Data Query: (Qualitative) Crosstab Query
Qualitative Crosstab Query
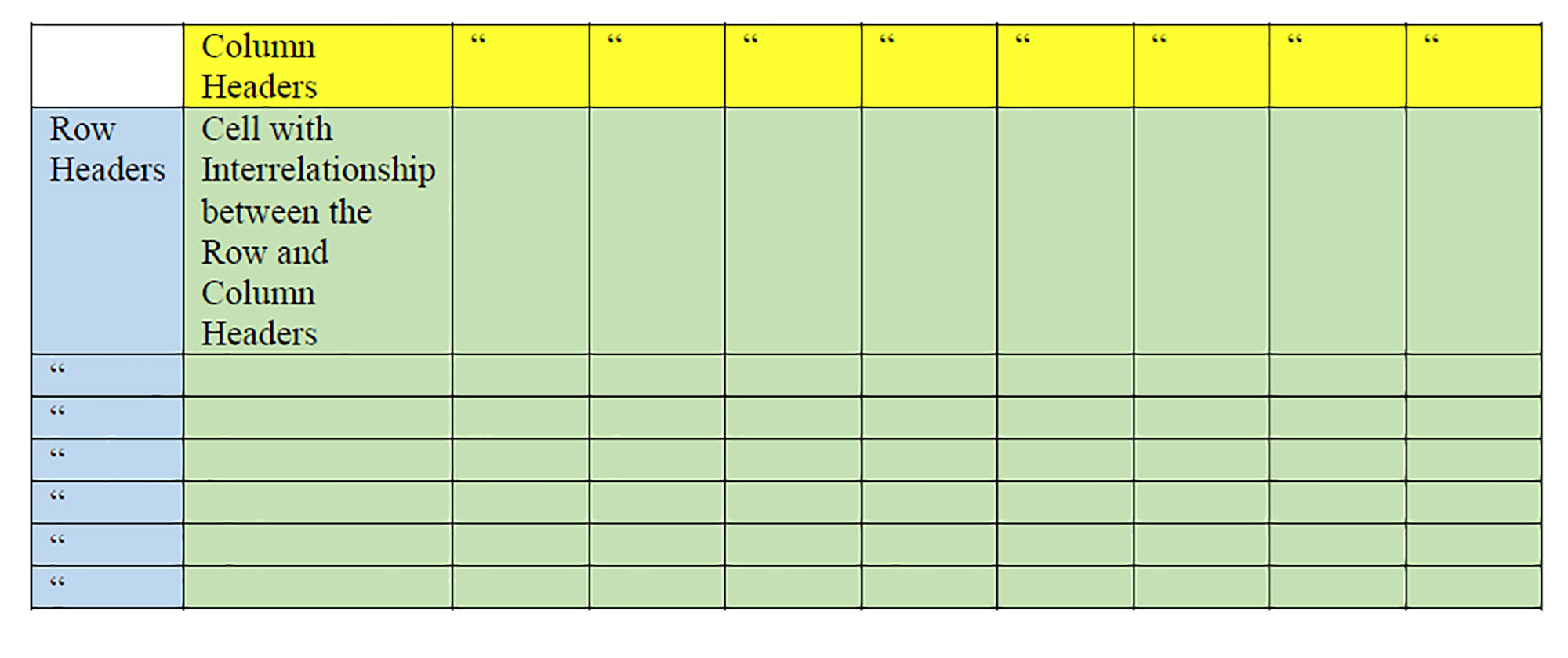
A classic quantitative research cross-tabulation analysis involves a setup of research variables in column headers ("banner") and row headers ("stub") in a basic matrix.
{kind=link}
The overlapping cells in the middle usually contain some numerical representation. Ceteris paribus, all things being equal, based on the numbers of variables, there should be certain predictable numbers (ranges of numbers) in each cell if there is nothing more than random chance acting on the respective variables. (The degrees of freedom or "df" is calculated in part by the numbers of variables in the matrix.)
Anomalous results in a data cell suggest that something else may be occurring between the two variables.
In such cases, the human analysts examine the variables and hypothesize what might be going on between the two.
A Huge Oversimplification of Quantitative Cross-tab Analyses
If the numbers in the data cells are unusual (based on a calculation of the chi-squared test), with a p < .05 or a p < .01, then it may be considered that there is something in the dyadic relationship between the two overlapping variables...that might suggest an association.
It would be better to read some heavier-duty statistical analysis explanations.
A Qualitative Crosstab Analysis.
A qualitative crosstabulation analysis does not involve complex calculations that result in the tests of statistical significance. Rather, this version enables the setting up of cross-tabulations that result in numerically populated tables that suggest at frequency (numerical counts)...and are represented as intensity matrices.
(Using the crosstab analysis assumes the creation of case nodes...so that demographic data may be used to structure particular queries for certain queries around certain data patterns.)
