Research with Maltego Carbon
{kind=link}
It may help to consider some of the potential of using Maltego Carbon for academic research. Some early thoughts are included here.
Types of Research Questions
What types of research questions may be asked using Maltego Carbon? It is quite possible to achieve the following:
- What are the http networks around particular domains? URLs? Organizations? Companies?
- What cyber entities are in the region of a particular physical area (like a country, state, city or county)? What cyber entities are a more precise location described by GPS coordinates?
- What is the geolocation of particular types of online data?
- What are some of the online entities and connections to a social media account?
- What are some leads to pursue in terms of resolving an online alias to people in the real world?
- What is the trending sentiment regarding a particular #hashtag conversation or keyword on Twitter? (Tweet Analyzer)
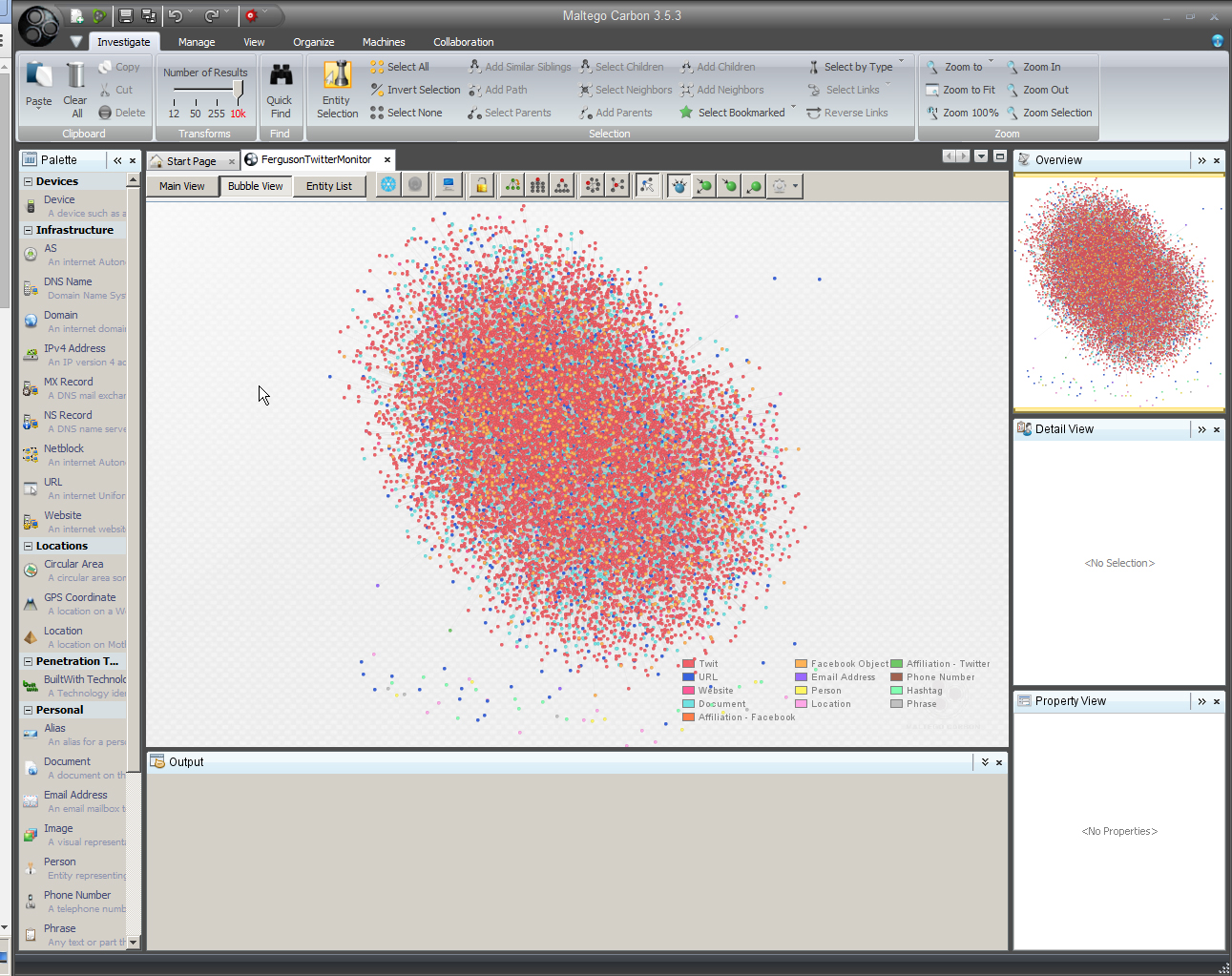
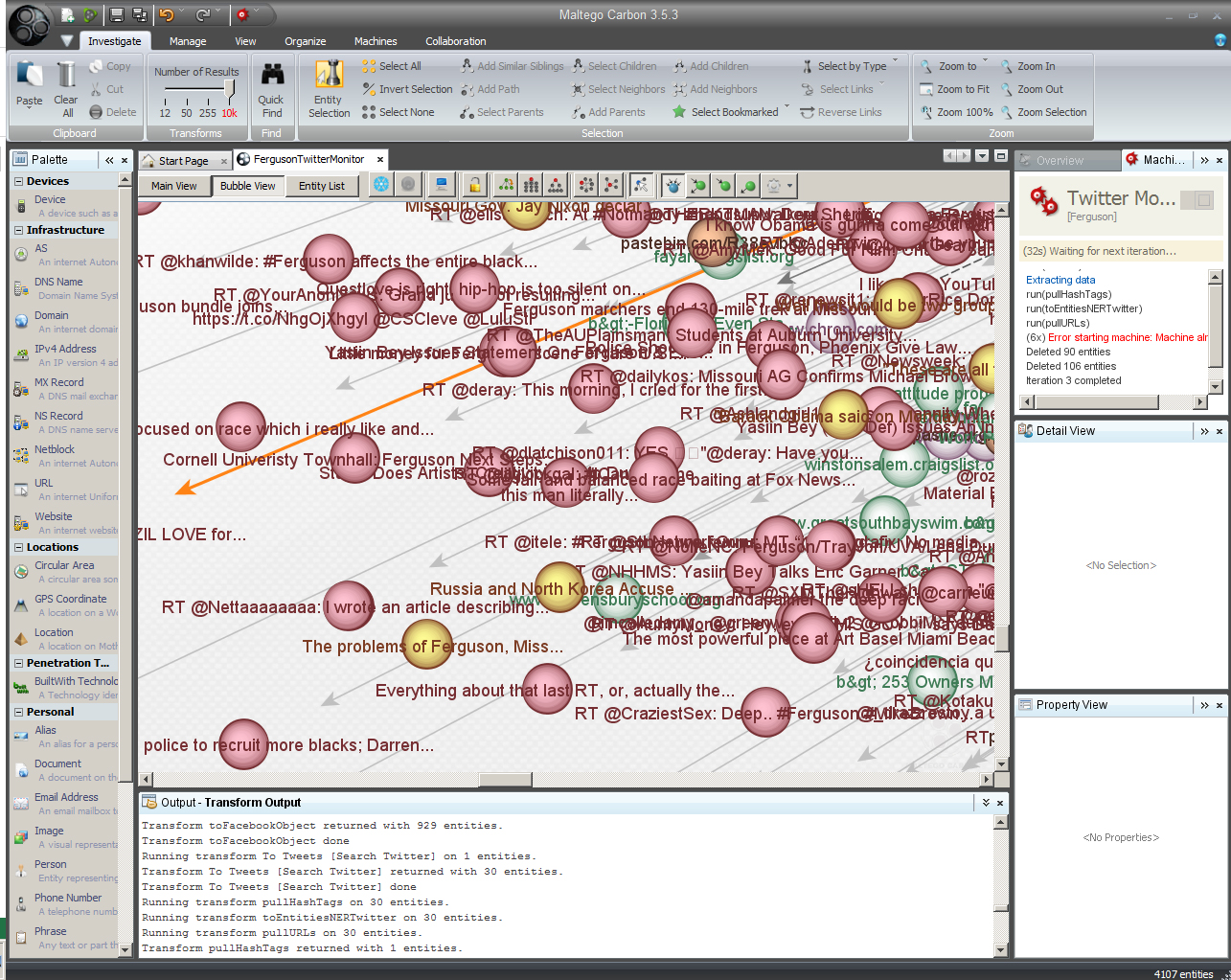
- What have been some trending conversations on Twitter over time? (Twitter Monitor)
In theory, this tool also enables the answering of some of the following (although this author has not been able to achieve positive results with the following types of questions).
- What is the network of editors who’ve worked on a particular Wikipedia article?
- What are some of the social networks formed around #hashtag conversations?
The author still failed to achieve the above types of queries even after inputting Twitter credentials within the Manage Service feature in Maltego Carbon 3.5.3. There are continuing efforts to achieve these types of data extractions. As capabilities change (whether the author’s, the software tool’s, or some combination), this page will be updated. With virtually all results, there will be some need to disambiguate findings and to prune branches.
When to Start with a “Machine”? When to Start with a “Transform”?
A “machine,” again, is a sequence of data extractions designed to achieve particular ends. A “transform” takes a known data input (of an entity) and relates that input to a variety of other types of related information. Maltego machines enable the mapping of macro large-scale networks. In practice, it apparently captures data from the Web and Internet fairly well, but has challenges in terms of accessing data from some social media sites (that require authentication). So when is it more advisable to start with a machine or with a transform?
