Distant Reading
https://docs.google.com/presentation/d/1mJzBxlrMrKDaN677AHyKph4IyYwl0P5-lCsTYJIZX_U/edit?usp=sharing
Too many words? Not enough time? Make your computer solve your problems for you.
Nearly every consideration of computerized text analysis begins the same way, so I’ll stay true to form:
We’re overwhelmed with text in this digital age. There’s simply too much of it — too much to read, too much to skim, certainly too much to make sense of. Google processes 20 petabytes of data per day, which in text terms is equivalent to 40% of all human-written works, ever [1]. The average Internet-using person encounters so much text even just in the form of privacy policies that if we read all the software agreements we sign with a click each year, it would take 76 full work days [2] .
Given the universality and reach of this problem, perhaps it is not surprising that researchers from all over the university, from biology to linguistics to history to business to computer science, have been attracted to computerized text analysis tools.
Text analysis drives natural language processing advances that make tools such as Siri and Alexa possible. Businesses mine the web using sentiment analysis tools to understand how their products are being received. Social media data has been mined for trends in influenza [3], adverse drug reactions [4], and e-cigarettes’ role in smoking cessation [5] .
Outside of academia, social media mining has proven more insidious. Police forces worldwide mine social media to monitor and quash protests, during the revolution in Egypt in 2011 [6], a terminated “Jasmine Revolution” protest in China [7], and the Quebec student strike in 2012 [8]. The ACLU maintains thousands of pages of documentation of police departments deploying forces based on monitoring of hashtags including #BlackLivesMatter, #DontShoot, and #PoliceBrutality.
For humanists, of course, the massive influx of and access to digital text presents particular opportunities — perhaps most visibly and popularly in the form of distant reading, finding trends in text as data and the metadata of text production that help us understand large quantities of fiction.
Agenda of This Workshop
This workshop will introduce you to some of those researchers’ approaches, with a particular focus on how digital humanists have approached text analysis. We’ll discuss how we might use — and analyze and interpret and futurize and hypothesize, because hermeneutics are our strongest domain — the methods of text analysis available to us.
Ultimately, you will select a corpus of words to analyze using one of the tools we discuss. You will begin with a data-exploration tool and come up with research questions that you might be able to answer with a more complex or bespoke tool. You'll pick a visualization you've created to discuss with the rest of the group. Finally, we'll take a humanistic turn and save the last half hour or so of the workshop to trouble the tools, methodologies, and results we’ve discussed.
Recent Traces of Computerized Text Analysis
You may have seen digital humanist text analysis in the news recently: When some unknown Trump administration official wrote an anonymous NYTimes op-ed, the Internet was atwitter with text analysts comparing officials' public writing style with the op-ed's. At least two of these analyses identified Mike Pompeo as the likely author. Analyst David Robinson came to his conclusion not because of the author’s favoring of the word "lodestar," an unusual word pundits had identified as stylistically noteworthy, but because of the use of the word "malign" among other language features. Other analyses pointed to Elaine Chao, or somebody else in the state department.
This area of study, known as stylometrics, is a growing subfield of computational linguistics. Similar tools were used to identify J.K. Rowling as the author of Cuckoo’s Calling.
Linguistic corpus analysis tools are also behind the Washington Post's data essay looking at State of the Union addresses from 1993-2019, identifying words in each that hadn't previously been spoken in States of the Union. New words in 2019 include “bloodthirsty,” “fentanyl,” “screeched,” and “venomous” (interpret away!).
Collocation, Lemmatizing, and WordSmith Tools
Such text analyses are grounded in the most basic features of linguistic text analysis: Counting word frequencies in a given text, finding unusual two- and three-word sequences (bigrams and trigrams), and presenting those findings for human readers. Software intended for this kind of analysis long predates the Internet and even predates graphical user interfaces.
At one point, in fact, literary scholars produced concordances by hand: Geoffrey Rockwell and Stefan Sinclair [9], creators of the Voyant Tools suite we’ll be using, cite Parrish’s 1959 A Concordance to the Poems of Matthew Arnold, which described a time-honored process of “cutting out lines of printed text and pasting them on 3-by-5-inch slips of paper, each bearing an index word written in the upper left-hand corner [...] Sixty-seven people (three of whom died during the enterprise) took part in the truly heroic labor of cutting and pasting, alphabetizing the 211,000 slips, and proofreading” (50). So get out your index cards, ready your scissors — kidding. Instead, thank your Microsoft and Google overlords; this kind of concordance is trivially easy to create at this point in computational linguistic history.
