The User Interface
The makers of NVivo have a simple user interface. To explore this interface, some screenshots have been taken of a semi-populated project.
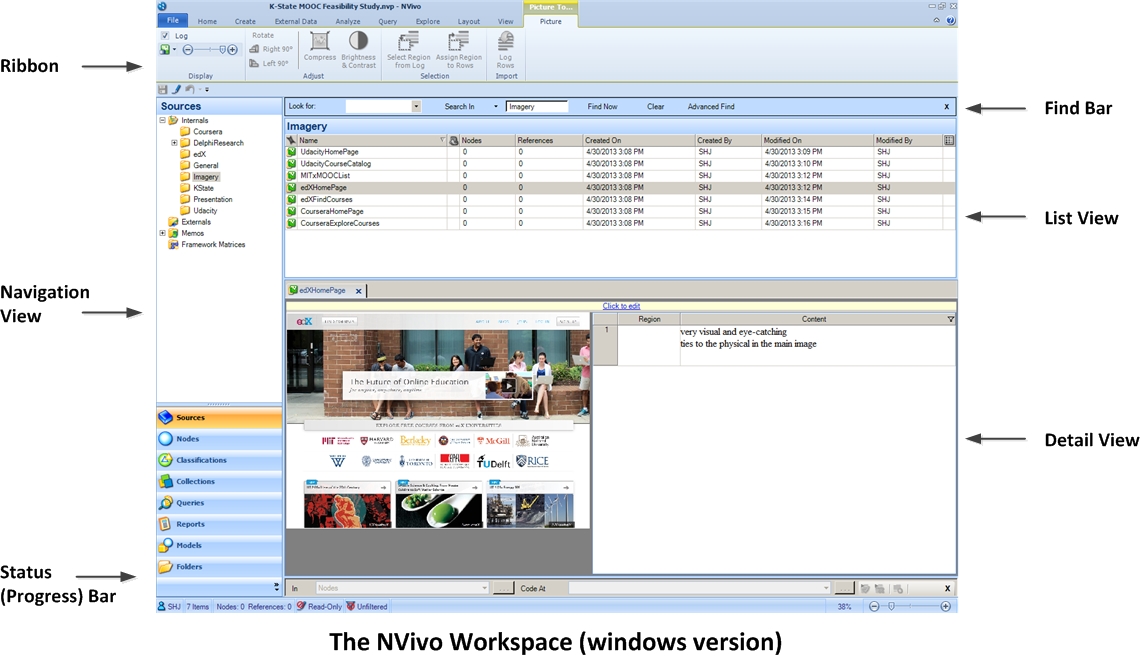
At the top is a ribbon from which a range of functionalities may be selected. The left column serves as the Navigation View, with various categories of resources at the bottom left (and the sub-contents within those categories at the upper left menu bar). At the far bottom left is the Status Bar (progress bar), to indicate when a process is occurring. Just under the ribbon is the horizontal Find Bar. The List View indicates what contents are inside a particular highlighted folder in the upper left menu bar. There is a working pane where a highlighted object may be viewed and coded. At the right is the detail view. The workspace looks a little different depending on the type of multimedia that is being viewed or analyzed.
(This section will focus on the left Navigation View and how contents are to be conceptualized. The functions in the ribbon will be addressed in other parts of this book based on various analytical queries, data visualizations, reports-creation, and other functions.)
Flexibility and inflexibility. NVivo is a highly flexible tool. Any document, folder, or node may be named and re-named. Any object may be moved from one location to another. The hierarchical structures (such as of folders or nodes) may be reconfigured. Any items may be deleted (and these are one with an irrecoverable hard delete, so researchers should be certain that they want to delete the particular object).
There are two main aspects of the tool that are “inflexible.” One is the person’s name and initials that are input at the installation. Once that is input, those are the initials that will show up in the eventlogs and other metadata linked to source file uploads and node annotations. The other is ingested data. Once interviews, surveys, or articles or other multimedia are ingested into the project, the researchers cannot edit out the names (so as to anonymize the data) or make changes to the original underlying files. While they may annotate over the files, they may not change the underlying information.
