Extracting Meaning from "Related Tags Networks" on Flickr
By Shalin Hai-Jew, Kansas State University
Free-form tags are generally created by non-experts (not professional archivists or librarians), so there is a “folk” element to them. (Expert coders tend to be more precise and nuanced in their coding; they also tend to follow certain labeling standards that enable mutual exclusivity in the uses of terms. Official taxonomies tend to be hierarchical and defined. A librarian colleague explained that she and her colleagues use a “controlled vocabulary” or taxonomy when labeling resources—in order to enable both findability of searched-for resources and some closely related or “adjacent” terms. “Folksonomy”-tagging tends to be “less governed,” in her words. Professional coders work hard to disambiguate resources and to describe them fully accurately. This work enhances the usage of resources both in the presence and into the future.) This folk element may be "noisy" when compared to formal object labeling, but folk tagging adds information as well with its framing of contents (by personality, by local experience, and so on). [In terms of "noise," one study found that only half of tags actually described the tagged image. The rest, in this context, would be "noise" vs. meaningful "signal."]
About Flickr(R)
Flickr, a social sharing repository of images and video owned by Yahoo, has 92 million users (according to Digital Marketing Ramblings). As of 2011, Flickr had 6 billion images in its repository, with an estimated 3.5 million images uploaded daily (The Verge, as cited in “Flickr”). Contents may be organized in formal sets and collections; they may be labeled by hashtags (#) to indicate particular events. Individuals may create stand-alone accounts but also maintain memberships in various groups of interest, within which they share images and videos. This is “big data” by any measure, but how much of this information is actually tapped with any data extraction may be unclear (the amount captured vs. the total amount available).
{kind=link}
As with many other social media platforms, Flickr has an application programming interface (API) which enables access to some of its data. To access this information, users have to be email-verified and white-listed in Flickr’s App Garden. (There are ways to extract all images and / or relational information and image / video labeling on a certain page in Flickr, through tools like DownThemAll. For those who can use command line coding, there are even more direct ways to access Web databases to extract a wide range of JSON / JavaScript Object Notation, and other data types in various data formats.)
There are a wide range of data extractions from Flickr expressed as networks. There may be ego neighborhoods created by certain individuals or groups on Flickr. Various types of social networks built up around certain interactive behaviors surrounding the digital resources may be mapped. For this short piece, the focus will be on “related tag networks.”
So “tags” are informal keyword labels applied as descriptions to digital resources. On Flickr, apparently, there is a maximum of 75 tags per object (a casual scan suggests most are far fewer). Some of the tags are “geotags,” which indicate location [but again are generally unstructured locations vs. the more precise locations reported in EXIF (exchangeable image file format) data from some digital cameras and camcorders].
The “relation” between related tags refers to their co-occurrence in the labeling of various digital objects. These related tags networks of clustered information are used in order to “(1) Identify landmarks and tourist attractions for a given location and (2) disambiguate tag meaning by identifying clusters of related tags” (Rodrigues & Milic-Frayling, 2011, p. 212). Those tags with high probability of co-occurrence are related. Then, in a network, the related tags may be organized in clusters or groups of further relatedness. For example, many related tags networks tend to have a cluster of tags that may relate to photography itself (various camera models, camera-based technologies, and photographic style issues like "black-and-white" and colors), another with references to nature, landmarks, and so on Clusters seem to be lightly topical.
Such networks tend to remain quite static over time. (The author pulled a series of related tags networks that had all the same graph metrics over a multi-year period. This may be because such networks are extracted from shadow databases that are not regularly updated. Or it could be that the threshold for inclusion of tags is sufficiently high that the same ones are extracted over time.) Related tags network extractions from Flickr work best in English; so far, the author has not been able to extract networks using non-English characters, words, or phrases. On the content-sharing platform itself, Flickr enables labeling using all languages representable by Unicode. Its tag BETA version enables machine tagging based on machine-based image recognition and offers computer-created tags to enhance the labeling of its image resources. Machine-suggested tags include such aspects of images such as whether the photos were taken indoors or outdoors, various types of human-made structures, aspects of nature, and so on.
A related tags network is essentially extracted by identifying a particular tag of interest [word(s), a phrase, a symbol, or some other data string]. Then, an individual decides whether the depth of the data extraction should be one-degree, 1.5 degrees, or 2 degrees. [A one-degree related tags network data extraction contains the focal tag and all direct ties to that tag; a 1.5 degree data extraction contains the focal tag, all direct ties to that focal tag, and then any relationships between the “alters” in that network (capturing transitivity); a two-degree data extraction involves the focal node, all direct ties of other tags to that focal node, all connections between the “alters” of that original network, and then also the ego networks of the direct “alters”).
