Applying Decision Trees to Online Learning Data
By Shalin Hai-Jew, Kansas State University
{kind=link}
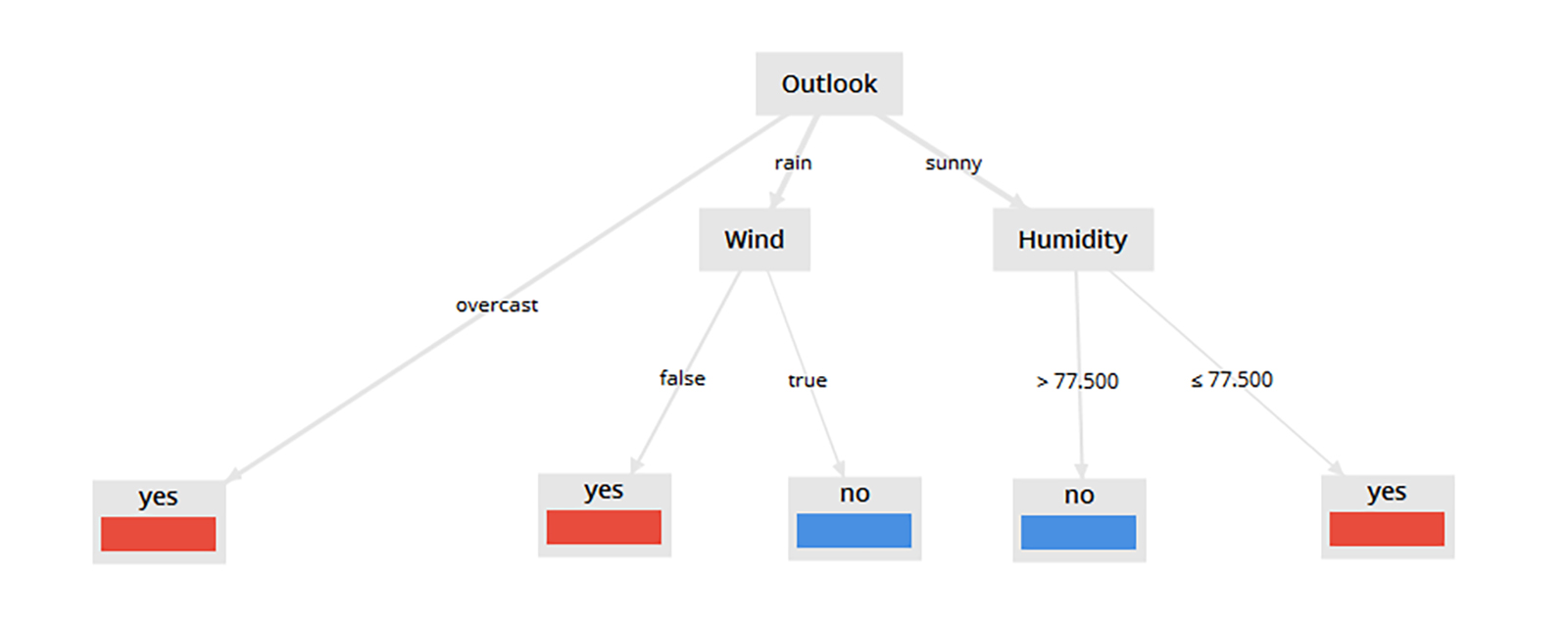
Figure 1: Golf Today? Decision Tree
If the weather outlook for the day is overcast, then it is quite likely that the person will go golfing. If the day is rainy but not windy, that would also make for a good golf day, but if it is rainy and windy, then generally, that person will not go golfing. If the weather outlook for the day is sunny, and the projected (relative) humidity is greater than 77.5%, then that person will not likely go golfing; however, if the day is predicted to be sunny and the humidity is predicted to be less than or equal to 77.5%, then the person will likely go golfing. So says the decision tree in Figure 1 based on faux sample data in RapidMiner Studio.