The first concordancing software debuted in the late 1960s at the University of Toronto [10]. Beginning in 1996, concordancing software that “lemmatizes” text (i.e. trims words to their most basic stems, removing prefixes and suffixes) has been available for researchers and the general public to download online. Lexically’s WordSmith Tools has been sold for the same 50-pound price since 1996.
Corpus analysis has been in a long boom era among genre and language-learning scholars [11][12][13][14][15][16][17]. The same tools have been employed to analyze public text, including 175,000 news articles’ representations of refugees [18], 200,000 articles’ representation of Islam [19] , and 4,000 articles’ representation of feminism [20].
Distant Reading
Although computerized analysis of text has been a popular method of language research in linguistics for several decades, in literature, the method has only been adopted much more recently. Stanford literature professor Franco Moretti brought corpus and metadata analysis to literary study with a series of essays published in 2003 and 2004 in the New Left Review, collected together in a 2005 book called Graphs, Maps, and Trees [21], which offers a variety of "distant" approaches to literary history. Complicating the phrase "the rise of the novel," he cross-culturally maps its many rises in Britain, Japan, Italy, Spain, and Nigeria; by using purchasing records to look at genres in aggregate, he is able to get a sense of their historical shapes instead of looking at their formal features or the particularities of any given text. In the case of early novels, this kind of metadata analysis is especially powerful in the sense that many of the early pulp novels have been lost to time — but publishers kept careful records.In 2010, Moretti founded the Stanford Literary Lab (which, since Moretti was accused of sexual harassment in 2017, has distanced themselves from him to an extent). There, researchers have taken the same data-driven analytical mindset to great questions of literature, publishing results in a series of pamphlets. Their most recent pamphlet, #17 [22], considers the question of the canon: How do we measure canonicity? Primarily, it takes two metrics: Prestige, as a function of "Primary Subject Author" mentions in the MLA bibliography, and Popularity, as a function of reads on Goodreads. This analysis highlights authors that are far and above prestigious and popular: Shakespeare alone at the far top right, followed distantly by Dickens (slightly more prestigious than popular) and Austen (slightly more popular than prestigious). But it also identifies some surprising things — for instance, that this method of mapping the canon often groups together authors from the same genre and period. Note the clustering of the Romantic poets Blake, Coleridge, and Lord Byron; and the clustering of the science fiction authors LeGuin, Dick, Bradbury, Heinlein, Asimov, and Clarke.
By using Goodreads, this measure of canonicity is grounded in current reading practices in a way that most other ways of describing the canon haven't been. Later in the pamphlet, however, the authors use the MLA data to get a sense of changing popularity over time: They chart, decade by decade, the changing rankings of the 20 now most-cited authors in the MLA from 1940 to present. Though Shakespeare remains at the top, unchanged, and Chaucer has held a steady fourth, all the others have shifted: Cervantes hit a low of 18th position in the 70s, to a high of 6th position in the 2010s. Twain has fallen in critical prestige from 8th position in the 40s to 17th today.
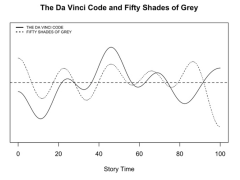
The Stanford Literary Lab also sparked such interesting projects as affiliates' Jodie Archer and Matthew Jockers's 2016 The Bestseller Code [22] , which involved mapping 20,000 novels by topical makeup, emotional beats of the plot, style, and character. From this analysis, they identify qualities most-often associated with bestsellers, and ultimately they identify one novel that best exemplifies these qualities: Dave Eggers's The Circle, which is about Modern Technology, Jobs and the Workplace, and Human Closeness (all among the top ten themes); it has a three-act plotline that nearly exactly matches Fifty Shades of Grey in emotional beats; it has a perfectly average use of masculine/feminine style, contractions, and punctuation; it has a female protagonist whose most-used verbs are "need" and "want" (Archer and Jockers 2016, 192).
This project uses many of the methods of text analysis in computer science and linguistics — machine learning, sentiment analysis, bigram analysis — and employs them to understand something new about novel-writing, something that would not have been possible simply via close reading.
