Scrubbing Digital Resources for Intentional Sharing
By Shalin Hai-Jew, Kansas State University
{kind=link}
Figure 1. "Data" (from the Wikimedia Commons)
{kind=link}
Introduction
The work of instructional design (ID) involves designing (and often developing) learning that is efficacious for a wide range of learners and for target learner groups. In the instructional design context, the idea is to share the learning broadly and clearly…while supporting learners in their endeavors. This is not a typical space where one exercises a malign imagination or creates a threat analysis or conceptualizes malicious actors. And yet, it does not hurt to be more intentional about sharing data. It helps to know what data may ride with respective files.
The challenge sometimes involves making sure that nothing else is riding with digital files than the information that one intended. Every so often, an ID has to make sure that various digital images (1), digital audio files and videos (2), digital slideshows and articles (3), digital learning objects (DLOs) (4), and datasets (5) do not accidentally leak data to a general public.
What is required to head off unauthorized disclosures in these respective modalities and forms? This work offers some initial thoughts.
Some Real-World Examples
It helps to offer some initial real-world examples for each of the respective forms.
- Digital imagery (1). One may have a set of images that show that a dangerous “select agent” was discovered on a farm, and the EXIF data reveals which farm it was or the captioning named the farm. When the farmer shared the information with the government agency, it was with the understanding that the farmer and the farm’s identities would be protected, so as not to harm reputation or access to markets.
- Digital video (2). A video is created in a sensitive building. To ensure that no relevant information is leaked about the building, the videographer is very careful about what is captured on-screen and controls for every element in the frame. (More concerning now are “deep fakes” that can be built off of a sufficient number of existing videos of a person talking into camera.) [Digital audio will automatically reveal a voice print, a biometric identifier (HIPAA Journal, Oct. 18, 2017, p. 1).]
- Slideshows (3). Or, an individual has brought a slideshow in for re-organization. She has emplaced an oval over a farmer’s head and thinks that that is sufficient protection. The issue is that in the edit mode, the oval shape can just be removed, and the person’s facial features are clearly viewable (and re-identifiable using facial recognition software).
- Articles (3). The academic articles, by definition, are expected to contain a certain amount of data. They are not expected to leave gaps about how work is achieved, how data are analyzed, and others. Some include images of people, sometimes with their signed releases and other times not, sometimes with their awareness of what information will be shared and other times not, and so on. [For those who review for academic publications, it is important to make sure that the researchers are compliant with human subjects research and that rights for personal information releases have been attained.] Articles in digital format also contain metadata, which may reveal various aspects of the work, including insights about prior drafts, which authors touched the work, review markups, and other information.
- Digital learning objects (DLOs) (4). A digital learning object has been created for use on a platform that automatically strips out EXIF and caption data from the imagery. The images, though, may be used in other ways downstream, with developers going back to the original imagesets for the images (with the EXIF and caption data riding with the images again).
- Survey data (5). An administrator on campus is sharing an online report of a student survey that cuts across colleges. The report shares summary data that provides general overviews. However, the survey platform also enables the downloading of particular data tables from the respective questions. Some of these contain information that may be re-identifiable.
- Qualitative project data (5). A research team is asked to share their project, which they team-coded. Their work resides on a qualitative data analytics software file. The ingested data cannot be de-identified. There are copious amounts of text, which is the basis for the coding and has not been scrubbed. For the team to make the case for the relevance of their mutual coding and the Kappa coefficient, they need to have all the raw data included to help make their case for reproducibility.
Part 1: On Digital Imagery
Digital imagery carries a lot of multimodal information. There is the image itself, with information in the foreground and background. An initial image assessment may include analysis of the visuals alone, including zooming in and zooming out. (How was the visual captured? What is the apparent setup for the image? What is it communicating? What is it designed to communicate? Who is its target audience?) If an image is part of a series, analyzing the series visually may shed light on context or other aspects of the images.
It helps to look at the name of the image, which is often a label for its contents. It helps to explore the EXIF (“exchangeable image file format”) data that is riding with the image.
