Creating Article Theme Histograms to Map a Topic
By Shalin Hai-Jew, Kansas State University
Whenever there are new capabilities in popular software tools, it is helpful to think about what affordances come with the new features. In late 2015, QSR International rolled out NVivo 11 Plus, with a topic modeling capability which they termed “theme and sub-theme” autocoding. What this feature essentially does is capture potential themes and sub-themes from individual texts or text corpora, without any prior inputs from the person using the software.
{kind=link}
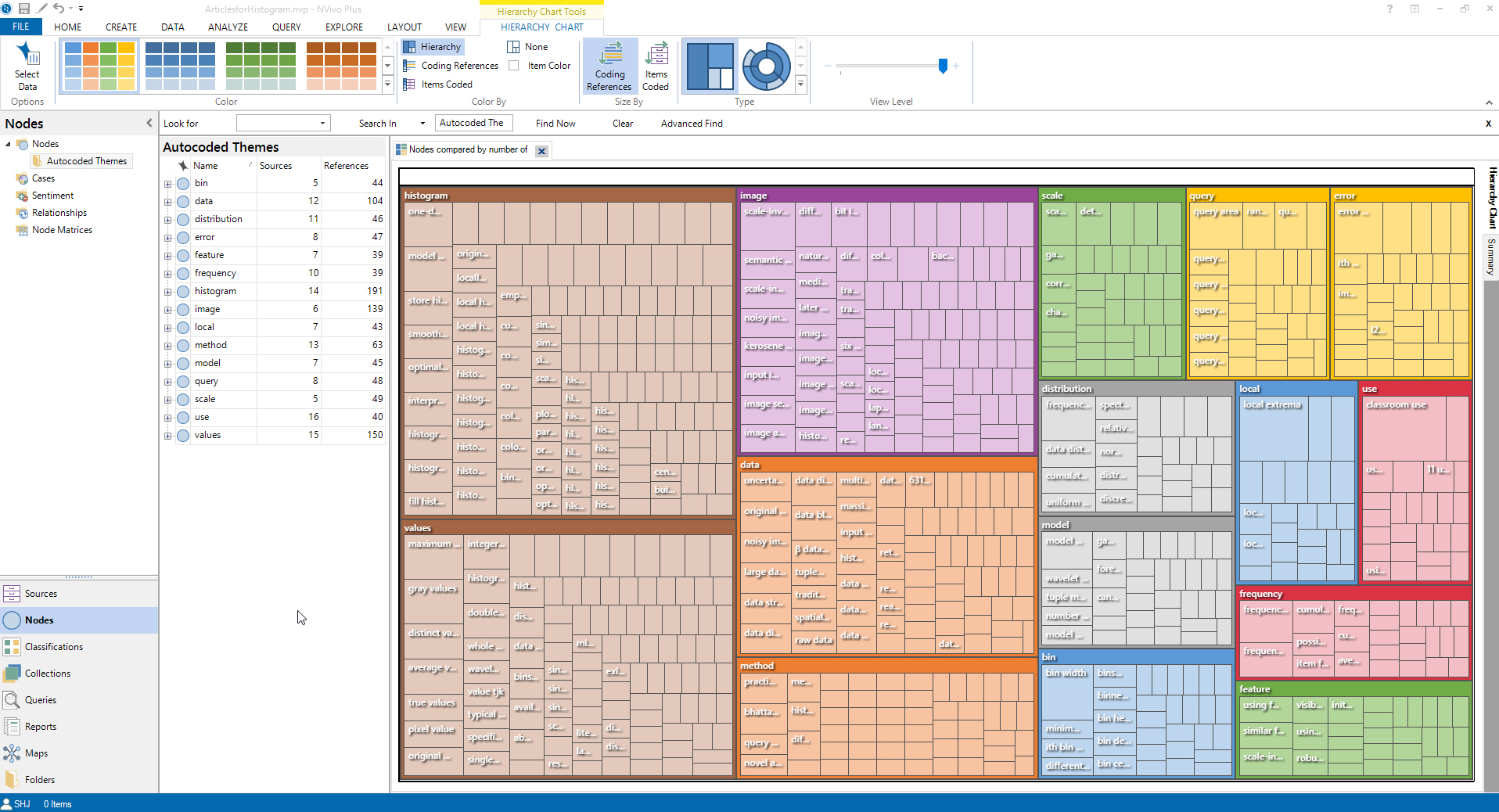
Figure 1: Article Theme Histogram Project in NVivo 11 Plus
A Brief Overview
This approach is termed “unsupervised machine learning” because the data mining is done without the need for a person to tell the machine how to capture the themes and sub-themes and does not include any initial seeding terms or parameters.