To over-simplify, if the target is a macro one, it may be easier to start with a “machine.” If the target is a micro one, it may be easier to start with a “transform.” That said, there are multiple points-of-entry for any sort of data extraction. Sometimes, a “machine” extraction stalls with no extracted data; at those times, it’s helpful to then move to “transforms.”
Data extractions using Maltego Carbon are done in a kind of breadth-depth-breadth-depth sort of way. In other words, a network of information is extracted. Nodes of interest are found or conceptualized. Then, additional data is extracted. The data will be structural (as in link analysis), and it will be content-based (with some extracted images, documents, and text).
{kind=link}
Melding Open- and Closed-Source Data
Maltego Carbon enables the integration of network-extracted data with mapping to organization servers for internal or private data, to enable the analytical capabilities of the tool to be applied. What this means is that open- and closed- source data may be commingled for analysis. (This capability comes with the server version of the software, not the stand-alone one.)
What are Nodes of Interest for More Transforms (and More Machines)?
As mentioned earlier, a data extraction in Maltego Carbon involves capturing a breadth of data generally and then digging deeper into particular nodes (entities) and links (relationships). So what are particular nodes and links which should be explored further? In a sense, this can only be answered based on the context. Generic answers may be the following:
- Which nodes are the largest (largest degree, or in-degree, or out-degree) and potentially most influential in the network?
- Which nodes serve as “bridging” nodes connecting otherwise disconnected sub-graphs?
- Which nodes are based on particular physical locations of interest?
- Which nodes seem anomalous? (Which nodes seem to be expected?) Why?
- Which links seem anomalous? (Which links seem to be expected?) Why?
Enough Information? Handling Information Glut
A typical research approach might include a review of the (semi)related literature, hypothesizing, theorizing about what one would see in the empirical data if a hypothesis is true and what one would see if a hypothesis is false, how to construct an experiment (or data query), how many data points are needed, and so on. There is an analogical process with working with Maltego Carbon. There is sometimes the additional question: What happens if one has too much data?
Experimentation for learning. It seems advisable to suggest plenty of experimentation with the software tool to understand optimal settings for various types of data extractions. It would be advisable to practice various types of “seeds” to use for queries for a particular issue. The “seeds” could be URLs, domains, locations, user accounts on social media, #hashtags, Wikipedia pages, and so forth. In terms of online contents, there are many ways to approach an issue. It also helps to extract data over time; Carbon™ enables the saving of the settings of a data extraction for refreshing with new data. Data collections may occur at regular intervals over time. There is limited capability for continuous data extractions through a Twitter Monitor (which may be covering a trending issue).
Data pruning. To create coherence, it is sometimes important to prune extraneous data. Data filtering occurs during the data extraction. Pruning of data may be done at any time during the data extraction process…even after multiple iterations of data collection.
While much pruning involves a hard-delete of the prior-collected data, there can also be strategic pruning. Researchers may break off branches and paste them into new projects for deeper analysis, for example.
Collect all and then sift? Initial tendencies are often to try to collect everything and then to filter what is not directly usable. However, it may be that there are ways to collect more strategically first instead of collecting everything and then sorting through it all. It is important to be able to process what is collected for awareness, research, and / or decision-making.
Any network information collected involves data tables, (interactive) graphs, and exportable reports. Data tables may be exported and analyzed in other tools like NVivo or Excel. Interactive graphs may be panned, zoomed, and visualized in many different ways. Exportable reports which are auto-generated in Maltego Carbon enable the surfacing of yet other insights.
Any collected information may lead to other types of searches and research. For example, in hashtag conversations, URLs, videos, audio, images, and text-based messages may all be explored (potentially using machine-analysis for some of the analyses). The Deep Web may be searched as well.
Adding Annotating Files to Entities
Particular files may be attached to particular nodes (by right-clicking the node and attaching files). Or URLs may also be associated with a particular entity.
What May be Asserted?
Such data extractions may involve some degree of false positives and false negatives. A false positive involves an identification of an entity or a link which does not actually belong to a particular network; a false negative involves failing to identify an entity or link which does actually belong to a network. There are some ways to try to “pressure test” the findings—by re-running queries, by using other software tools to extract insights (and then cross-referencing results), and so on. In other words, given the noise in the environment, the reliance on a number of technical platforms that must be accessed to collect the information, the limits to Internet connectivity, the busyness of the Paterva servers, and other potential factors.
What this means is that any assertions made should be done with the proper explanations for how the data was extracted, including what parameters were used for the extractions, the type of extraction, the decisions made to filter the extraction, and the pruning of the data. The inherent limiting factors based on the types of queries should be included.
As-yet, there is no systematic way to identify the potential amount of "error" (false negatives, false positives; uncaptured data) in each data extraction.
| Previous page on path | Cover: Conducting Surface Web-Based Research with Maltego Carbon(TM), page 10 of 17 | Next page on path |
Discussion of "Research with Maltego Carbon"
Add your voice to this discussion.
Checking your signed in status ...