Extracting Human Sentiment from Text Sets with NVivo 11 Plus
By Shalin Hai-Jew, Kansas State University
A new feature in NVivo 11 Plus enables the extraction of sentiment from machine-readable text sets. Some commonly analyzed text sets include formal research articles based on particular topics and social media data sets (like Twitter Tweetstreams or Facebook posts, crowd-sourced Wikipedia articles, and others). The use of machine reading of aspects of unlabeled (and unstructured) texts enable scalability and speed for human analysis.
In this context, the text sets may come in a variety of file formats: .doc, .docx, .txt, .rtf, .pdf, .xl, .xlsx, and so on. As long as the texts are machine-readable (“searchable”), they may be ingested into an NVivo 11 Plus project and auto-analyzed for sentiment and also for embedded themes and subthemes.
What is Sentiment Analysis?
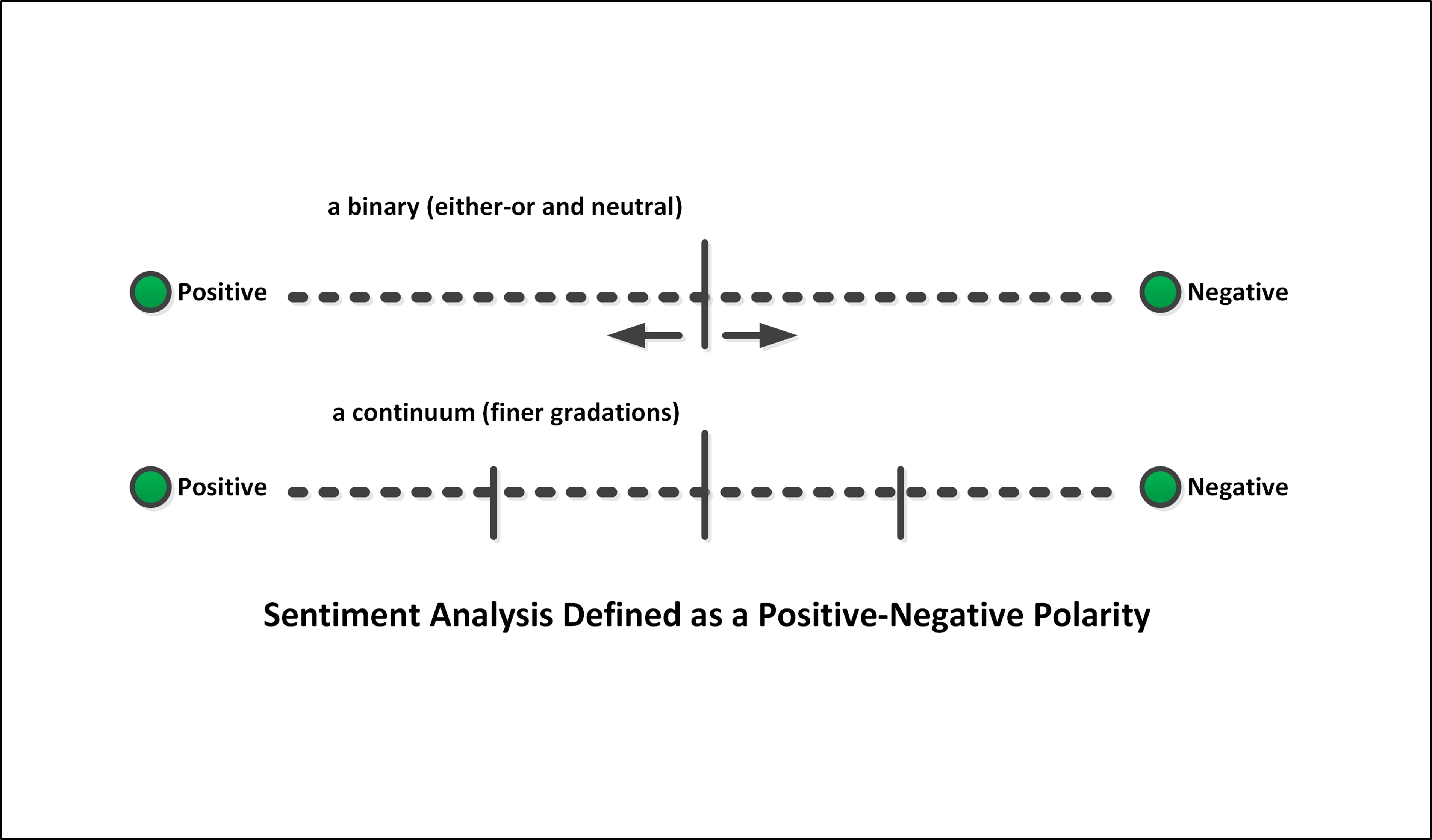
“Sentiment analysis” has historically been referred to as “opinion mining”. “Sentiment analysis,” as understood in a computational context, basically involves the detection of polarity, where one pole is positive (+) and the other is negative (-). While there are a variety of algorithms that deal with sentiment, some very common methods involve human-coded dictionaries or word sets in which terms have an inherent positive-negative polarity. As depicted in Figure 1, a coarse separation may be between a binary “positive” or “negative,” with a third set of uncoded “neutral” words…or a continuum approach with finer degrees of positive or negative polarity. (Some sentiment research includes a category of "bipolar" meaning both highly positive and highly negative--to add to positive, negative, and neutral.) In this latter case, words fit into certain categories of intensities of positive or negative.