In the broader community, topic modeling has been around since the late 1990s (“Topic model,” May 3, 2016, Wikipedia, https://en.wikipedia.org/wiki/Topic_model). Computer scientists, through the years, have proposed a number of methods and various algorithms to capture topics from texts. The approaches are more complex than mere word frequency counts. The actual sequence of data categorization and extraction, though, is not fully clear and is not officially defined by QSR International.
With the need to improve searchability and information retrieval for digital contents—both in data repositories and the wider Web and Internet—topic modeling capabilities have been in high demand for decades but has only recently been available to the wider community of researchers through integrated software tools.
One Use Case
This article introduces one use case for this extraction of the themes and sub-themes from text sets. The idea is that a researcher can collect a number of formal articles and less formal ones into a collection, then run the theme and subtheme autocoding tool over the texts…and be able to identify articles of interest for a close reading. In other words, the computer itself identifies the main themes in the articles, and human readers can be more discerning about which works they will read based on what contents are likely in the actual work.
An Overview of the Process
A brief summary of the process follows. First, the individual should collect related articles and other contents from various sources. For this demonstration, 17 articles about “histograms” were collected.
Generally, histograms are data visualizations that show the distribution of numerical data. A classic histogram is conceptualized as summarizing the probability distribution of a continuous quantitative variable. One common example is a color photo histogram which shows the amounts of red, green, and blue, for example.
In this case, an article histogram is a somewhat analogous conceptualization but without continuous variables. In this case, the rectangle or bar areas represent the class interval for a particular theme (topic).
Rather, this is a non-parametric version of a histogram, and the frequencies counted are themes (with embedded subthemes). (If the themes extracted are representative of all possible relevant themes from the set, then the histogram may be even more apt of a visualization.)
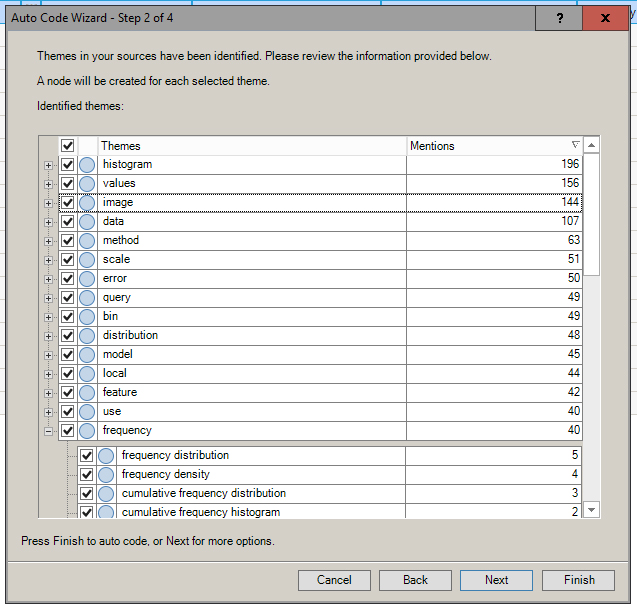
The articles were highlighted in the Source files, and the Autocoding wizard was started to run the theme and sub-theme analysis. Figure 2 shows the second step of this process, during which the themes and subthemes may be explored and unwanted themes / subthemes may be unchecked and removed from the processing (Figure 2).
