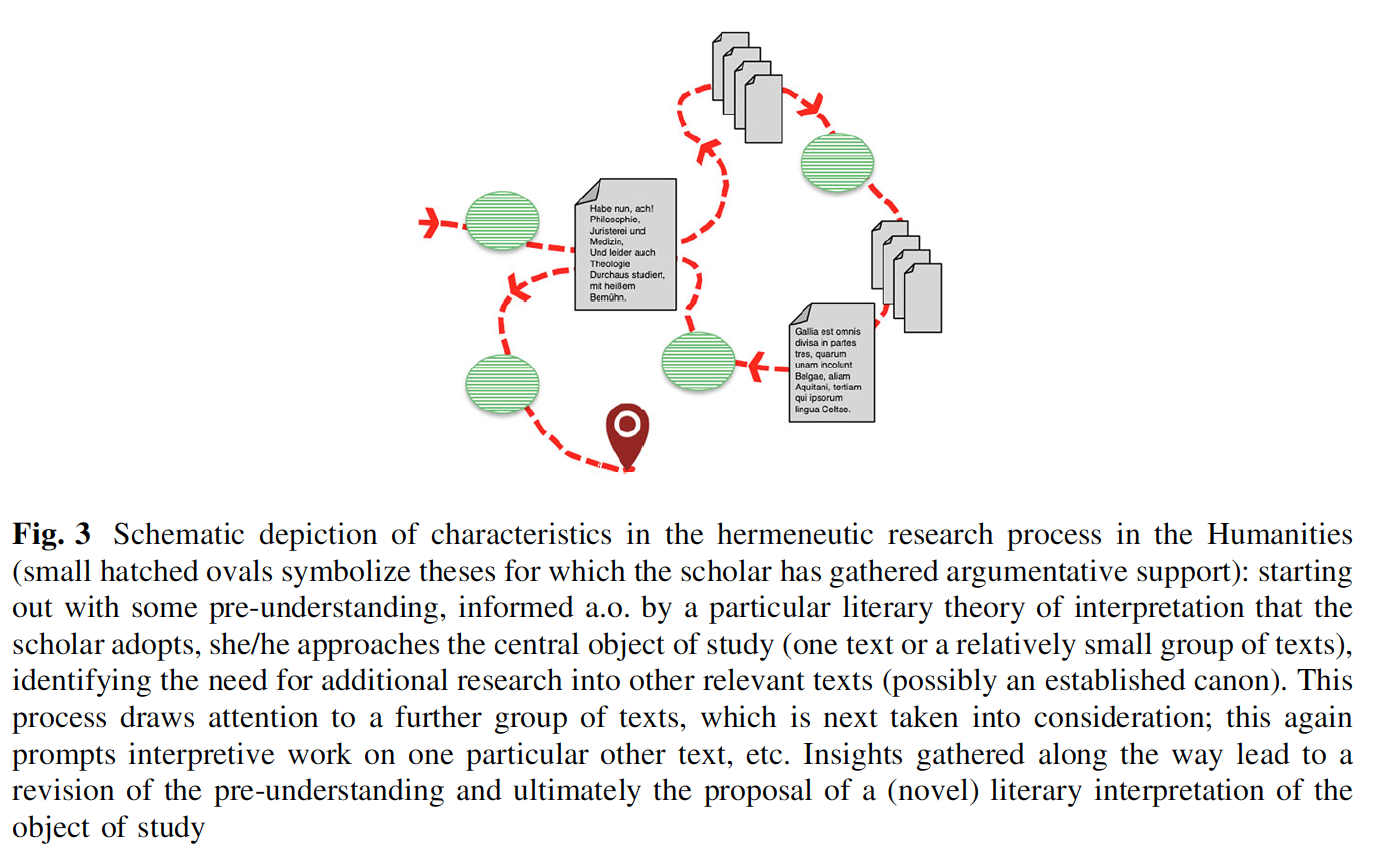
There are large arguments that the quality of texts that are delivered through technology is worsened due to underlying intentions of data mining, which takes away from conventional interpretations of texts. Kirschenbaum quickly debates the positive aspects of computer-based reading devices by saying: “Finally, today, we see the simultaneous explosion of interest in...large-scale text digitization projects, the most significant of course being Google Books, with scholars like Franco Moretti taking up data mining and visualization to perform ‘distance readings’ of hundreds, thousands, or even millions of books at a time” (60). It is possible that the booming e-reading industry is targeted more to benefit large corporations without any regard for how it diminishes classic texts. The digitalization of texts encourages the concept of “distance readings,” which entails sources being read at the surface level and then being passed on. This process diminishes the significance of classics or intensely researched texts, and it occurs because of the plentiful and accessible nature of the different texts. It is increasingly apparent that the influx of information also makes it harder for students and teachers alike to remedy the scheduling dilemma described by Jonas Kuhn in his article “Computational text analysis within the Humanities: How to combine working practices from the contributing fields?”. This dilemma describes the conflict between the determination of which computational modeling components to implement and the location in which to place them within the programs. Kuhn’s dilemma is closely related to the “distant reading” concept that Kirschenbaum discusses, as well as Da’s idea that CLS leads to the disregard of deeper, academic meanings of literary texts (Kuhn 17). Furthermore, Da argues that CLS in general is an extremely basic reading of sources and fails to grasp important themes, which leads texts to lose significance with each version. Da writes, “CLS’s processing and visualization of data are not interpretations and readings in their own right... In CLS data work there are decisions made about which words or punctuations