Over the years, sentiment labeling has become more fine-tuned, with methods for identifying and considering humor, sarcasm, and irony. There are ways to capture the opposite of what a target sentiment word might indicate: for example, a person may write that he or she is “not unhappy”—with the “not” changing the direction of the “unhappy” but also restraining the positiveness in a way that would not happen with something simple such as that he or she is “happy.” (This is known as "negation detection.")
Communications via social media are considered a sub-language of the natural language language set. Of late, there has also been tuning to include the original aspects of social media-based communications, like hashtag (#) use, newly coined terms, shorthand, keywords, emoticons, and other aspects. There may also be sentiment riding on the URLs mentioned in the messaging as well as the images, the audio, the video, and other integrated multimedia. On Twitter, messages also often contain multiple languages, as represented by the UTF-8 character set of Unicode.
[As an aside, the research field itself has moved into other areas—such as using machine learning to differentiate the amounts of objectivity or subjectivity in documents, analyzing various qualities of emotions in texts, profiling text sets for author personality and author psychological states (such as whether they're depressed or not), and other applications. These are spin-offs from the early sentiment analysis research, which dates to early 2000.]
{kind=link}
Figure 1: Sentiment Analysis Designed as a Positive-Negative Polarity
To understand why such analyses can work fairly well—to a degree—it helps to understand that meaning is encoded into language in a generalist way that enable people from a wide range of backgrounds, ages, cultures, and such, to share information. Without that consistency of shared rules of language, people would have problems communicating at various points of encoding meaning into words and decoding meaning from words.
NVivo 11 Plus
It takes a little adjustment for people used to close (human) reading of texts to benefit from machine-based reading. NVivo 11 Plus is designed to be an easy-to-use software tool, but its makers do not necessarily shed light on what is going on algorithmically under the hood.
Automated sentiment identification. Essentially, this software tool categorizes semantic or content-bearing text into four categories: very negative, moderately negative, moderately positive, and very positive. Based on Figure 1, NVivo 11 Plus uses a sentiment dictionary and an algorithmic method that applies varying sentiment weights to the found text. In terms of text analyses, there are “stop words” list automatically applied to words which do not carry sentiment-relevant meaning.
Automated theme and subtheme extraction. The other new feature in NVivo 11 Plus involves automated theme extraction from a text document or text corpora (text set). This feature seems to combine a word frequency count over the semantic words in a text corpus and then a proximity search for those terms to set up a nested text structure showing the main concepts and their related sub-concepts.
Two Weather-Based Social Media Account Targets
Social media is thought to offer opinion-rich texts, particularly in terms of reviews, postings, microblogging messages, and other elements. The “holy grail” of marketing is to pursue messages and digital content that goes “viral,” and researchers have been able to describe the types of messages that actually go viral: to wit, the message has to be provocative, attention-getting, and either funny or sexy (or both). A viral message is quite rare because it has to escape the gravitational pull of a particular interest silo, and it has to spread quickly across a number of interest communities shortly after its release. Most shared contents on social media end up in the “long tail,” and only a few messengers and a few messages reach a wide audience. Information that has been out in-the-wild tends to remain inert and unseen in a competitive attention economy.
To provide a sense of how this all works, two different Tweetstreams were extracted: one for the National Weather Service (@NWS at https://twitter.com/nws) and one for the Weather Channel (@WeatherChannel at https://twitter.com/weatherchannel). At the time of the data extractions, the National Weather Service had 9,705 Tweets, 278 following, 233, 111 followers, 7 likes, and 1 list. The Weather Channel had 58,032 Tweets, 6,824 following, 1.09 million followers, 5,853 likes, and 26 lists. For the @NWS account, 2,813 recent messages were extracted; for the @WeatherChannel account, 2,325 recent messages were extracted.
These two social media accounts on the Twitter microblogging site were selected as convenience samples. For the @NWS, NodeXL Basic (Network Overview, Discovery and Exploration for Excel Basic) was used to extract the data based on a search of “@NWS” on Twitter; this was tried after NCapture was used to try to extract the Tweetstream but failed due to an apparent setting on the @NWS account. For the @WeatherChannel, the NCapture web browser add-on to Chrome was used, which enabled access to the data and easier ingestion directly into NVivo (as both tools are made by QSR International). Because there were two different methods for the extraction of the data, the datasets are not directly comparable even though both sets were collected at about the same time. Twitter rate-limits such data extractions, and those who control the accounts may place some limits on data access. In both datasets, retweets were included.