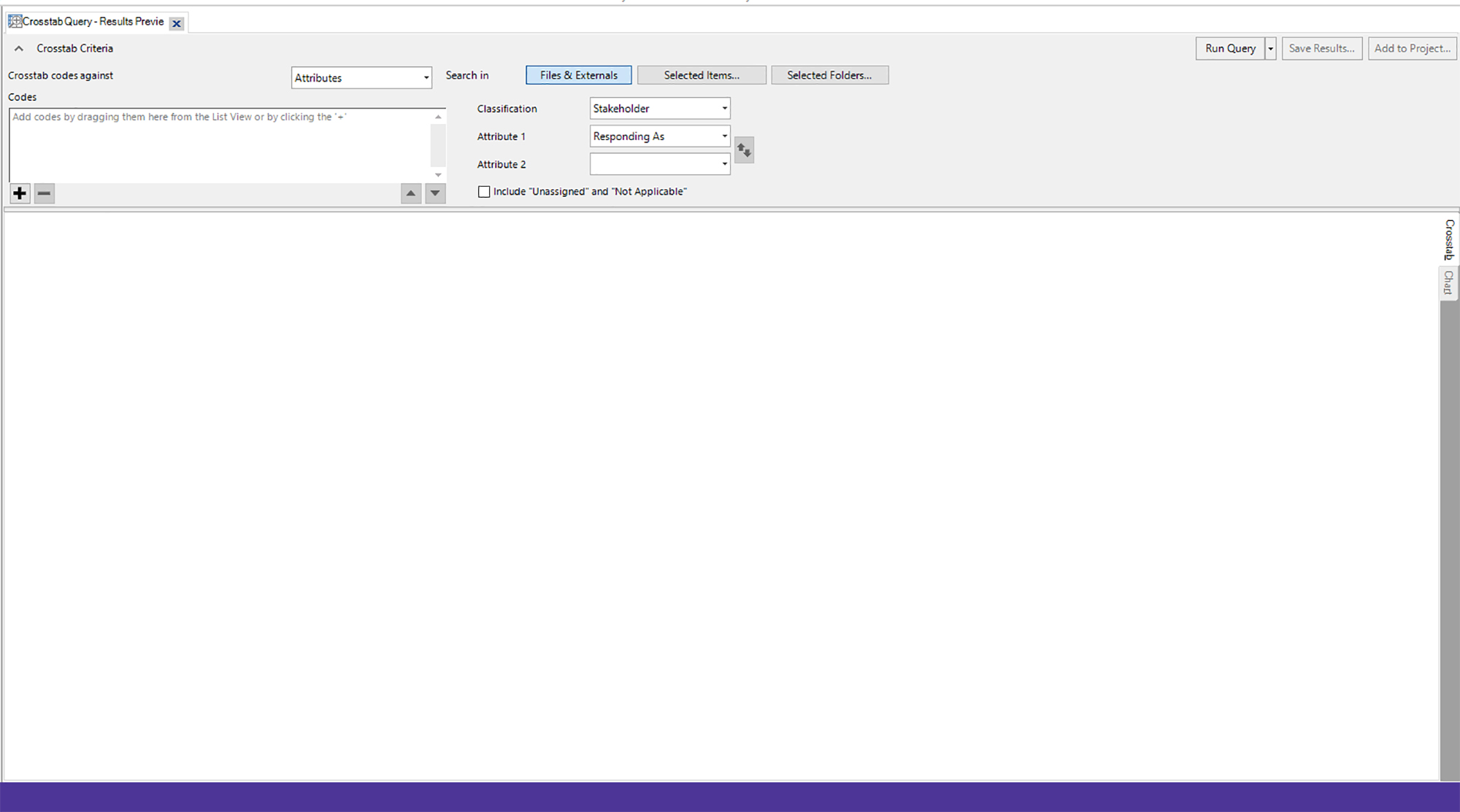
Some Askable Questions Using the (Qualitative) Crosstab Query
{kind=link}
For this example, let's assume that the data has been collected and coded properly to enable the asking of the following questions.
Some askable questions in NVivo using this data query type include the following:
Ego (individual)-based questions:
- Based on this particular attribute of a respondent (gender, class, age, or others), what were their sentiments around a particular topic?
- Based on the geographical attribute of the respondent (home address, work location, or others), what were their main concerns in this domain area?
- Based on a particular open-ended question, what are the main differences between males and females in terms of their focal responses?
Entity (group)-based questions:
- Are there differences in concerns of micro, meso, and macro-sized organizations in this particular sector about this particular issue? If so, what? What are the differences of foci? What are the differences in sentiment? Why?
- What are some differences in attitudes towards the target market by organizations in different countries? Why?
- Do new businesses have different attitudes about a particular topic in a particular domain as compared to older businesses?
- Are there core differences in responses based on a target population based on segmentation by whether they were interacted with by focus group or by interview or by online survey?
The asking of questions requires that the correct information be collected, handled properly, cleaned properly, set up correctly, queried properly (so that there are the available nodes to cross-reference), and set up accurately in the crosstab analysis. There are ways to get off track.
| Previous page on path | Conducting Data Queries... (Part 2 of 2), page 5 of 8 | Next page on path |
Discussion of "Data Query: (Qualitative) Crosstab Query"
Add your voice to this discussion.
Checking your signed in status ...