For this case, “Overland Park” was used as the focal tag for a one-degree related tags network on Flickr. The following shows the related terms brought up in Flickr.
The same related tags network is shown with extracted thumbnail images. This latter version conveys some of the NodeXL capabilities of offering a sense of visual gist in a related tags network. There are tradeoffs between having visual information vs. the distraction of such visual data from the term semantics. Also, the thumbnail images are not a random selection of an image from the set of images tagged with the particular term (or any sophisticated image morph across tagged examples); rather, the image is a relatively unchanging "stand-in" for the set (the same image recurs for each respective tag). It is unclear how each respective image was selected.
The proximity of the related tags to each other shows relatedness. The highlighting of “royals” shows its direct ties to other members of its cluster.
To contrast a 1.5-degree network with a 2-degree network, the same “Kansas City” related tags network on Flickr was conducted but with the network degree parameter set at two. The resulting related tags network graph shows Kansas City (the focal tag) at the center. Then, there are clusters of tags that are grouped by co-occurrence and which are indicated by the similar color. The positioning of the tags in this graph (based on a Harel-Koren Fast Multiscale layout algorithm) also relate somewhat to their proximity to the focal tag and its core “alters.”
This related tags network graph shows more of a diffuse sensibility in terms of meanings. This may also show some artifacts of the context: large-scale aggregate tagging behavior, the aesthetics of the software tool used for the extraction and graphing (NodeXL), the nature of Flickr (such as its focus on nature for close-in tags for many related tags networks and the tendency of Flickr to privilege tags related to images and videos), and other tendencies.
The academic research literature offers a bounty of writing on Flickr, given its rich APIs, its numerous affordances, its popularity, and its image and video holdings. Some interesting questions asked include the following:
Rodrigues, E. M. & Milic-Frayling, N. (2011). Flickr: Linking people, photos, and tags. Ch. 13. In Analyzing Social Media Networks with NodeXL: Insights from a Connected World. D.L. Hansen, B. Schneiderman, & M.A. Smith, Eds. Amsterdam: Elsevier.
There are a wide range of data extractions from Flickr expressed as networks. There may be ego neighborhoods created by certain individuals or groups on Flickr. Various types of social networks built up around certain interactive behaviors surrounding the digital resources may be mapped. For this short piece, the focus will be on “related tag networks.”
Related Tags Networks from Flickr
So “tags” are informal keyword labels applied as descriptions to digital resources. On Flickr, apparently, there is a maximum of 75 tags per object (a casual scan suggests most are far fewer). Some of the tags are “geotags,” which indicate location [but again are generally unstructured locations vs. the more precise locations reported in EXIF (exchangeable image file format) data from some digital cameras and camcorders].
The “relation” between related tags refers to their co-occurrence in the labeling of various digital objects. These related tags networks of clustered information are used in order to “(1) Identify landmarks and tourist attractions for a given location and (2) disambiguate tag meaning by identifying clusters of related tags” (Rodrigues & Milic-Frayling, 2011, p. 212). Those tags with high probability of co-occurrence are related. Then, in a network, the related tags may be organized in clusters or groups of further relatedness. For example, many related tags networks tend to have a cluster of tags that may relate to photography itself (various camera models, camera-based technologies, and photographic style issues like "black-and-white" and colors), another with references to nature, landmarks, and so on Clusters seem to be lightly topical.
Such networks tend to remain quite static over time. (The author pulled a series of related tags networks that had all the same graph metrics over a multi-year period. This may be because such networks are extracted from shadow databases that are not regularly updated. Or it could be that the threshold for inclusion of tags is sufficiently high that the same ones are extracted over time.) Related tags network extractions from Flickr work best in English; so far, the author has not been able to extract networks using non-English characters, words, or phrases. On the content-sharing platform itself, Flickr enables labeling using all languages representable by Unicode. Its tag BETA version enables machine tagging based on machine-based image recognition and offers computer-created tags to enhance the labeling of its image resources. Machine-suggested tags include such aspects of images such as whether the photos were taken indoors or outdoors, various types of human-made structures, aspects of nature, and so on.
How a Related Tags Network is Created
A related tags network is essentially extracted by identifying a particular tag of interest [word(s), a phrase, a symbol, or some other data string]. Then, an individual decides whether the depth of the data extraction should be one-degree, 1.5 degrees, or 2 degrees. [A one-degree related tags network data extraction contains the focal tag and all direct ties to that tag; a 1.5 degree data extraction contains the focal tag, all direct ties to that focal tag, and then any relationships between the “alters” in that network (capturing transitivity); a two-degree data extraction involves the focal node, all direct ties of other tags to that focal node, all connections between the “alters” of that original network, and then also the ego networks of the direct “alters”).
