Book review: Computational learning from online human connectivity
By Shalin Hai-Jew, Kansas State University
Online Social Networks: Perspectives, Applications and Developments
Chee Wei Tan, Editor
Nova Science Publishers
2020
217 pp.
Chee Wei Tan, editor of Online Social Networks: Perspectives, Applications and Developments (2020), explores how remote online social connectivity between peoples may be studied for deeper insights, based on various computational social network analysis approaches. Social networks in visual form are intuitively available and understandable. They are widely consumed in this social-digital age.
However, less common are understandings of the technical side of arriving at the respective social networks and the related data. This collection involves research works in which individuals and teams identify a need in the social networking space, which they then address as computer scientists and programmers. More often than not, they test their program against synthetic and / or non-synthetic real-world datasets and evaluate the accuracy and efficiency of their program, sometimes in competition with others’ assessed programs (and performance metrics).
These chapters build their explications on the following:
These are interesting in terms of high precision and rigor; after all, other researchers are often told enough about the processes and methods of the authors to emulate their work, if needed. However, those who are not active in the field would have a hard time parsing out the various aspects. An elementary or functional understanding of social network analysis may provide a bridge into the text, but that approach is still limited. It also helps to think abstractly and to read persistently although these approaches alone do not make up for a lack of expertise. Some of the writing is too complex and difficult to truly understand for a non-computer-scientist. So with these caveats, what follows involves a light descriptive review.
Social networks are often represented as node-link or vertex-edge diagrams, in 2d or 3d. Each node represents an ego (or entity), and each link represents some sort of relationship or tie. The intensity of the relationship may be indicated by line thickness or some annotation indicating the connection. The lines may have arrows for directed graphs to show the directionality of the relationship. Undirected graphs have links that do not have arrows on either end.
Social network analysis (SNA) provides various ways to describe the egos (based on various attributes and their roles within their social networks). High-degree egos are major individuals through whom much information flows. In a social hierarchy, information flows up to those in power but not down, in general. Such egos are influential in the network. High-centrality egos are those that are core to a social network. SNA also enables ways to understand the relating between the respective nodes. Isolate nodes are those who may not choose to belong or who are not included.
Social habits of relating often move through formal and informal relationships, often requiring some level of trust. Various relationships between nodes may be mapped in links. Links indicate how information and resources move through a network, the powerful egos and entities in social relationships who have wide influence, the average length of time of relationships, how to break social networks (such as malicious ones), and other phenomena. Belonging to a social network can benefit members through mutual supports and resource sharing, but belonging may also entail costs and requirements for membership. Links or edges have their own attributes as well, based on collectible information.
Social networks evolve and change over time. They emerge to meet common interests, thrive for a time, and eventually sunset (often when shared interests no longer exist).
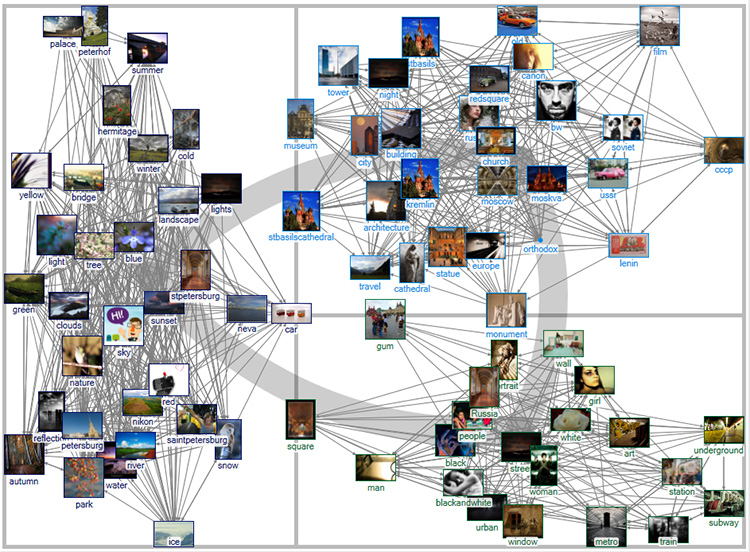
On social media, which has been so critical for human well-being and connectivity during the pandemic, various trace data may be harvested for social network analysis. Mixed in the data may be the scripted agents or social ‘bots that are used to engage people en masse. Social media enable other types of network graphs, such as between tags in an image-sharing site. (Figure 1)
Cheng-Shang Chang, Ching-Chu Huang, Chia-Tai Chang, Duan-Shin Lee, and Ping-En Lu’s “Generalized Modularity Embedding: A General Framework for Network Embedding” (Ch. 1) addresses the “network embedding problem” to map nodes similar to each other “to vectors in a Euclidean space that are close to each other” (p. 1) visually. The researchers argue for “using the generalized modularity matrix for network embedding,” and treating this challenge as “a trace maximization problem like the community detection problem” (p. 1). How to identify similar nodes may be understood differently by focusing on different dimensions and attributes of the respective nodes and perhaps actions and behaviors. This research team explains their rationales in designing their particular approach to understanding network embedding from various datasets, with the highest accuracy and computational efficiency possible. They run their program on various datasets to test the outcomes. A theorem proof is offered in the appendices.
