NVivo 12 Plus’s New Qualitative Cross-Tab Analysis Function
By Shalin Hai-Jew, Kansas State University
One common type of computational data analysis built into some online research systems is the cross-tabulation analysis. For example, Qualtrics® has a cross-tabulation analysis tool that enables automated calculation of the main required statistical tests.
These analyses assume that the underlying survey questions are single-barreled, independent, “random,” and generally orthogonal (and non-collinear). Quantitative cross-tabulation analyses help identify potential statistically significant associations between data variables. (Certainly, association is not causation.)
A qualitative cross-tab analysis does not involve complex statistical assessments. Rather, it involves comparisons of various attributes and variables in a straight count of coded topics, sentiment-laden words, and other terms. The innovation here is the bringing in of code (manual, auto-created, and others), text data, and numerical data, for the identification of variable associations and data patterns. In the traditional quant-based cross-tab analyses, the data are numerical (and may include dummy and categorical variables).
A cross-tabulation analysis is often expressed in a matrix structure. Variables may be emplaced as columnar (vertical) or row (horizontal) data. (Figure 1)
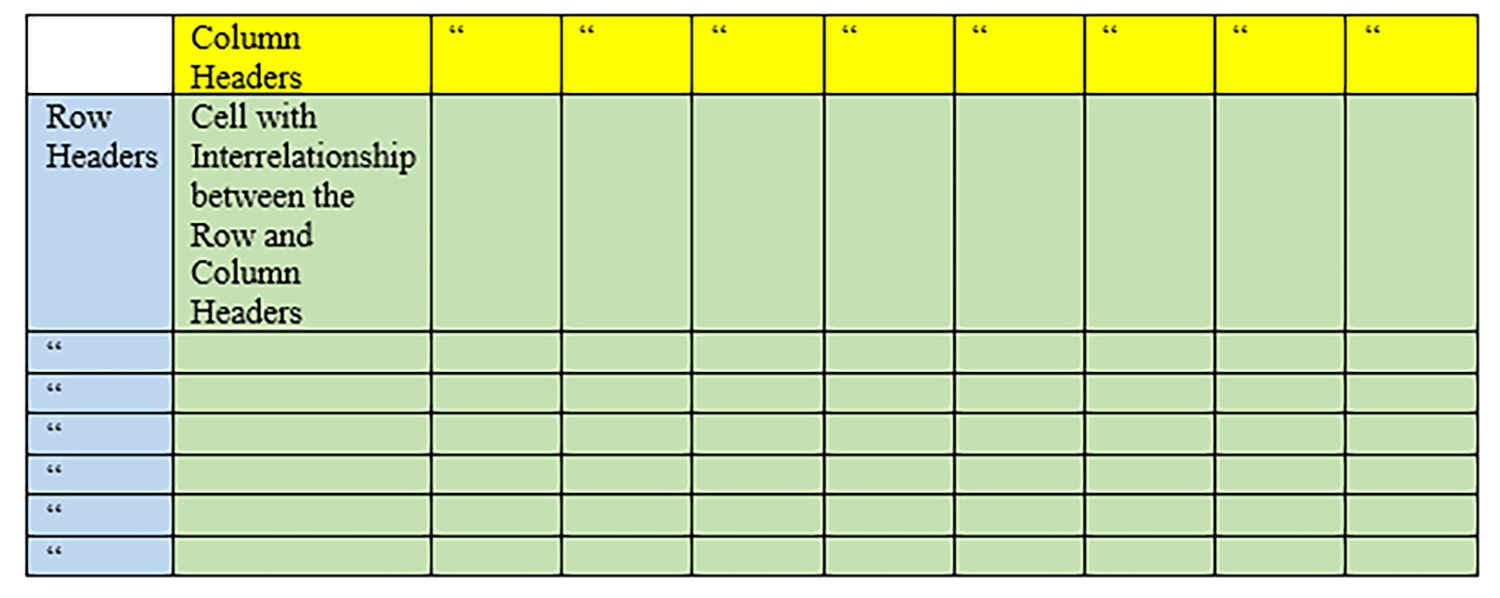{kind=link}
Figure 1. A Basic Matrix Structure for Cross-Tabulation Analyses (Quantitative and Qualitative)
To see how this feature works, two real-world datasets were used for these walk-throughs.
