Book Review: Using Statistics and Machine Learning to Promote Cybersecurity
By Shalin Hai-Jew, Kansas State University
{kind=link}
Figure 1: “Knowledge Discovery in Cyberspace…” (cover)
Knowledge Discovery in Cyberspace: Statistical Analysis and Predictive Modeling
By Kristijan Kuk and Dragan Randelović
New York: Nova Science Publishers
2017 206 pp.
The title of Kristijan Kuk and Dragan Randelović’s Knowledge Discovery in Cyberspace: Statistical Analysis and Predictive Modeling (2017) and its inclusion in the Cybercrime and Cybersecurity Research series might give a wrong impression.
This short collection of seven chapters explores some ways that statistical and computational analyses may be applied to law enforcement (writ large). The work is not about “cyberspace” per se. Also, the work seems largely theoretical and abstract, without much in the way of insight about either cybercrime or cybersecurity and little in the way of applied real-world cases. This is a very high risk in information technologies where ideas on paper sound great, but reality is often different in application.
What are some of the technologies described? The methods are not particularly cutting edge: an algorithm to find latent patterns in text-based blog data, GIS technology to support police work, simple linear regressions to anticipate computer crime (with very sparse data), the uses of Benford’s Law to identify anomalies in data (including accidental and purposeful ones, and including possible fraud), a survey used to understand people’s attitudes about privacy, text finding algorithms for e-government documents, and a custom encrypted communications plan using Linux on an Android platform.
Similarly, the assertions in the Preface suggest that the book addresses “mathematical methods in crime prevention for special agents, and discusses their capabilities and benefits that stem from integrating statistical analysis and predictive modeling” and is written “to police investigators and cyber special agents interested in predictive analytics” (Kuk & Randelović, 2017, p. vii). Those assertions also seem to mis-assert what the book covers.
The work itself focuses geographically on Serbia and other parts of S.E. Europe, and only two of the works seems insightfully transferable to other contexts. The editing on this book seems fairly light and uneven, so readers will have to work through non-native English. The eight acknowledged reviewers for this collection are professionals in universities in Jordan, Croatia, Macedonia, Serbia, Belarus, China, and the Russian Federation.
This is not a book that should be judged by its cover. It should not be read to understand the state of cybercrime or cybersecurity.
Qualms aside, “Knowledge Discovery in Cyberspace…” offers insights on how others are thinking about technologies and how they are struggling to harness technologies for practical outcomes.
Pattern Mining
Drs. Darko Marinkovic and Turhan Civelek’s “Computer-Based Data Analysis Techniques: The Potential Application to Crime Investigation in Cyber Space” (Ch. 1) suggest the importance of social media as important spaces to explore information about potential suspects. The authors suggest the importance of “dataveillance” (“in the Anglo-Saxon literature”) (Marinkovic & Civelek, 2017, p. 4) as a tool of governance. They open with writing which suggests modern societies existing wholly without individual personal privacy:
It is a general view today that exceptional organization of human society inevitably relies on collecting and managing the most various data related to their members. The efficient functioning of the government as well as non-governmental sector requires the existence of numerous information registers about different entities (individuals, organizations, etc.), covering all aspects of their activities (Marinkovic & Civelek, 2017, p. 2).
Ubiquitous government awareness is seen as necessary and not particularly sinister if legally and legitimately accessed and maintained and used. This work reads fairly theoretically. For example, they describe integrated databases which enable easy access to mixed data. However, there is not the real-world sense of the necessary work of proper data labeling (and metadata), data schemas, connecting databases, and enabling big data searches. The authors suggest that cyber surveillance is comparable to physical surveillance but is lower-cost; this assertion is debatable. Also, this assumes that people in the contemporaneous present use social media in an unsophisticated and data-leaky way, which may or may not be true based on the individual.