Roxana Alexandru and Pier Luigi Dragotti “Epidemic Source Detection in Complex Networks” (Ch. 2) propose a method to understand various diffusive or propagation phenomena on social networks. The diffused materials may be rumors, computer viruses, ads, failure messages in sensor networks, or other contents. Their approach is informed by traces of the infection on the nodes of complex networks. They write: “…given observed traces of infection at some nodes in the network…the probability of correctly detecting the diffusion source is high, in both synthetic as well as real-world graphs” (p. 31). The researchers note that large-scale graphs are too big to study with an N = all; rather, many approaches use partial knowledge of networks to model and predict and describe (p. 33). Their technique is to “efficiently solve the diffusion source inference problem in a general network of known topology, using multiple snapshots from a sparse set of monitors, in a fixed time window” (p. 34). The topologies refer to various node-link connectivity structures. They provide a light summary of how various “infection” models work along with some engaging visual depictions. They then describe their own approach based on deriving “the infection likelihood of a node, as a function of its shortest distance to the origin of the epidemic” (p. 38). Their approach enables the estimating of the start times of the epidemic, the identification of candidate sources (as a set) based on observed infections, and other insights.
Jinhuan Wang, Kunfeng Qiu, Yalu Shan, Qi Xuan, and Guanrong Chen’s “Subgraph Network for Expanding Structural Feature Space with Application to Graph Data Mining” (Ch. 3) takes as its inspiration mapping each node as “a subgraph of the original network” (p. 69). Their graph data mining approach using subgraph networks (SGNs) enable the classifying of nodes, ego networks, graphs and subgraphs; the predicting link weights; and other applications (pp. 69-70). Mapping subgraphs from a social network enables the exploration of local structures. This work describes their methods for building subgraphs:
They explain higher-order subgraphs:
This approach enables mapping the target social networks in layers, which provides more hierarchical and high-dimensional information. Link weights in social networks indicate “strength of friendship” and potentially other information (p. 75). Using various named datasets, the researchers test various subgraph network approaches for various tests, such as subgraph mapping, link-weight predictions, node classification, graph classification, and others, to better expand knowledge of structural feature spaces of social networks.
Feng Ji, Wenchang Tang, Jielong Yang, and Wee Peng Tay’s “Online Information Spreading and Source Identification” (Ch. 4) harnesses some different tools and methods to understand diffusion of information online. They use Bayesian inference methods and a sequential source estimation approach to track down rumor sources in an online social network. They explain early on: “For the simplest problem formulation in which only a snapshot of the infection status of the nodes in a network is available, we present various graph centrality methods and explain the motivations behind them” (p. 93). Theirs is a method to “generalize a source identification method developed for a tree network to a general graph, using the concept of Gromov matrices” (p. 93). To set a context for their work, they refer to independent cascade models of information spread. They point to various common models, including the susceptible-infection (SI) model, the susceptible-infection-recover (SIR) model, the susceptible-infection-recover-infection (SIRI) model, and the susceptible-infection-susceptible (SIS) model, which are fairly mechanistic. How something propagates through a network is understood as node-to-node transmission, with node states as either susceptible (open to infection), infected (carrying the information), or recovered (prior infected but no longer so). These models generally suggest that a sufficient level of exposure by neighboring nodes leads to infection (p. 94). While the language here is of infection by a contagious disease, the concept can apply to various things like information, emotion, cultural practices, and others. Different models may have different underlying assumptions in applications to different data and contexts. One example used in this work is of rumor-sharing via social accounts. An account is recovered if the account shared the rumor but later retracted the message, for example. The researchers run their setup based on various starting stages of the rumor; they use single-source states, multiple-source states, and multiple-source states with different start times, among others. In another round, they collected timestamp observations of first infection for the nodes and then applied Bayesian methods and sampling methods to identify potential node sources of the rumors. The Bayesian approach involves trying to understand the hidden actual state of the world given observables (the samples).
