Supervised learning
1 media/supervised_learning_thumb.jpg 2025-09-09T16:44:42-07:00 Carina Albrecht 6c2c563e658b00687803c6e8b1e715c6bf1de2a4 41570 1 plain 2025-09-09T16:44:43-07:00 Carina Albrecht 6c2c563e658b00687803c6e8b1e715c6bf1de2a4This page is referenced by:
-
1
media/white_square.jpg
2024-12-09T11:31:26-08:00
Classify
6
plain
2025-09-09T17:03:14-07:00
This module conceptualizes data classification as a form of infrastructure —a systematic mechanism designed to organize and control data. This perspective is informed by the influential work of Geoffrey Bowker and Susan Leigh Star (1999). The module also explores the relationship between classification infrastructures and Foucault's theory of biopolitics, which examines the power structures that govern the control of bodies. Finally, the module demonstrates how datasets can be integrated into various systems as infrastructures, carrying classification standards with them.
The urge to classify
Why do we classify? What purpose does classification serve in our lives?
Bowker and Star (1999) define classification as a "segmentation of the world" and argue that "to classify is human". This definition inherently suggests that the world is not naturally segmented; instead, humans impose categories upon it. Categories are not natural phenomena but human creations, originating from our experiences and what the human body can perceive in the physical and social world.
The question of why we classify and create categories for natural phenomena has been a subject of philosophical inquiry since the dawn of civilization. An entire branch of philosophy called ontology is dedicated to studying "being"—what entities exist or do not, and why humans are compelled to categorize what they experience as existing. Therefore, when Bowker and Star declare "to classify is human," they underscore the profound influence of human experience on classification, making it inherently subjective and messy.
Classification is an "idealization" of the world by a person or group, and this idealization is then projected into systems that order and control. Crucially, categories created by some can conflict with the real-world experiences of others, especially when they attempt to impose organizational structures or social values. Therefore, categories are social constructions: there is no fundamentally natural or correct way to classify things.
Standards: the material force of classification
When a social group or institution reaches a consensus on a particular method of classification, standards are born. These standards often emerge from industry, academia, and research communities, and are typically imposed by powerful and authoritative groups or institutions within a given field. A classic example is the choice between the metric and imperial systems for categorizing distance. The adoption of one over the other (e.g., Canada adopting metric, the US adopting imperial) is a cultural choice, not based on objective reasoning. These choices are made by those with the power to impose them, and individuals comply because these standards become embedded in numerous infrastructures. Once established, standards transform categories into a taken-for-granted force that organizes things, rarely questioned by those who use them.
Standards effectively impose the classifier's point of view on the spaces they organize, becoming a potent force for order and control. Bowker and Star (1999) refer to this as the "material force" of classification, highlighting its real power to influence and move people and objects caught within its infrastructure.
Foucault, biopolitics, and the power of classification
Bowker and Star's concept of material force draws heavily from Michel Foucault's theory of biopolitics. Foucault (2010) used the term biopolitics (from "bio," referring to bodies) to describe how entities exercise power through the management and regulation of populations and bodies. This occurs through various techniques that organize society, not only by governments but also by institutions like the church, workplaces, and schools. For Foucault, discipline is a form of power. Institutions like prisons, workplaces, and schools exert discipline, shaping bodies and behaviours. This power can be distributed, not always concentrated in one person. This disciplinary power creates what Foucault termed "docile bodies"—individuals whose behaviour is regulated through what they perceive as self-discipline, but which is, in fact, an externally imposed discipline from society and institutions.
Foucault also argued that normalization is a kind of power. Certain behaviours are deemed "normal," while others are labelled "deviant". This extends to bodies themselves: categories for gender, sexuality, and race define what is "normal," and bodies that do not fit these categories are considered "deviant". Discipline and normalization represent a "soft power" because their source is often diffuse and difficult to pinpoint.
These Foucauldian theories of power are crucial for understanding Bowker and Star's "material force" of categorization. Categories are a form of normalization, defining what is considered normal and what is not. This normalization, once integrated into an overarching system through standards and infrastructures, becomes disciplinary power.
