Applying LIWC-22 for computational narrative analysis
By Shalin Hai-Jew, Kansas State University
When people speak or write, they are sharing some information intentionally, and they are also sharing some information unintentionally. People always “leak” something when they express themselves, whether it involves micro expressions on their faces or aesthetics in their art or values in their consumer behaviors, and whatnot.
Computational text analysis offers one way to better read into people’s language-based expressions. And of the various tools used for various types of computational text analysis, Linguistic Inquiry and Word Count (LIWC-22), pronounced “luke,” was initially applied from 1992 – 1994 (Tausczik & Pennbaker, 2010, p. 28). It was made public sometime in mid-1990 (Hai-Jew, May 15, 2016). LIWC is one of the foremost tools in use today (and one of the best and transparently documented instruments, with measures for construct validity, reliability, and other factors). Beyond the classic linguistic analysis and word count, there have been a range of built-in validated psychometric tools in LIWC.
A review of some of the literature in which LIWC was used shows applications for deception analysis, authorship analysis, social relationship exploration, suicide prediction, fraud detection, remote profiling, and numerous other applications.
Besides its track record, it is very easy-to-use. The published manuals about the tool are solid and easy-to-understand. The tool does not save the data internally, though, and it does require dumping the information out in Excel for data visualizations and analysis.
While the built-in dictionary is not available to view or edit, users of LIWC-22 may make their own dedicated dictionaries. And many have shared their dictionaries (.dic format) online via the LIWC site.
The latest release after the 2015 one is LIWC-22, which was released in early 2022. The cost is still very reasonable, on a type of sliding scale, at least for the academic or educational license. This version includes a feature for narrative analysis, and there is a forthcoming capability for authorship analysis.
Storytelling is considered the oldest form of information exchange for humanity. The telling of stories is seen as a natural and common way for information to be shared. A typical story is comprised of a beginning, a middle, and an end. Typically, the early part of a story is used to set the stage. Then tension builds over time as the character or various characters strive to achieve their objectives. Then, there is a moment of denouement and then a release. The cultural practices of storytelling in every society means that there may be some level of predictability in the writing. The prior describes the typical approaches for linear or chronological storytelling, but that is not to say that there aren’t various non-linear types of storytelling (such as looping time stories, flashbacks, and others).
The narrative analysis splits a text into five segments (although this parameter may be changed in the tool), which are then analyzed across three dimensions. “Staging” refers to language that is used to set a scene (introducing characters, introducing the context). “Plot progression” refers to action verbs and language that show action occurring. “Cognitive tension” refers to language that shows the building up of tension and the release of tension.
A minimum of 250 words per “document” are thought to be necessary so the technology has at least 50 words to work with per each 20% segment. [This may mean that microblogging messages may be too short to treat as individual documents for narrative analysis. I had tried some six-word novels during SIDLIT 2022 and could not get the system to work, for example.] For very long documents, perhaps it would make more sense to have more than five segments, in order to capture more of the granular changes across the three dimensions, in ways that track and map.
So how do these three elements apply to narration (storytelling)? Basically, texts that hew closely to narratives have a high level of “staging” language early on, and then the staging drops off as it becomes less important. (The scene is already set by the midpoint or earlier of a classic story.) “Plot progressions” are supposed to build in action over time and perhaps level off near the end (unless the story ends with a crescendo of action). In terms of “cognitive tension,” this should rise over the narrative and level off after the peak and resolve.
For this article, 15 transcripts were collected from full episodes of Mountain Men (History Channel) hosted on YouTube. Before any analysis was done, I speculated that the transcripts would be fairly sparse (so much of a story on video is told through visuals and non-verbal sounds and facial expressions and editing/framing). I thought that there would be multiple staging given the episodic nature of the videos (with several thematically interweaving narratives occurring at the same time). Given the life-and-death drama of the show, I thought that the plot would be full of action words, and I also thought that the cognitive tension would continuously rise across the segments.