Man Fai Wong, Ching Nam Hang, and Chee Wei Tan’s “The PageRank Bipartite Graph Ranking: Online Chat Group Recommendation” (Ch. 5) explores the use of a modified version of Google’s PageRank algorithm in a recommender model for a chat group based on Tencent QQ social messaging data. The bipartite graph has nodes divided into two sets “such that no edge connects the nodes in the same group” (p. 127). From this, the various social nodes are ranked in a hierarchy, with each node assigned a number and placed in a ranking structure. While this work was to study the algorithm “for a recommendation system for chat groups in a Tencent QQ system,” the researchers did not fully explore their thinking in terms of the practical application in the context (p. 138).
Ching Nam Hang, Pei-Duo Yu, and Chee Wei Tan’s “Parallel Counting of Subgraphs in Large Graphs: Pruning and Hierarchical Clustering Algorithms” (Ch. 6) takes as its challenge the “subgraph isomorphism” problem as posed in the 2018 MIT-Amazon Graph Challenge. Their solution is “a novel joint hierarchical clustering and parallel counting framework” dubbed MEGA to compute “the exact number of triangles in large graphs” (with applications to computing across big data) (p. 141). This work describes the thinking and design process at arriving at the particular solution by the team. This work shows how readers may spark off the learning and methods of others.
Lin Ling and Chee Wei Tan’s “Social Learning Network and its Applications in Large Scale Online Education through Chatbot” (Ch. 7) focuses on social learning networks (SLNs), enabled through the advent of mobile technologies and online pedagogical methods. This research team identified two problems in the space to engage: how to optimize task scheduling “between multiple learning contents for each learner, so that the learning outcome within the limited learning time can be maximized” and how to automate the grading process in large-scale SLNs (p. 166). For their scheduler, the team brings into play deep insights about learning in the real, and they also consider the respective learning outcomes for the students in a personalized way (through three variables for the respective learners). The researchers design an automated grading system with human inputs, too. Then, they combined both systems into a mobile messenger chatbot called Nemo Bot for math learning, built in part on the Facebook Messenger platform.
Pei-Duo Yu, Chee Wei Tan, and Hung-Lin Fu’s “Rumor Source Detection in Finite Graphs with Boundary Effects by Message-Passing Algorithms” (Ch. 8) suggests the importance of taking into consideration real-world features of social networks, such as their finitude and “complex spreading behavior” in terms of information. Such boundary effects need to be considered. Their work solves “the constrained maximum likelihood estimation problem by a generalized rumor centrality for spreading in graphs with boundary effects” (p. 185) and propose a message-passing algorithm effective in this space (p. 186). This work exemplifies how there are continual efforts to improve practical computational methods with considerations for how the real world may be modeled digitally.
Chee Wei Tan’s Online Social Networks: Perspectives, Applications and Developments (2020) highlights some important works around familiar algorithms in the social network space.
The editor has multiple graduate degrees from Princeton University. He is a Professor of Computer Science at City University of H.K. Dr. Tan has earned numerous recognitions for his work.
Shalin Hai-Jew works as an instructional designer / researcher at Kansas State University. Her email is shalin@ksu.edu.
{kind=link}
Chee Wei Tan, Editor
Nova Science Publishers
2020
217 pp.