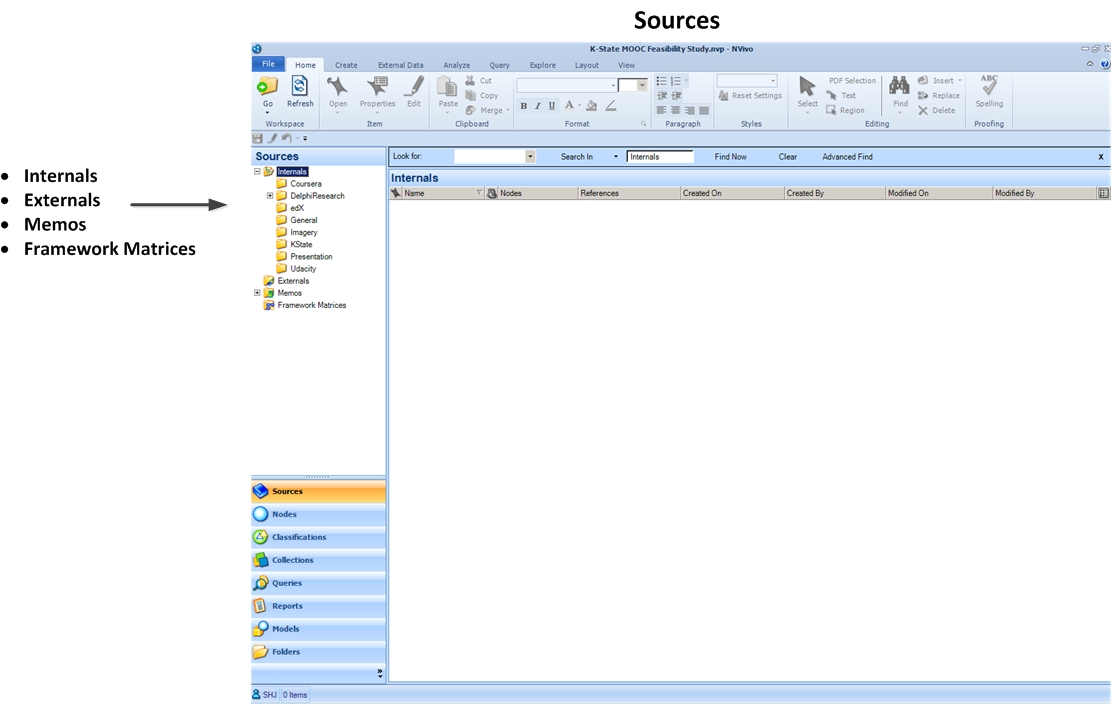
One of the main areas where researchers will work—at least initially—is in the sources area. The pre-existing folders in this area are Internals, Externals, Memos, and Framework Matrices.
The Internals folder contains any sort of digital files that are usable in NVivo: text files (.doc, .docx, .txt, .rtf, and others), document files (.pdf), imagery (.png, .jpg, .tif, and others), audio files (.mp3 and others), video files (.mov, .mp4, and others), datasets (.xl, and others), and so on. Microsoft slideshows (.ppt and .pptx) are not ingestable, but they may be easily converted to PDF with a free PDF converter.
The Externals folder contains “proxies” for non-digital sources of relevant information for the research. These “external” types of sources may include file types that are not ingestible into NVivo. To enable the researcher to include such information, the Externals folder should contain summaries and other types of codable data—from external events and sources.
The Memos folder contains notes about the research by the researcher / research team.
Framework Matrices are matrices that may be used to help provide a summary overview (framework) of source materials. One example that is used is the pulling out of particular themes in the columns (and listed in row A1) and then various individual cases or exemplars in the rows below. In each of the intersected cells, then, are the respective summaries. Another organizational method may be to have each of the rows be different age groups or different regions of the interview subjects or different socio-economic status factors used to group the respondents…and themes about their responses on a number of variables (in the columns). A framework matrix is not automatically populated. Rather, the intersecting cells are filled in manually by the researcher or research team.
At the top is a ribbon from which a range of functionalities may be selected. The left column serves as the Navigation View, with various categories of resources at the bottom left (and the sub-contents within those categories at the upper left menu bar). At the far bottom left is the Status Bar (progress bar), to indicate when a process is occurring. Just under the ribbon is the horizontal Find Bar. The List View indicates what contents are inside a particular highlighted folder in the upper left menu bar. There is a working pane where a highlighted object may be viewed and coded. At the right is the detail view. The workspace looks a little different depending on the type of multimedia that is being viewed or analyzed.