Decision Trees in Machine Learning
A decision tree, in a machine learning (formerly data mining) context, is induced from data. The data used to draw a decision tree is actually in classic data table format. What is the basic data table structure? There are unique identifiers for each record (each row of data in the data table). There are attributes applied to the respective records. And most importantly, there is an outcome variable that labels the particular row data. This outcome variable may be a label that describes what category the particular row belongs to.
- In a data table of sales prospects, the label data may be defined in a binary fashion such as the following: sale_achieved or no_sale. Data lost to observation may be left off of that data table.
- In a dataset of people in a dating app, which members of a population end up with a left swipe or a right swipe? What attributes about those people indicate what classification or category they end up in (within a certain time period…after joining…after making contact with another member…after some other “event”)?
- Or in a dataset of online learners, the classifications may be the following: A, B, C, D, or F, or I, or Z, as outcome variables. In other words, grade-wise, how did the learner fare?) What a decision tree does is it looks at statistical relationships to see which variable (which column data) most informs the outcome for each outcome of interest.
In terms of data cleaning, this process does not require anything too difficult. If there are gaps in data cells, that may have to be addressed. If the data is in a format that the particular decision tree method cannot handle (and there are over a half-dozen types of decision tree algorithms available in popular software programs), then the software program will flag and data and indicate the necessary change. In this case, the change has to be made and recorded, and the data reloaded, and the decision tree re-run.
The power behind a decision tree is that it is used to identify the data attributes that are most revelatory of classification of the records for the respective possible outcomes. At the first split is the attribute that is the most telling indicator of membership classification, and the next split captures other data insights after the data segmentation from the earlier split. This process is therefore sequential and iterated, with each split affecting what follows. Depending on the pre-pruning settings applied to decision trees, trees may resolve within one or a few levels. Depending on the data, there may or may not even be a decision tree that is inducible from it.
Computer-based machine learning methods—like decision tree induction--can process data at scale to find otherwise-latent or otherwise-hidden relationships in the data. For example, in a mass-scale consumer dataset, in which there are thousands of datapoints per consumer, is it possible to run the data to see which members may be predicted to be in the market for a major durable goods purchase like a car. A simplified version of a generic data table may be seen in Figure 2.
{kind=link}
Figure 2: Decision Tree Data Structure as an Originating Data Table (basic)
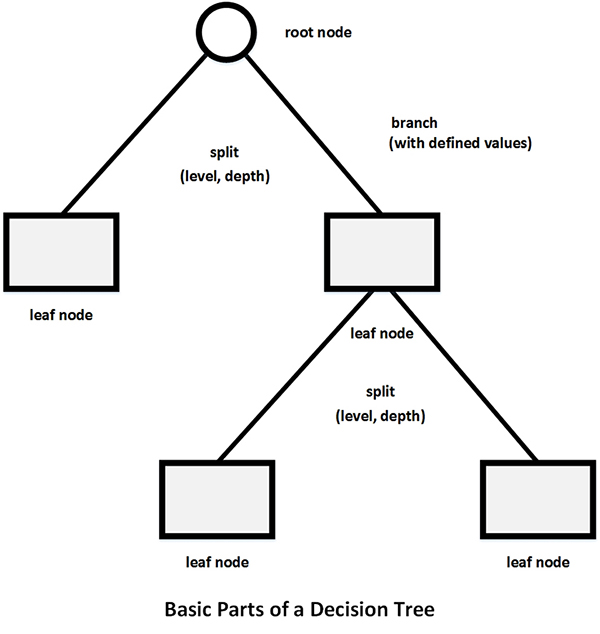
A decision tree is one of the easier types of data visualizations to interpret from a machine learning process because its processes are fairly transparent, and the culminating data visualization shows data relationships in a fairly human-readable and human-interpretable way. A decision tree informs readers what attributes are most associated with certain classifications. From this information, a researcher may hypothesize from the observations for deeper insights. A generic form of a decision tree follows in Figure 3 “Basic Parts of a Decision Tree.”