Chee Wei Tan, editor of Online Social Networks: Perspectives, Applications and Developments (2020), explores how remote online social connectivity between peoples may be studied for deeper insights, based on various computational social network analysis approaches. Social networks in visual form are intuitively available and understandable. They are widely consumed in this social-digital age.
However, less common are understandings of the technical side of arriving at the respective social networks and the related data. This collection involves research works in which individuals and teams identify a need in the social networking space, which they then address as computer scientists and programmers. More often than not, they test their program against synthetic and / or non-synthetic real-world datasets and evaluate the accuracy and efficiency of their program, sometimes in competition with others’ assessed programs (and performance metrics).
These chapters build their explications on the following:
- theorizing, conceptualizing, modeling;
- mathematical notations and equations;
- logical notation;
- algorithms;
- diagrams, data plots, visuals; and
- text.
These are interesting in terms of high precision and rigor; after all, other researchers are often told enough about the processes and methods of the authors to emulate their work, if needed. However, those who are not active in the field would have a hard time parsing out the various aspects. An elementary or functional understanding of social network analysis may provide a bridge into the text, but that approach is still limited. It also helps to think abstractly and to read persistently although these approaches alone do not make up for a lack of expertise. Some of the writing is too complex and difficult to truly understand for a non-computer-scientist. So with these caveats, what follows involves a light descriptive review.
Introduction
Social networks are often represented as node-link or vertex-edge diagrams, in 2d or 3d. Each node represents an ego (or entity), and each link represents some sort of relationship or tie. The intensity of the relationship may be indicated by line thickness or some annotation indicating the connection. The lines may have arrows for directed graphs to show the directionality of the relationship. Undirected graphs have links that do not have arrows on either end.
Social network analysis (SNA) provides various ways to describe the egos (based on various attributes and their roles within their social networks). High-degree egos are major individuals through whom much information flows. In a social hierarchy, information flows up to those in power but not down, in general. Such egos are influential in the network. High-centrality egos are those that are core to a social network. SNA also enables ways to understand the relating between the respective nodes. Isolate nodes are those who may not choose to belong or who are not included.
Social habits of relating often move through formal and informal relationships, often requiring some level of trust. Various relationships between nodes may be mapped in links. Links indicate how information and resources move through a network, the powerful egos and entities in social relationships who have wide influence, the average length of time of relationships, how to break social networks (such as malicious ones), and other phenomena. Belonging to a social network can benefit members through mutual supports and resource sharing, but belonging may also entail costs and requirements for membership. Links or edges have their own attributes as well, based on collectible information.
Social networks evolve and change over time. They emerge to meet common interests, thrive for a time, and eventually sunset (often when shared interests no longer exist).
On social media, which has been so critical for human well-being and connectivity during the pandemic, various trace data may be harvested for social network analysis. Mixed in the data may be the scripted agents or social ‘bots that are used to engage people en masse. Social media enable other types of network graphs, such as between tags in an image-sharing site. (Figure 1)
Figure 1. “Russia” Related Tags Network on Flickr (1.5 deg.)
{kind=link}
Exploring Network Embedding
Cheng-Shang Chang, Ching-Chu Huang, Chia-Tai Chang, Duan-Shin Lee, and Ping-En Lu’s “Generalized Modularity Embedding: A General Framework for Network Embedding” (Ch. 1) addresses the “network embedding problem” to map nodes similar to each other “to vectors in a Euclidean space that are close to each other” (p. 1) visually. The researchers argue for “using the generalized modularity matrix for network embedding,” and treating this challenge as “a trace maximization problem like the community detection problem” (p. 1). How to identify similar nodes may be understood differently by focusing on different dimensions and attributes of the respective nodes and perhaps actions and behaviors. This research team explains their rationales in designing their particular approach to understanding network embedding from various datasets, with the highest accuracy and computational efficiency possible. They run their program on various datasets to test the outcomes. A theorem proof is offered in the appendices.