Datasets as infrastructures: categories and machine learning
Datasets are where individual units of data are most likely to become standardized and merge with technological infrastructures. A dataset, as its name suggests, is a collection of data that has been gathered, organized (manually or through automation), classified, and packaged for reuse. Throughout this multi-step process, bias can creep in at various points.
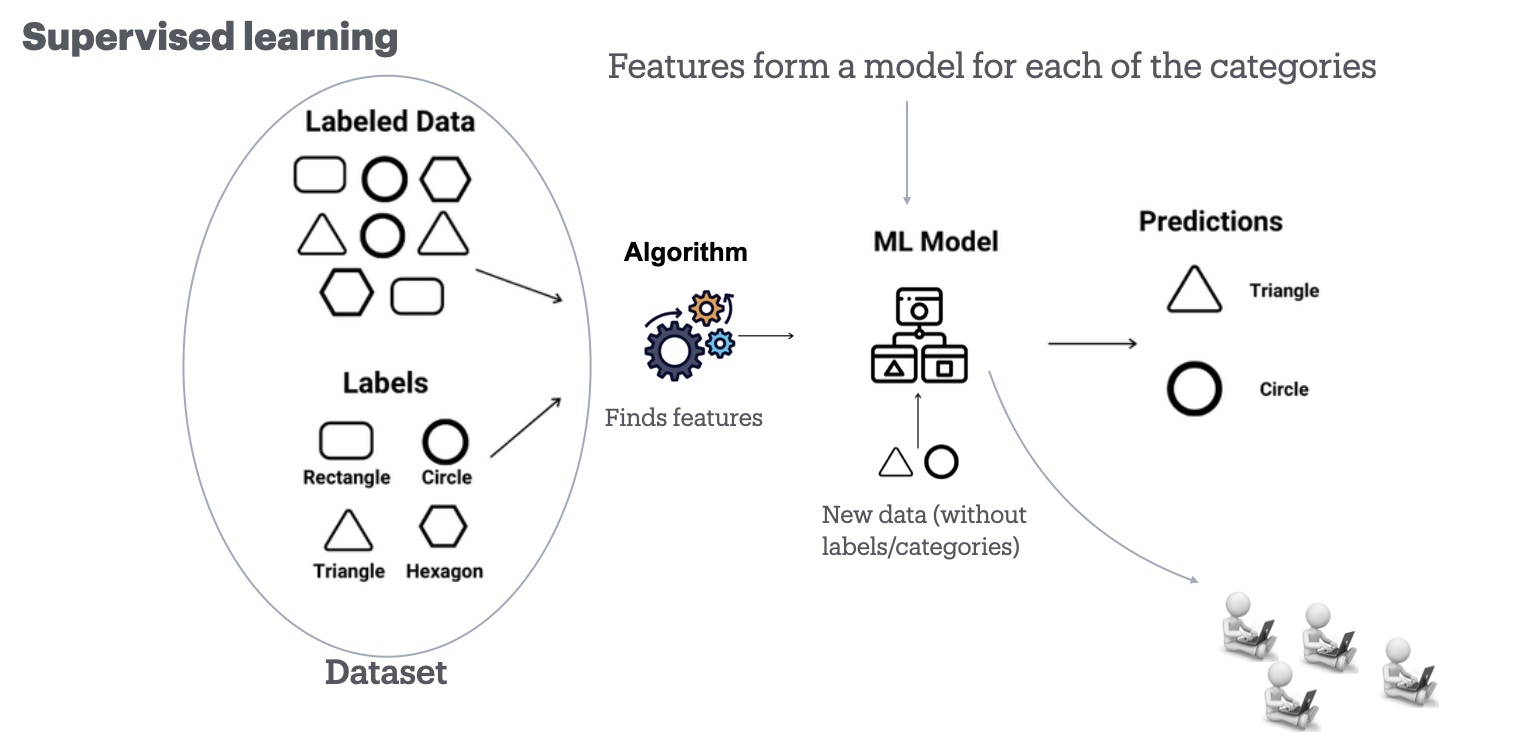
For example, in supervised machine learning, an algorithm is "fed" classified datasets to infer patterns that define each of the categories (or "labels") used in the classification. The algorithm identifies similarities within data belonging to the same category and differences between categories, constructing a "model" for each. For example, if given a dataset of geometric shapes (rectangles, circles, triangles) correctly labelled by a human, the algorithm will identify "features"—specific characteristics—that are similar within a category but different from others (e.g., circles lack corners, triangles have three corners). These features then form a model for each category, representing what makes them unique. Once the model is built, new, unlabelled data is fed into it, and based on its features, the model predicts the category the shape belongs to. Crucially, in this process, the model is what circulates later, not the initial dataset—the dataset becomes invisible once the model is packaged. However, the dataset is still present in the work of classification through the model.For example, consider one machine learning model built to classify faces in photos based on race (Khan et al., 2021). Researchers gathered 250 facial photos (source unspecified, possibly a company database) and had a person manually classify them by race, creating a labelled dataset. The learning algorithm then analyzed these photos to identify features differentiating each racial category. The model identified six features predictive of race: eyes, mouth, nose, skin, brows, and hair (with the photo's background also being a feature).
Machine learning models rank features by importance, assigning more weight to those most predictive of a category. In this case, nose was the most important predictor of race, followed by hair, mouth, eyes, and eyebrow, while skin was the least helpful predictor of race. One might be tempted to conclude that this algorithm is not racist because skin colour is not the primary discriminator; instead, features like nose, hair, and mouth are.
However, this approach is alarmingly similar to 19th-century methods of categorizing race, despite our scientific understanding that race is not a biological truth but a social construction (Crawford, 2021).