{kind=link}
Figure 2: An Initial Extraction of Themes and Subthemes for User (Non)Acceptance
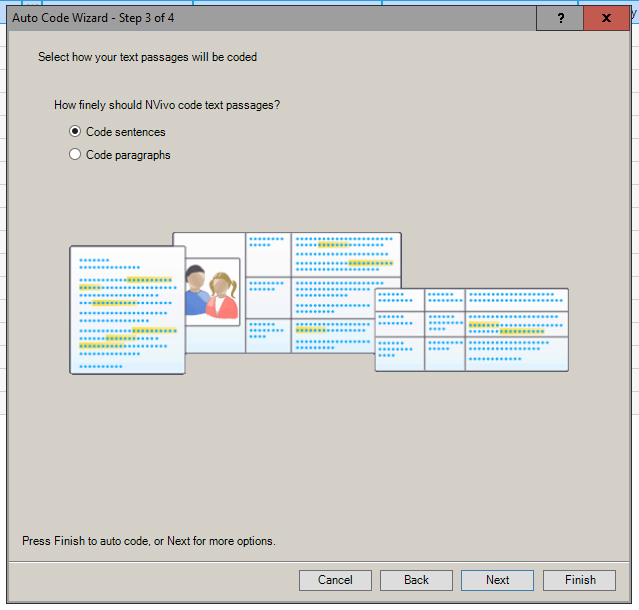
In Step 3, users can choose to apply this thematic coding at sentence or paragraph level. (If the data were in data tables, there would be the third option of coding at data cell level.) The sentence level is more granular than the coarser paragraph level of coding. If one selects coding at sentence level, there will likely be higher theme and subtheme counts than at paragraph level. (It is hard to generalize about cell level coding because what coding emerges will depend on the type of data in the data tables and what is contained in each cell. For example, online survey data is extracted in data table format and may contain single counts, sentences, microblogging messages, or paragraphs, or even other contents in one cell.) In this case, NVivo 11 Plus was asked to code to sentences (Figure 3).
{kind=link}
Figure 3: Step 3: Deciding Whether to Apply Accepted Theme / Subtheme Coding at Sentence or Paragraph Level
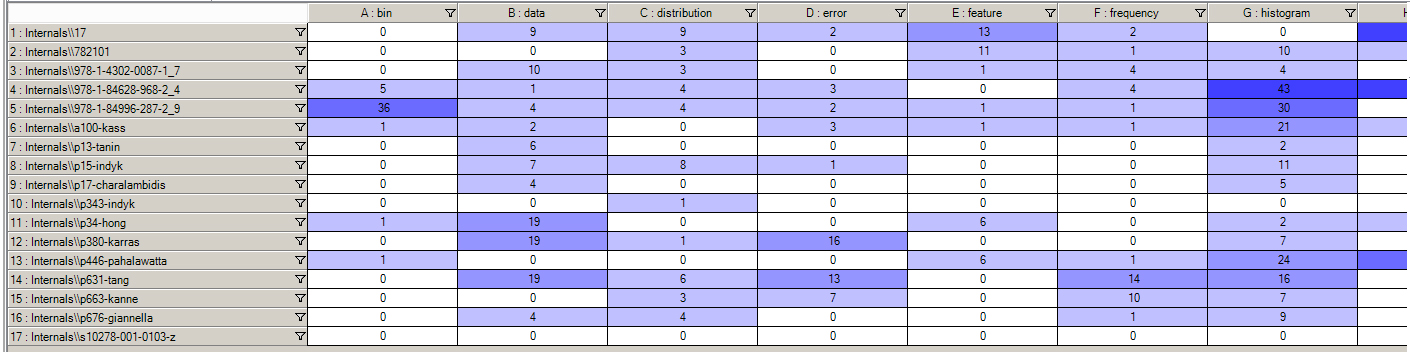
In the next step, the findings are reported out as an intensity matrix. The items in the left column are the respective articles. The themes are listed across the column headers. In the intersecting cells of the intensity matrix are numbers representing the identified counts of the theme’s appearance in each article. The higher the number of counts, the darker the color in the cells. White cells, listed as 0, indicate that the particular theme was not found in that particular article. The resulting matrix is known as a somewhat sparse matrix because there are quite a few cells which register 0 (Figure 4). This is typical for term-document matrices, which tend to have well below 1% non-zero cell entries.