Setting up a Qualitative Cross-Tab Analysis in NVivo 12 Plus
Dataset 1: Proposed Presentations for #SIDLIT2018
To demo how this tool works, I am borrowing data from the 2018 proposals for SIDLIT 2018, collected on the Qualtrics Research Core Platform 2018. First, for each question, the numerical values were recoded to align with the intensity of the response (such as for Likert-like scale values) and to differentiate categorical variables. The original survey is comprised of some 61 responses. It is possible to download the data directly from Qualtrics and to then import it into NVivo 12 Plus.
Another option is to use the Qualtrics application programming interface (API) token to access data from NVivo 12 Plus. This approach enables autocoding of the data from the online platform. The Survey Import Wizard window may be seen in Figure 2.
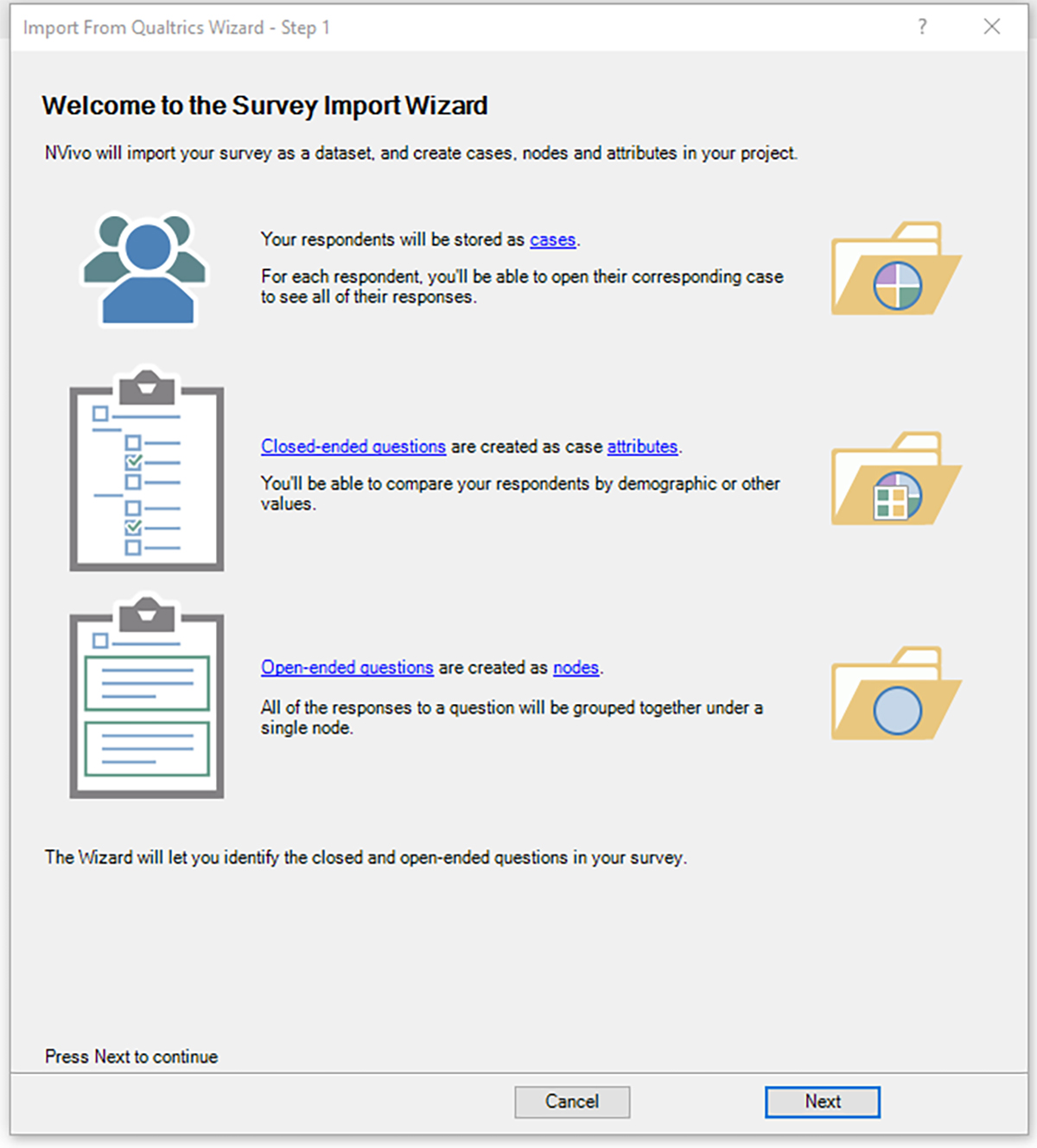{kind=link}
Figure 2. Survey Import Wizard in NVivo 12 Plus
In Figure 3, the survey data has been imported, with “cases” for the survey respondents (each row data), case attributes recorded using close-ended questions, textual nodes for open-ended questions, and the automated extraction of themes (topic modeling) and sentiment (positive to negative) from the text data.