In Adobe Photoshop, one gets to this data using the File -> File Info sequence. Here, there may be a wide range of data: the stated photographer, the image description, applied keywords, the copyright status, camera data, shot information, date created, physical location, GPS data, audio, video, and raw XML data, among others. In the instructional design context, it is important to keep an unedited pristine master set of the visuals…and then a processed set with the EXIF and caption and alt-text data removed…or more generic information applied in lieu of the earlier data, and so on. It would be a bad idea to remove information that will be needed later, such as XMP data for schemas in databases. [The contrary is also important to analyze—how much one can ensure that necessary and accurate data ride with an image that may be separated from a context or a learning object or a set.]
There are other interventions. If an image is needed, but a part of it is too sensitive, that part may be redacted, with an unremovable opaque shape that is saved into the image (with the original unavailable). Or various editing effects may be applied to distort the part of the image (although it is likely that there are ways to reverse engineer to an original image by sophisticated actors). There is no compellence to necessarily use a sensitive image. If the images one has are too sensitive to share, one can always go to photo-realistic drawings that are a step out from the original images. Or original images may be changed from full-color to black-and-white. (Whatever changes are made to an image will affect its fidelity, so that should be noted in the share.)
The removal of EXIF and XMP data from photos may be done to make image sizes smaller when uploading to a social sharing or other site (with selected relevant information left available, such as “shutter speed, aperture and ISO”) (Mansurov, n.d., p. 1). It is possible to go to Adobe Photoshop and export a file with Preferences that eliminate all metadata, or one can select to include “Copyright and Contact Info” and so on. (Figure 2)