For this case, “Overland Park” was used as the focal tag for a one-degree related tags network on Flickr. The following shows the related terms brought up in Flickr.
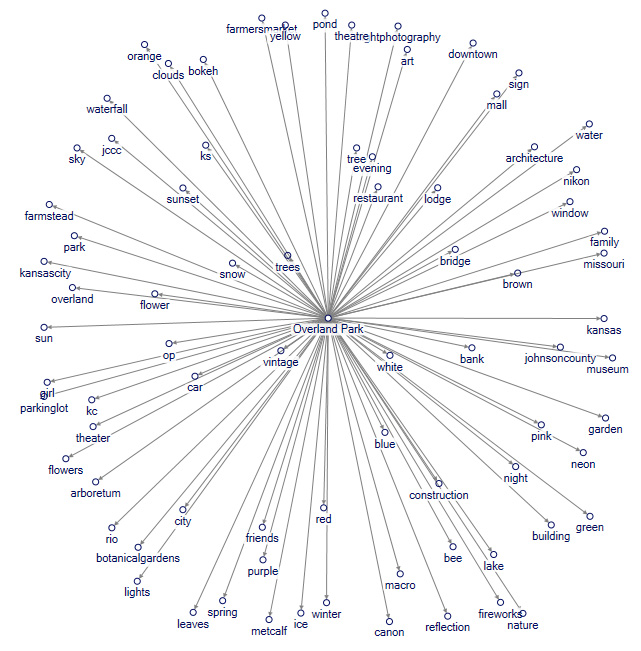{kind=link}
The same related tags network is shown with extracted thumbnail images. This latter version conveys some of the NodeXL capabilities of offering a sense of visual gist in a related tags network. There are tradeoffs between having visual information vs. the distraction of such visual data from the term semantics. Also, the thumbnail images are not a random selection of an image from the set of images tagged with the particular term (or any sophisticated image morph across tagged examples); rather, the image is a relatively unchanging "stand-in" for the set (the same image recurs for each respective tag). It is unclear how each respective image was selected.
{kind=link}
Next, a 1.5 degree related tags network of “Kansas City” was created from Flickr. There were two related clusters of data: one indicated by the light blue nodes (vertices) and the other by the darker blue.
{kind=link}
The proximity of the related tags to each other shows relatedness. The highlighting of “royals” shows its direct ties to other members of its cluster.
{kind=link}
Within the software program that created this visualization, the data is interactive.
To contrast a 1.5-degree network with a 2-degree network, the same “Kansas City” related tags network on Flickr was conducted but with the network degree parameter set at two. The resulting related tags network graph shows Kansas City (the focal tag) at the center. Then, there are clusters of tags that are grouped by co-occurrence and which are indicated by the similar color. The positioning of the tags in this graph (based on a Harel-Koren Fast Multiscale layout algorithm) also relate somewhat to their proximity to the focal tag and its core “alters.”
{kind=link}
This related tags network graph shows more of a diffuse sensibility in terms of meanings. This may also show some artifacts of the context: large-scale aggregate tagging behavior, the aesthetics of the software tool used for the extraction and graphing (NodeXL), the nature of Flickr (such as its focus on nature for close-in tags for many related tags networks and the tendency of Flickr to privilege tags related to images and videos), and other tendencies.
Some Uses in Research
The academic research literature offers a bounty of writing on Flickr, given its rich APIs, its numerous affordances, its popularity, and its image and video holdings. Some interesting questions asked include the following:
- What does image tagging on Flickr suggest about how (un)happy people are in various cities of the world?
- Are males or females more accurate in their geotagging of images on Flickr?
- What do the Flickr tags linked to a particular individual or group profile say about that individual or group's interests? What may be inferred about them? What sorts of "data leakage" may be observed in tagging?
- What are some regionalisms in terms of tag selection? What do those regionalisms suggest about geographical locales, cultures, and languages?
References
Rodrigues, E. M. & Milic-Frayling, N. (2011). Flickr: Linking people, photos, and tags. Ch. 13. In Analyzing Social Media Networks with NodeXL: Insights from a Connected World. D.L. Hansen, B. Schneiderman, & M.A. Smith, Eds. Amsterdam: Elsevier.
Resources
For more information, go to Querying Social Media with NodeXL (2014).
Note: Any researchers working in data extraction from social media platforms and content analysis may consider submitting a chapter proposal and draft chapter to "Social Media Data Extraction and Content Analysis."
About the Author
Shalin Hai-Jew works as an instructional designer at Kansas State University. She may be reached at shalin@k-state.edu.
| Previous page on path | Cover, page 13 of 21 | Next page on path |
Discussion of "Extracting Meaning from 'Related Tags Networks' on Flickr"
Add your voice to this discussion.
Checking your signed in status ...