Creating Combo Charts in Excel 2019
By Shalin Hai-Jew, Kansas State University
A “combo chart” in Excel basically involves two or more chart types synthesized into one data visualization. A chart type refers to how data are represented—as a pie chart, an area chart, a line graph, a bar graph, and so on. A “combo” combines two or more types, ideally in a coherent and analytically valuable way.
A review of some examples of “combo charts” in Excel shows some cool feats:
- Cluster charts overlaid with line graphs, each representing related information and maintaining a sense of analytical coherence (one had six different data sources)
- A green exploding pie chart with a vertical bar chart, an area chart, a line graph, and scatter points forefronted
- An area chart with a line graph overlaid over it
- A stacked bar chart overlaid with a line graph
- A pie chart with an x-y scatter chart
Some of the data visualizations deal with faux data that provides a neat look-and-feel, but there are others that are clearly built off real data and are even more impressive. After all, the point of a data visualization is not only to attract attention but to convey information for analysis (while not enabling misapprehensions).
The display not only uses overlapping data visualizations, but it expands the left vertical primary axis with a right vertical secondary axis (y-axes) (for double vertical axes), and there can also be an accompanying horizontal axis to the x-axis at the bottom with one on the top (for double horizontal axes). The design of combo charts seems to be to enable comparability even with phenomenon with differing units of measure, to identify data patterns.
Basic Steps to Creating a Combo Chart in Excel 2019
The type of data that may be depicted with combo charts are essentially numerical data values for variables that may have some interaction effects or associations.
To see how this might work, the “Inpatient Prospective Payment System (IPPS) Provider Summary for the Top 100 Diagnosis-Related Groups (DRG) – FY 2011" dataset was used. This dataset contains 163,000 rows and 12 columns. Three contiguous columns are of current interest: the Average Covered Charges, Average Total Payments, and Average Medicare Payments.
Open the .csv download. Highlight the columns of interest. In this example, three were selected. (Figure 1)
{kind=link}
Figure 1. Three Data Columns of Interest Highlighted
Go to the Insert tab. Select the Combo Chart icon, and select it. There are three options:
- Clustered Column – Line
- Clustered Column – Line on Secondary Axis
- Stacked Area – Clustered Column
The first combines a vertical column chart with a line graph. The second combines a clustered column (a variable with multiple values) with a line graph albeit with the line mapped to the right vertical secondary axis. (This requires that the data come in groupings or clusters, with different values within each cluster.) The third offers a stacked area chart in the background for some part of the data and clustered columns in the foreground. The proper selection of which chart type should be used depends on the alignment of the data visualization with the underlying data.
A quick rough of the three types can be made even when the data itself may not be ideal to the context. (Figure 2)
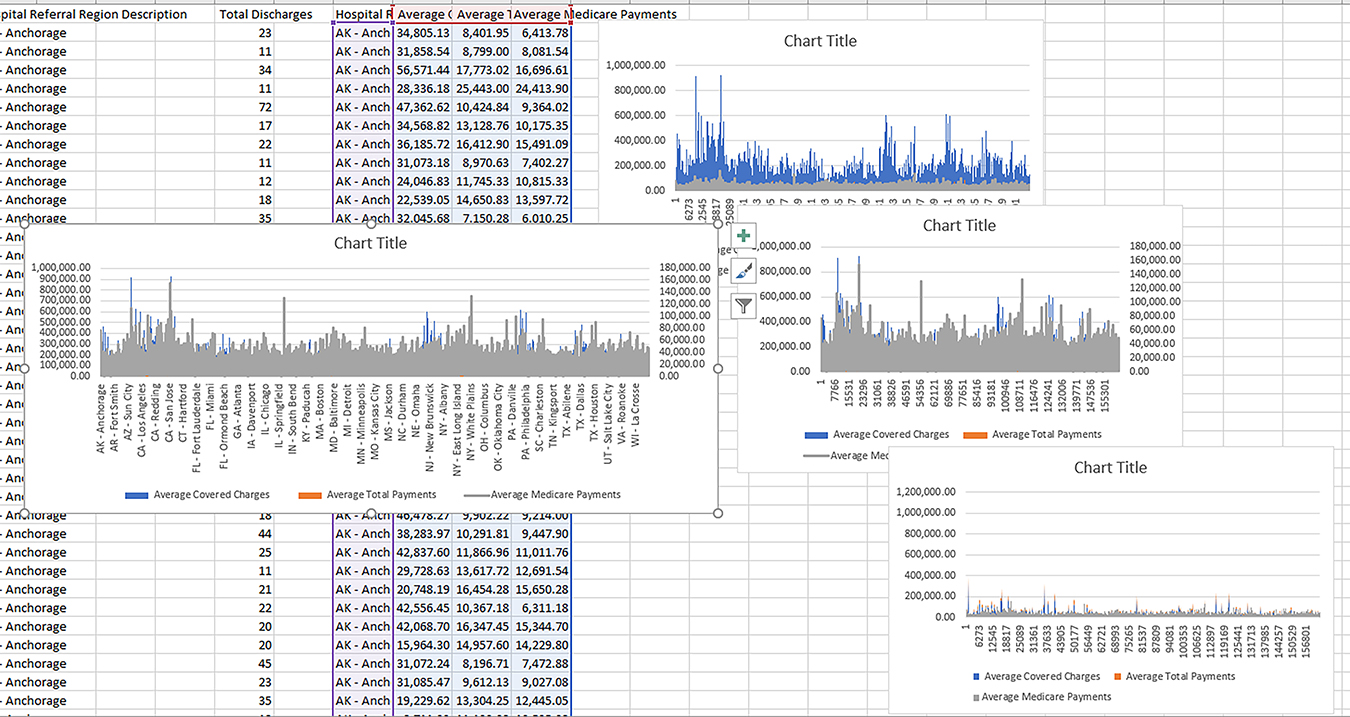{kind=link}
Figure 2. A Quick Rough of the Three Premade Types of Combo Charts (with a Remade Cluster One to the Left)
Of course, there is also the option of “Create Custom Combo Chart” in the “Insert” tab and the . This approach enables the selection of each data column and the definition of the chart type for that column of data. (Figure 3) This option enables more granular control over the data.