The General Steps to the Sentiment Identification and Theme and Subtheme Extractions in NVivo 11 Plus
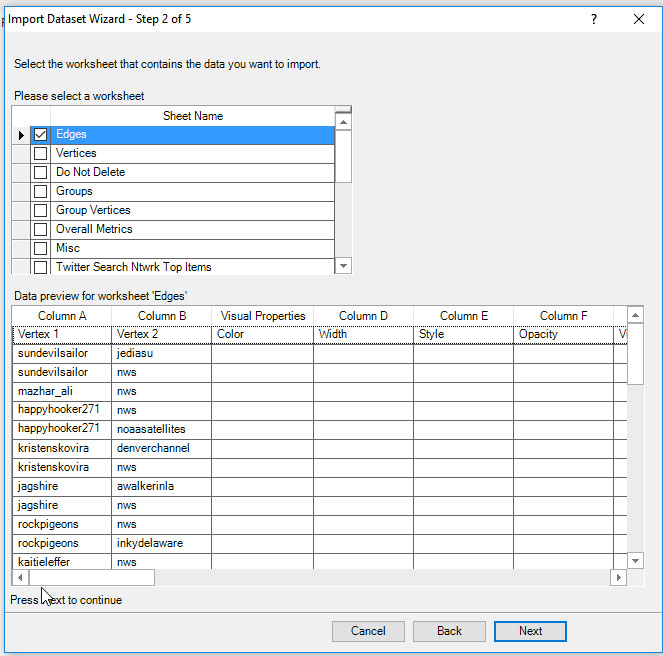
This section summarizes the work of extracting the social media data and then running the data through sentiment analyses and theme extractions. The first sequence deals with the recent and partial @NWS Twitter Tweetstream, and the latter deals with the @WeatherChannel Twitter Tweetstream. Figure 2 shows the importation of data from the @NWS Twitter Tweetstream (with the .xlsx data created in NodeXL and Excel).
{kind=link}
Figure 2: Importing NodeXL Data into the NVivo 11 Plus Project
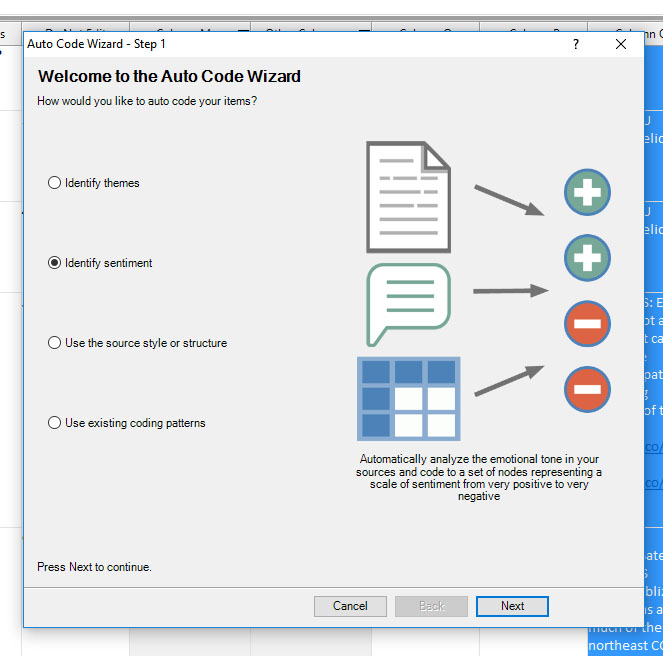
Once the data has been acquired and ingested into NVivo, a user highlights the file and turns on the Auto Code Wizard. Then, he or she selects “Identify sentiment” in order to start the process of running a sentiment analysis on the ingested text. The first screen of this process may be seen in Figure 3.
{kind=link}
Figure 3: The Auto Code Wizard and the "Identify Sentiment" Option
In Figure 4, the ingested Tweetstream with the Tweets is identified as the target of the sentiment analysis.
{kind=link}
Figure 4: Selecting the Tweet Column of @NWS Messages (2,813)
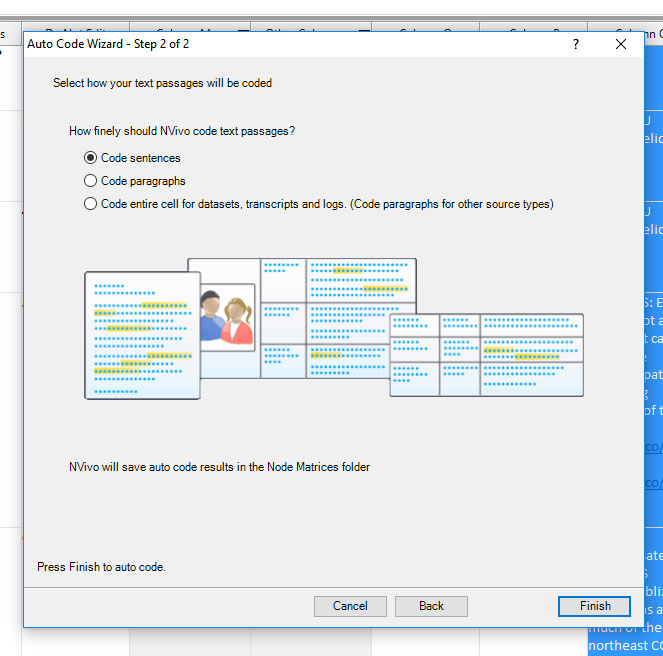
In Figure 5, a user may select to code the text at one of three levels of analysis: sentence-level, paragraph-level, or cell level. (Both of these datasets were processed at the cell level, with the idea that the short texts of microblogging messages may best be handled at the cell level of the data.)