{kind=link}
Figure 3: Basic Parts of a Decision Tree
As noted in the walk-through at the beginning, the reading of a decision tree starts at the root node (ironically at the top) and moves downwards…through the branches and toward the leaf nodes, down to the respective terminal nodes. Each level of a decision tree, each split, shows some insight about the data and the data relationships. The root node is the data attribute that most “predicts” its membership into a particular category (based on the measure or state of that particular attribute).
Inducing Decision Trees with RapidMiner Studio
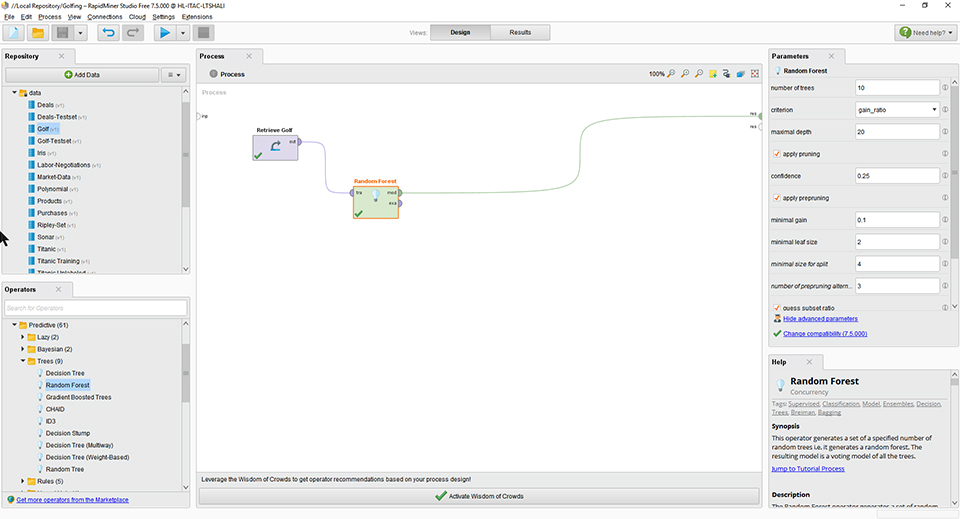
Using a free, educational version of RapidMiner Studio, and using the built-in sample datasets, some decision trees were induced. In this case, just the basic Decision Tree algorithm was used…and then later a Random Forest model…with all the default presets. The results of the basic Decision Tree was introduced in Figure 1. In Figure 4, the design setup for the Random Forest run on the Golf sample data is shown in the RapidMiner workspace.
{kind=link}
Figure 4: Golf Random Forest Design in RapidMiner Studio
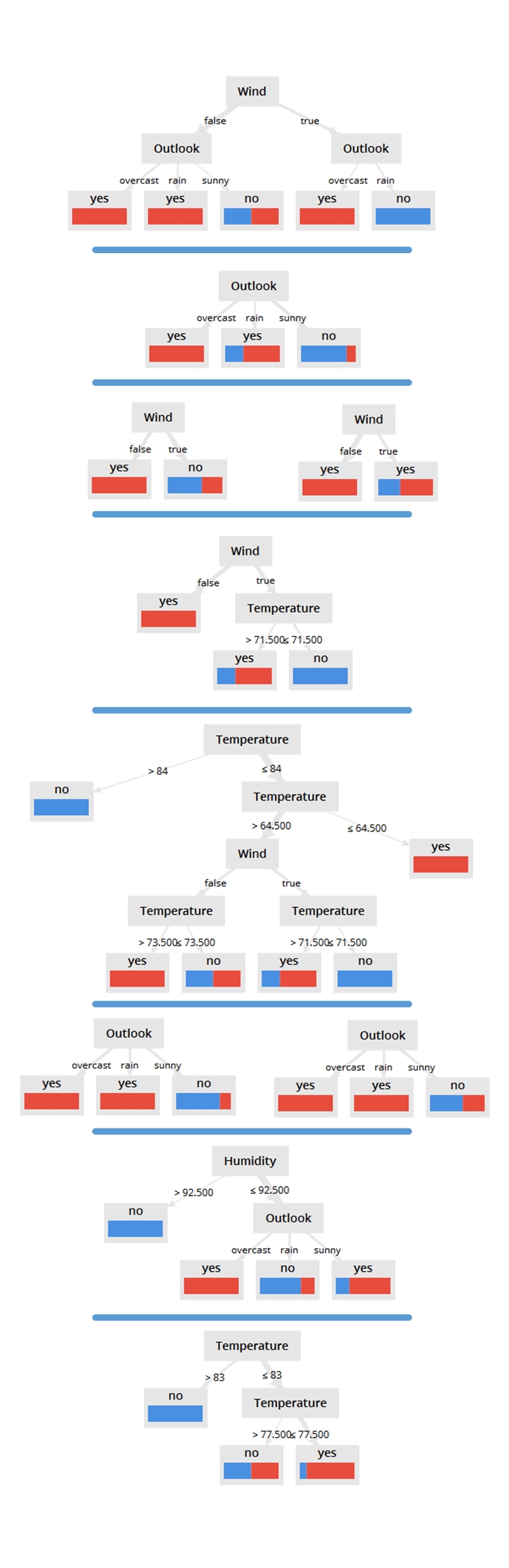