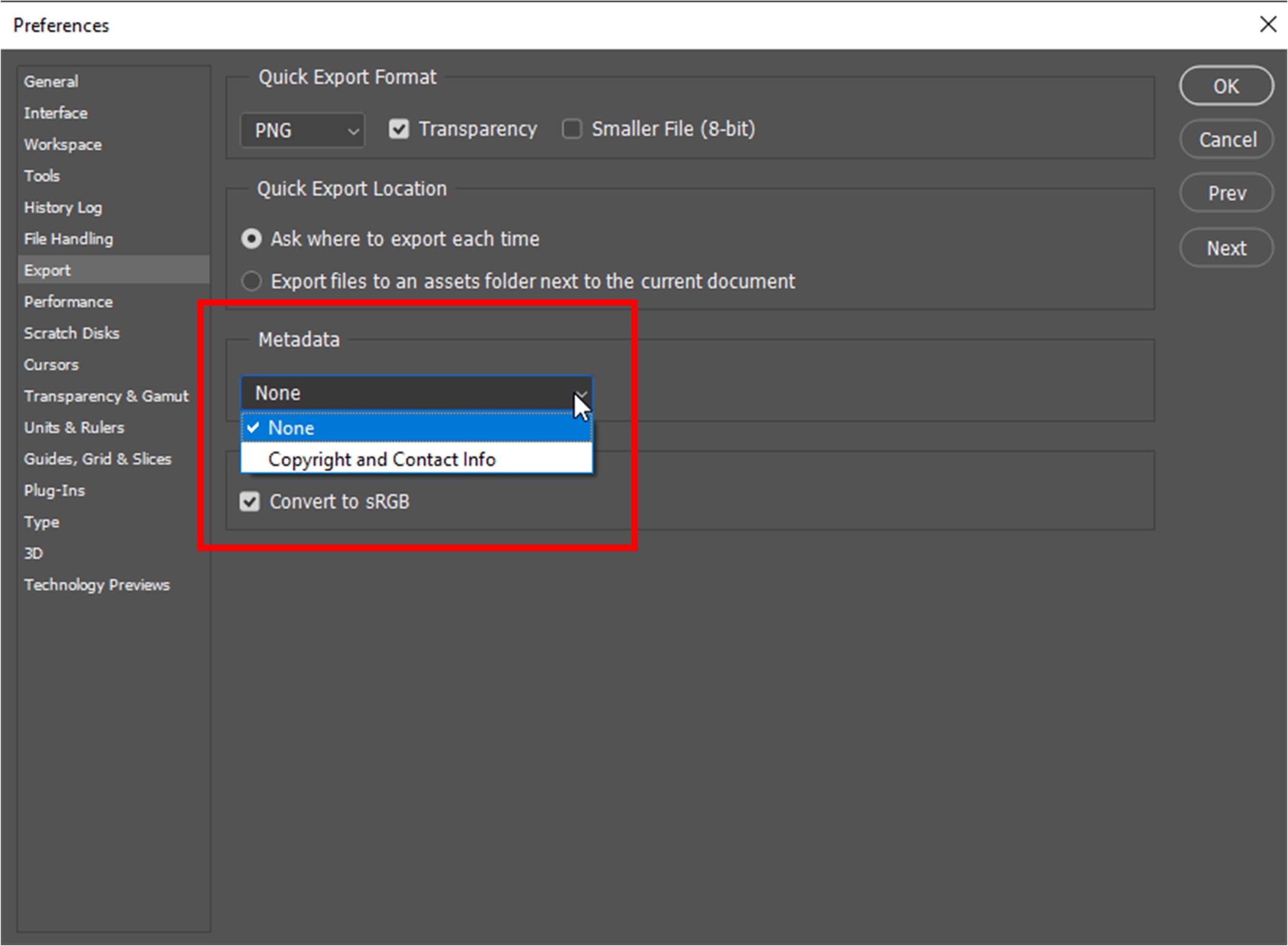{kind=link}
Figure 2. Image File Export Preferences in Adobe Photoshop
Depending on changes to the image editing software (and which ones are being used), there are likely other work sequences. After the parameters are set, be sure to test what data ride with the image and which do not. Images may be batch-processed using macros.
Also, a simple way to ditch any extra information that may be riding with a digital image is to screenshot it and use the screenshot. (Separately, I am assuming that the user has engaged due diligence and is legally using the image and not contravening copyright.)
Part 2: On Digital Audio, On Digital Video
In the same way that visual analysis may be done on still images, digital audio files may be analyzed for obvious sound and non-obvious sound…and videos for obvious visuals and non-obvious visuals and obvious and non-obvious sounds. Metadata can also ride with digital audio and digital video files. These may be scrubbed in different ways. Inherent data is shared automatically through the making of audio and video files, like voice prints and facial expressions (in some cases), which may enable “deep fakes,” a special concern in the modern era. Also, listed credits convey information about people, except for those that exercise due care in what is / is not released.
Part 3: On Slideshow Creation; On Article Writing
Slideshows and articles are common forms in academia. Both carry alt-text and metadata. For example, in PowerPoint, go to File -> Info -> Check for Issues -> Inspect Document to access the “Document Inspector” to make changes (Figure 3). The check toggles on the included data, and the uncheck toggles it off.
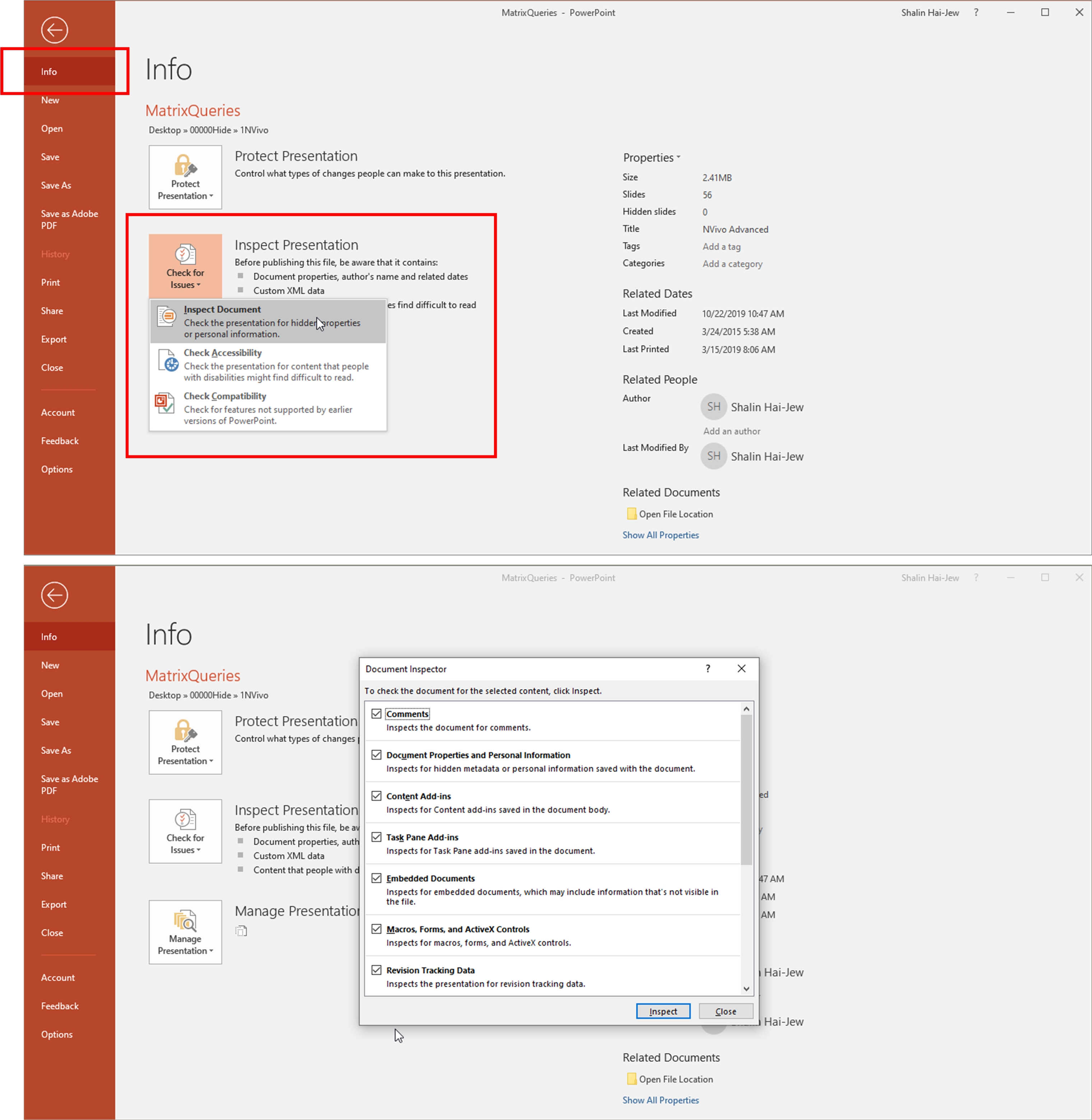{kind=link}
Figure 3. File -> Info -> Check for Issues -> Document Inspector (in PowerPoint)
Whenever a person shares a pre-print of an article, a lot of metadata rides with the file. This is so for .docx or .pdf, and other common forms.