{kind=link}
Figure 5: The Option to Code Sentences, Paragraphs, or All Cells (in the Auto Code Wizard)
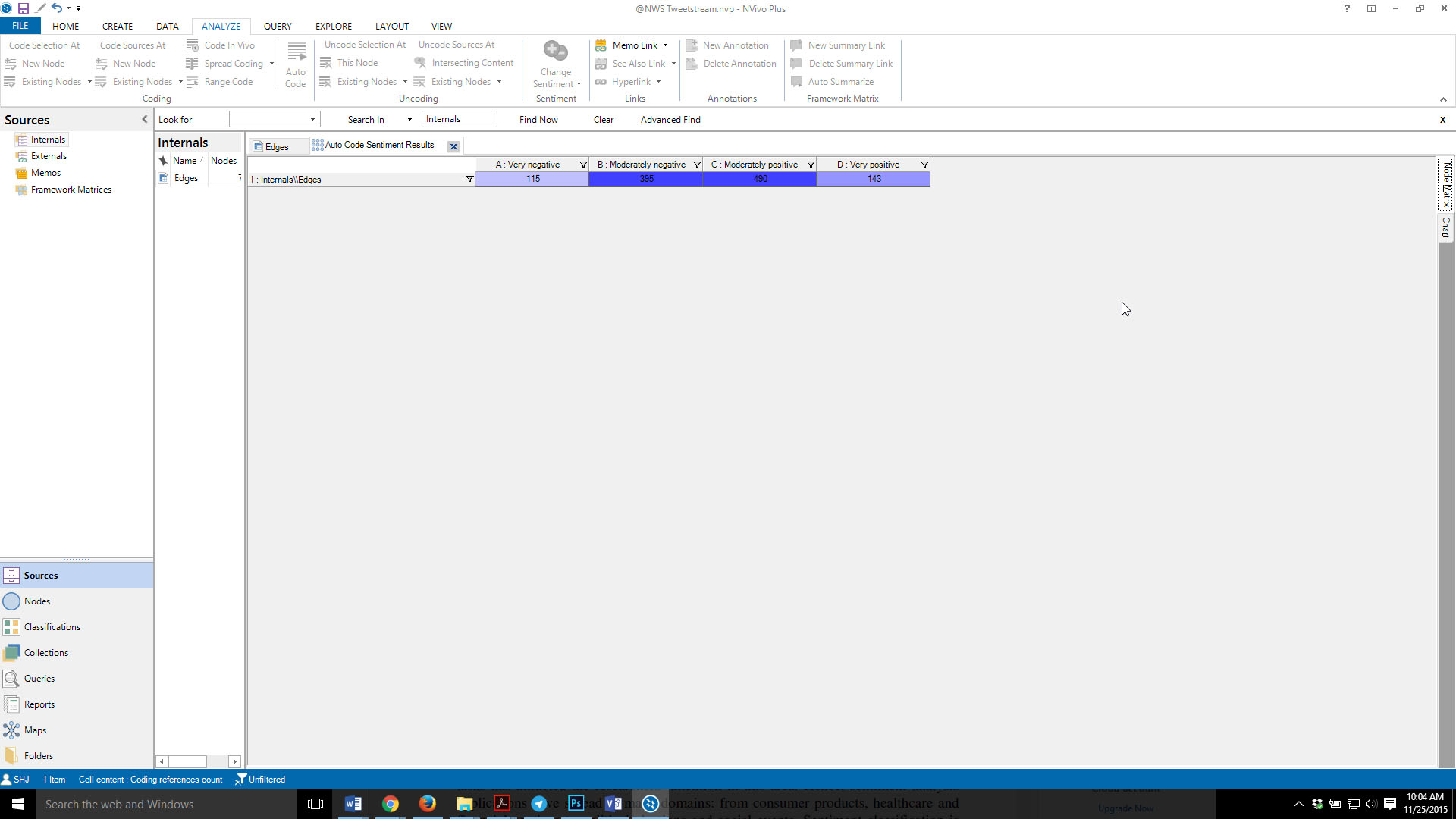
On finishing the setup, NVivo 11 Plus applies the sentiment analysis, and the first screen involves the depiction of an “intensity matrix” depicting sentiment. The degree of sentiment is represented both as a number in a particular cell and as the intensity of the color in the particular cell.