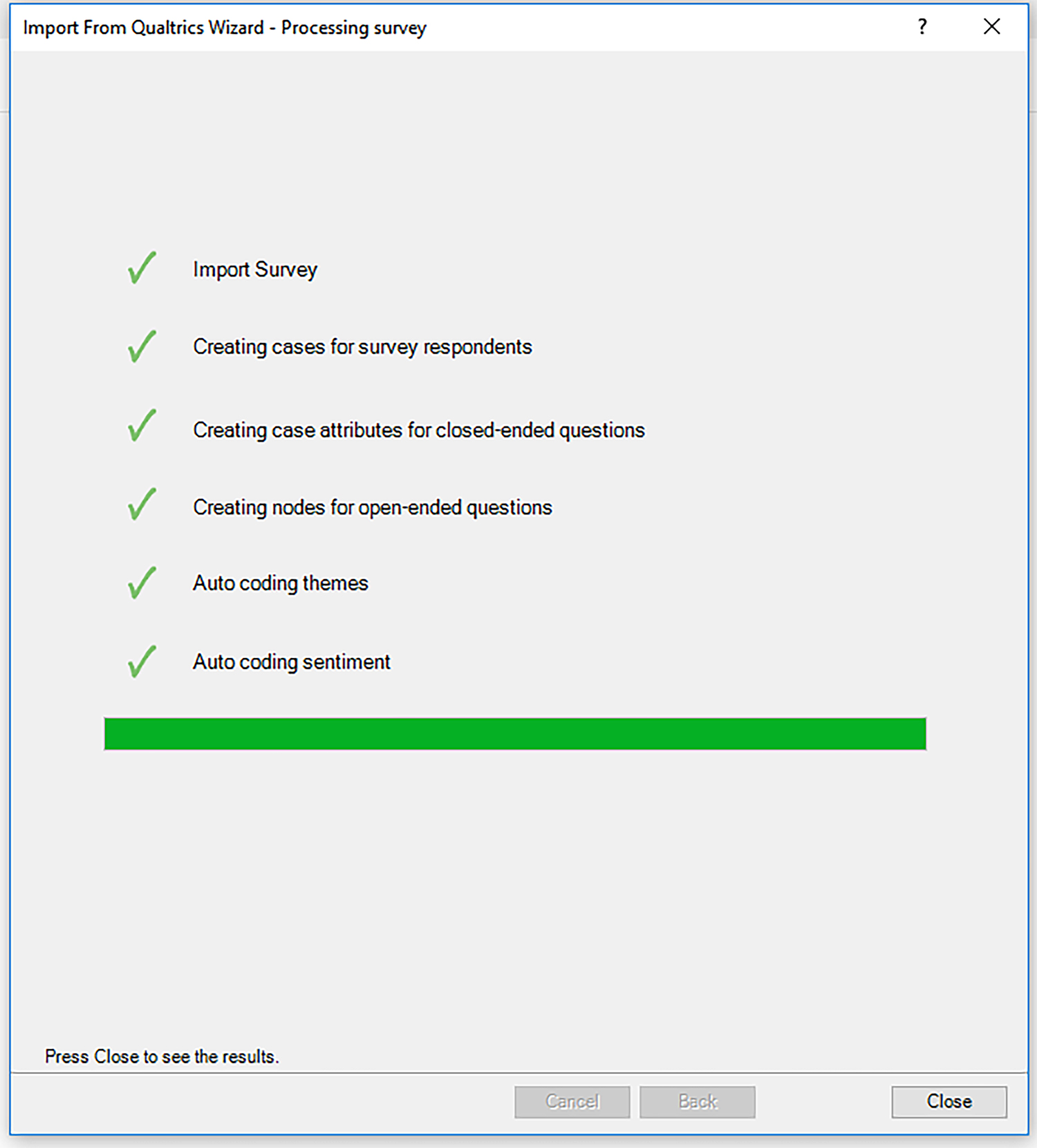{kind=link}
Figure 3. Auto-processing Survey Data for Cases, Nodes, Themes, and Sentiment
The ingested data may be seen in a typical data structure in NVivo (Figure 4).