Article 17 actually has no counts of any of the main themes from the collection. This may mean that the article is an outlier in terms of a thematic focus, or it may mean that the article itself maybe does not belong in this particular set and was mistakenly selected for inclusion.
{kind=link}
Figure 4: A Source-Node Intensity Matrix Showing Articles in the Rows and the Extracted Themes in the Column Headers
The same theme results may be seen in Figure 5, albeit as a bar chart.
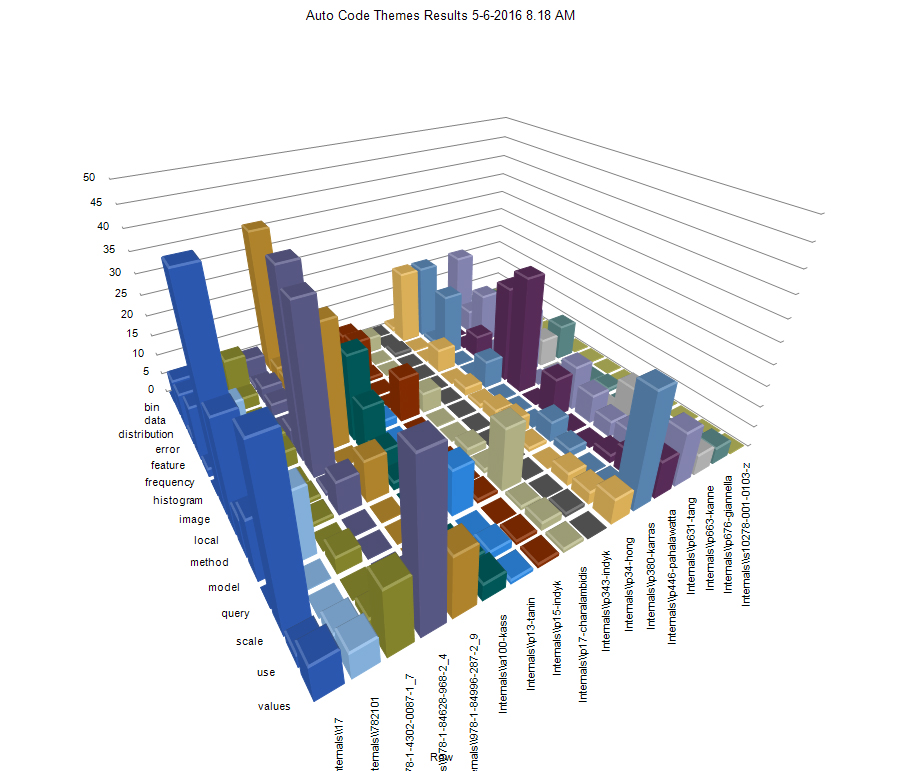{kind=link}
Figure 5: A Bar Chart of the Articles and Themes
In Figure 6, the same data may be viewed as a treemap diagram. This diagram is known as a hierarchical visualization because it shows interrelationships between various elements in a hierarchy, in this case, the most popular topic to the least from the top left to the bottom right.