{kind=link}
Figure 6: An Intensity Matrix from the @NWS Tweetstream
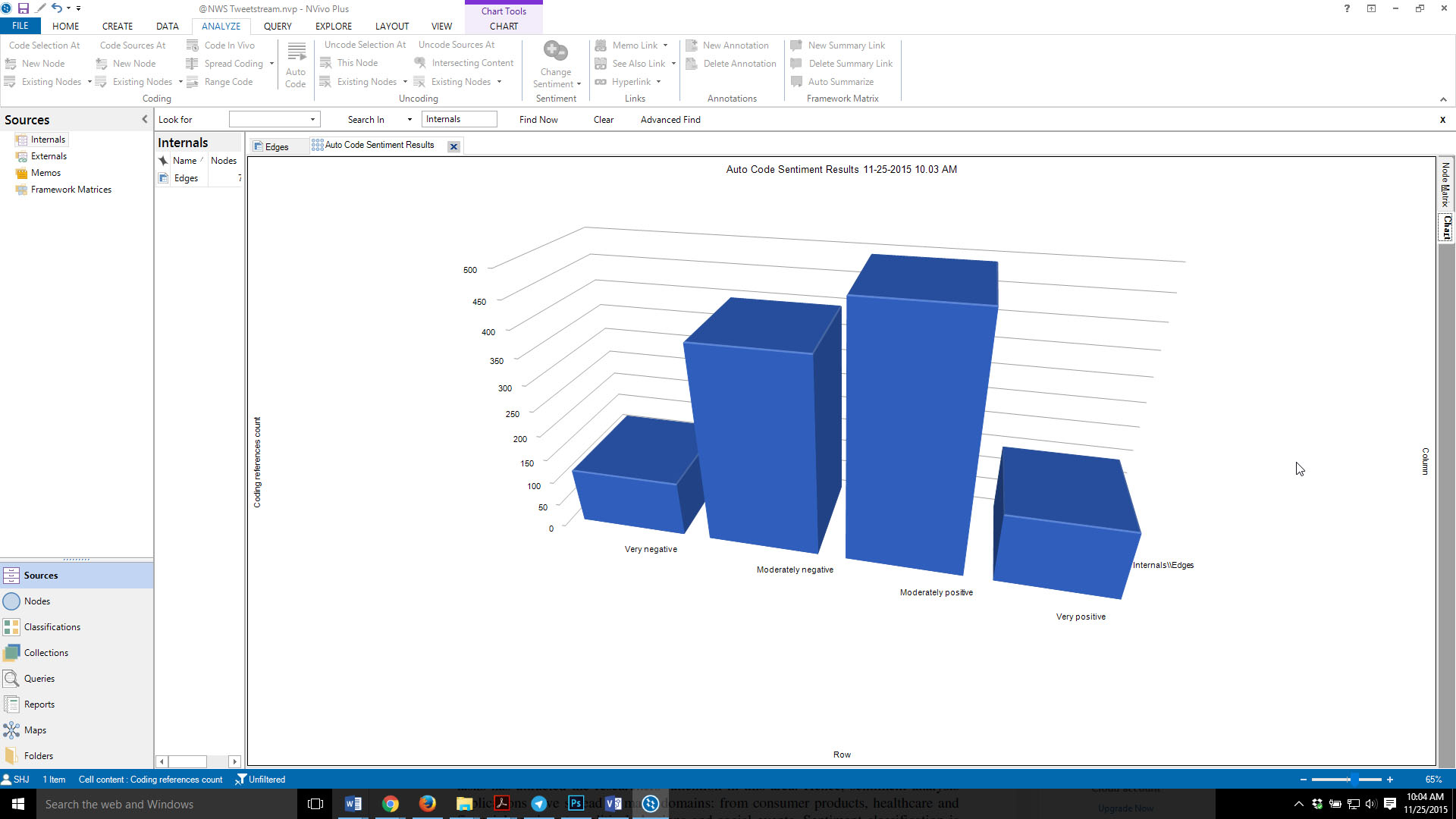
The intensity matrix may be turned into a bar chart, which lists the “very negative,” “moderately negative,” “moderately positive,” and “very positive” from left to right.