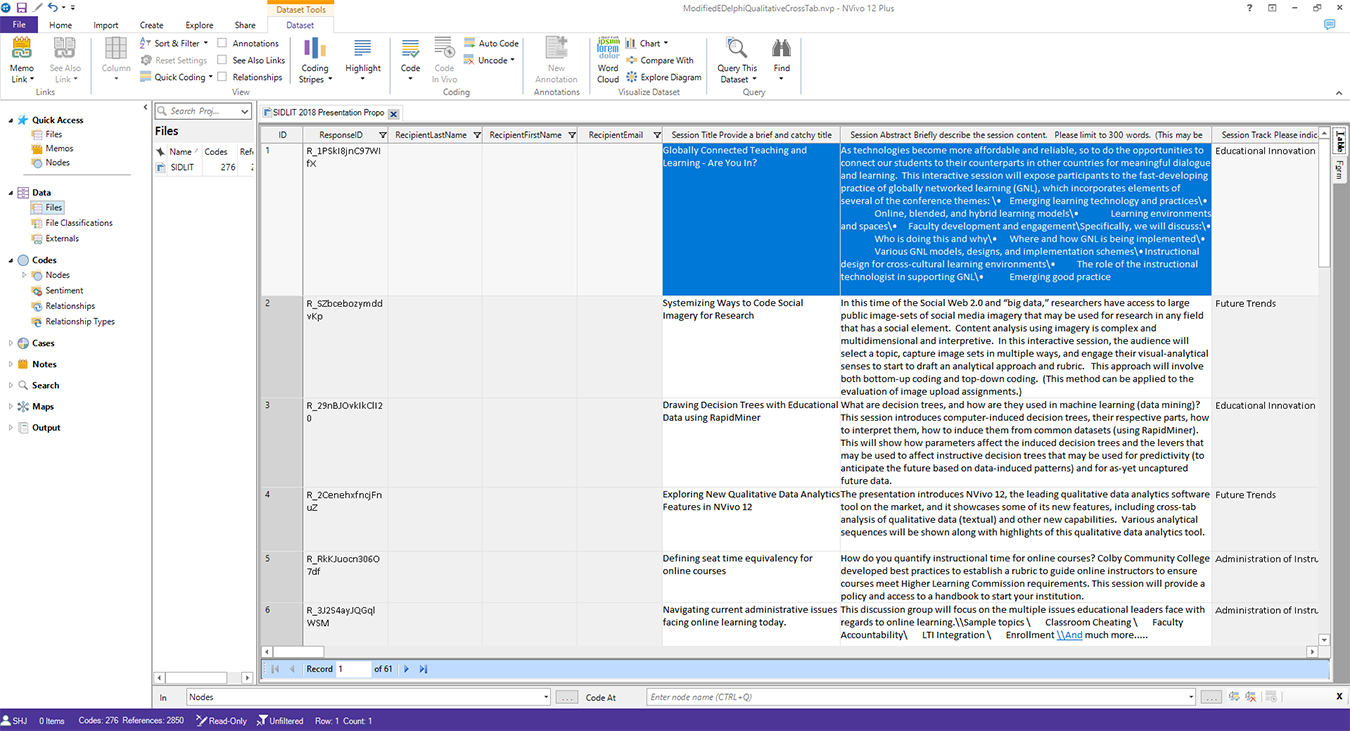{kind=link}
Figure 4. Ingested SIDLIT2018 Survey Data inside NVivo 12 Plus
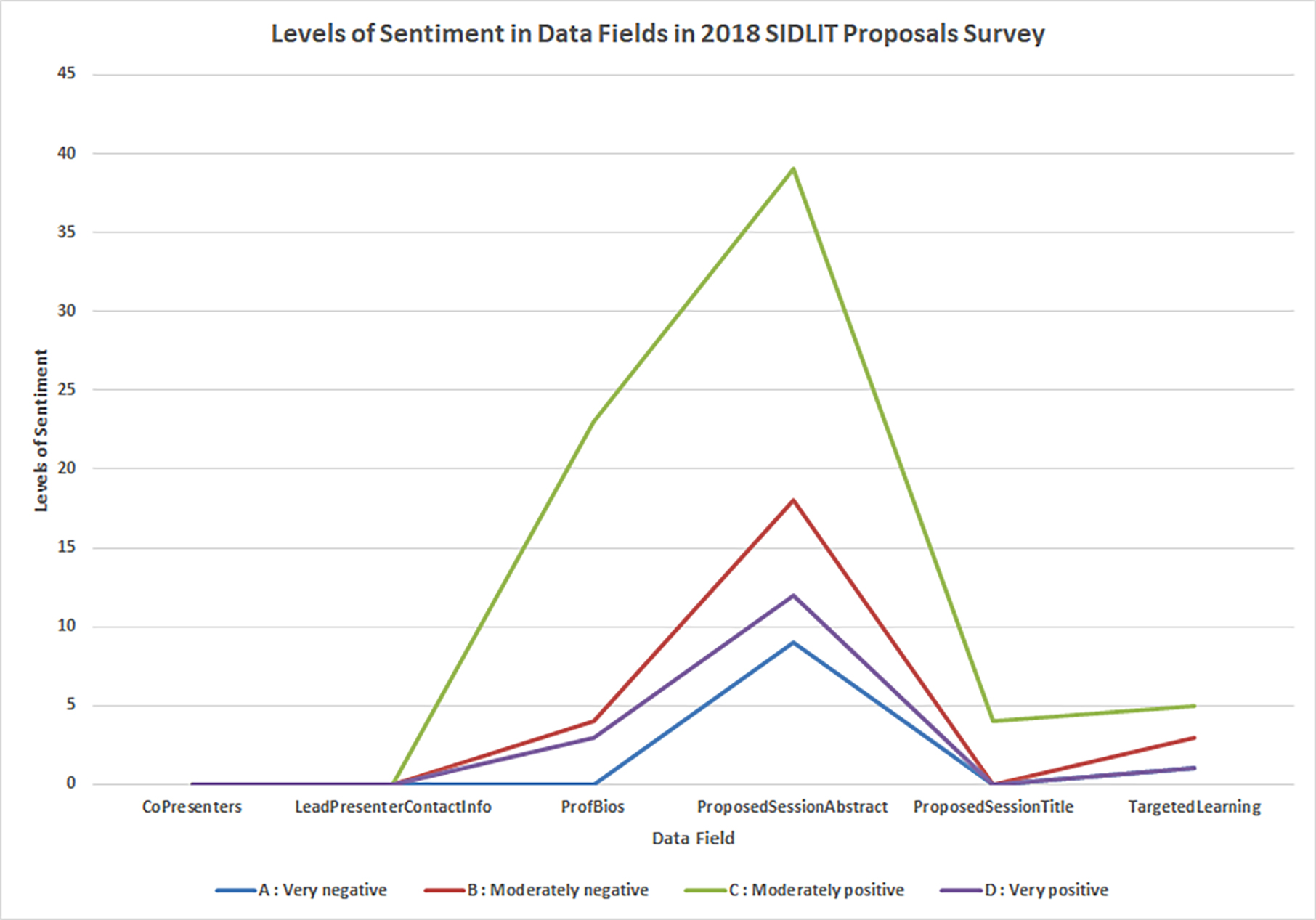
As part of the data ingestion, NVivo codes the textual data fields for sentiment in four categories: Very negative, Moderately negative, Moderately positive, and Very positive (or in binary format of Positive or Negative). Most language does not carry sentiment, but sentiment may be seen in the following fields: what attendees will learn from the sessions, session abstracts, and professional biographies. Titles tend to be either neutral or positive (without negative terms). Contact information and such do not tend to be sentiment-bearing. (Figure 05)
{kind=link}
Figure 5. Identified Sentiment from Text Fields in the SIDLIT2018 Dataset
The varying levels of sentiment may be seen in Figure 06.