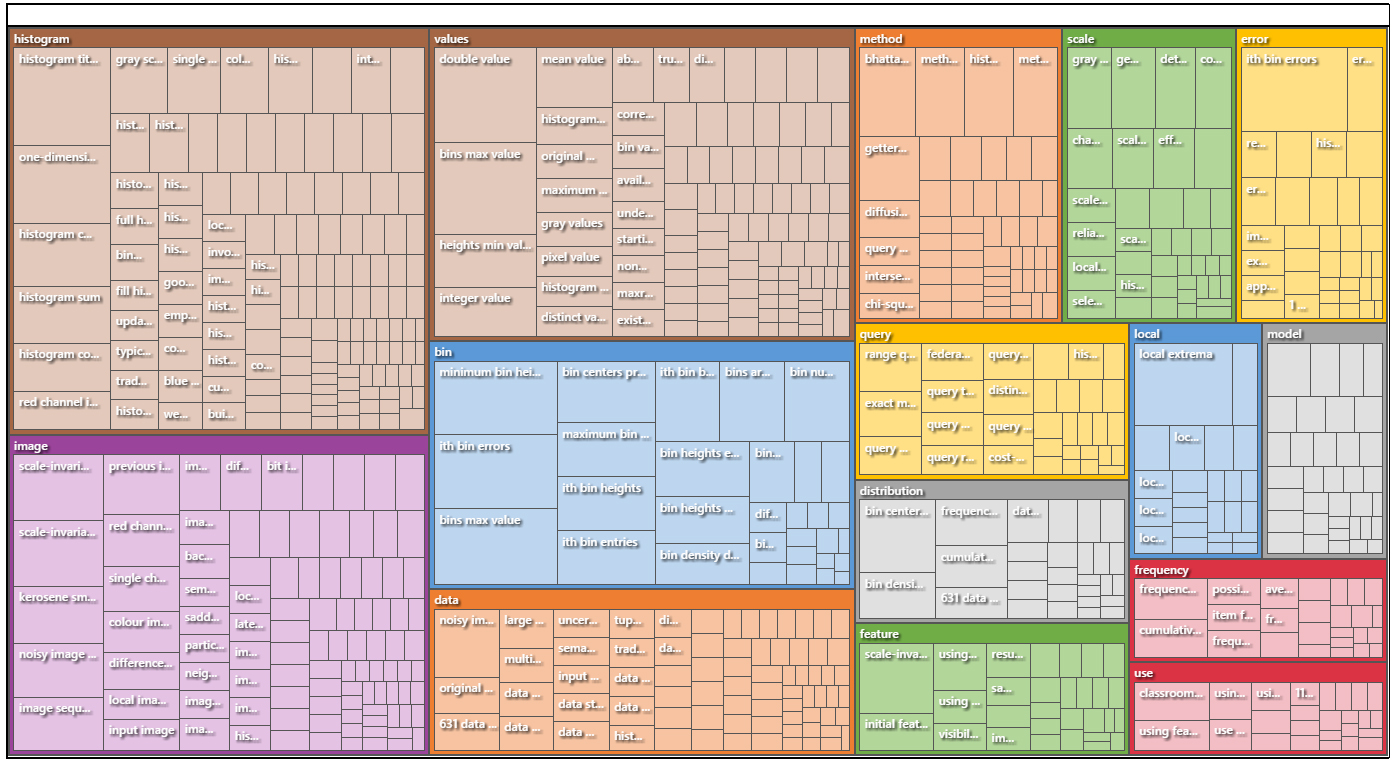{kind=link}
Figure 6: Summary View of Extracted Themes and Subthemes in a Treemap Diagram (Hierarchy Chart)
There is a second type of hierarchical data visualization in this workflow, and that is a sunburst. In Figure 7 is a sunburst visualization of the same data.
{kind=link}
Figure 7: An Interactive Sunburst of the Extracted Themes and Subthemes
It is possible to double click on a particular theme in order to see the related subthemes, which look to be literal versions of the top-level theme but versioned to capture other meanings based on words-in-proximity.