{kind=link}
Figure 7: Sentiment Bar Chart from the @NWS Tweetstream
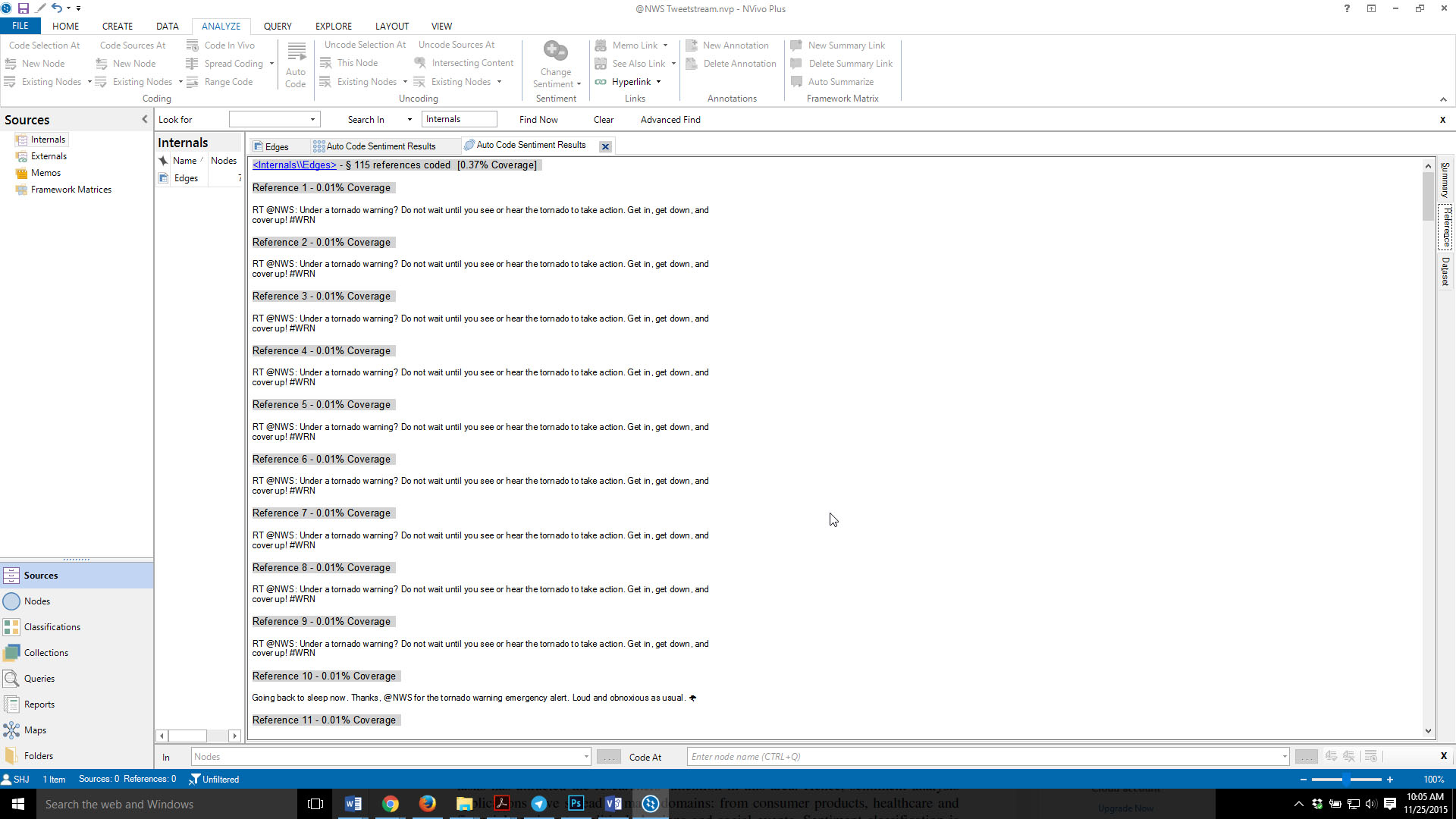
Figure 8 shows the text set for the “very negative” category in the @NWS Tweetstream dataset. Being able to explore the topics in the respective data sets enables researchers to conduct word frequency counts and text searches to the data. In other words, assuming that the sentiment coding is correct, what are the main topics seen in negative light? What is being said about the topics that are seen in negative light?
In NVivo 11 Plus, it is possible to hand-correct the machine coding by uncoding texts (to not fit into any of the four sentiment categories) and recoding others to their “proper” categories. A particular sequence of text may be coded to multiple sentiment categories simultaneously. Often, what a machine labels a particular way does not make human sense…or does not make sense for the particular data set. Such data post-processing may change the respective contents in each sentiment category and the overall counts. (Also, this work does not mention data pre-processing, which can also change the outcomes of both the sentiment analysis and the theme and subtheme extraction.)
That said, users of the software cannot change the labeling of the sentiment in the sentiment dictionary (or sentiment set) against which other sets of text will be compared…and categories created. In other words, it is not possible to customize the sentiment dictionary at present. Also, it is not currently possible to apply unique lexicon sets (used in particular research domains) for machine reading and machine application of sentiment in NVivo 11 Plus.
Finally, it also helps to note that human “close reading” can be highly beneficial for ferreting out human intentions and meanings, beyond a surface or summary level of analysis. Close readings also bring in the targeted expertise of the human analyst.