{kind=link}
Figure 6. Levels of Sentiment in Data Fields in 2018 SIDLIT Proposals Survey
A word cloud (based on a word frequency count) summarizes some of the more popular terms in the session proposals for SIDLIT 2018. (Figure 7)
{kind=link}
Figure 7. Word Cloud of Terms in the Proposed Presentations for SIDLIT 2018
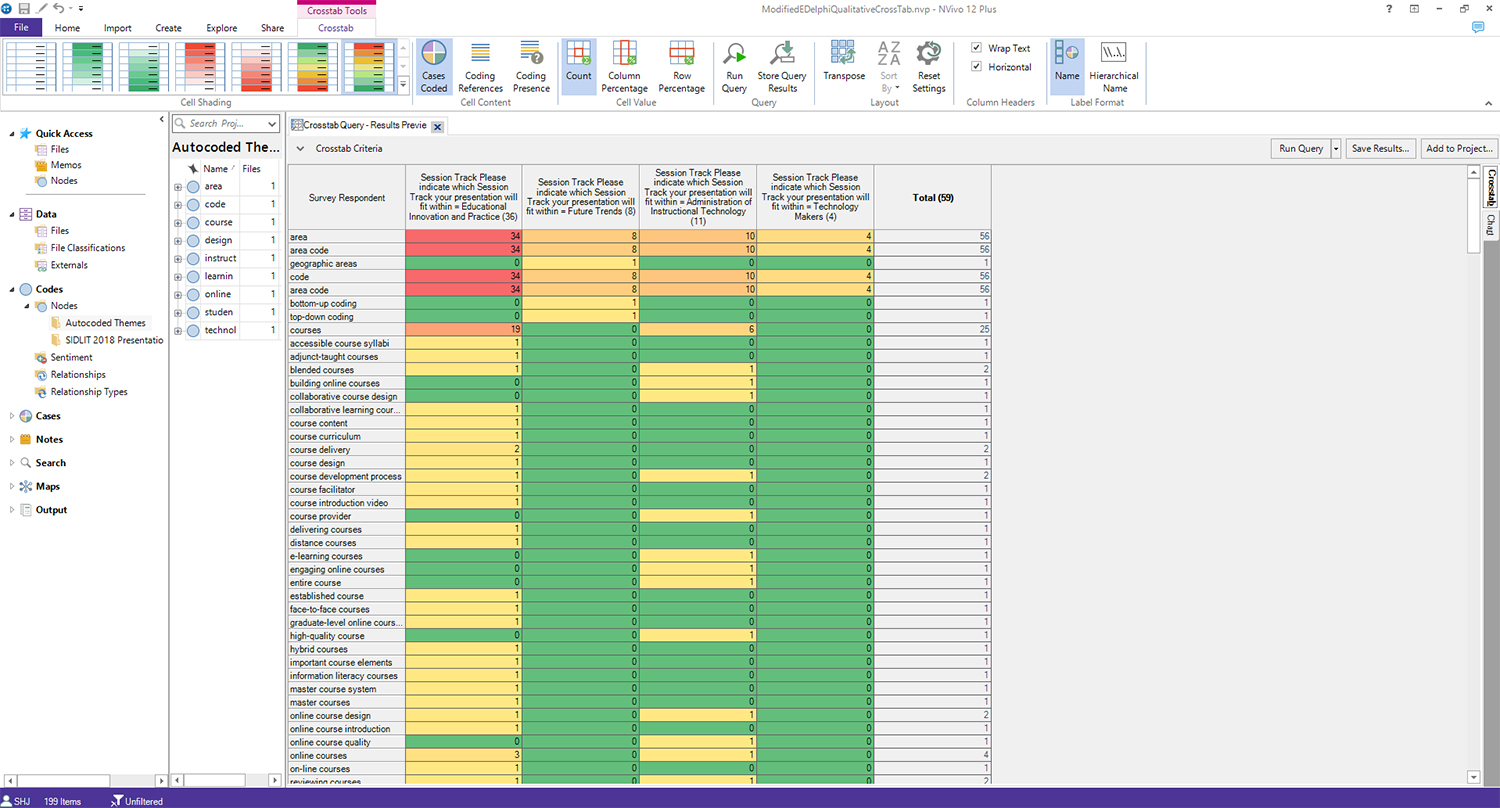
The first qualitative cross-tab analysis from this dataset involved comparing autocoded themes on one axis to the identified presentation tracks. (Figure 8)
{kind=link}
Figure 8. Comparing Declared Session Tracks by Users with Autocoded Themes from Session Descriptions
In this matrix, the most popular tracks (as identified by the software, not the potential presenters) were as follows (in descending order): Educational Innovation and Practice (36), Administration of Instructional Technology (10), Future Trends (8), and Few in Technology Makers (4).
Dataset 2: Recent Tweestreams from @NVivobyQSR and @QSRInt on Twitter
@NVivobyQSR, at the time of the data capture, had 5,190 Tweets, 1,368 Following, 4,021 Followers, 1,638 Likes, and 5 Lists. The landing page may be viewed below. (Figure 9)
{kind=link}
Figure 9. @NVivobyQSR Twitter Landing Page
A related site by the same software maker, QSR International, @QSRInt, had 12 Tweets, 87 Following,
72 Followers, and 5 Likes. The landing page may be seen below (Figure 10).
{kind=link}
Figure 10. @QSRInt Twitter Landing Page
For both of these microblogging accounts, the recent Tweets were captured as a dataset including retweets (so a sense of popularity of messaging could be captured instead of just one example of each microblogging message captured from each account).