In Figure 5, the resulting decision trees (as they’re refined over the iterations) are shown in order from top to bottom. A few refined decision trees were shown side-by-side as a before-after, in order to include more information and to make the visualization a little more readable (do expand the visualization for a clearer look).
{kind=link}
Figure 5: Decision Trees from a Random Forest from the Golfing Dataset
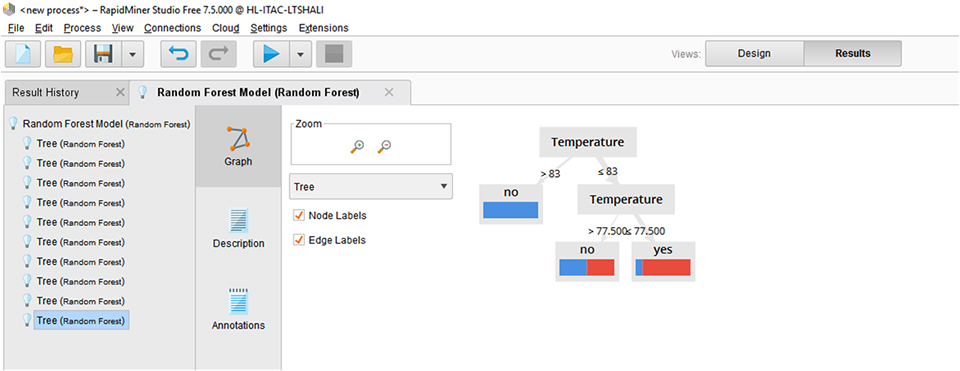
Figure 6 shows the most refined decision tree from the random forest 10 levels down.
{kind=link}
Figure 6: Random Forest Sequence of Golf Dataset in RapidMiner Studio
How well-regarded are decision trees in the machine learning toolsets? So remember that decision trees are extracting data patterns that are inherent in data. This means that there are other ways to find those same patterns. Based on some readings, it looks like decision trees may not necessarily be the best or most computationally efficient ways to find these patterns, but for discussion’s sake, let’s consider both internal and external validity. This will give readers a sense of how decision tree models may be assessed, at least on a few dimensions.