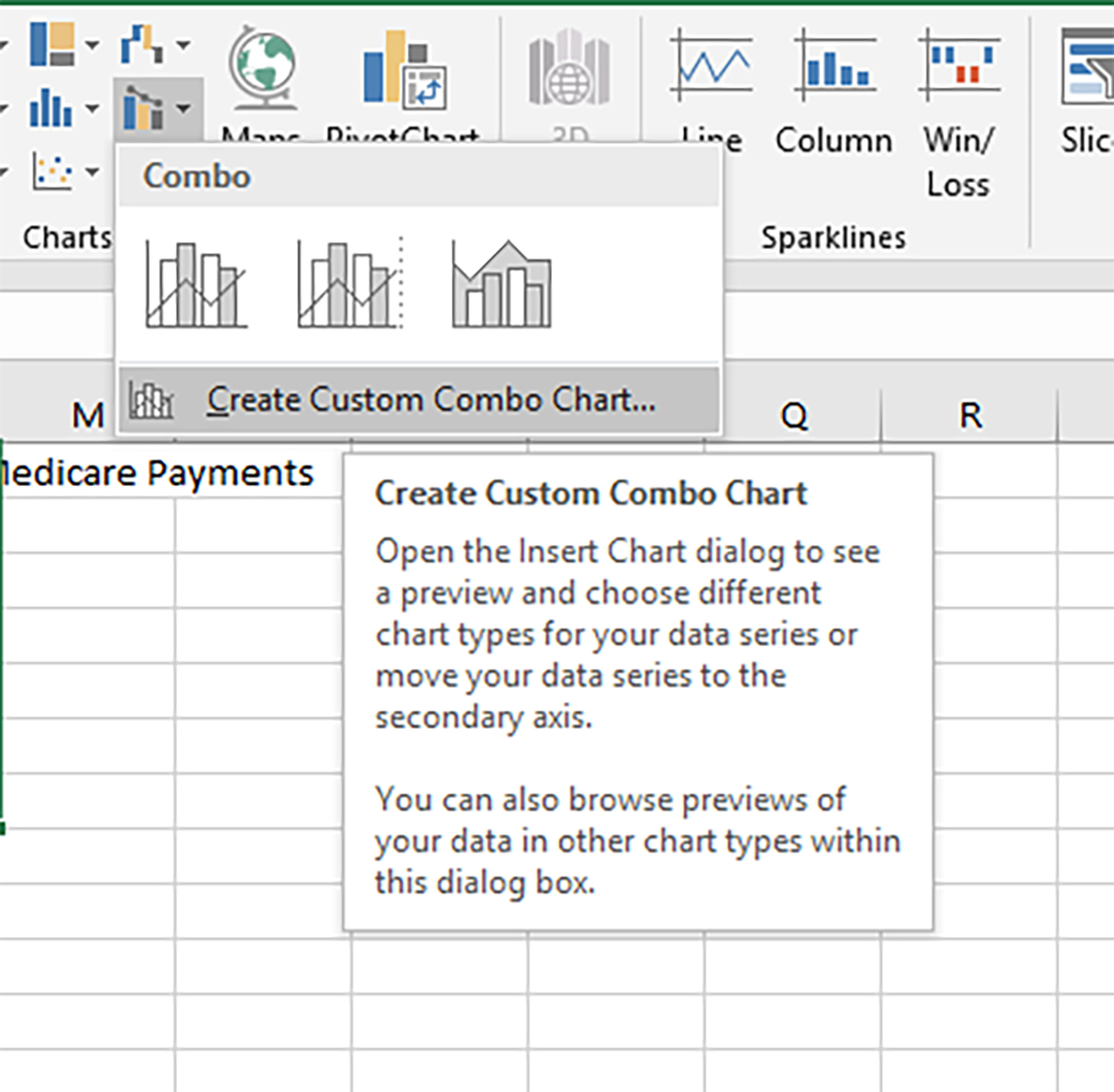{kind=link}
Figure 3. The Create Custom Combo Chart Option
This “wizard” also offers visual aids for what the data will look like in the plot space. (Figure 4)
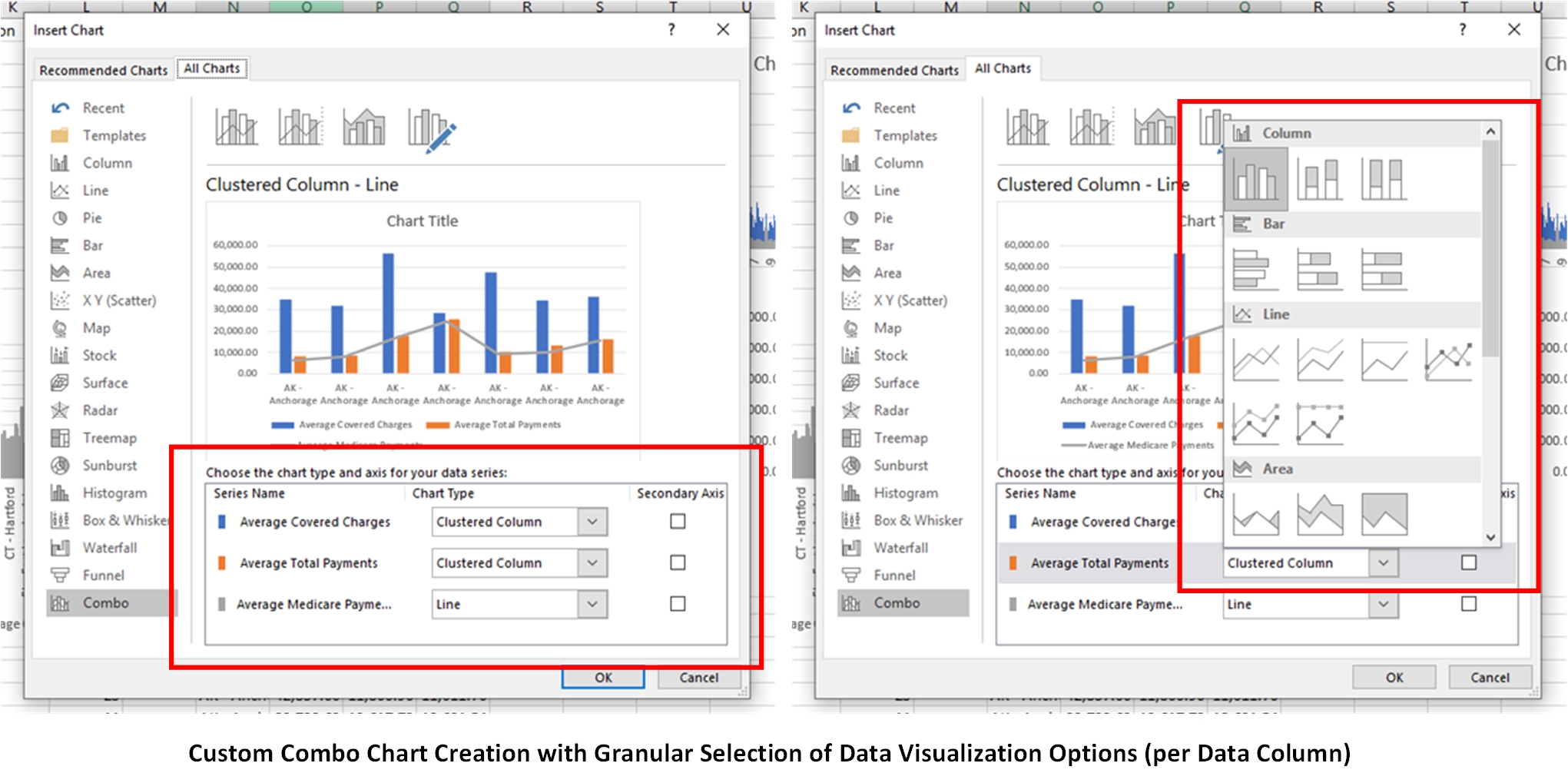{kind=link}
Figure 4. Custom Combo Chart Creation with Granular Selection of Data Visualization Options (per Data Column)
It is also possible to highlight the selected data in the graph view and change its data type there. When cleaning up the data visualization, it is possible to change the colors of the respective objects as well and to introduce transparency and other effects. The idea is to make the data visualization as clear as possible. In Figure 5, the amount paid by Medicare is much less than the coverage amount. Notice the discrepancy between the primary y-axis (left) and the secondary y-axis (right). There are mixed scales on the primary and secondary axes…and the data mapped to one side is not directly comparable to the data mapped to the other side. A critical approach requires an accurate understanding of what is depicted (and where the source data comes from and its strengths and weaknesses, its fidelity to the world).