These additional sets of social media data were captured in order to try to use the “Attribute” feature in the qualitative cross-tab analysis tool in NVivo. Below, the two datasets were treated as “cases” with “organization” classification sheets modified for the Tweet, Following, Follower, and other metrics as attribute data of the respective accounts. (Figure 11)
{kind=link}
Figure 11. Editing Case “Classification Sheet” Attributes in List View in NVivo 12 Plus
Several data runs were conducted using the respective attributes…to see if any of them had associations with autocoded topics, with sentiment, and so on. Multiple cross-tab analyses queries were run with no results. A basic cross-tab analysis of the two sets (as cases) with the auto-extracted high-level topics (in alphabetical order) was run, resulting in a side-by-side comparison (Figures 12 and 13).
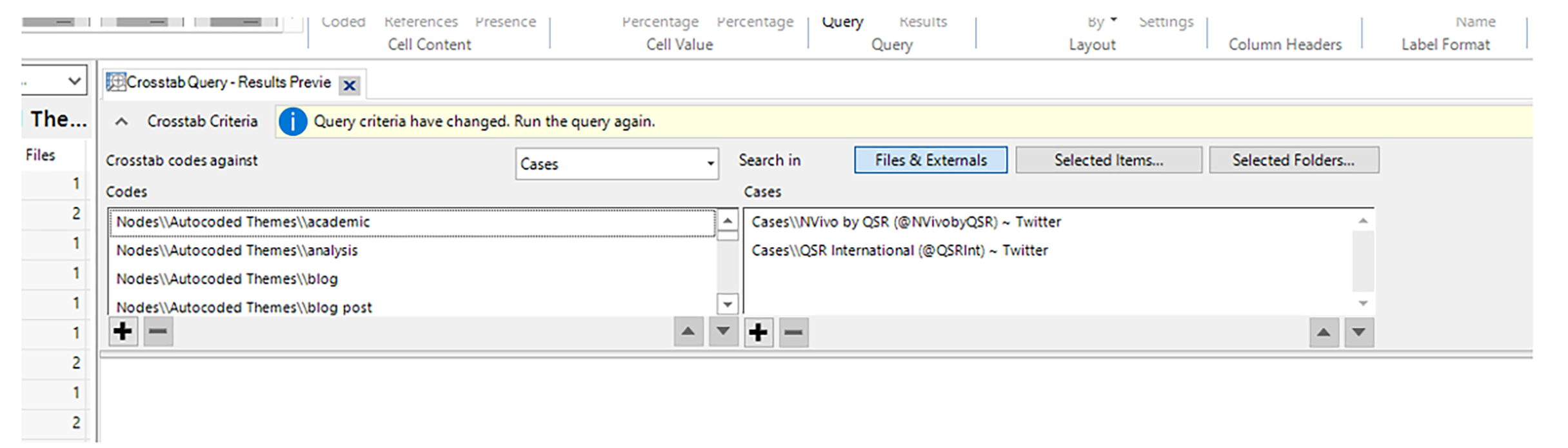{kind=link}
Figure 12. Setup of the Cross-Tab Query in NVivo 12 Plus with Themes in the Left Window and the Datasets in the Right
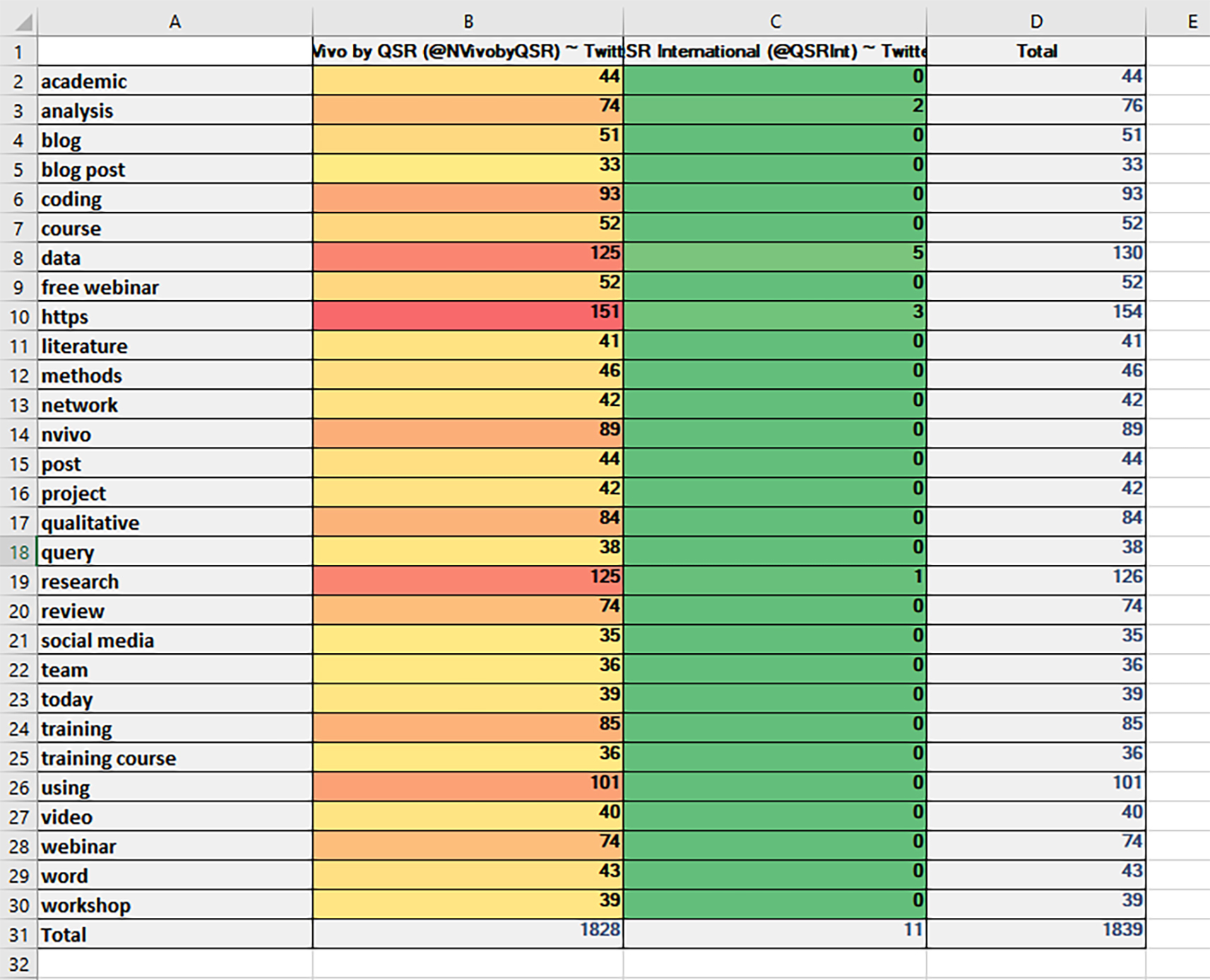{kind=link}
Figure 13. Extracted Themes of the @NVivobyQSR and @QSRInt Tweetstreams
The same data in Figure 13 may be seen below as a stacked vertical bar chart (or column chart) (Figure 14).
{kind=link}
Figure 14. Autocoded Topics from Related QSR International Tweetsets in a Vertical Stacked Bar Chart
A word cloud was created from these topics as a rough summary of term frequency (seen as a proxy for term popularity). (Figure 15)
{kind=link}
Figure 15. A Word Cloud of the Most Popular Words in the Twitter Microblogging Datasets
Even though the initial ambition was to use the Attributes feature of the qualitative cross-tab analysis tool, none of those actually resulted in any counts. Ultimately, these look more like matrix queries.
For more on NVivo 12 Plus’s crosstab query feature, including with the uses of attribute data, please visit their site at the prior link.