{kind=link}
Figure 8: Exploring a Theme and its Subthemes
Finally, using this same data from the data matrix, it is possible to export the data to Excel and create simple article theme histograms. An example may be viewed as Figure 9. The higher bars show higher frequencies of the particular term. The themes are listed in alphabetical order on the x-axis, and the frequency counts are on the y-axis as straight numerical counts. “Image” is the most popular theme in Article 1, followed by “Scale” and “Local.” It helps to notice that themes are listed as unigrams (single words), and no bigrams (two words in a particular order) or trigrams, etc. Also, it helps to notice that the subthemes are encapsulated and hidden within the singular bar.
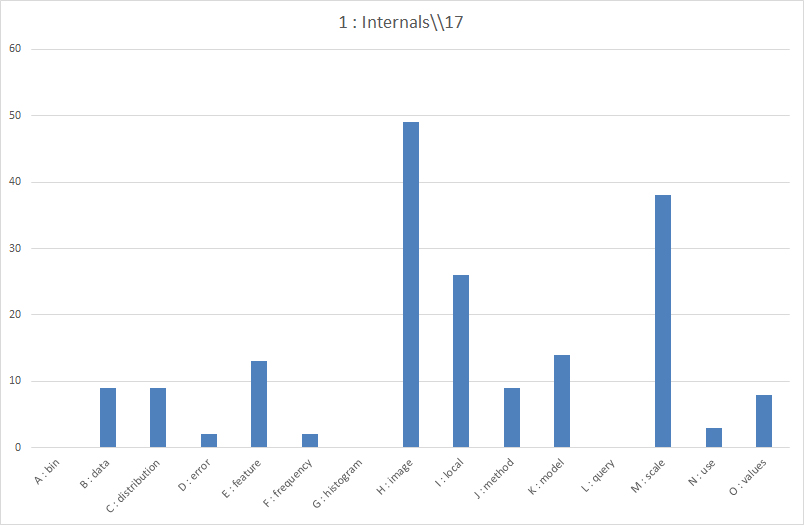{kind=link}
Figure 9: Reading an Article Histogram
The extraction of theme and subthemes suggest a way to compare article closeness or distance with other articles in the set based on whether the articles have themes and subthemes in common. To view the sequence of the 17 articles captured in the convenience sample, please go to the following digital slideshow. (The articles are listed in no real order except by alphabetization based on the file names of the various databases from which these were downloaded.)
Figure 10: Article Theme Histograms in a Digital Photo Album
Or, to view this in a new window, please go to this link.
Finally, a basic linegraph may be used to show comparisons of topic coverage. In the figure below, only half-a-dozen articles were selected. Too many more, and this becomes visually confusing and even incoherent.
{kind=link}
Figure 11: Comparing Six Articles' Main Themes from the Set
Also, it is possible to set a threshold for frequency counts above which a work is important or relevant...or worthy of a human close reading.
