Statistical thinking: Statistical inference
As consumers of information, students interpret findings derived by common methods of statistical inference. They articulate how common statistical findings are derived, as well as common errors that bedevil statistical inferences.
Samples and the Population
Students recognize that a large, random sample can tell us about the total population.
They recognize that a full account of these findings will include statements of confidence and error. In other words, students recognize the powerful implications of the central limit theorem and standard error.
The central limit theorem
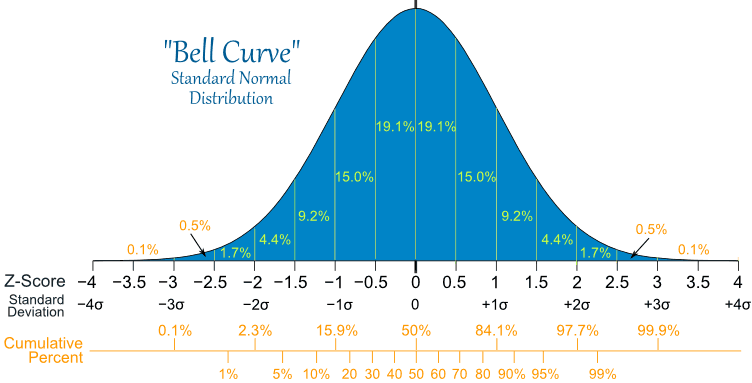
The central limit theorem states that “the sample means for any population will be distributed roughly as a normal distribution around the population mean.” This is true even if the distribution of the population is NOT normal.
In other words: If we want to know something about a population (say, the mean household income in the U.S.), we can't usually ask everyone, so we take a random sample. If we were to take one random sample, and find the mean of that sample, that mean will almost certainly be somewhat greater or lesser than the mean of the entire population. We want to know how much greater or lesser the sample mean is from the mean of the population. The central limit theorem gives us the likelihood that our sample falls into a given range surrounding the population mean--following the normal distribution.
{kind=link}
The standard error
Students understand that the standard error “measures the dispersion of the sample means. How tightly do we expect the sample means to cluster around the population mean?” The higher the number in the sample, the lower the standard error.
Students understand that any statistical inference must be accompanied by a confidence interval. And they realize that a confidence interval is necessary due to variability in the data (not due to errors or malice).
“Because the sample means are distributed normally (thanks to the central limit theorem), we can harness the power of the normal curve. We expect that roughly 68 percent of all sample means will lie within one standard error of the population mean; 95 percent of the sample means will lie within two standard errors of the population mean; and 99.7 percent of the sample means will lie within three standard errors of the population mean.”
In other words, statistical findings should include both a standard error and a confidence level (for instance, 95 percent
confidence that the sample mean falls within two standard errors). These numbers will help us to interpret the significance of the finding.
- Polls usually include a margin of error, such as +/- 3%. The margin of error is based on the standard error for the finding, so like the standard error it decreases as the number in the sample increases.
- Polls often do not report the confidence level. As a result, as consumers we do not usually know how many standard errors the margin of error represents.
- If a poll reports that 54 percent of voters favor proposition X, with a margin of error of +/- 2%, we will be tempted to assume that the population lies between 52 and 56 percent. But this assumption must fall within a confidence interval. For many polls, the findings are reported within a confidence interval of 95 percent. In other words, 5 percent of the time, the total population's opinion will be higher or lower than the findings report (in this case, higher than 56 or lower than 52).
- Another way to think about it: we often assume that a small margin of error means that a finding is more accurate. But it could be that the margin of error is small because the confidence level is low.
- Pollsters can report with greater confidence if they increase the sample size OR if they increase the margin of error.
Statistical significance
Students recognize that some findings are statistically significant, that is, the association between two variables is probably not due to chance. They recognize the implications and limitations of statistical significance.
Statistical significance is crucial when comparing two groups (control and treatment, for instance, or, in within-subject experiments, comparing two conditions).
Statistical significance allows researchers to reject a null hypothesis in favor of a complementary alternative hypothesis.
Example: Is drug X effective?
- Null hypothesis: drug X is no more effective than a placebo.
- Complementary alternative hypothesis: drug X is more effective than a placebo.
Statistical significance is often expressed as a p-value, which is the probability that the finding is a coincidence rather than a reflection of real difference between groups. The typical threshold for significance is 5 percent (in other words, the sample mean is within two standard errors of the population mean).
In other words, on average, 19 out of 20 findings deemed statistically significant will actually be significant, and 1 may not actually be significant. Replication of experiments is therefore a crucial part of the scientific process.
Common Problems
Students evaluate statistical findings within the context of sample size.
- It is difficult to establish statistical significance with a small sample size. There is a difference between “finding no effect and finding no statistically significant effect (especially with small samples).”
- Statistically significant findings are not necessarily large findings. There is a difference between “statistical significance and practical importance (especially with large samples).”
Students evaluate the trade-offs between two major errors in statistical inference.
- Type I error: Wrongly rejecting a null hypothesis—a false positive. Wrongly thinking that drug X is effective, in other words wrongly rejecting the null hypothesis that it is not more effective than a placebo.
- Type II error: wrongly accepting a null hypothesis—a false negative. Wrongly thinking that a drug Y is not an effective treatment, in other words wrongly accepting the null hypothesis.
Because statistical inference is not 100 percent accurate, we have to evaluate the tradeoffs between the two types of errors:
- Email spam filters (null hypothesis = it’s not spam): It is probably acceptable to have Type II error that allows spam into your email, but probably not acceptable to have a Type I error that diverts a good and valuable email.
- Smoke alarms (null hypothesis = no fire): It’s probably ok to have have Type I error that means your smoke alarm is too sensitive, but probably not acceptable to have a Type II error that misses a fire.
- Terrorism (null hypothesis = there is not a terror threat): Neither kind of error is acceptable; a Type I error will lead to the arrest of innocent people, and a Type II error will allow a terrorist attack to occur.
| Previous page on path | Statistical thinking, page 7 of 8 | Next page on path |
Discussion of "Statistical thinking: Statistical inference"
Add your voice to this discussion.
Checking your signed in status ...