{kind=link}
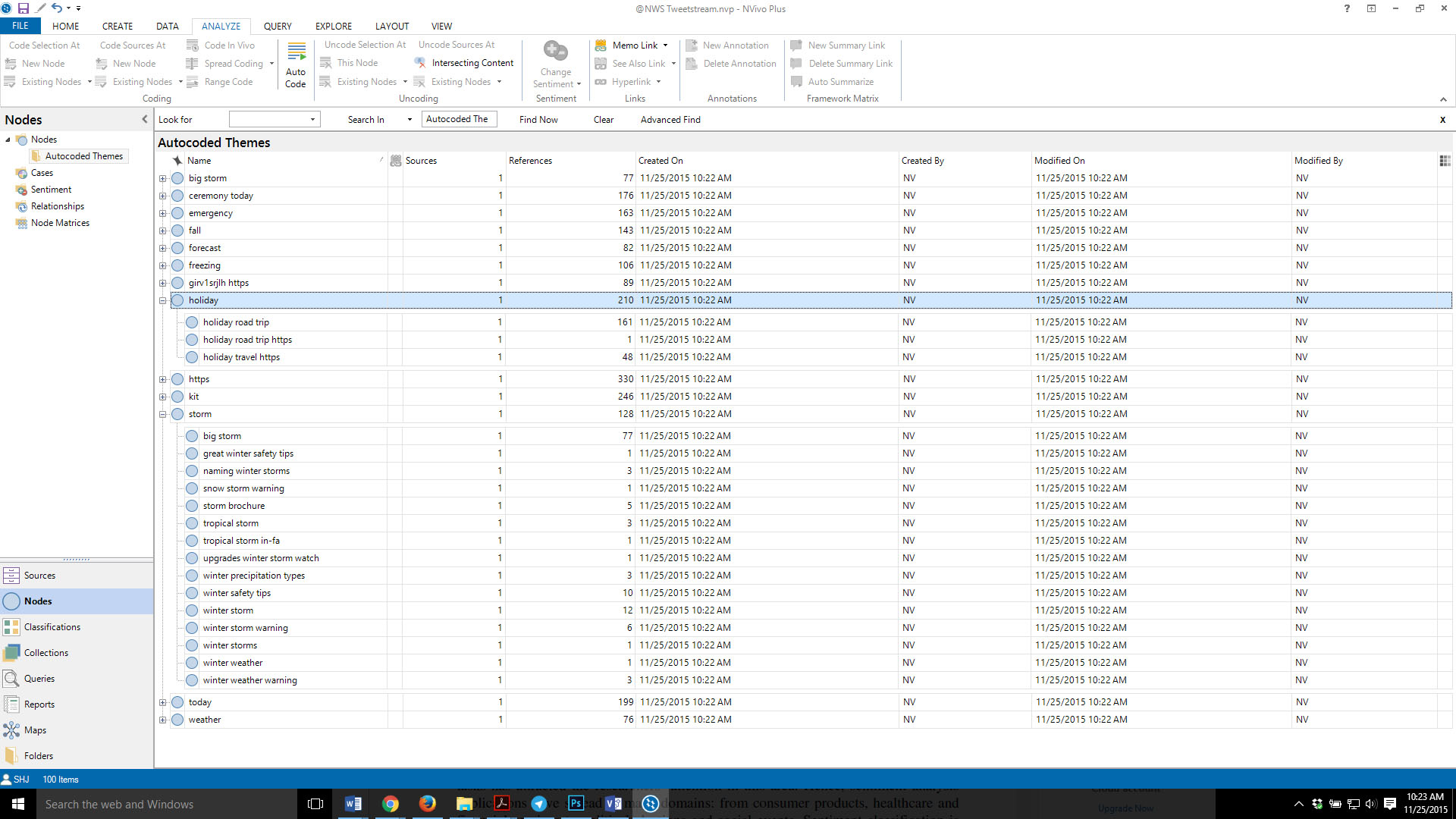
Figure 9 shows the results of the automated theme and subtheme extraction from the @NWS Tweetstream. In NVivo, it is possible to remove particular themes or subthemes that do not seem relevant to the human coder before the themes and subthemes are finalized. (Of course, even if the themes and subthemes are coded completely, they may still be removed later.) The topics include: big storm, ceremony today, emergency, fall, forecast, freezing, holiday, https, kit, storm, today, and weather.
{kind=link}
Figure 9: Automatically Extracted Themes from the @NWS Twitter Search Data
In Figure 10, the sentiment bar chart from the @WeatherChannel Tweetstream is depicted.
{kind=link}
Figure 10: @WeatherChannel Tweetstream Sentiment Bar Chart
A theme and subtheme extraction from the @WeatherChannel Tweetstream may be seen in Figure 11. The theme analysis (in descending order vs. alphabetical order) include the following: warning, tornado, tornado warning, https, and storm.
{kind=link}
Figure 11: Autocoded Themes and Subthemes from the @WeatherChannel Tweetstream
In Figure 12, there is a sociogram of the @WeatherChannel Tweetstream. Here, the nodes are the entities (social media accounts on Twitter), and the links show direct messaging between the nodes (which indicate shared replies or messaging). This essentially shows the “ego neighborhood” for the @WeatherChannel account in terms of recent messaging.