Testing the Internal and External Validity of the Decision Tree Models
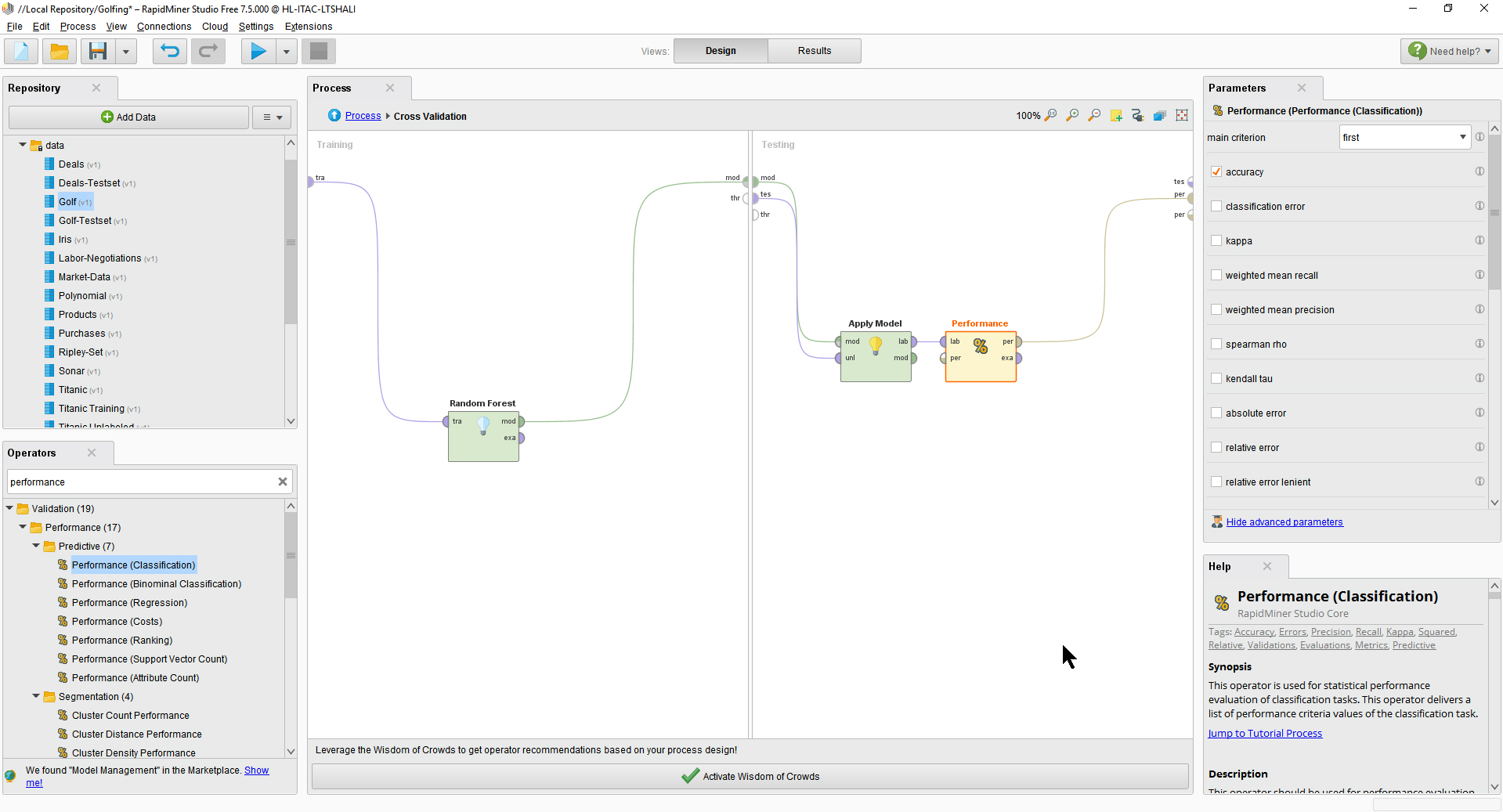
Within RapidMiner Studio, there are ways to test models. One method is cross-validation, which uses the training data that created the decision tree model also as test data to see how well the model predicts classifications of the row data (based on the labeled data). Figure 7 shows the cross-validation setup.