Also, this visual breaks the rule in terms of aesthetic pleasure and clarity, but with a large set of data being processed on a laptop, even small changes can take a lot of time. Also, the challenge here is to ensure that users do not just breeze past the data visualization; otherwise, they will come away with erroneous impressions. It may be important to have appropriate lead-up text and appropriate lead-away text to explain the data. Or, this data may be separated into two different combo charts…with different emphases on each.
In other cases, it may help to prepare the data first…and not try to represent the whole set in one visual. (The point of combo charts is to combine data, but the data should be as clear as possible.) (This example should be maybe what “not” to do, but the clustering by hospital is interesting. Potentially, it would be good to cluster hospitals by regions and have separate plots for each region. How data are set up for data visualizations has a lot to do with the target learning and the target learners. In this case, these visuals are being created to explore combo charts and what to do and what not to do!)
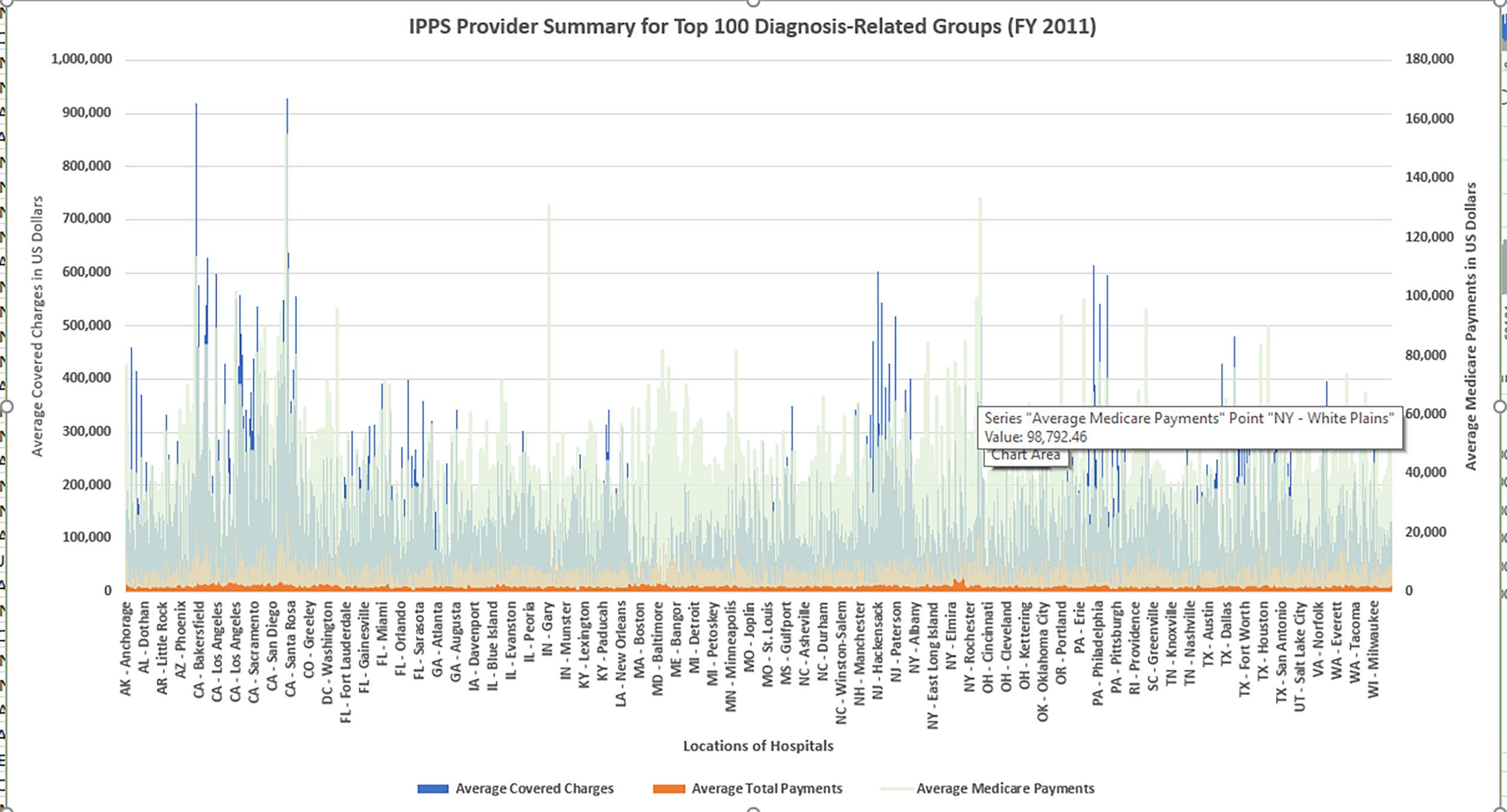{kind=link}
Figure 5. IPSS Provider Summary for Top 100 Diagnosis-Related Groups (FY 2011)
In many ways, Excel 2019 enables smart graphing anyway, with its recognition of the underlying data and ideas of what may work better foregrounded and what backgrounded, but it also requires human readability sense.