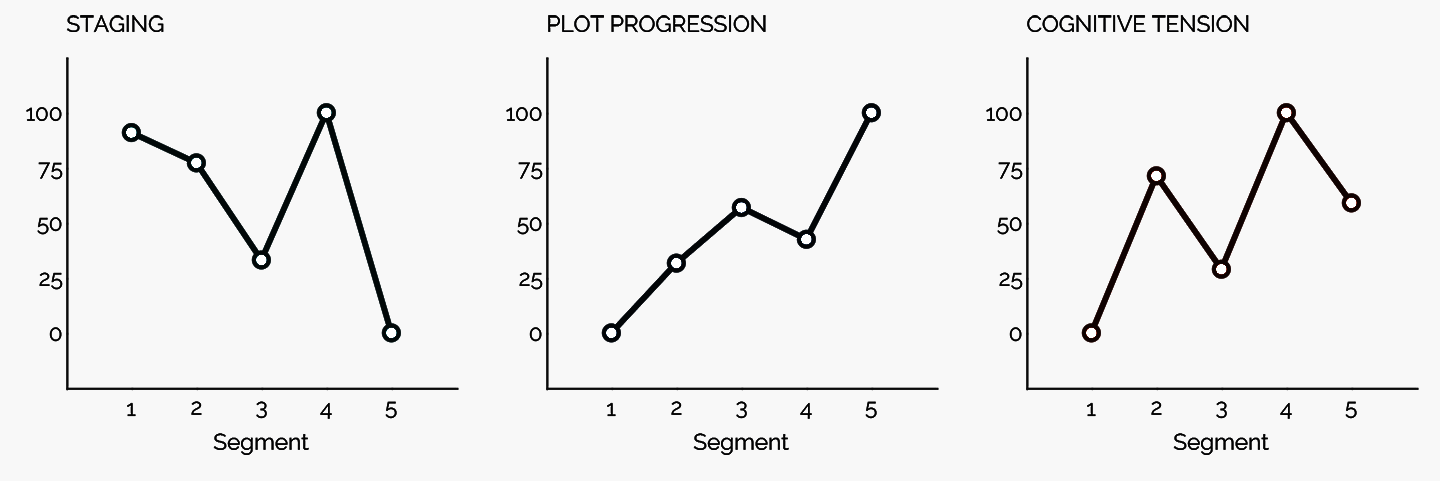
So what did I find? The staging seemed somewhat sparse, but it did start high and taper off. It looked like there were two main staging period in the television show transcripts. The action words in the “plot progression” did show rising action. The action did start off slow in the first fifth segment. The cognitive tension, interestingly, bounced. The overall trajectory was to rise, but there were several rises and falls, which makes sense with the episodic stories told in bits.
The trajectories may be seen in the so-called Arc of Narrative (AON) graphs, as may be seen in Figure 1. [The LIWC “AON” graphs are not to be confused with the “activity on node” ones, which are used for project planning and management, and which are used to compute the shortest and longest times a complex project may take.]
The Narrative Arc analysis in LIWC-22 can be applied in many different ways.
Some early ideas were shared in May in “Mapping Narrative Structures w/ Computational Text Analysis (LIWC-22).”
It will be interesting to see what researchers do as this tool feature is adopted further.
{kind=link}
Computational text analysis offers one way to better read into people’s language-based expressions. And of the various tools used for various types of computational text analysis, Linguistic Inquiry and Word Count (LIWC-22), pronounced “luke,” was initially applied from 1992 – 1994 (Tausczik & Pennbaker, 2010, p. 28). It was made public sometime in mid-1990 (Hai-Jew, May 15, 2016). LIWC is one of the foremost tools in use today (and one of the best and transparently documented instruments, with measures for construct validity, reliability, and other factors). Beyond the classic linguistic analysis and word count, there have been a range of built-in validated psychometric tools in LIWC.
Various Applications of LIWC in the Academic Research Literature
A review of some of the literature in which LIWC was used shows applications for deception analysis, authorship analysis, social relationship exploration, suicide prediction, fraud detection, remote profiling, and numerous other applications.
Easy-to-Use
Besides its track record, it is very easy-to-use. The published manuals about the tool are solid and easy-to-understand. The tool does not save the data internally, though, and it does require dumping the information out in Excel for data visualizations and analysis.
While the built-in dictionary is not available to view or edit, users of LIWC-22 may make their own dedicated dictionaries. And many have shared their dictionaries (.dic format) online via the LIWC site.
The latest release after the 2015 one is LIWC-22, which was released in early 2022. The cost is still very reasonable, on a type of sliding scale, at least for the academic or educational license. This version includes a feature for narrative analysis, and there is a forthcoming capability for authorship analysis.
Narrative Analysis
Storytelling is considered the oldest form of information exchange for humanity. The telling of stories is seen as a natural and common way for information to be shared. A typical story is comprised of a beginning, a middle, and an end. Typically, the early part of a story is used to set the stage. Then tension builds over time as the character or various characters strive to achieve their objectives. Then, there is a moment of denouement and then a release. The cultural practices of storytelling in every society means that there may be some level of predictability in the writing. The prior describes the typical approaches for linear or chronological storytelling, but that is not to say that there aren’t various non-linear types of storytelling (such as looping time stories, flashbacks, and others).
The narrative analysis splits a text into five segments (although this parameter may be changed in the tool), which are then analyzed across three dimensions. “Staging” refers to language that is used to set a scene (introducing characters, introducing the context). “Plot progression” refers to action verbs and language that show action occurring. “Cognitive tension” refers to language that shows the building up of tension and the release of tension.