Even if no metadata rides with the respective slideshows and articles, various writing (and spoken words) may be analyzed for temperament (psychometrics), reverse-engineered capabilities, and other information, using computational textual coding and human analytics.
Part 4: On Digital Learning Objects
Digital learning objects, no matter what authoring tools are used to create them, are created from component parts: images, texts, audio, video, and so on, all of which carry more information than may be assumed. (See above.) In addition, the authoring tools often involve ride-along information and metadata.
Part 5: On Datasets
In academia, people may share datasets for any variety of specific and combined reasons: publishing, presentations, data sharing, collaborative research, analytics and reproducibility, and others. For all the data sharing, each time data is touched, it changes.
The natural state of real-world data is “dirty” (Seif, n.d.), which means that data analysts need to clean the data—in a way that makes it analyze-able but without introducing errors or biases. (The “dirty” dataset is protected in its original form as a master set before anything is done with it.) One analyst defines a general “coarse-to-fine” style of data cleaning by first working “grating issues” and then down to “nitty gritty details” (Seif, n.d., p. 2). Data cleaning also ensures that typos and incorrectly captured data may be addressed (Bailey, June 14, 2017, pp. 2 – 3).
Perhaps there is missing data. Seif suggests potentially dropping features in a dataset, by eliminating data columns that are not correlated with the target variables of interest, dropping variables with “90% of its data points” missing (empty cells), and whether a variable is practically useful (n.d., p. 2). Other common approaches for missing cells are to fill them with averaged values, random values, or to let the null values remain and run statistical analyses that are robust against missing data. Seif notes that it is possible to discretize continuous data and vice versa (n.d., p. 4), to transcode or recode values.