The authors discuss—in very broad terms—computational methods for association rule discovery from text, sequence pattern detection, and classification approaches (Marinkovic & Civelek, 2017, pp. 5 – 6), and suggest that these may be applicable to public social media data in a cybersecurity context. They provide a quick review of basic mathematical notations for computing accuracy rates, error rates, precision, recall, f-measures, and (Cohen’s) Kappa values for predictive analytics but without in-depth explanations (Marinkovic & Civelek, 2017, pp. 7 – 9). The writing focuses on how these elements should work but none of the real-world sense of how to analyze data, what the parameters of the various data extractions should be set at and why, and how to understand the outcomes in a real-world context. They frame the analysis around the free and open-source software “WEKA” (Waikato Environment for Knowledge Analysis) which is built around machine-learning and data mining algorithms and has been available since the early-to-mid-1990s.
The sense of rose-colored analytic lenses applies to the descriptions of the blogging platforms in Web 2.0:
There are a lot of companies which support free blog facilities in order to collect data and perform different analyses (economical, social, political, etc.). Beside (sic) common features such as age, education, or blog topic, a lot of other (often ‘hidden’) tendencies can be revealed as well (internet identity, personal affinities such as political opinion, music preferences, religion, etc.) (Marinkovic & Civelek, 2017, p. 12)
Of course, not all people are so enamored of a public persona. There is also no sense of any oppositional or adversarial ways that people may apply to confusing this law enforcement regime. (How many people use their actual names when they blog? How accurate is the information that people share to a broad public readership?) There is also not a sense of the challenges to scraping data from blogs. There is no sense about how data cleaning should be done. There is no sense of how the publicly available blog data may be used in law enforcement or in the legal system in Serbia and Turkey (where the co-authors reside). [One author hails from the Academy of Criminalistic and Police Studies in Serbia and one from the Software Engineering Department in Kirklareli, Turkey.]
Applying the analytics capabilities to real-world contexts may be helpful to know how much / little is empirically assertable, how much is public vs. non-public, and so on. It is important to validate / invalidate various methods for data collection, especially when people's well-being is at stake...and when state power is being wielded.
The authors return to the idea of bringing the topic back to “police and intelligence agencies” (Marinkovic & Civelek, 2017, p. 15), but this direction seems somewhat forced and add-on. The Big Brother-esque comfort with government informational over-reach may be discomfiting to readers who live in liberal democracies and who may have some residual mistrust of government.
GIS for Police Work
Nenad Milić, Brankica Popović, Venezija Ilijazi, and Erzen Ilijazi’s “Spatial Data Visualization as a Tool for Analytical Support of Police Work” (Ch. 2) addresses the importance of geographical spatiality in crime prevention, such as in “hotspot policing” (identifying locales where there are high frequencies of crimes and ensuring a high police presence there to address anticipated issues), the drawing of crime maps for deployment on the Internet, geographic profiling of offenders, and predictive analytics to aid law enforcement.
The authors—who hail from universities, government, and the UN—suggest that the most important types of information for crime analysts are “sociodemographic, temporal and spatial” (Milić, Popović, Ilijazi, & Ilijazi, 2017, p. 24). An empirical and data-based approach to crime solving and analysis stands to benefit “crime intelligence analysis” (the study of data about criminal offenders, victims, and organizations), “tactical crime analysis” (the study of police data to inform “patrol and investigative priorities and deployment of resources”), “strategic crime analysis” (the study of long-term population trends, hotspots, and crime to develop “long-term strategies, policies, and prevention techniques”), and “administrative crime analysis” (analytics to meet “the administrative needs of the police agency, its government, and its community” (Milić, Popović, Ilijazi, & Ilijazi, 2017, p. 23).
The authoring team describes the importance of social science research techniques and computation-based analysis techniques including statistical analysis, link analysis, data visualization, and crime mapping (Milić, Popović, Ilijazi, & Ilijazi, 2017, p. 24). In many cases, law enforcement benefits from fast (even real-time) access to relevant information.
Crime is not distributed randomly throughout geographic space. More specifically, there are denser concentrations, which may be identified and visualized with software like ESRI’s ArcGIS suite.
Crimes tend to concentrate at particular geographic locations where favorable opportunities exist. These concentrations or clusters of crime are commonly referred to as hotspots. Proliferation of GIS software contributes to the fast and easy hotspot maps creation, making them a central part of crime analysis and hotspot policing. (Milić, Popović, Ilijazi, & Ilijazi, 2017, p. 34)
The authors note that without accurate identification of crime hotspots, these may “affect police effectiveness, as well as the citizens’ quality of life, or even their rights” (Milić, Popović, Ilijazi, & Ilijazi, 2017, pp. 34 - 35). The writing makes it sound like those who live in hotspot areas can expect to have their quality of life compromised and their rights contravened. The authors list three models of geographical profiling of unknown offenders—Rosmo’s model, Canter’s model, and Levine’s model (p. 39), but they do not define these nor provide comparisons.