Race has historically been, and continues to be, used to justify violence, oppression, and discrimination. While these issues are well-established in social sciences and humanities, computer scientists and engineers often casually integrate racial classification into machine learning models. By doing so, they are encoding into infrastructure a model known to cause oppression, potentially expanding its reach across various systems. Such models have dangerous applications, particularly in facial recognition for policing and security surveillance at airports, borders, or CCTV systems. They can also be used in advertising, which can still lead to discrimination (e.g., in real estate). All these applications for racial classification are known to produce bias and discrimination. Building such models means encoding bias into the machine through datasets, which, when integrated into surveillance or policing infrastructure, will amplify this bias (Buolamwini, 2023).
Conclusion
Classification might appear to be a simple, mundane, and useful task. However, when applied to humans, classification becomes an ethical choice. It inherently reflects the viewpoint of the classifier, and by privileging some perspectives, it can silence others. Once categories are established as part of a classification system, they become standardized and often invisible. When we look at a data visualization, we rarely question the complex journey of the dataset or the hidden work that shaped it. When classification systems are encoded into algorithms and obscure infrastructures, their consequences can be far-reaching, making it difficult to pinpoint the sources of oppression and injustice. The inherent obscurity of classification within infrastructure often prevents us from understanding the origins of bias. Moreover, classification systems, along with their biases, can endure for years within machine learning models.
While classification serves a vital purpose by making systems usable and efficient, it is crucial to remember that it is never neutral. The stakes are significantly higher when humans are caught within classification systems, particularly concerning race and gender. In these contexts, classification has the power to amplify existing systems of oppression.
Therefore, understanding the non-neutrality and consequences of data classification is crucial for responsible engagement with data and AI.
Sources
Crawford, K. (2021). “Classification,” in The Atlas of AI: Power, Politics and the Planetary Costs of Artificial Intelligence, pp. 123-149.
Khan, K., Khan, R. U., Ali, J., Uddin, I., & Khan, S. (2021). Race Classification Using Deep Learning. Computers, Materials & Continua, 68(3)
Buolamwini, J. (2023). Unmasking AI: A story of hope and justice in a world of machines. Random House.
Foucault, M. (2010). The birth of biopolitics: Lectures at the Collège de France, 1978-79 (M. Senellart, Ed.; Paperback ed). Palgrave Macmillan.
{kind=link}