{kind=link}
Again, there is nothing necessarily deterministic about the structure. A researcher or research team is free to determine which aspects of the folder structure to use. If the numbers of buttons at the bottom left are undesirable, faculty members have the ability to “hide” some of the source types at the bottom right in the shaded area of the left menu bar.
Flexibility and inflexibility. NVivo is a highly flexible tool. Any document, folder, or node may be named and re-named. Any object may be moved from one location to another. The hierarchical structures (such as of folders or nodes) may be reconfigured. Any items may be deleted (and these are one with an irrecoverable hard delete, so researchers should be certain that they want to delete the particular object).
There are two main aspects of the tool that are “inflexible.” One is the person’s name and initials that are input at the installation. Once that is input, those are the initials that will show up in the eventlogs and other metadata linked to source file uploads and node annotations. The other is ingested data. Once interviews, surveys, or articles or other multimedia are ingested into the project, the researchers cannot edit out the names (so as to anonymize the data) or make changes to the original underlying files. While they may annotate over the files, they may not change the underlying information.
More about the Interface
Sources Space
One of the main areas where researchers will work—at least initially—is in the sources area. The pre-existing folders in this area are Internals, Externals, Memos, and Framework Matrices.
{kind=link}
The Internals folder contains any sort of digital files that are usable in NVivo: text files (.doc, .docx, .txt, .rtf, and others), document files (.pdf), imagery (.png, .jpg, .tif, and others), audio files (.mp3 and others), video files (.mov, .mp4, and others), datasets (.xl, and others), and so on. Microsoft slideshows (.ppt and .pptx) are not ingestable, but they may be easily converted to PDF with a free PDF converter.
The Externals folder contains “proxies” for non-digital sources of relevant information for the research. These “external” types of sources may include file types that are not ingestible into NVivo. To enable the researcher to include such information, the Externals folder should contain summaries and other types of codable data—from external events and sources.