De-identifying data. Finally, data tables and datasets contain not only metadata, but they also contain personal protected data directly. People have rights to privacy, so their data should not be leaked accidentally or shared intentionally. Their well-being may be at stake, particularly in regards to health data, financial data, and other personal data. In higher education, student information is protected under the Family Education Rights and Privacy Act (FERPA), and faculty and staff information is protected under general and specific privacy protections. In an educational context, there are many other situations in which sensitive data is used in transactions and the normal course of work (“De-identified data,” July 23, 2015).
Shared data tables and datasets have to be scrubbed of personal identifiers, so that sensitive information is not leaked during the share. In many cases, datasets that contain…
- “personally identifiable information” (PII) [information that may be used to relate the data to a person] and
- “protected health information” (PHI) [“individually identifiable health information transmitted by electronic media, maintained in electronic media, or transmitted or maintained in any other form or medium” (Liu, Mar. 7, 2008, p. 5)]
may need to be re-versioned so that no PII or PHI is included. These revised datasets are de-identified in various ways that strive to ensure that no one’s “personal identity” is revealed (“De-identification,” Nov. 8, 2019, p. 1). “Data anonymization” refers to efforts to de-identify “metadata or general data” through “deleting or masking personal identifiers, such as personal name, and suppressing or generalizing quasi-identifiers, such as date of birth” (“De-identification,” Nov. 8, 2019, p. 1). “Anonymization” refers to the “irreversibly severing a data set from the identity of the data contributor in a study to prevent any future re-identification, even by the study organizers under any condition” (“De-identification,” Nov. 8, 2019, p. 2).
The challenge is that the data still has to be accurate for analytics after the data cleaning and changes. There are two main methods for data de-identification. The more common one is a heuristic method (rules of thumb) that remove personal identifiers from a dataset (“safe harbor” method)…or involve the creation of limited datasets…or that involve the generation of variables with hidden personal identifiers (Liu, Mar. 7, 2008, p. 10) for access to summary information. The second is a statistical method described as “scientific principles and methods proven to render information not individually identifiable.—not used that often” (Liu, Mar. 7, 2008, p. 9).
The safe harbor method focuses on the removal of common direct identifiers like names, street addresses, birthdates, admission dates, discharge dates, telephone numbers, fax numbers, email addresses, Social Security numbers, medical record numbers, VIN numbers, URLs, Internet Protocol addresses, photos, fingerprints, and others. There are also indirect identifiers, such as gender, race, ethnicity, religion, age, job, education, income, and others.
“Deidentification doesn’t tend to successfully anonymize data because there are so many sources of data in the world that still have identifying information in them,” writes Lea Kissner (Jun. 28, 2019). The mix of information may be used for so-called “linkage attacks,” in which a person may be re-identified with some of the demographic and other data linked to a particular record. A researcher explains that in this attack, “each record in the de-identified dataset is linked with similar records in a second dataset that contains both the linking information and the identity of the data subject” (Garfinkel, Oct. 2015, pp. 17 – 18), a known weakness since the 1990s. To disrupt “quasi-identifiers,” a range of strategies is applied to data: suppression, generalization, perturbation, swapping, sub-sampling, and others (Garfinkel, Oct. 2015, p. 20). Then, there are inference attacks, too, in which various data may be data-mined for insights.
In one information graphic, the various “degrees of identifiability” are analyzed, from pseudonymous data to de-identified data to anonymous data, with each type more robust against re-identification and potential mis-use (“A Visual Guide…,” Apr. 2016). Certain types of records have been found difficult to de-identify: location data, medical records, metadata (from social media), and others (Jerome, Apr. 1, 2019, pp. 2 - 3). Using the known to reidentify the anonymized (Campbell-Dollaghan, Dec. 10, 2018) is still applied today. And de-identification of data is not an “automatic get-out-of-jail-free card” (Jerome, Apr. 1, 2019), and there are other legal considerations, in addition.
There are apparently various software programs that may be used to help with data de-identification, with various levels of efficacy. There are also commercial validation services that verify whether the data was sufficiently de-identified.