The Crime Information Warehouse (CIW)—which brings together ESRI Maps and IBM Cognos in the ESRI cloud—offers real-time big data analytics to enable predictivity of crime and of criminal behaviors and of potential victims of crimes (Milić, Popović, Ilijazi, & Ilijazi, 2017, p. 44).
In a sense, there seems to be a gap between freeware technologies and the commercial enablements by large multi-national corporations. Also, it seems like a small world after all in terms of available technologies in this space.
Promoting Cybersecurity
“Cybercrime Influence on Personal, National and International Security while Using the Internet” (Ch. 3), by I. Cvetanoski, J. Achkoski, D. Rančić, and R. Stainov, reads like a basic primer on cybersecurity risks on the Web and Internet. Early on in the work, the authors bring in The Matrix (1999), maybe to evoke a bewildering sense of the future in terms of cybersecurity:
Perhaps the movie ‘Matrix’ starring Keanu Reeves is one of the many stories about the future and the evolutionary process of cyberspace, about the evolution of the war, about change of the perception of the man to the machine, about the technological development and the development of artificial intelligence, about switching roles between the humans and the machines, about the world in which the machines manage the people, about virtual world created by the progress of machinery using the possibilities of cyberspace and smooth mutual communication through the established network connections. (Cvetanoski, Achkoski, Rančić, & Stainov, 2017, p. 55)
They follow this with a generalized listing of types of cyber attacks and a listing of the ways that computers may be “endangered” (p. 58), based on broadly public data. They define common terms in cybersecurity. They advise against “Reckless using of the services of social networks: Facebook Twitter, LinkedIn, Myspace…” (Cvetanoski, Achkoski, Rančić, & Stainov, 2017, p. 54), albeit without further elaboration.
Then, of more interest, the authors offer statistics for cybercrime in Macedonia. For example, “abuse of credit cards” and “unauthorized penetration into a computer system” are some of the more common challenges (Cvetanoski, Achkoski, Rančić, & Stainov, 2017, p. 72). The collected numbers of cybercrimes seem very low (likely due to low reportage): 1 in 2012,
91 in 2013, 103 in 2014, and 48 in 2015 (Cvetanoski, Achkoski, Rančić, & Stainov, 2017, p. 72). With such sparse data and a lack of clarity of how they were arrived at, it would be difficult to try to use these in any analytic way. The rising trend of observed and recorded cybercrimes may well be a factor of heightened awareness and increased surveillance.
Additional data tables and data visualizations add more information. For example, a large percentage of Internet users have experienced computer viruses in Macedonia (68% in 2010 and 71% in 2015). In this same table are statistics from Turkey, Greece, Bulgaria, Slovenia, and Croatia (Cvetanoski, Achkoski, Rančić, & Stainov, 2017, p. 74). Electronic banking is high-risk for bank customers, according to the data. The data show different on-ground realities in terms of cybersecurity.
This chapter concludes with a list of do’s and don’ts at the individual level, followed by another about what may be done at the national and international levels to protect against cyber compromises. This chapter cites works by a number of Western authors and CERT spinoffs in locales from around the world.
Hidden Patterning and Fraud Detection
D. Joksimović, G. Knežević, V. Pavlović, M. Ljubić, and V. Surový’s “Some Aspects of the Application of Benford’s Law in the Analysis of the Data Set Anomalies” (Ch. 4) builds off a discovery from the late 1800s about patterns in numbers and using these frequencies as a baseline against which anomalies may be identified (to possibly indicate fraud). The number pattern is known as Newcomb-Benford’s law. Essentially, the idea is that with a sufficient amount of non-random data, first digits tend to occur with a certain amount of frequency. For example, there are more 1’s than any of the other leading 9 digits (2, 3, 4, 5,…9).