Back-Tracing to Source(s) of Informational Epidemics
Roxana Alexandru and Pier Luigi Dragotti “Epidemic Source Detection in Complex Networks” (Ch. 2) propose a method to understand various diffusive or propagation phenomena on social networks. The diffused materials may be rumors, computer viruses, ads, failure messages in sensor networks, or other contents. Their approach is informed by traces of the infection on the nodes of complex networks. They write: “…given observed traces of infection at some nodes in the network…the probability of correctly detecting the diffusion source is high, in both synthetic as well as real-world graphs” (p. 31). The researchers note that large-scale graphs are too big to study with an N = all; rather, many approaches use partial knowledge of networks to model and predict and describe (p. 33). Their technique is to “efficiently solve the diffusion source inference problem in a general network of known topology, using multiple snapshots from a sparse set of monitors, in a fixed time window” (p. 34). The topologies refer to various node-link connectivity structures. They provide a light summary of how various “infection” models work along with some engaging visual depictions. They then describe their own approach based on deriving “the infection likelihood of a node, as a function of its shortest distance to the origin of the epidemic” (p. 38). Their approach enables the estimating of the start times of the epidemic, the identification of candidate sources (as a set) based on observed infections, and other insights.
Expanding the Social Network Structural Feature Space through Subgraph Networks
Jinhuan Wang, Kunfeng Qiu, Yalu Shan, Qi Xuan, and Guanrong Chen’s “Subgraph Network for Expanding Structural Feature Space with Application to Graph Data Mining” (Ch. 3) takes as its inspiration mapping each node as “a subgraph of the original network” (p. 69). Their graph data mining approach using subgraph networks (SGNs) enable the classifying of nodes, ego networks, graphs and subgraphs; the predicting link weights; and other applications (pp. 69-70). Mapping subgraphs from a social network enables the exploration of local structures. This work describes their methods for building subgraphs:
In the first-order case, a line is chosen as a subgraph, based on which SGN is built, denoted by SGN. The first-order SGN is also known as a line graph, where the nodes are the links in the original network, and two nodes are connected if the corresponding links share a same terminal node. (Wang, Qiu, Shan, Xuan, & Chen, 2020, p. 72)
They explain higher-order subgraphs:
In the second-order case, higher-order subgraphs are constructed by taking into consideration the connection patterns between the three nodes. There are more diverse connection patterns among three nodes than the case of two nodes. In theory, there are 13 possible non-isomorphic connection patterns among three nodes in a directed network. This number decreases to 2 in an undirected network, namely only open and closed triangles. Here, only connected subgraphs are considered, while those with less than two links are ignored. Compared with lines, triangles can provide more insights about the local structure of a network. (Wang, Qiu, Shan, Xuan, & Chen, 2020, p. 73)
This approach enables mapping the target social networks in layers, which provides more hierarchical and high-dimensional information. Link weights in social networks indicate “strength of friendship” and potentially other information (p. 75). Using various named datasets, the researchers test various subgraph network approaches for various tests, such as subgraph mapping, link-weight predictions, node classification, graph classification, and others, to better expand knowledge of structural feature spaces of social networks.
Identifying Sources of Online Information Spread
Feng Ji, Wenchang Tang, Jielong Yang, and Wee Peng Tay’s “Online Information Spreading and Source Identification” (Ch. 4) harnesses some different tools and methods to understand diffusion of information online. They use Bayesian inference methods and a sequential source estimation approach to track down rumor sources in an online social network. They explain early on: “For the simplest problem formulation in which only a snapshot of the infection status of the nodes in a network is available, we present various graph centrality methods and explain the motivations behind them” (p. 93). Theirs is a method to “generalize a source identification method developed for a tree network to a general graph, using the concept of Gromov matrices” (p. 93). To set a context for their work, they refer to independent cascade models of information spread. They point to various common models, including the susceptible-infection (SI) model, the susceptible-infection-recover (SIR) model, the susceptible-infection-recover-infection (SIRI) model, and the susceptible-infection-susceptible (SIS) model, which are fairly mechanistic. How something propagates through a network is understood as node-to-node transmission, with node states as either susceptible (open to infection), infected (carrying the information), or recovered (prior infected but no longer so). These models generally suggest that a sufficient level of exposure by neighboring nodes leads to infection (p. 94). While the language here is of infection by a contagious disease, the concept can apply to various things like information, emotion, cultural practices, and others. Different models may have different underlying assumptions in applications to different data and contexts. One example used in this work is of rumor-sharing via social accounts. An account is recovered if the account shared the rumor but later retracted the message, for example. The researchers run their setup based on various starting stages of the rumor; they use single-source states, multiple-source states, and multiple-source states with different start times, among others. In another round, they collected timestamp observations of first infection for the nodes and then applied Bayesian methods and sampling methods to identify potential node sources of the rumors. The Bayesian approach involves trying to understand the hidden actual state of the world given observables (the samples).