A minimum of 250 words per “document” are thought to be necessary so the technology has at least 50 words to work with per each 20% segment. [This may mean that microblogging messages may be too short to treat as individual documents for narrative analysis. I had tried some six-word novels during SIDLIT 2022 and could not get the system to work, for example.] For very long documents, perhaps it would make more sense to have more than five segments, in order to capture more of the granular changes across the three dimensions, in ways that track and map.
So how do these three elements apply to narration (storytelling)? Basically, texts that hew closely to narratives have a high level of “staging” language early on, and then the staging drops off as it becomes less important. (The scene is already set by the midpoint or earlier of a classic story.) “Plot progressions” are supposed to build in action over time and perhaps level off near the end (unless the story ends with a crescendo of action). In terms of “cognitive tension,” this should rise over the narrative and level off after the peak and resolve.
An Informal Narrativity “Experiment”
For this article, 15 transcripts were collected from full episodes of Mountain Men (History Channel) hosted on YouTube. Before any analysis was done, I speculated that the transcripts would be fairly sparse (so much of a story on video is told through visuals and non-verbal sounds and facial expressions and editing/framing). I thought that there would be multiple staging given the episodic nature of the videos (with several thematically interweaving narratives occurring at the same time). Given the life-and-death drama of the show, I thought that the plot would be full of action words, and I also thought that the cognitive tension would continuously rise across the segments.
So what did I find? The staging seemed somewhat sparse, but it did start high and taper off. It looked like there were two main staging period in the television show transcripts. The action words in the “plot progression” did show rising action. The action did start off slow in the first fifth segment. The cognitive tension, interestingly, bounced. The overall trajectory was to rise, but there were several rises and falls, which makes sense with the episodic stories told in bits.
The trajectories may be seen in the so-called Arc of Narrative (AON) graphs, as may be seen in Figure 1. [The LIWC “AON” graphs are not to be confused with the “activity on node” ones, which are used for project planning and management, and which are used to compute the shortest and longest times a complex project may take.]
Figure 1. An Arc of Narrative Graph from LIWC-22 (for "Mountain Men" transcripts)
{kind=link}
Applications of the Narrative Arc Analysis in Research
The Narrative Arc analysis in LIWC-22 can be applied in many different ways.
- How do various genres of textual content stack up in terms of alignment with narrations? Songs? Poems? Advertisements? Love letters? Novels? Jokes? Microblogging messages? Poststreams?
- What about how collaborative teams write novels on the Social Web?
- What about speechwriters in different contexts?
- What about particular authors…of short stories?
- What about various types of “fund me” gambits?
- What types of comparatives are possible, such as between authors? Genres between cultures? Particular works vs. other works?
- And so on…
Some early ideas were shared in May in “Mapping Narrative Structures w/ Computational Text Analysis (LIWC-22).”
It will be interesting to see what researchers do as this tool feature is adopted further.
References
Boyd, R.L., Ashokkumar, A., Seraj, S., & Pennebaker, J.W. (2022, Feb.) The development and psychometric properties of LIWC-22. Austin, TX: University of Texas at Austin. https://www.liwc.app/. Retrieved Aug. 18, 2022, from https://www.researchgate.net/publication/358725479_The_Development_and_Psychometric_Properties_of_LIWC-22.
Hai-Jew, S. (2016, May 15). LIWC-ing at texts for insights from linguistic patterns. Summer Institute on Distance Learning and Instructional Technology. Retrieved Aug. 18, 2022, from https://www.slideshare.net/ShalinHaiJew/liwcing-at-texts-for-insights-from-linguistic-patterns.
Tausczik, Y.R. & Pennbaker, J.W. (2010). The psychological meaning of words: LIWC and computerized text analysis methods. Journal of Language and Social Psychology, 29(1), 24 – 54. Retrieved Aug. 18, 2022, from https://www.cs.cmu.edu/~ylataus/files/TausczikPennebaker2010.pdf.
Shalin Hai-Jew works as an instructional designer at Kansas State University. Her email is shalin@ksu.edu.
Hai-Jew, S. (2016, May 15). LIWC-ing at texts for insights from linguistic patterns. Summer Institute on Distance Learning and Instructional Technology. Retrieved Aug. 18, 2022, from https://www.slideshare.net/ShalinHaiJew/liwcing-at-texts-for-insights-from-linguistic-patterns.
Tausczik, Y.R. & Pennbaker, J.W. (2010). The psychological meaning of words: LIWC and computerized text analysis methods. Journal of Language and Social Psychology, 29(1), 24 – 54. Retrieved Aug. 18, 2022, from https://www.cs.cmu.edu/~ylataus/files/TausczikPennebaker2010.pdf.
About the Author
Shalin Hai-Jew works as an instructional designer at Kansas State University. Her email is shalin@ksu.edu.
| Previous page on path | Cover, page 9 of 22 | Next page on path |
Discussion of "Applying LIWC-22 for computational narrative analysis"
Add your voice to this discussion.
Checking your signed in status ...