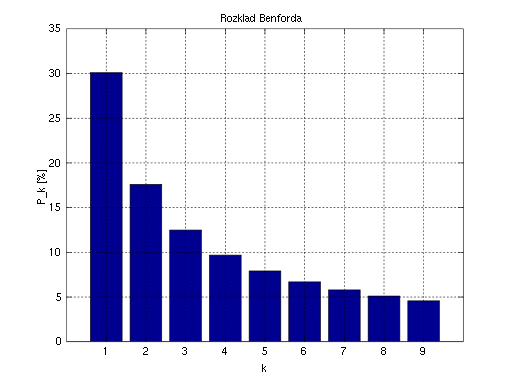{kind=link}
Figure 2: Benford’s Law (illustrated by Gknor, Aug. 6, 2008)
{kind=link}
Real-world data, such as global countries’ populations, are seen to map to this frequency of leading digits. Some suggest that this phenomenon is a universal.
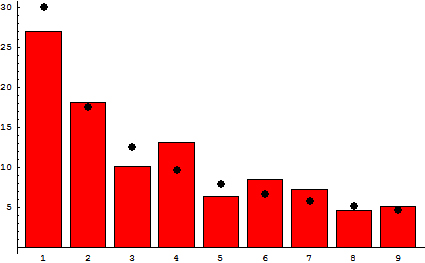{kind=link}
Figure 3: Benford’s Law Illustrated by World Countries’ Populations (by Jakob Scholbach, Aug. 2010)
{kind=link}
The authors of this work suggest that Benford’s law may have some relevant applications to cybersecurity, but the ideas are not fully developed. It would be interesting to see this applied to live data to identify anomalies and to draw logical conclusions from those anomalies.
Sampling Privacy Attitudes
Gordana Savić and Marija Kuzmanović, in “Behaviour and Attitudes vs. Privacy Concerns of Social Online Networks” (Ch. 5), describes research into personal privacy attitudes around the sharing within online social networks (OSNs). An online survey of 641 respondents in Serbia resulted in the categorization of respondents into three categories: “fundamentalists, pragmatists and unconcerned” [based on the Westin Privacy Segmentation Index (WPSI)], with 283 Privacy Fundamentalists, 335 Privacy Pragmatists, and 23 Privacy Unconcerned. The thesis being tested was: There is a relationship between privacy attitudes about online social networks and demographics details, more specifically:
We assumed that fundamentalists are older, mainly concerned about their privacy, probably having experience with private data harassment and consequently spending less time on the OSNs in comparison to the group of pragmatists and unconcerned users. As opposed to that, the unconcerned users should be the most flexible group, spending significant amounts of time on OSNs and leaving actual data on all networks used. (Savić & Kuzmanović, 2017, p. 124)
The co-researchers used an established instrument for their work based on the the Westin-Harris consumer privacy surveys “from the late 1970s until 2004…” on areas of “marketing, medical, and online commerce.” This methodology resulted in the segmentation of respondents into three main groups based on their privacy attitudes (Savić & Kuzmanović, 2017, p. 124).
The researchers made a raft of nuanced observations, such as significant differences in attitudes about chatting online between those who are married, in a relationship, or single.
They observe: “The majority of the respondents use an OSN for sharing information—only 2.7% have never shared information. The students are also leaders in this segment. Actually, 78.6% of university students often used OSNs for sharing information, while high school students mainly do not use them for this purpose. This result is in full compliance with the statistics of the responses to the question about what activities OSNs are used for. Namely, the students in high school use OSNs for being informed about social events the least (26.3%, p<0.01), but they often use OSNs for sharing photos and videos (more than 50%, p<0.05). In addition, about 50% of women share, while just 4.8% of women and 11% of men do not share their photos and videos (p<0.01)” (Savić & Kuzmanović, 2017, p. 133).
There are preferences for particular social media platforms. There are observed daily life usage patterns for respective social media platforms among particular slices of the population.
In this chapter, there is a lot of descriptive data about individuals and their thoughts and behaviors on social media, and many of these are described using evocative data visualizations.
The authors explain their research with clarity, including the use of cross-tabulation analyses. They also suggest the potential use of conjoint analysis in the future to explore more deeply. Overall, this is one of the more satisfying chapters in this collection. The authors capture well the hard work of collecting data and then making sense of it. It would be intriguing to understand how generalizable the data is and what this might mean for social media usage in Serbia.