Distant reading is not intended to replace close reading; rather, it is a collection of methods with different aims and goals, always intended to support human interpretation of both the texts themselves and the data about them. Nevertheless, there has been some resistance to distant reading as a methodology. Maurizio Ascari [23] argues that the pseudoscientific approach of distant reading can present biased analyses with the cool implacability of graphs. Lauren Klein [24] suggests that distant reading as practiced has not done enough to seek inclusive, accessible corpora and models that uncover what is hidden instead of what is canonical.
Text analysis lets us ask questions that wouldn't otherwise be answerable, but it is not a method outside of social construction. As you explore texts over the next couple of hours, consider: What kinds of questions do these tools enable you to ask? What kinds of questions do they ignore, disregard, or make impossible to answer?
Some Other Interesting Text Analysis Projects
Contents of this path:
This page references:
- Language about White and Black NFL Recruits: "Intelligence" vs. "Instincts"
- Thorburn, Elise. "Assemblages: Live Streaming Dissent in the 'Quebec Spring.'"
- Tribble, Christopher. "Corpora and corpus analysis: New windows on academic writing."
- Klein, Lauren. "Distant Reading after Moretti."
- Emotional Beats in The DaVinci Code and Fifty Shades of Grey
- Rockwell, Geoffrey, and Stéfan Sinclair. Hermeneutica.
- Gabrielatos, Costas, and Paul Baker. "Fleeing, sneaking, flooding: A corpus analysis of discursive constructions of refugees and asylum seekers in the UK press, 1996-2005."
- John Baez, "Information"
- Flowerdew, L. "Corpus Linguistic Techniques Applied to Textlinguistics."
- Baker, Paul, Costas Gabrielatos, and Tony McEnery. "Sketching Muslims: A corpus driven analysis of representations around the word ‘Muslim’in the British press 1998–2009."
- Madrigal, Alexis C. "Reading the Privacy Policies You Encounter in a Year Would Take 76 Work Days."
- Flowerdew, Lynne. "An integration of corpus-based and genre-based approaches to text analysis in EAP/ESP: Countering criticisms against corpus-based methodologies."
- Jaworska, Sylvia, and Ramesh Krishnamurthy. "On the F word: A corpus-based analysis of the media representation of feminism in British and German press discourse, 1990–2009."
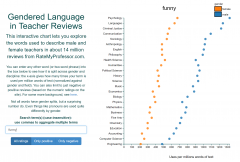
- Gendered Language in Teacher Reviews
- Corley, Courtney D., Diane J. Cook, Armin R. Mikler, and Karan P. Singh. "Using Web and Social Media for Influenza Surveillance."
- Swales, John M. "Integrated and fragmented worlds: EAP materials and corpus linguistics."
- Moretti, Franco. Graphs, maps, trees.
- Nikfarjam, A., A. Sarker, K. Oconnor, R. Ginn, and G. Gonzalez. "Pharmacovigilance from Social Media: Mining Adverse Drug Reaction Mentions Using Sequence Labeling with Word Embedding Cluster Features."
- Aphinyanaphongs, Yin, Armine Lulejian, Duncan Penfold Brown, Richard Bonneau, and Paul Krebs. "Text Classification For Automatic Detection Of E-Cigarette Use And Use For Smoking Cessation From Twitter: A Feasibility Pilot."
- Hyland, Ken, and Polly Tse. "Hooking the reader: A corpus study of evaluative that in abstracts."
- Porter, J.D. Stanford Literary Lab Pamphlet 17: Popularity/Prestige.
- Measuring the Literary Canon via Popularity and Prestige
- Salem, Sara. "Creating Spaces for Dissent: The Role of Social Media in the 2011 Egyptian Revolution."
- Hyland, Ken, Chau Meng Huat, and Michael Handford, eds. Corpus applications in applied linguistics.
- Archer, Jodie, and Matthew L. Jockers. The Bestseller Code.
- Changing MLA Prestige Rankings of the 20 Most-Prestigious Authors, 1940-2018
- Poell, Thomas. "Social Media Activism and State Censorship."
- Scott, Mike, and Christopher Tribble. Textual patterns: Key words and corpus analysis in language education
- Ascari, Maurizio. "The Dangers of Distant Reading: Reassessing Moretti's Approach to Literary Genres."
- The Rise(s) of the Novel
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}