to count and decisions made about how to represent those counts. That is all” (606). The claim is that CLS only pertains to the word count and data behind the text, which, in turn, devalues the underlying meaning of the text and how traditional literary studies place significance on them. This relates to a lesser understanding of texts commonly to understand certain aspects of life through social themes and other means, which draws away from deeper literary meanings and, thus, taints traditional literary studies. The use of CLS is a way of distancing oneself from the texts rather than further investigating the deeper meaning of them and the ways in which they are studied in a traditional setting because the understanding and investigation is surface-level.
{kind=link}
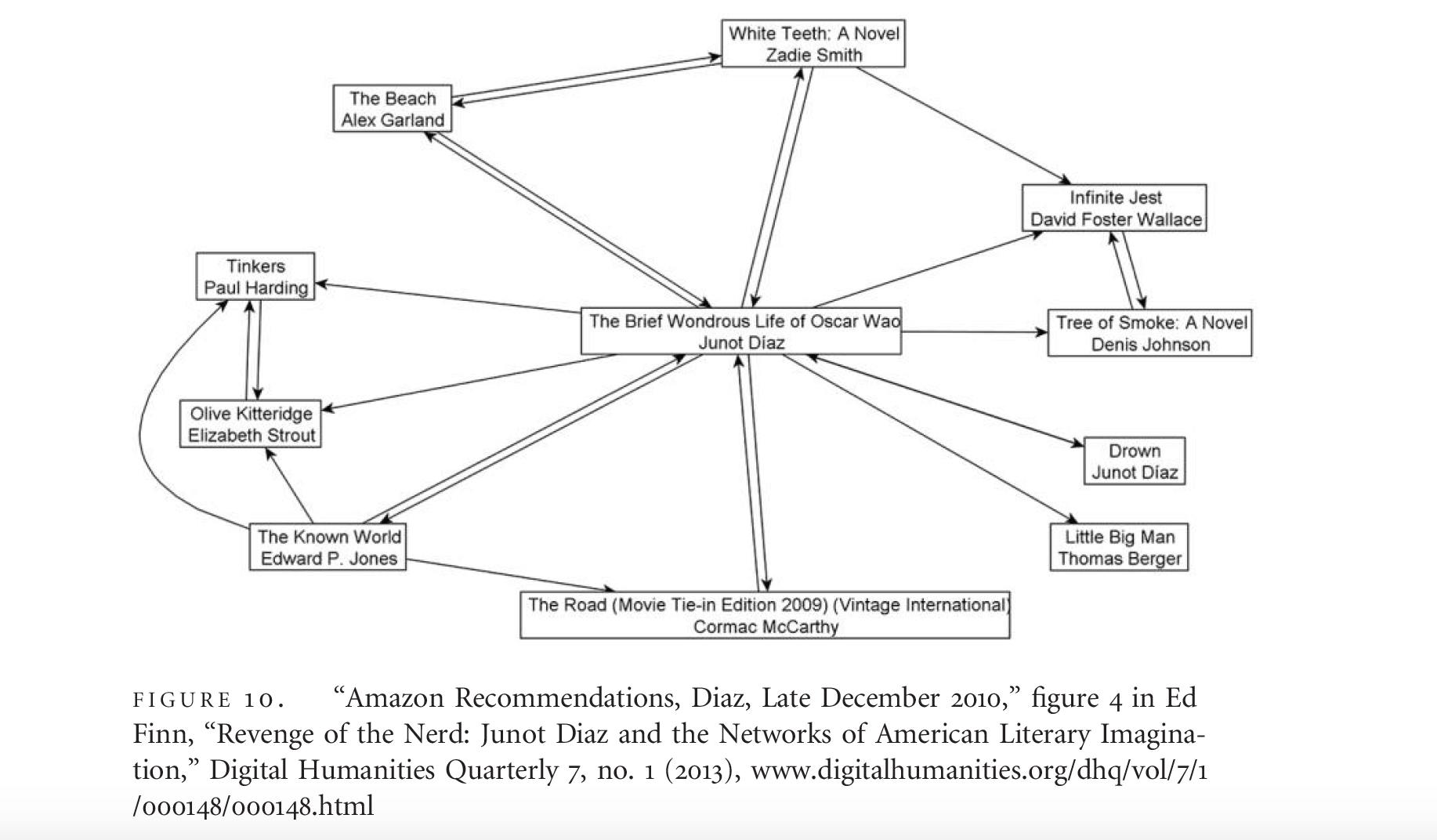
Lastly, there is a growing issue about the way in which the culture surrounding different social media platforms has created a rift in the accountability of sources, as well as the integrity of these posts. First, Da mentions the network mapping behind many websites by stating that “CLS network analysis can easily become recommender-system literary sociology, in which consumer and discursive associations are visualized without regard to the tone, context, emphasis, rhetoric, and so on” (630). This idea relates to Google, Facebook, and various other sources alike. It highlights to concepts of how CLS is a creation of a network that takes in data without being able to comprehend the context behind it and thus the results are only vaguely connected to our searches. Programs will create these recommender-systems through network analysis, which poses a security threat and enables a consumer culture to boom as targeted ads take away from traditional investigative processes of literature. Kirschenbaum comments on Twitter’s impacts specifically: “Twitter...has inscribed the digital humanities as a network topology, that is to say, lines drawn by aggregates of affinities, formally and functionally manifest in who follows whom, who friends whom, who tweets whom, and who links to what” (59). There is a way with Twitter to track back with the linkage of posts and thus an anticipated