One More Example Set
Finally, to get a sense of how the combo charts might look, a data table from the 2013 Housing Affordability Data System from the AHS National Data, AHS Metro Data, and 1997 – 2009 median household incomes in larger metro areas in the U.S. were downloaded through the Data.gov site. A core purpose of this research is to measure housing affordability across the U.S. –as a factor of housing prices (for ownership, for rental) as compared to household income. This survey looks at how much of a burden housing costs are, with the assumption that housing costs should not require more than 30% of their income. Between 30 – 49.9% of income is considered moderately burdensome, and 50% or more of income spent on housing is considered a severe housing cost burden.
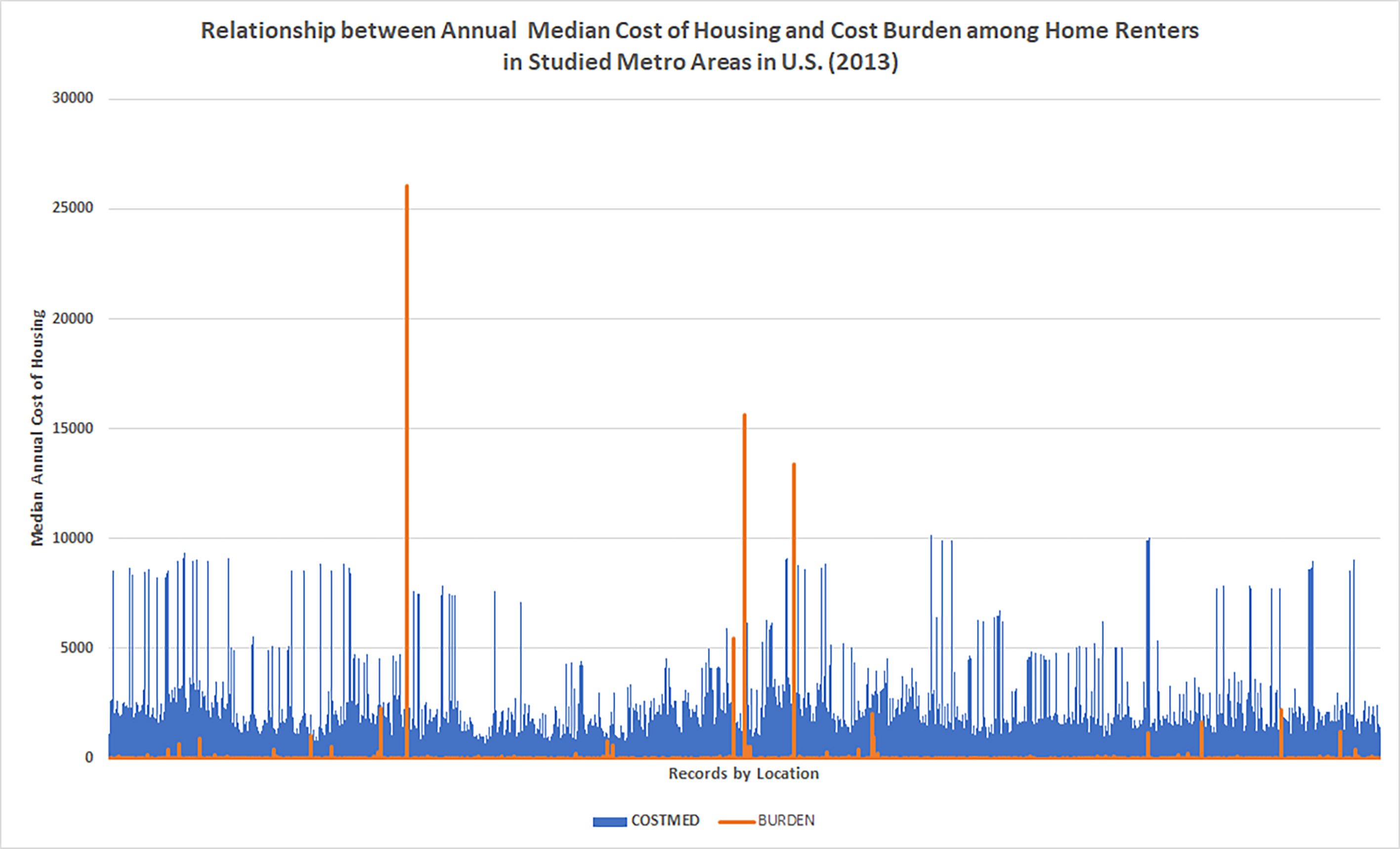
There are many ways to slice up a dataset for data visualizations. Figure 6 shows the relationship between the annual median cost of housing and the cost burden among home owners in studied metro areas (with 39,856 records), and Figure 7 shows the same for renters (with 26,055 records). (The general pattern is that housing on both coasts are much more expensive with housing costs outpacing income.)