The uses of attributes are important because they enable researchers to see if there are patterns in responses to interviews, surveys, and focus groups based on respondents’ demographic data (age group, gender, class, education level, geographical location, livelihood, and other features). Attributes may be applied to individuals (egos) and groups and organizations (entities). In qualitative research, suggestions of nuanced patterns may be powerful, and these may offer a path forward for further exploration and hypothesizing.
By contrast, the more traditional cross-tabulation analysis involves some basic assumptions of the data—that it is random, that the variables are mutually exclusive, and that they are independent (no multi-collinearity or collinearity). Another assumption is that the data in the cells are assumed to fall in a normal distribution if the null hypothesis is true (and cannot be rejected), or that only random chance is affecting the data. There are several basic statistical calculations. The core consideration is what the expected values are per cell, based on the following:
- degrees of freedom (number of rows minus one multiplied by the number of columns minus one)
- the chi-square statistic (the measure of how observed values compare to expected values in each cell)
- the p-value (the measure of statistical significance (evidence against the null hypothesis being true, that only chance is affecting the data)
The rigor of quantitative cross-tabulation analyses is different than for qualitative ones. The assertions that can be made from each also differ.
About the Author
Shalin Hai-Jew works as an instructional designer at Kansas State University. Her email is shalin@k-state.edu.
The author has no formal tie to QSR International, the maker of NVivo.
| Previous page on path | Cover, page 16 of 22 | Next page on path |
Discussion of "NVivo 12 Plus’s New Qualitative Cross-Tab Analysis Function"
Add your voice to this discussion.
Checking your signed in status ...