On-ground, there seem to be complex real-world challenges (Kissner, June 28, 2019, p. 2). One writes:
There is a counterintuitive pitfall to avoid in deidentification: Overdoing it can cause other privacy problems. When someone asks you to delete their data, you need to delete it completely, not just from the primary data store but from all these secondary data stores, like caches, analytics datasets, and ML (machine learning) training datasets. If you’ve deidentified that data in a meaningful way, then it’s awfully hard to figure out what part of the dataset to delete. Because the data is not anonymized, you are still responsible for doing this deletion. The most effective way to do this is to delete the entire dataset periodically. Some datasets only need to exist for a limited time, like slices of server logs used for analytics. (Kissner, June 28, 2019, p. 2)
Regardless of the various endeavors, the risk is never quite 0. For some large “big data” datasets, summary data may be made available, but in a “non-consumptive” way, with no access to the underlying data from which the summary statistics are drawn (such as with the Google Books Ngram Viewer).
The General Sequence
The general sequence for scrubbing sensitive data may be summarized in the flowchart (Figure 4).
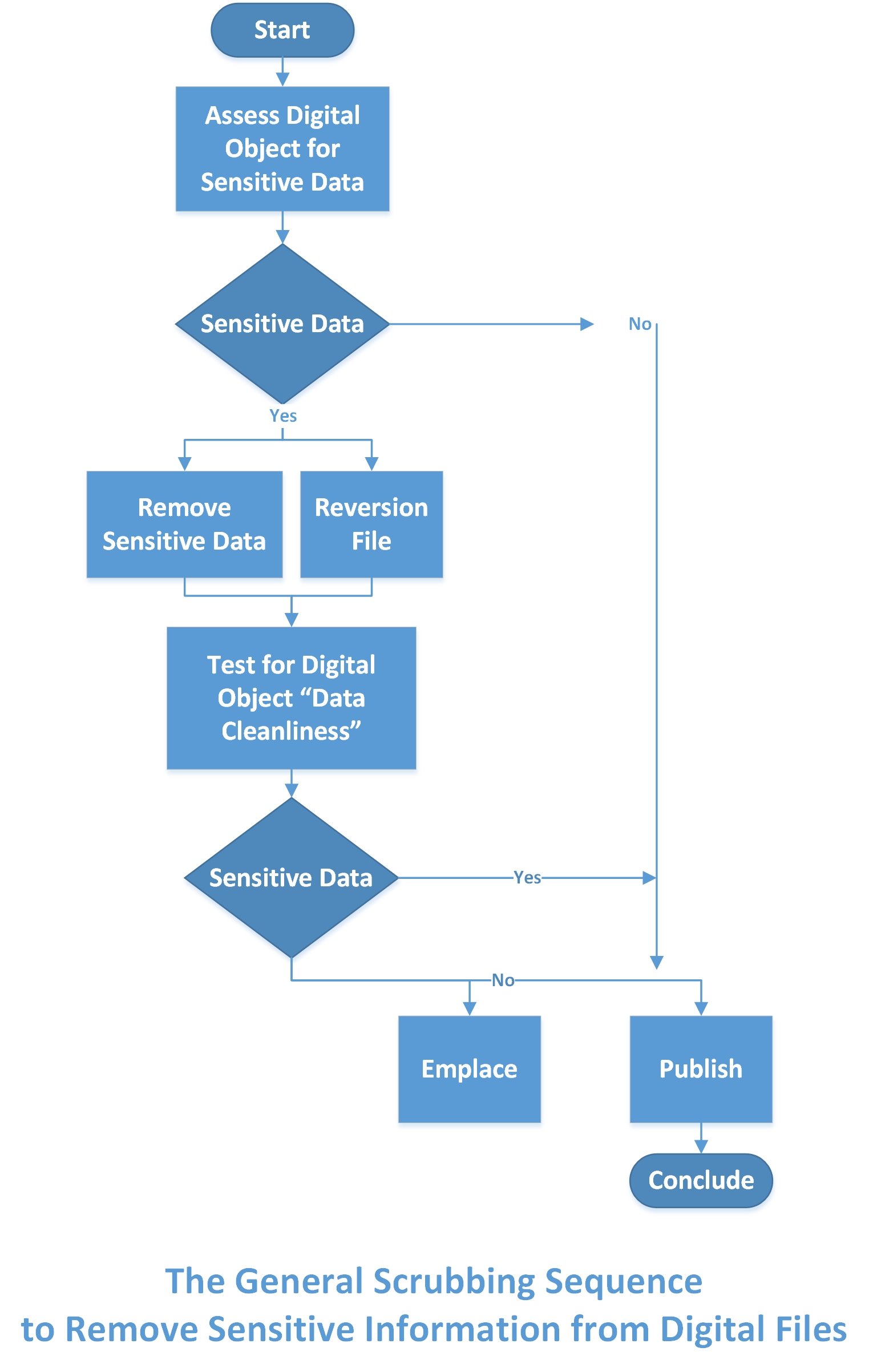{kind=link}
Figure 4. The General Scrubbing Sequence to Remove Sensitive Information from Digital Files
Conclusion
People do not go into instructional design with the idea that they will handle sensitive data, and yet, every so often, they will. This may be for data analytics. This may be for the teaching and learning directly. The principal investigators (PIs) of the projects will sometimes share insights about the threat space for the particular learning and what to be careful of—sometimes. While such information may be discomfiting, one gets over it and gets to the work shortly thereafter. The instructional designer should not be the “weak link” on a team, who drops information that the team should hold closely.