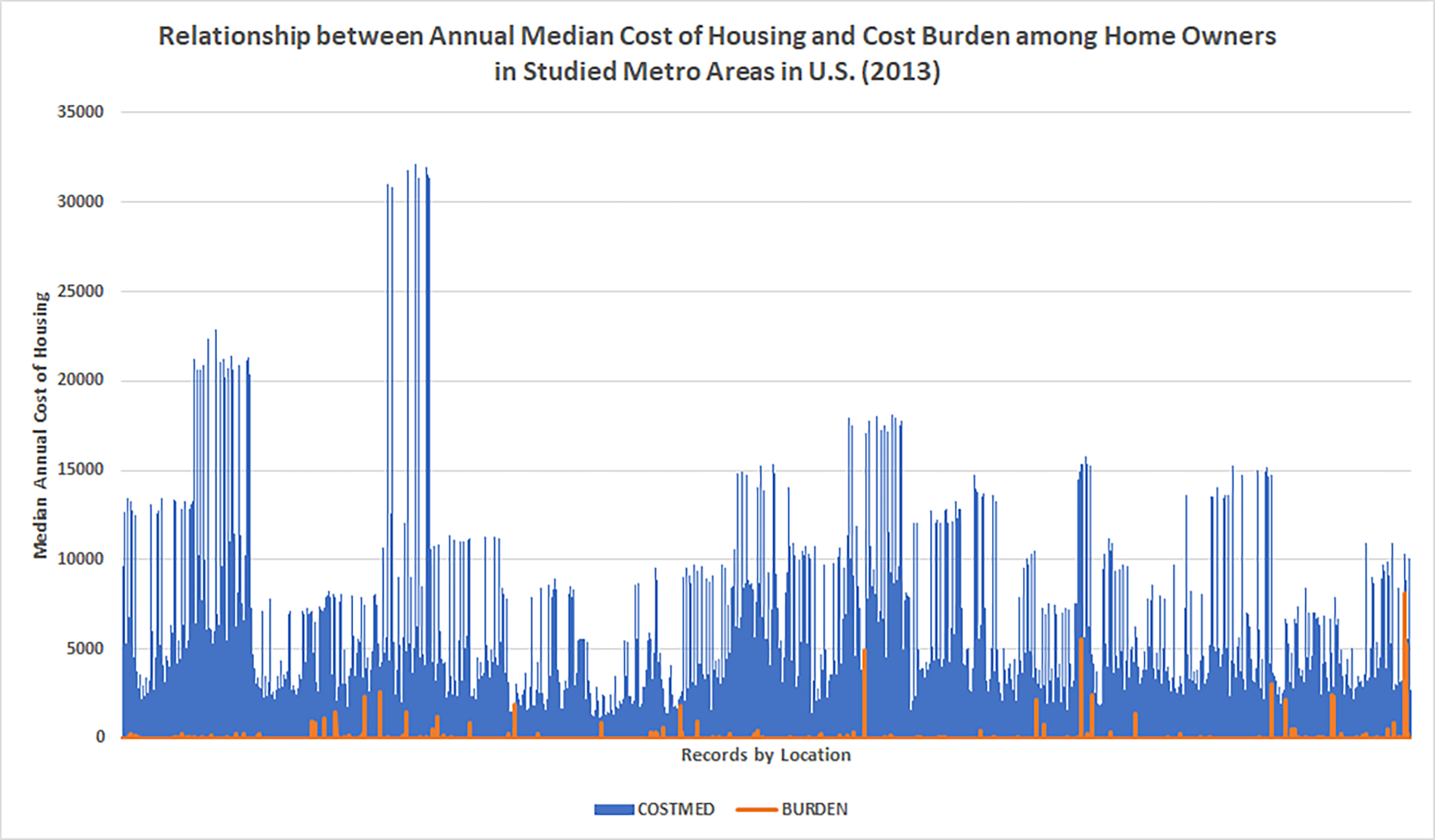{kind=link}
Figure 6. Relationship between Annual Median Cost of Housing and Cost Burden among Home Owners in Studied Metro Areas in U.S. (2013)
The data show annual median costs of housing and extrapolates area expense based on annual median incomes in the area. In other words, these are summary data.
{kind=link}
Figure 8 compares the year built, average values, and affordable housing burden for the U.S. nationally based on representational housing stock examples. Is there any relationship between the year built and the income burden? Are there patterns of change over time across the national affordable housing dataset for 2013? Are older homes lower cost and less of a burden, or are they more expensive because of the need for upkeep?
