The Significance of Computational Literary Studies
Computational Literary Studies (CLS) is a branch of Digital Humanities that yields quantitative data via the use of computer programs that perform analysis of numerous literary texts. There has been controversy about the quality of the analysis and arguments made through the use of CLS because of the quantitative methods that scholars such as Nan Da claim do not take into account context, syntax or semantics of the literary texts. Docuscope, a text tagging device, has analyzed texts such as numerous Shakespear plays and British novels from the 19th century. The findings made by Docuscope prove to be significant to the field of digital humanities. Computational Literary Studies have amassed controversy based on their ability to produce analysis and arguments about literary texts; however, supporting the research studies possible via CLS is crucial because of the efficiency in which they produce valuable analysis of literary texts.
{kind=link}
In the pamphlet “Quantitative Formalism: An Experiment” by Sarah Allison, Ryan Heuser, Matthews Jockers, Franco Moretti and Micheal Witmore, a group of scholars conducted an experiment in which they test if a program called Docuscope would be able to recognize literary genres based on text analysis. The program used to conduct this experiment was Docuscope, which is a text tagging device containing over several millions of words that are categorized into linguistic categories. Docuscope is able to recognize words and word strings in order to categorize a text into a rhetorical category. According to Allison:
“Using just 44 word and punctuation features – which we eventually ended up calling Most Frequent Words, or MFW – Jockers was able to classify the novels in the corpus as well as Witmore had done with Docuscope”(pg7).
The discovery at the end of the experiment is that although the program was able to recognize literary genres, the scholars also learned that “Statistical findings,” said Heuser, made us realize that genres are icebergs: with a visible portion floating above the water, and a much larger part hidden below, and extending to unknown depths”. There is still much untapped knowledge about genres that the scholars will pursue to learn about via CLS.
I believe this article by Sarah Allison et al. (2011) will be helpful to my research because it provides a complete experiment that shows the success of computational literary studies. It also alludes to the untapped potential of the field that has not yet been studied. The use of CLS in the field of digital humanities is a key component in generating new analysis and understanding of an immense library of literary texts. Realizing that there is still much information to be discovered about genres can lead to new experiments involving CLS. The article is effective as a source because it provides evidence that CLS can categorize text via word patterns and strings. Allison claims that “...locative prepositions, articles and verbs in the past tense are bound to follow. They are the effects of the chosen narrative structure. And, yes, once Docuscope and MFW foreground them, making us fully aware of their presence, our knowledge is analytically enriched: we “see” the space of the gothic, or the link between action verbs and objects (highlighted by the frequency of articles), with much greater clarity”(pg26). It also sheds a positive light on the potential of CLS’s ability to categorize and analyze literary texts.
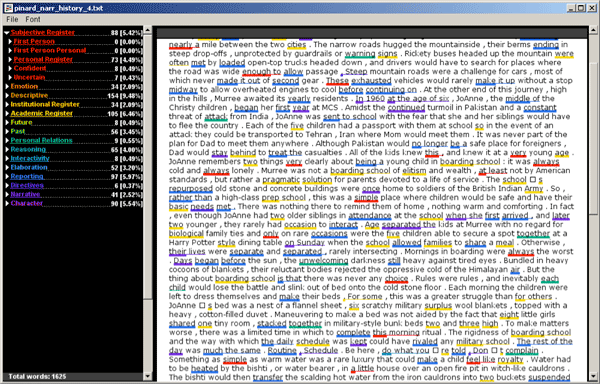
In the article “The Computational Case against Computational Literary Studies” by Nan Da, there is an argument formulated against the ability of Computational literary studies(CLS) to produce significant analysis literary texts due to conceptual flaws within it. The stance taken by Da is that the use of CLS is not reliable enough to form meaningful analysis about literary texts. She defines CLS as
“Another suitable definition of computational literary studies (CLS) is the statistical representation of patterns discovered in text mining fitted to currently existing knowledge about literature, literary history, and textual production” (pg 602).
Various statistics and charts are used as evidence to either support Da’s claims or to disprove the claims of other scholars using CLS to make claims. Da claims that “Computational literary criticism is prone to fallacious overclaims or misinterpretations of statistical results because it often places itself in a position of making claims based purely on word frequencies without regard to position, syntax, context, and semantics”(pg611). She analyzes specific examples of scholars collect data from an experiment but failing to take context into account which ends up in a misrepresented analysis. Da mentions this by “Anyone who has read Confessions knows that the last three chapters differ from the first ten because Augustine turns to discussions of Genesis after spending ten chapters on autobiography, and so of course different words will start to show up”(pg612). She also mentions the works of other scholars in the field and goes as far as to claim that some of their charts to be wrong and taking the opportunity to make her own charts. A bold claim made by Da is “Looking for, obtaining copyrights to, scraping, and drastically paring down “the great unread” into statistically manageable bundles, and testing the power of the model with alternative scenarios, takes nearly as much, if not far more, time and arbitrariness (and with much higher chance of meaninglessness and error) than actually reading them”(pg638) which she fails to back up with evidence. The claim that humans could keep up with the pace of computational methods in analyzing literary texts is false and irresponsible. Da is critical of CLS, as she believes that “CLS has no ability to capture literature’s complexity” (pg 634) and expresses disagreement with its use in analyzing literature.
I believe Da’s article will be a useful source for my research because it provides an opposing view on CLS. Although some of her arguments and claims may be biased, the ideas provided in the article are some that should be taken into consideration when looking into what extent CLS can be used to analyze literary texts. It is fundamental to look at all sides of a conversation in order to understand it as a whole. An article like Nam Da’s is crucial when understanding the conversation and current stance of CLS in the realm of digital humanities.
In closing, although some scholars may emphasize the potential faults and doubts of the results produced through CLS, there is much untapped potential of CLS to be discovered. Currently, there have been successful experiments involving CLS that prove the efficiency of methods such as text analysis. As one of the basic components of CLS, text analysis produces significant quantitative data. In order to inch closer to achieving the analysis of the vast library of literary texts at our disposal, it is essential we use computational methods in order to increase efficiency and working pace. Quantitative data produced via CLS is essential to new discoveries in the field of digital humanities.
Citations
Allison Sarah, Heuser Ryan, Jockers Matthews, Moretti Franco and Witmore Micheal. “Quantitative Formalism: An Experiment.” Stanford Literary Lab, Pamphlet 1, January 15, 2011, https://litlab.stanford.edu/LiteraryLabPamphlet1.pdf.
Da, Nan. “The Computational Case against Computational Literary Studies”. Critical Inquiry. Vol 45, Issue 3, The University of Chicago Press, 2019.