Extracting Conceptual Schemas
“Information Retrieval and Development of Conceptual Schemas in E-Documents for Serbian Criminal Code” (Ch. 6), by Vojkan Nikolić, Predrag Dikanović, and Slobodan Nedeljković, builds on the affordances of data finding and extraction. In this context, the researchers explore how unstructured text-based documents (in the Serbian language, and in the HTML, PDF, and Microsoft Word formats) created as a byproduct of e-government may be explored and used for awareness and analytics. The technology is the Lucene library one, and the application is to the processing of textual information related to criminal offenses, with a leap to the identification of crime in cyberspace (Nikolić, Dikanović, &Nedeljković, 2017, pp. 151 - 152).
The authors write:
With an increasing number of anonymous reports submitted by citizens electronically in relation to various areas of crime leads to aggravation of the process of analyzing applications and performing analytical conclusions. This problem appears to be more complex because such an obtained information is not filtered or guided in a detective-led interview and results in obtaining an irrelevant information. (Nikolić, Dikanović, &Nedeljković, 2017, p. 131)
They suggest that various text queries and processes may link the reports to information in the Serbian Criminal Code. They use examples from the criminal code related to bodily injury and suggest some generalized semantic indexing of synsets (synonym sets) through controlled vocabularies, taxonomies, thesauruses, and ontologies…that may bring order to such data and enable faster awareness and informational processing (Nikolić, Dikanović, &Nedeljković, 2017, p. 156). They describe words that should be added to the stopwords list for an effective document search algorithm. The authors describe the resource as EuroVoc, and it is unclear if what is online now under that name is related to this original project.
“Development of the Android-Based Secure Communication Device” (Ch. 7), by Aleksandar Jevremović, Mladen Veinović, Goran Šimić, Nikola Savanović, and Dragan Randelović, describes a theorized approach to create an encrypted communications system between Android devices. In this approach, the authors suggest an open-source and “secure” intercommunications system. As to how practical this approach is, that is unclear from the available information. Actual deployments of technologies always differ from plans, and no secure system is considered robust against threats unless testers “red team” the system. This chapter was the result of several state-funded projects from the Ministry of Education, Science and Technology Development for the Republic of Serbia.
Conclusion
Kristijan Kuk and Dragan Randelović’s “Knowledge Discovery in Cyberspace: Statistical Analysis and Predictive Modeling” (2017) provides a window into how academic researchers are thinking about harnessing available technological capabilities for law enforcement applications.
Indeed, other research has already shown the near-universal hesitancy and slowness in adopting technologies. For all the limitations of this book, it does shed light on the difficulty of harnessing technologies for practical aims. Even if the descriptions in the writing may be superficial, the work may still introduce new concepts and new ideas of analytical methods and new technologies to the readers, and these may inspire exploration and implementations.
This work would benefit from some exploration of specific (vs. generalist) off-the-shelf software that may be harnessed for actual cybersecurity and the fighting of cybercrime. It would benefit from more in-depth machine learning applications. Expanding technological analytics to the Internet of Things (IoT)—think cyber applications in housing, automotive applications, healthcare, household robotics, and others—would also enhance this work. The inclusion of real-world cases would be helpful. Localizing the topic to particular regions would benefit this, too.
People in law enforcement are famously close-mouthed about capabilities, and so they should be. However, in a collection like this, the authors have to be able to apply the theorized approaches to real-world data and contexts—to make the case for the efficacy of such approaches. They need to convey a sense of what the legal and law enforcement regimes are like. There should be a taste of the bureaucratic regimes around law enforcement. And certainly, there should be a range of data and analytical methods that may enhance understandings of cybercrime and cybersecurity. Of course, these are ideal expectations--and it's always better to actualize a book and not let perfection be the enemy of good (enough).
About the Author
Shalin Hai-Jew works as an instructional designer at Kansas State University. Her email is shalin@k-state.edu.
| Previous page on path | Cover, page 18 of 23 | Next page on path |
Discussion of "Book Review: Using Statistics and Machine Learning to Promote Cybersecurity"
Add your voice to this discussion.
Checking your signed in status ...