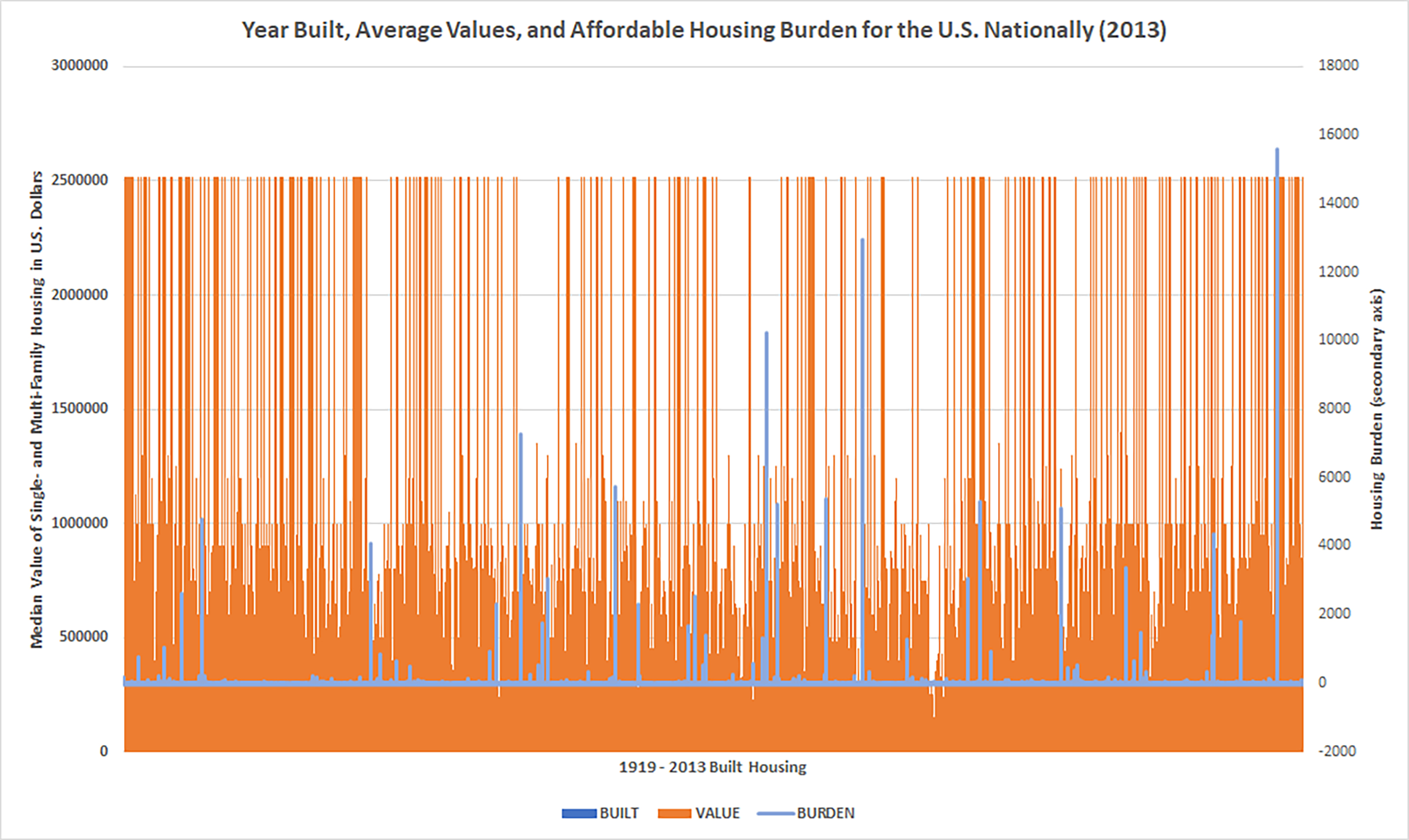{kind=link}
Figure 8. Year Built, Average Values, and Affordable Housing Burden for the U.S. Nationally (2013)
Figure 9 shows the combo chart of median household incomes in larger metro areas in the U.S. for 1997 and 2009, a 12-year interval. Some areas show more robust economies enabling higher wage growth in that time than others. The data are from cities with populations over 100,000.