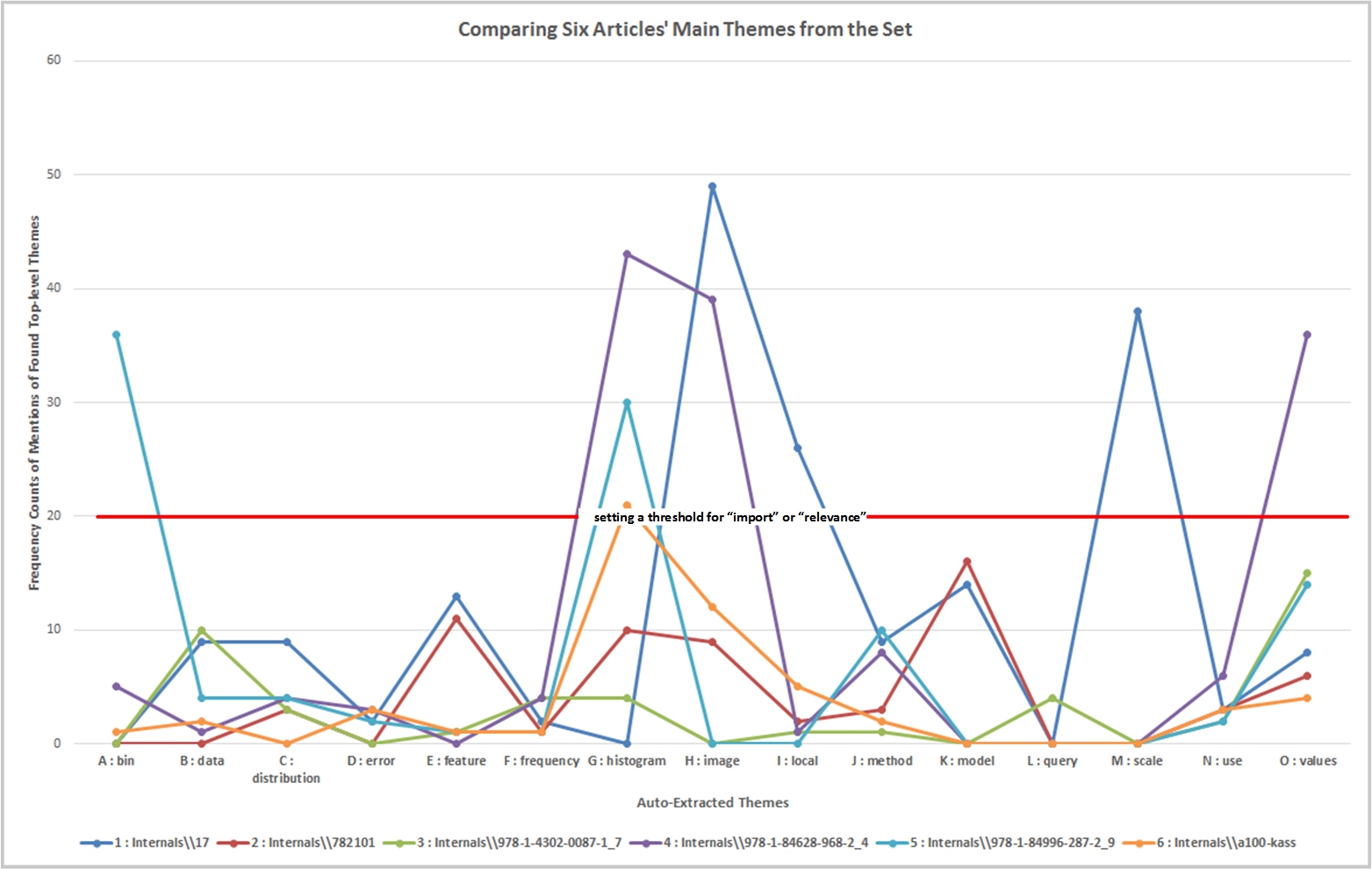{kind=link}
Figure 12: Setting a Threshold for "Import" or "Relevance"
In the title, the suggestion is that a topic may be mapped using this method. This assumes that all articles which list this topic are captured and are integrated in the theme and sub-theme extraction. After a certain number of articles, though, the software (which runs on the local PC) will be unable to handle the amount of information. The software running on a server with plenty of data storage space and computing power would handle big data much more efficiently. This walk-through, which was purposefully limited, does not show a comprehensive representation of research into histograms.
Other Variations
It would be possible to map an article histogram with its sub-themes represented, such as in a stacked bar chart.
If the articles were actually sequenced by time, it would be possible to see how topics in a topic set (or a "document space") evolved over time based on researcher expertise, interests, funding, and other factors.
About the Author
Shalin Hai-Jew works as an instructional designer at Kansas State University. She may be reached at shalin@k-state.edu.
| Previous page on path | Issue Navigation, page 17 of 25 | Next page on path |
Discussion of "Creating Article Theme Histograms to Map a Topic"
Add your voice to this discussion.
Checking your signed in status ...