It helps to have a conversation about what is legally, ethically, aesthetically shareable, without causing unnecessary harm and without compromising others or the self. Being aware of data leakage raises instructional designer awareness and raises their sense of professional control across the various modalities.
References
A Visual Guide to Practical Data De-Identification.” (2016, Apr.) Future of Privacy Forum. Retrieved Nov. 26, 2019, from https://fpf.org/wp-content/uploads/2016/04/FPF_Visual-Guide-to-Practical-Data-DeID.pdf.
Bailey, B. (2017, June 24). Data Cleaning 101. Towards Data Science. Retrieved Nov. 26, 2019, from https://towardsdatascience.com/data-cleaning-101-948d22a92e4.
Campbell-Dollaghan, K. (2018, Dec. 10). Sorry, your data can still be identified even if it’s anonymized. Fast Company. Retrieved Nov. 26, 2019, from https://www.fastcompany.com/90278465/sorry-your-data-can-still-be-identified-even-its-anonymized.
De-identification. (2019, Nov. 8). Wikipedia. Retrieved Nov. 26, 2019, from https://en.wikipedia.org/wiki/De-identification.
De-identification of Protected Health Information: How to anonymize PHI. (2017, Oct. 18). HIPAA Journal. Retrieved Nov. 26, 2019, from https://www.hipaajournal.com/de-identification-protected-health-information/.
De-identified data. (2015, July 23). The Glossary of Education Reform. Great Schools Partnership. Retrieved Nov. 26, 2019, from https://www.edglossary.org/de-identified-data/.
Garfinkel, S. L. (2015, Oct.) De-identification of personal information. NISTIR 8053. Retrieved Nov. 26, 2019, from http://dx.doi.org/10.6028/NIST.IR.8053.
Jerome, J. (2019, Apr. 1). De-identification should be relevant to a privacy law, but not an automatic get-out-of-jail-free card. Retrieved Nov. 26, 2019, from https://cdt.org/insights/de-identification-should-be-relevant-to-a-privacy-law-but-not-an-automatic-get-out-of-jail-free-card/.
Kissner, L. (2019, June 18). Deidentification versus anonymization. International Association of Privacy Professionals. Retrieved Nov. 26, 2019, from https://iapp.org/news/a/de-identification-vs-anonymization/.
Liu, X.S. (2008, Mar. 7). How to de-identify data. Vanderbilt Biostatistics Wiki. Retrieved Nov. 26, 2019, from http://biostat.mc.vanderbilt.edu/wiki/pub/Main/XuleiLiu/HowtoDe-identifyData_LXL_20080307.pdf.
Mansurov, N. (n.d.) How to remove EXIF data. PhotographyLife. Retrieved Nov. 26, 2019, from https://photographylife.com/how-to-delete-exif-data.
Seif, G. (n.d.) 3 steps to a clean dataset with Pandas. Towards Data Science. Retrieved Nov. 26, 2019, from https://towardsdatascience.com/3-steps-to-a-clean-dataset-with-pandas-2b80ef0c81ae.
About the Author
Shalin Hai-Jew works as an instructional designer at Kansas State University. Her email is shalin@ksu.edu.
| Previous page on path | Cover, page 15 of 21 | Next page on path |
Discussion of "Scrubbing Digital Resources for Intentional Sharing"
Add your voice to this discussion.
Checking your signed in status ...