PageRank Bipartite Graph Ranking for Online Chat Group Recommending
Man Fai Wong, Ching Nam Hang, and Chee Wei Tan’s “The PageRank Bipartite Graph Ranking: Online Chat Group Recommendation” (Ch. 5) explores the use of a modified version of Google’s PageRank algorithm in a recommender model for a chat group based on Tencent QQ social messaging data. The bipartite graph has nodes divided into two sets “such that no edge connects the nodes in the same group” (p. 127). From this, the various social nodes are ranked in a hierarchy, with each node assigned a number and placed in a ranking structure. While this work was to study the algorithm “for a recommendation system for chat groups in a Tencent QQ system,” the researchers did not fully explore their thinking in terms of the practical application in the context (p. 138).
Parallel Counting of Subgraphs in Large Graphs
Ching Nam Hang, Pei-Duo Yu, and Chee Wei Tan’s “Parallel Counting of Subgraphs in Large Graphs: Pruning and Hierarchical Clustering Algorithms” (Ch. 6) takes as its challenge the “subgraph isomorphism” problem as posed in the 2018 MIT-Amazon Graph Challenge. Their solution is “a novel joint hierarchical clustering and parallel counting framework” dubbed MEGA to compute “the exact number of triangles in large graphs” (with applications to computing across big data) (p. 141). This work describes the thinking and design process at arriving at the particular solution by the team. This work shows how readers may spark off the learning and methods of others.
Automation to Strengthen Social Learning Networks (SLNs)
Lin Ling and Chee Wei Tan’s “Social Learning Network and its Applications in Large Scale Online Education through Chatbot” (Ch. 7) focuses on social learning networks (SLNs), enabled through the advent of mobile technologies and online pedagogical methods. This research team identified two problems in the space to engage: how to optimize task scheduling “between multiple learning contents for each learner, so that the learning outcome within the limited learning time can be maximized” and how to automate the grading process in large-scale SLNs (p. 166). For their scheduler, the team brings into play deep insights about learning in the real, and they also consider the respective learning outcomes for the students in a personalized way (through three variables for the respective learners). The researchers design an automated grading system with human inputs, too. Then, they combined both systems into a mobile messenger chatbot called Nemo Bot for math learning, built in part on the Facebook Messenger platform.
Message-Passing Algorithms for Rumor Source Detection
Pei-Duo Yu, Chee Wei Tan, and Hung-Lin Fu’s “Rumor Source Detection in Finite Graphs with Boundary Effects by Message-Passing Algorithms” (Ch. 8) suggests the importance of taking into consideration real-world features of social networks, such as their finitude and “complex spreading behavior” in terms of information. Such boundary effects need to be considered. Their work solves “the constrained maximum likelihood estimation problem by a generalized rumor centrality for spreading in graphs with boundary effects” (p. 185) and propose a message-passing algorithm effective in this space (p. 186). This work exemplifies how there are continual efforts to improve practical computational methods with considerations for how the real world may be modeled digitally.
Conclusion
Chee Wei Tan’s Online Social Networks: Perspectives, Applications and Developments (2020) highlights some important works around familiar algorithms in the social network space.
The editor has multiple graduate degrees from Princeton University. He is a Professor of Computer Science at City University of H.K. Dr. Tan has earned numerous recognitions for his work.
About the Author
Shalin Hai-Jew works as an instructional designer / researcher at Kansas State University. Her email is shalin@ksu.edu.
| Previous page on path | Cover, page 18 of 22 | Next page on path |
Discussion of "Book review: Computational learning from online human connectivity"
Add your voice to this discussion.
Checking your signed in status ...