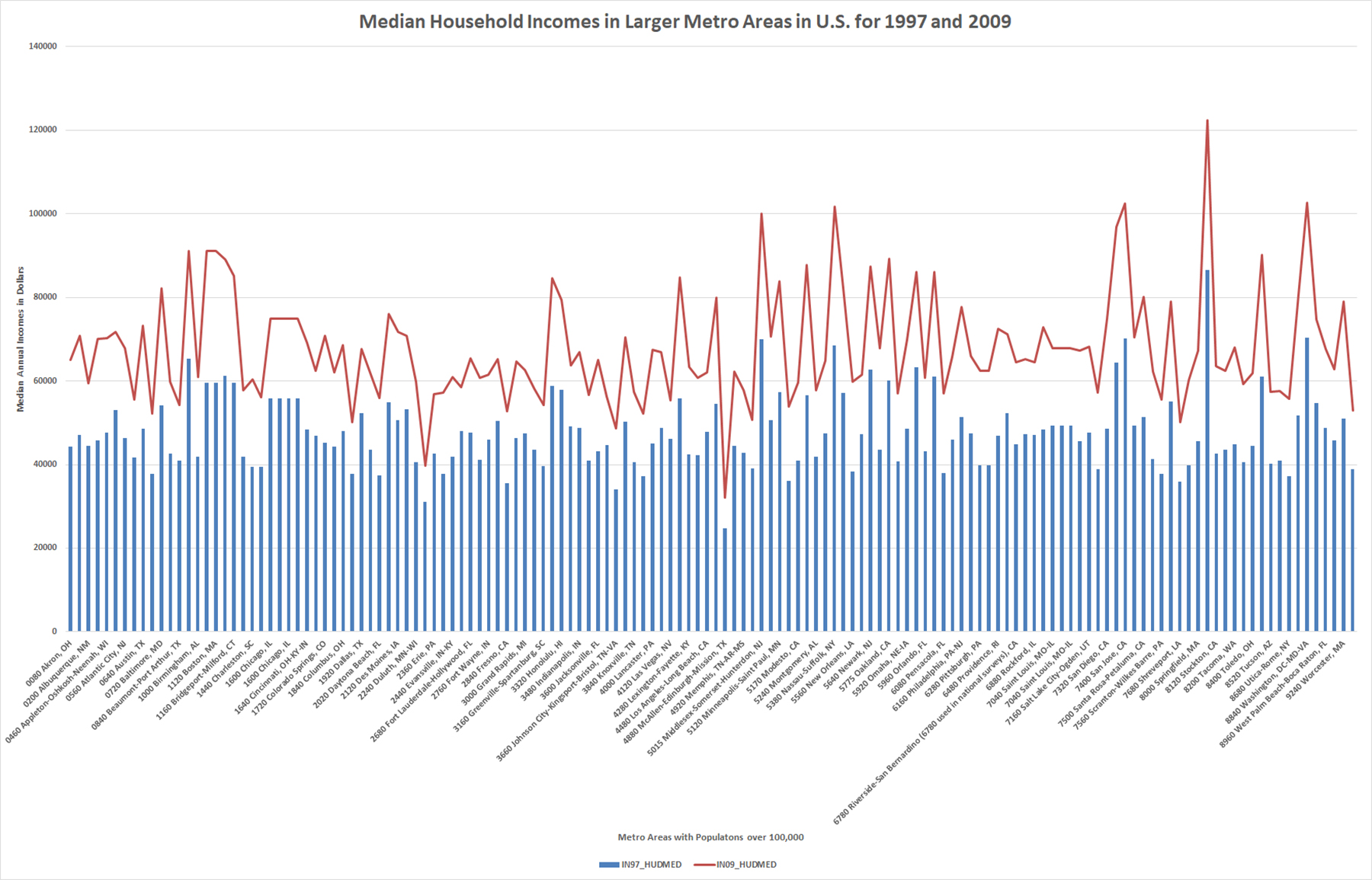{kind=link}
Figure 9. Median Household Incomes in Larger Metro Areas in U.S. for 1997 and 2009
The same data in the prior figure is shown in Figure 10, albeit with a different combo chart type, with clustered bar charts and stacked area charts.
{kind=link}
Figure 10. Cumulative Median Household Incomes in Larger Metro Areas in U.S. from 1997 to 2009
Combo charts are just another tool in a toolkit. For very complex data, it may help to have a number of data visualizations, each answering different questions. It may help to have an interactive dashboard on Excel to help learners engage the data and zoom-in on particular patterns and interrelationships.
References
American Housing Survey: Housing Affordability Data System. (n.d.) Office of Policy Development and Research (PD&R). Data.gov. Retrieved Dec. 26, 2018, from https://www.huduser.gov/portal/datasets/hads/hads.html.
Inpatient Prospective Payment System (IPPS) Provider Summary for the Top 100 Diagnosis-Related Groups (DRG) – FY 2011. CMS. Data.gov. Retrieved Dec. 26, 2018, from https://data.cms.gov/Medicare-Inpatient/Inpatient-Prospective-Payment-System-IPPS-Provider/97k6-zzx3.
About the Author
Shalin Hai-Jew works as an instructional designer at Kansas State University. Her email is shalin@ksu.edu.
| Previous page on path | Cover, page 13 of 23 | Next page on path |
Discussion of "Creating Combo Charts in Excel 2019"
Add your voice to this discussion.
Checking your signed in status ...