path to authenticate sources, but in reality there due to one-sided following, the process of authentication is much more difficult. Additionally even within an original tweet it is impossible to know whether that is original, reliable content or not. Due to the now prominent field of social media, professionals and academics alike are becoming frustrated and anxious over blogs and tweets because, as mentioned earlier, they are perceived as a threat to higher education as a whole (Kirschenbaum 60).
While there seem to be benefits to certain aspects of Digital Humanities in the ways that it allows for quick spreading of information and easy access to sources, there are extreme negatives. First of all, since CLS does not usually produce reliable data, when current articles are cited in future academic journals it will be riddled with falsehoods. As a result, this will create a new, lower standard for future research projects. Additionally, CLS has decreased the desire for higher education because social media outlets have created a new culture that has made it to a point where citing and confirming sources are no longer deemed necessary. The negative outcomes of the digitalization of texts and the growing social media culture are rolling over to change the social structure of our society in which education is highly prioritized. Overall, CLS is growing and the benefits are clear, but there is a need for a higher standard of accountability as well as an increased need for the recognition of the traditional interpretation of texts that cannot be determined by a computer alone.
{kind=link}
Works Cited
Da, Nam. “The Computational Case against Computational Literary
Studies.” University of Chicago Press, Critical Inquiry 45, no. 3, 2019, doi:https://doi.org/10.1086/702594.
Kuhn, Jonas. “Computational Text Analysis within the Humanities: How to Combine Working
Practices from the Contributing Fields?” Language Resources and Evaluation, June 2019, pp. 1–38, doi:https://doi.org/10.1007/s10579-019-09459-3.
Kirschenbaum, Matthew G. “What is Digital Humanities, and What’s It Doing in English Departments?”
ADE Bulletin, no. 150, 2010, pp. 55-61. August 30, 2019. 10.1632/ade.150.55