{kind=link}
Figure 7: Cross Validation Setup
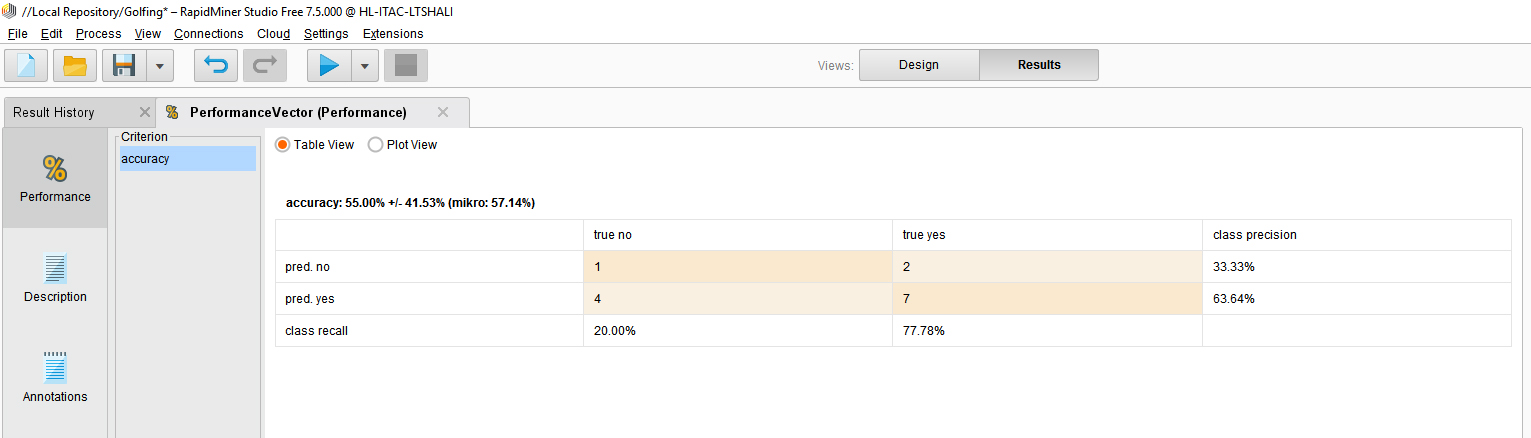
Figure 8 shows the model accuracy in this case…for the random forest…and the accuracy of the labeling of the data is only about 55%, and the micro average performance on all samples was 57.14%.
{kind=link}
Figure 8: Model Accuracy
The accuracy rate is a test against the original data and so is a test of internal validity…based on the original data. Remember that a decision tree also has to be interpreted by the human user. There can be ex post hypothesizing after the decision tree induction. Based on classical inductive logic, looking at data patterns from a set of collected information, there is a leap to a conclusion. This is done algorithmically by the decision tree processes…but it is also done by the human after the decision tree is induced…because the human interprets the decision tree and finds meaning from that. (At any point in the process—the data collection, the data processing, the decision tree setup, the decision tree validation/invalidation, the interpretation of the decision tree…there can be mistakes and misinterpretations. At any point in the process, there can be value added and work-done-right to increase rigor. Full stop.)
Then, there’s the issue of external validity asks how accurately the model tests against the world, broadly speaking. After all, internal validity may be high (not so much in this case), but if the dataset is quite incomplete, or the data was improperly handled, it is possible to have a data-induced model that is only accurate to the underlying data but does not generalize to the world. In other words, the (faux) golfing data may not be accurate to how the target individual makes decisions about whether or not to play golf on a particular day or not.