The Memos folder contains notes about the research by the researcher / research team.
Framework Matrices are matrices that may be used to help provide a summary overview (framework) of source materials. One example that is used is the pulling out of particular themes in the columns (and listed in row A1) and then various individual cases or exemplars in the rows below. In each of the intersected cells, then, are the respective summaries. Another organizational method may be to have each of the rows be different age groups or different regions of the interview subjects or different socio-economic status factors used to group the respondents…and themes about their responses on a number of variables (in the columns). A framework matrix is not automatically populated. Rather, the intersecting cells are filled in manually by the researcher or research team.
Nodes Space
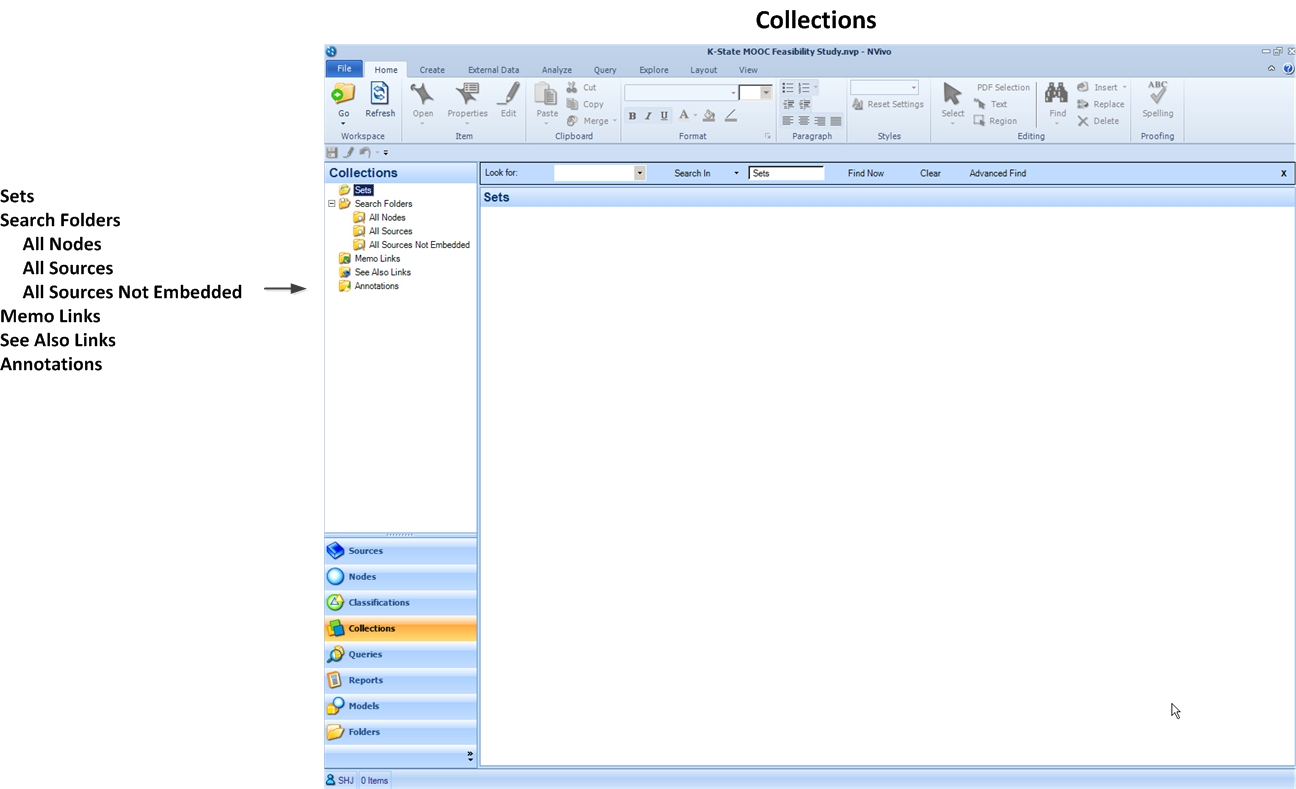
Collections Space
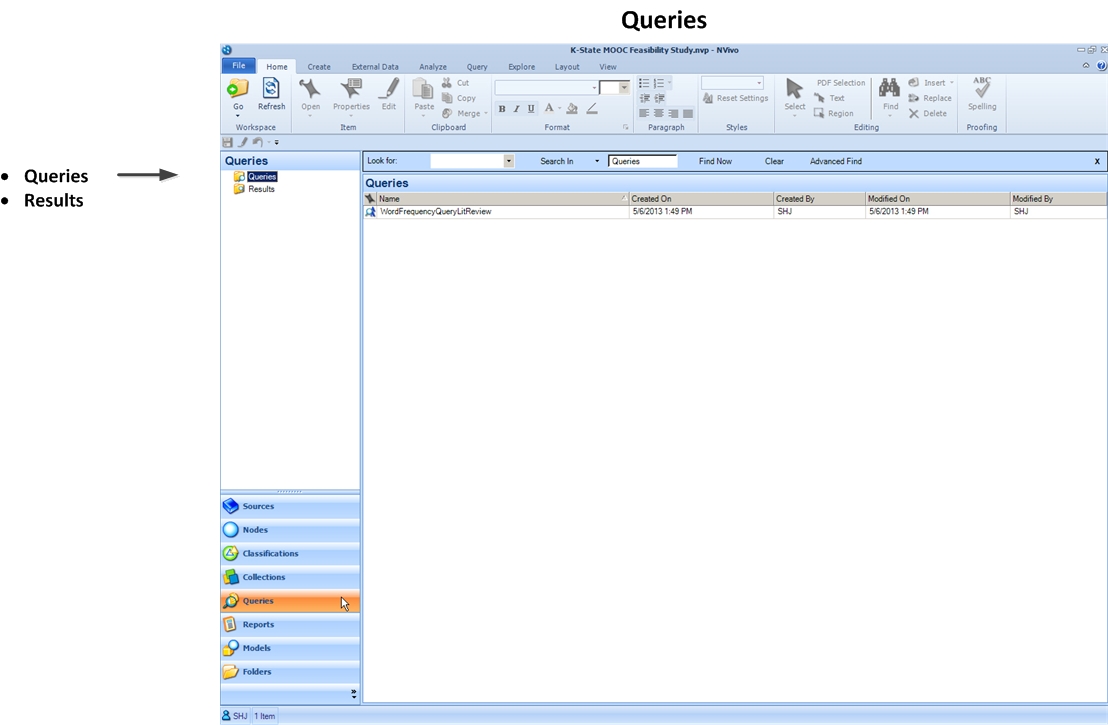
Queries Space
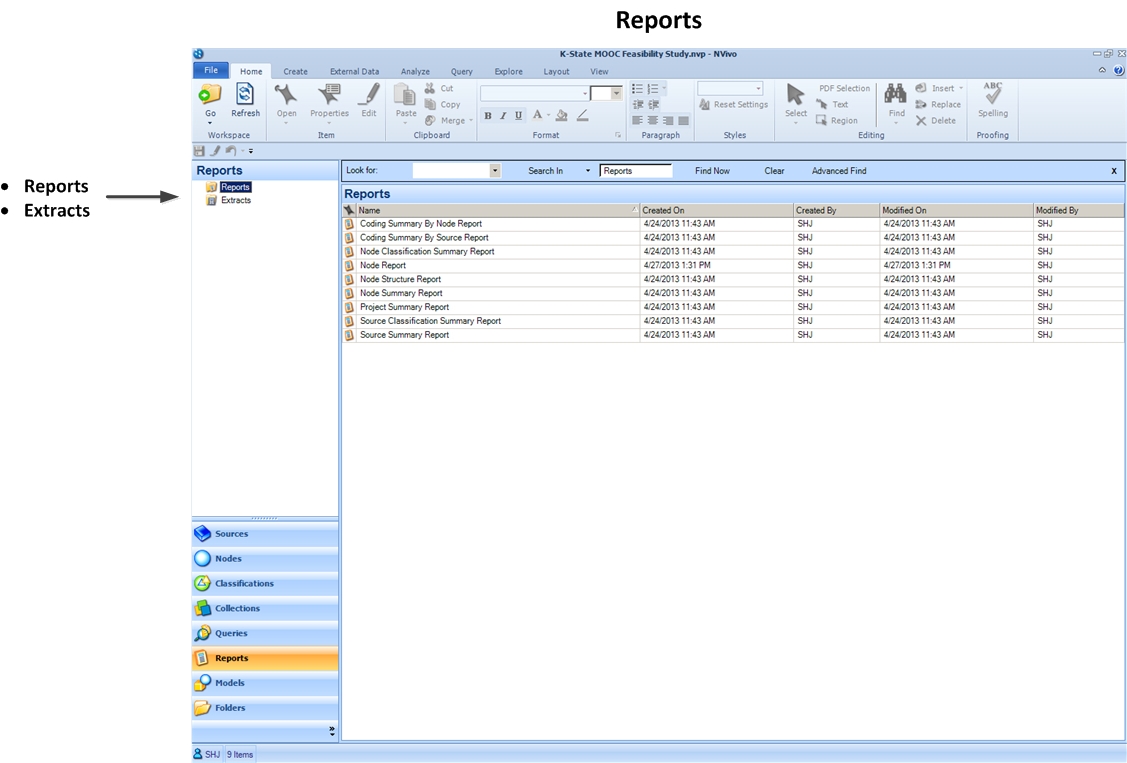
Reports Space
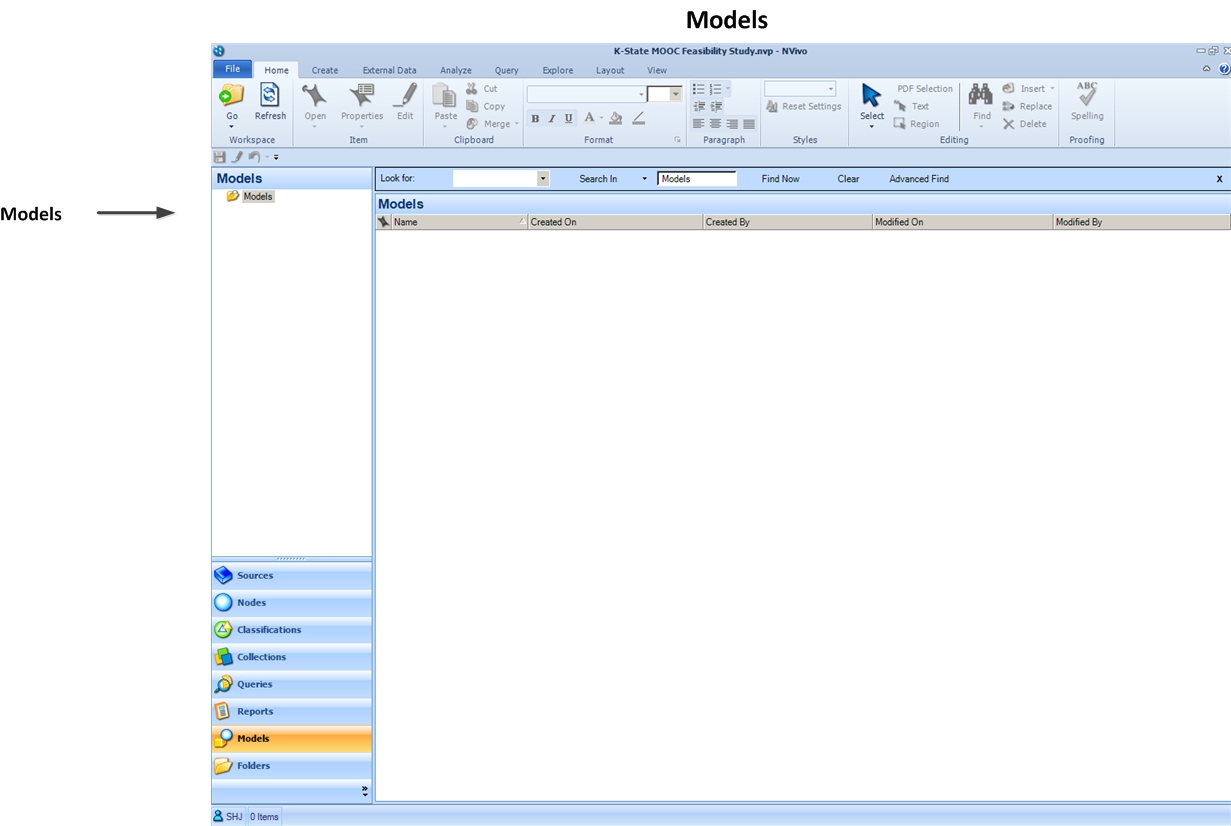
Models Space
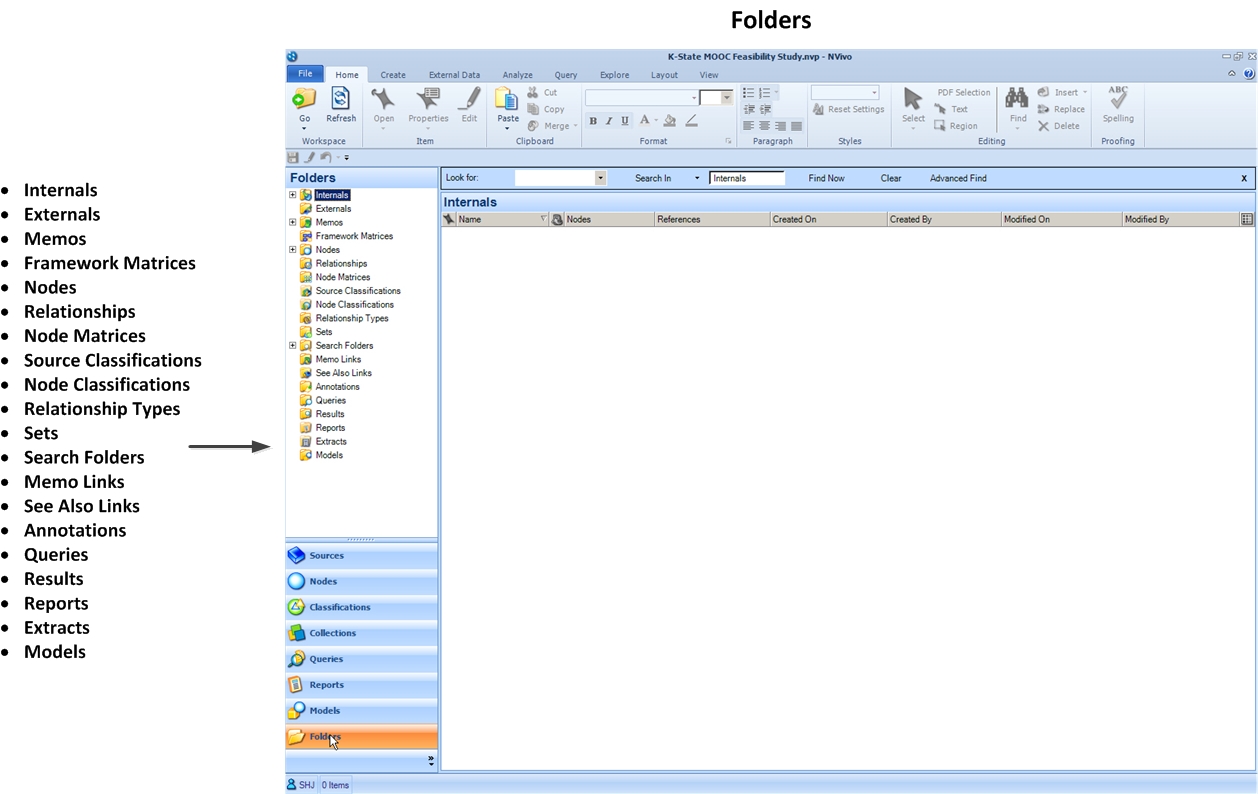
Folders Space
{kind=link}
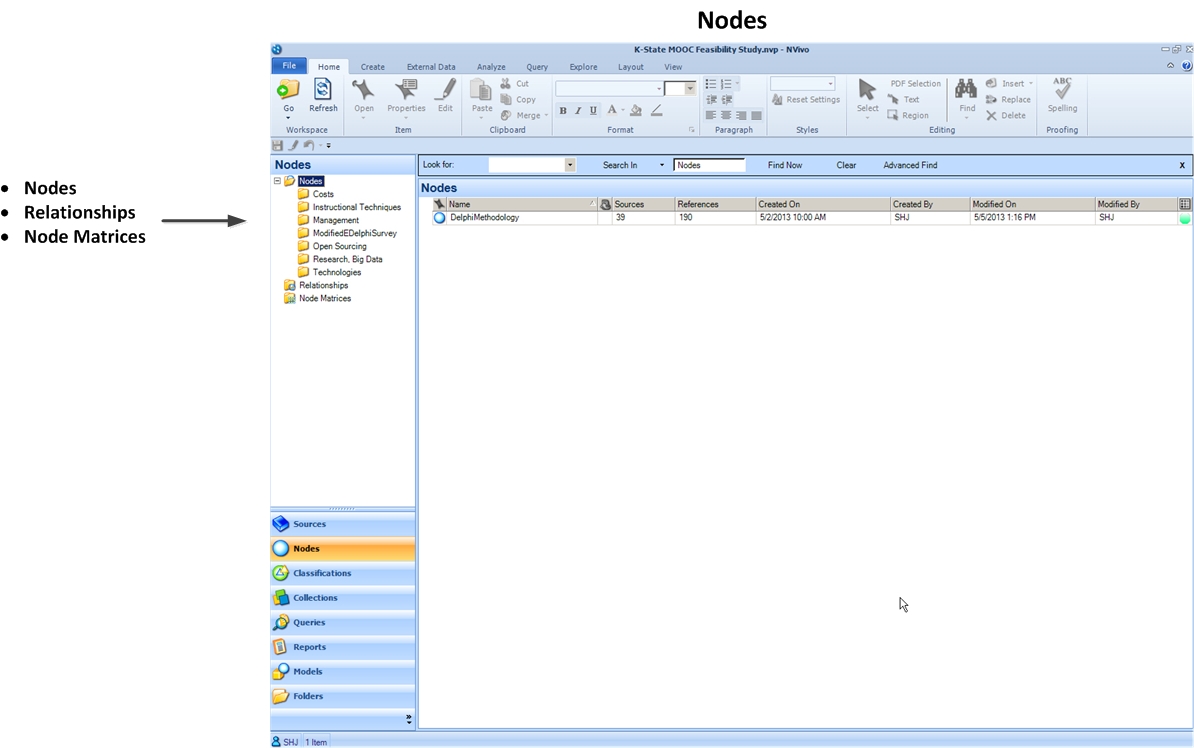
The Nodes space is also a very critical one, which consists of the overlay of coding that is applied to the source data.
The Nodes space contains the coding linked to the particular project. This may include codes that were both human-created as well as those that were auto-coded (by data ingestion and / or by machine-emulation of human coding patterns).
The Nodes section also contains any of the defined relationships between the nodes.