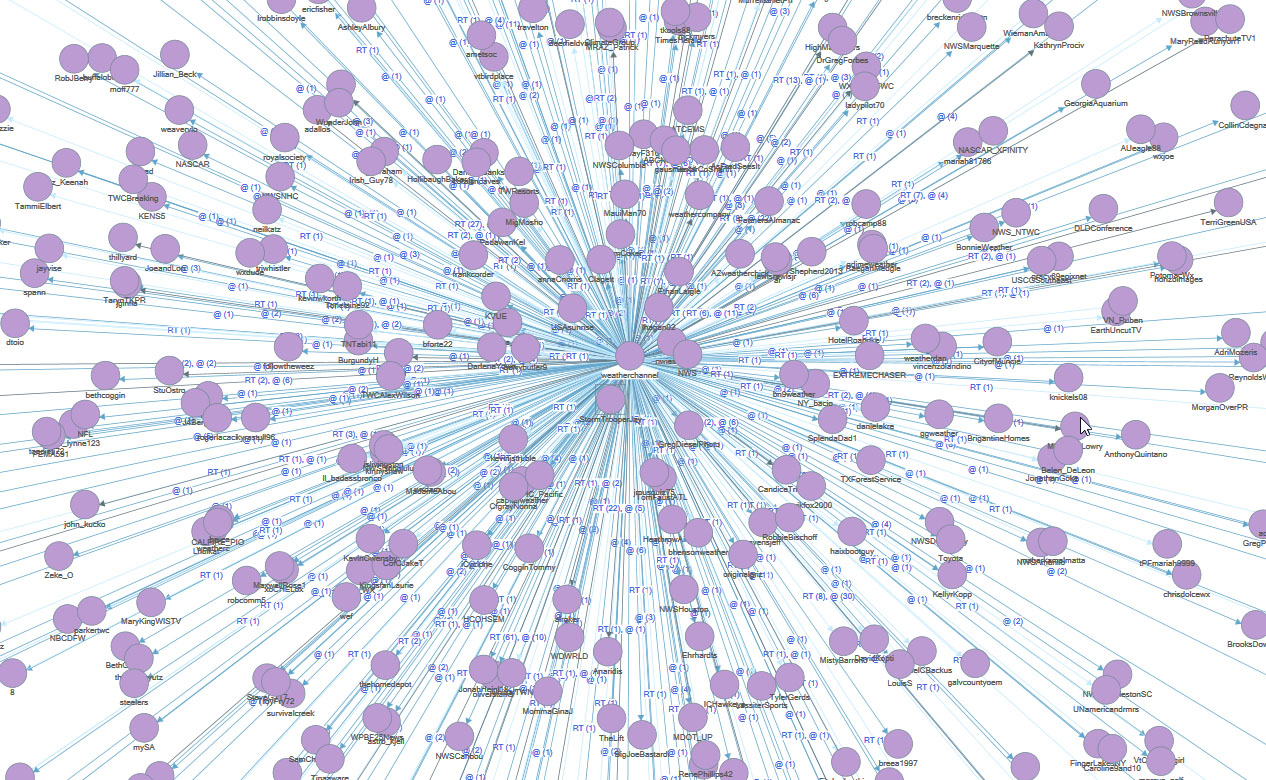{kind=link}
Figure 12: The @WeatherChannel Sociogram Extracted from the Official Tweetstream
Some Practical Applications of Sentiment Analysis Using NVivo 11 Plus
Human sentiment plays a fairly important role in decision-making and actions. Keeping tabs on what is being messaged online might reveal the temperature of an issue and may enable predictions; such awareness of people’s attitudes and thoughts may enable counter-messaging.
Individuals who run social media companies have explored how people in various demographic groups self-represent and intercommunicate with others based on the social constructs of identity and culture and other factors. One of the co-founders of OKCupid has captured how males and females from various demographic groups in the U.S. identify themselves and what they look for in dates (Rudder, 2014). Researchers break apart datasets into demographic groups to capture their sentiments at their sub-group levels. Regional groups are also extracted. They also extract clusters that are identifiable in the data in order to find patterns inherent in the data (such as similar language clusters or similar sentiment clusters, and others).
Social science research has long been holding up a mirror to how people socialize, think, and behave in groups. One long-running insight has been that people make decisions and act on their feelings, which are fairly deeply integrated with their perceptions, memory, and cognition. People, though, do not tend to be very aware of what influences them, with much affecting people’s decisions subliminally (Mlodinow, 2012). The science of influence works in both levels of human consciousness and unconsciousness and is a potent field, with efforts in the private (marketing and advertising, commerce, service provision) and public sectors (politics, governance, law enforcement.
References
Mlodinow, L. (2012). Subliminal: How your Unconscious Mind Rules your Behavior. New York: Pantheon Books.
Rudder, C. (2014). Dataclysm: Who We Are When We Think No One’s Looking. New York: Crown Publishers.
For More
About the Author
Shalin Hai-Jew works as an instructional designer at Kansas State University. Dr. Hai-Jew may be reached at shalin@k-state.edu.
| Previous page on path | Issue Navigation, page 16 of 26 | Next page on path |
Discussion of "Extracting Human Sentiment from Text Sets with NVivo 11 Plus"
Add your voice to this discussion.
Checking your signed in status ...