Applying Decision Trees to Online Learning Data
So how can decision trees be induced from online learning data? So if a person has online learning data in the classic data table setup (indicated above)…and has labeled outcome data…he or she or they can run decision trees to see if there are attributes that are power-indicators of classification. Based on that, they can interpret the data associations and can see if the attribute may be changeable to improve outcomes.
For example, if a particular online course (a variable or attribute) is an important one in guiding under-represented learners into full careers in STEM fields (outcome variable), then maybe researchers may look to understand why that course is so important in leading learners into the STEM fields. They may place more focus on bringing under-represented learners into that course and supporting them (as needed, if needed) in their studies.
For example, if how soon a learner starts to engage with a fellow peer in an online course is an indicator of success / failure in a course, that may have implications for encouraging constructive and positive social ties in online learning.
From the two hypothetical example walk-throughs above, a decision tree could simplify complex data into a more parsimonious and manageable model for awareness and decision-making. Decision trees are necessarily selective of attributes and reductionist of data from datasets. As such, they help focus human attention.
How informative a particular decision tree is depends in part on the data, the context, and the analysts. The point, though, is to find applicable surprises and insights.
Decision trees do not have to apply only to people data. They may also apply to inanimate online learning data.
For example, if there is a dataset about uploaded files in a learning management system (LMS) instance. It is possible to examine the features of the respective uploaded files to which ones are responded to sooner directly after uploaded, and what might inform that faster response. For example, would the attribute of the assignment being in physics mean a faster response than an assignment from another area? Or would the attribute of the assignment maybe be file size (with smaller file sizes responded to faster than larger file sizes, with file size standing in for project complexity possibly)?
Conclusion
Manual decision trees are those that are drawn by hand or manually via software to indicate decision paths and important decision junctures. These are the structural basis for the visual aspects of machine learning-created decision trees. Machine induced decision trees tend to only have binary splits, though, while manually created decision trees may have more complex path options. These latter type are not about making decisions per se but to understand how certain row data may emplace as different classification types based on characteristics of the particular records.
Machine learning-induced decision trees may involve unlabeled data (for unsupervised machine learning applications). The example here was a supervised machine learning example, with human-labeled data.
There are many times of decision tree algorithms in machine learning. This article only showed the basic form one. For more on decision tree learning, please see the linked article.
About RapidMiner Studio(TM)
This short article was set up to introduce decision trees as one tool in the machine learning (data mining) capabilities of the modern age, with a free-for-education tool that enables processing of datasets with up to 10,000 rows of data each. Creating an education account does require a current professional affiliation with an educational institution and meeting stipulations not to use the tool for any commercial or funded research. In these latter cases, users are encouraged to purchase an educational license. The company requires users to sign a contract using DocuSign, and the license is active for three years.
To download a trial version of the software, go to:
Also, there are a number of packages and add-ons that may be used with RapidMiner Studio. There are also integrations with R and Python, so scripts from these programming languages may also be used.
The tool is well documented, with context-sensitive help within the software tool. There is a downloadable manual (v. 6) as well: https://docs.rapidminer.com/downloads/RapidMiner-v6-user-manual.pdf.
References
Hai-Jew, S. (2017, Aug. 16). Using decision trees to analyze online learning data. SlideShare. From the proceedings of the International Symposium on Innovative Teaching and Learning and its Application to Different Disciplines. Kansas State University. Sept. 26 – 27, 2017. https://www.slideshare.net/ShalinHaiJew/using-decision-trees-to-analyze-online-learning-data.
About the Author
Shalin Hai-Jew is an instructional designer at Kansas State University. She may be reached at shalin@k-state.edu.
She is currently eliciting manuscripts for "Designing Instruction for Open Learning," a text forthcoming from Springer.
The author has no tie to RapidMiner, Inc.
| Previous page on path | Cover, page 15 of 26 | Next page on path |
Discussion of "Applying Decision Trees to Online Learning Data"
Add your voice to this discussion.
Checking your signed in status ...