Also, any node matrices are included. Node matrices are created when particular nodes are selected and cross-referenced against other nodes to find points of overlap.
The Nodes space contains the coding linked to the particular project. This may include codes that were both human-created as well as those that were auto-coded (by data ingestion and / or by machine-emulation of human coding patterns).
The Nodes section also contains any of the defined relationships between the nodes.
Also, any node matrices are included. Node matrices are created when particular nodes are selected and cross-referenced against other nodes to find points of overlap.
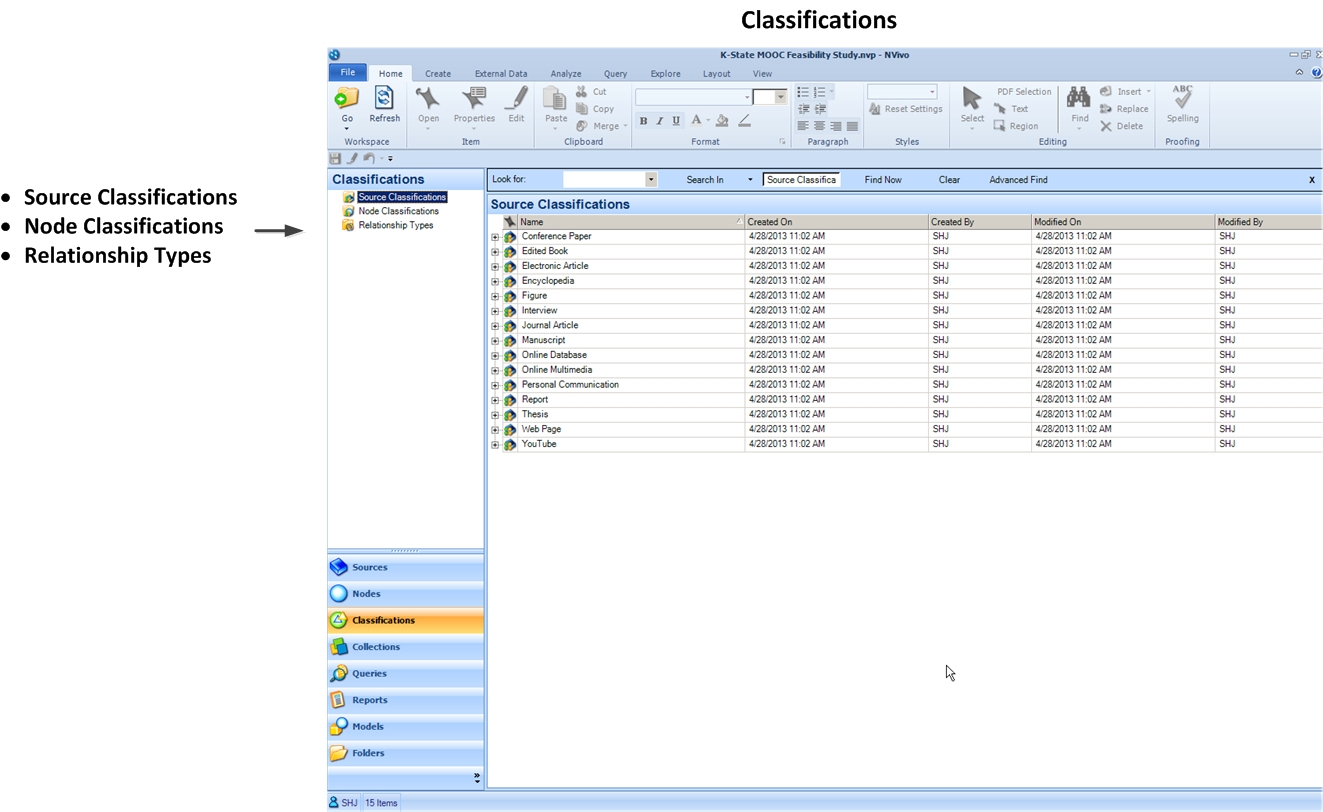
Classifications Space
{kind=link}
{kind=link}
Queries Space
{kind=link}
Reports Space
{kind=link}
Models Space
{kind=link}
Folders Space
{kind=link}
| Previous page on path | Index, page 5 of 23 | Next page on path |
Discussion of "The User Interface"
Add your voice to this discussion.
Checking your signed in status ...